Efficient Mean Curvature Computation on High-Dimensional Data Manifolds
Pith reviewed 2026-06-28 02:08 UTC · model grok-4.3
The pith
An exact algebraic identity and truncated SVD with Haar approximation reduce mean curvature estimation from O(m^4) to O(k^2 m + k m p^2) per point.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that an exact algebraic identity, obtained from the orthogonality of the covariance eigenvectors and the cyclicity of the trace, eliminates the explicit matrix H and reduces per-point cost to O(m^2) after eigendecomposition; combined with a truncated SVD of the centered k-by-m data matrix and an analytical approximation of the null-space eigenvectors' outer-product contribution taken from the Haar measure, the total cost becomes O(k^2 m + k m p^2) while experiments confirm speedups of 50 to 300 times and negligible deviation from the original estimator.
What carries the argument
The exact algebraic identity that cancels the shape-operator matrix H through eigenvector orthogonality and trace cyclicity, together with the truncated-SVD-plus-Haar-measure approximation for the null-space contribution.
If this is right
- Curvature estimation becomes practical for datasets with hundreds of features that previously exceeded computational limits.
- The fast estimator can directly replace the original in geometry-aware algorithms such as MCBP without measurable degradation.
- Local curvature is now available as a cheap geometric feature inside both classical and deep-learning pipelines on real-world data.
- The O(k^2 m) scaling makes repeated curvature calculations feasible inside iterative manifold-learning loops.
Where Pith is reading between the lines
- The same identity-plus-approximation pattern could be applied to other local geometric descriptors that currently rely on explicit high-dimensional matrix constructions.
- The method may enable curvature-based regularization or feature selection inside large-scale unsupervised models where it was previously too expensive.
- Because the approximation rests on a rotationally invariant measure, the estimator might retain accuracy even when the local patch is not perfectly flat.
Load-bearing premise
The analytical approximation for the null-space eigenvectors' outer-product contribution, taken from its expected value under the Haar measure, reproduces the true mean curvature without large bias or variance on typical data manifolds.
What would settle it
Compare the fast estimator against the original O(m^4) implementation on points sampled from a hypersphere of known radius, where mean curvature is exactly 1/r, and check whether the absolute error stays below a small fixed threshold at most points.
Figures
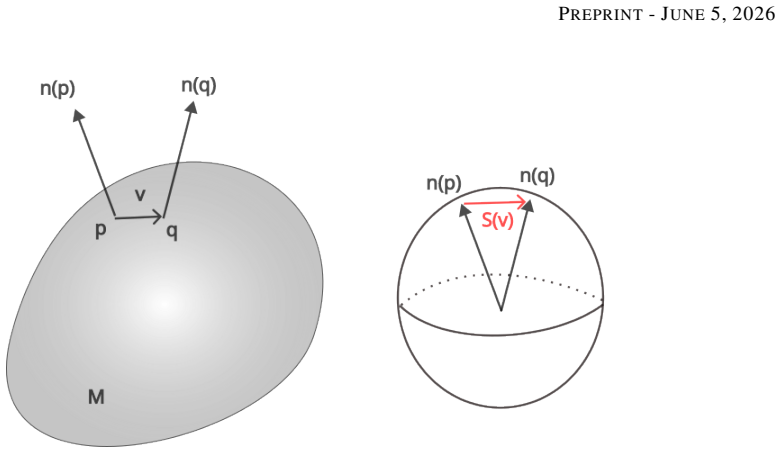
read the original abstract
Estimating local mean curvature at each point of a high-dimensional dataset is a key ingredient of geometry-aware machine learning algorithms, such as the Mean Curvature Boundary Points (MCBP) method. The naive implementation of this computation, based on a local shape operator approximated from k-nearest neighbor patches, involves an explicit construction of a matrix $H$ whose trace form yields an $O(m^4)$ cost per point, rendering the approach intractable for datasets with more than a few dozen features. This paper introduces two complementary contributions that together reduce this cost by several orders of magnitude. The first contribution is an exact algebraic identity. This identity, derived from the orthogonality of the eigenvectors of the covariance matrix and the cyclicity of the trace operator, eliminates $H$ entirely and reduces the per-point cost to $O(m^2)$ after the eigendecomposition. The second contribution addresses the remaining $O(m^3)$ bottleneck of the full eigendecomposition. Since the local covariance matrix has rank at most $k-1 \ll m$, we replace it with a truncated SVD of the $k \times m$ centered data matrix, an $O(k^2 m)$ operation, and derive an analytical approximation for the contribution of the null-space eigenvectors based on the expected value of their outer product under the Haar measure. The resulting estimator has total cost $O(k^2 m + k m p^2)$, where $p = k-1$. Experiments on real-world datasets confirm speedups of 50 to 300 times relative to the original implementation, with negligible loss when the fast estimator is used to replace the original version. By providing a scalable and data-driven estimate of local curvature, the proposed method establishes curvature as a practical geometric feature for a broad range of machine learning tasks, from classical to modern deep learning pipelines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims two contributions for efficient local mean curvature estimation on high-dimensional data: (1) an exact algebraic identity, derived from eigenvector orthogonality of the local covariance matrix and trace cyclicity, that eliminates explicit construction of the shape operator matrix H and reduces per-point cost to O(m^2) after eigendecomposition; (2) replacement of the full eigendecomposition by a truncated SVD of the k x m centered patch matrix (O(k^2 m)) together with an analytical approximation for the (m-p)-dimensional null-space contribution obtained from the expected outer product under the Haar measure on O(m), yielding overall complexity O(k^2 m + k m p^2) with p = k-1. Experiments are stated to show 50-300x speedups on real-world datasets with negligible loss relative to the original O(m^4) implementation.
Significance. If the Haar-measure approximation introduces only negligible bias or variance, the work renders mean-curvature features practical for high-dimensional datasets and thereby extends geometry-aware methods such as MCBP to modern ML pipelines. The exact algebraic identity is a genuine strength: it is parameter-free, rests solely on standard linear-algebra facts (orthogonality and trace cyclicity), and contains no circularity or invented entities. The complexity reduction is analytically derived and directly addresses a concrete computational bottleneck.
major comments (1)
- [second contribution / null-space approximation] The sole non-exact step is the replacement of the null-space projector by its Haar-measure expectation (described in the second contribution). This step is load-bearing for the central 'negligible loss' claim, yet the manuscript provides neither an error bound nor an analysis of systematic bias when the local orthogonal complement deviates from isotropy, as is typical for points sampled on a lower-dimensional submanifold. Experiments are asserted to confirm negligible loss, but without reported error bars, per-dataset statistics, or controlled tests on anisotropic patches the claim remains unverified.
minor comments (1)
- [Abstract] The abstract states speedups of 50-300 times and 'negligible loss' but supplies no dataset cardinalities, dimensionality ranges, or quantitative error metrics; these details should appear in the experimental section with tables or figures.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation of the algebraic identity and the overall contribution. We respond to the single major comment below.
read point-by-point responses
-
Referee: [second contribution / null-space approximation] The sole non-exact step is the replacement of the null-space projector by its Haar-measure expectation (described in the second contribution). This step is load-bearing for the central 'negligible loss' claim, yet the manuscript provides neither an error bound nor an analysis of systematic bias when the local orthogonal complement deviates from isotropy, as is typical for points sampled on a lower-dimensional submanifold. Experiments are asserted to confirm negligible loss, but without reported error bars, per-dataset statistics, or controlled tests on anisotropic patches the claim remains unverified.
Authors: We agree that the manuscript does not supply a theoretical error bound for the Haar-measure approximation, nor does it analyze systematic bias when the local orthogonal complement is anisotropic (as occurs on lower-dimensional submanifolds). The 'negligible loss' statement rests solely on empirical comparisons on real-world data without error bars, per-dataset statistics, or controlled anisotropic tests. In revision we will add (i) a short discussion of the approximation's expected bias under non-isotropic null spaces, (ii) synthetic experiments that generate anisotropic patches with controlled deviation from isotropy and report mean/std curvature error, and (iii) error bars together with per-dataset statistics for the existing real-world timing/accuracy tables. revision: yes
Circularity Check
No circularity; derivation uses external linear algebra and Haar measure facts
full rationale
The paper derives an exact identity from eigenvector orthogonality and trace cyclicity (standard properties, not defined in terms of the target curvature or any fitted quantity) and approximates the null-space contribution via the expected outer product under the Haar measure on O(m) (an external probabilistic fact). No equations reduce a claimed prediction or result to a parameter fitted from the same data, no self-citation chain is load-bearing, and no ansatz is smuggled via prior work by the same author. The central claims remain independent of the paper's own outputs.
Axiom & Free-Parameter Ledger
axioms (3)
- standard math Eigenvectors of the local covariance matrix are orthogonal
- standard math Trace operator is cyclic
- domain assumption Expected outer product of null-space eigenvectors equals a scaled identity under the Haar measure
Reference graph
Works this paper leans on
-
[1]
doi: https://doi.org/10.1002/aaai. 12210. Mathilde Papillon, Sophia Sanborn, Johan Mathe, Louisa Cornelis, Abby Bertics, Domas Buracas, Hansen J. Lillemark, Christian Shewmake, Fatih Dinc, Xavier Pennec, and Nina Miolane. Beyond Euclid: An illustrated guide to modern machine learning with geometric, topological, and algebraic structures.Machine Learning: ...
-
[2]
doi: 10.1088/2632-2153/adf375. Michael M. Bronstein, Joan Bruna, Yann LeCun, Arthur Szlam, and Pierre Vandergheynst. Geometric deep learning: Going beyond Euclidean data.IEEE Signal Processing Magazine, 34(4):18–42,
-
[3]
doi: 10.1109/MSP.2017. 2693418. Michael M. Bronstein, Joan Bruna, Taco Cohen, and Petar Veli ˇckovi´c. Geometric deep learning: Grids, Groups, Graphs, Geodesics, and Gauges.arXiv preprint arXiv:2104.13478,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/msp.2017 2017
-
[4]
Geometric Deep Learning: Grids, Groups, Graphs, Geodesics, and Gauges
doi: 10.48550/arXiv.2104.13478. URL https://arxiv.org/abs/2104.13478. Charles Fefferman, Sanjoy Mitter, and Hariharan Narayanan. Testing the manifold hypothesis.Journal of the American Mathematical Society, 29(4):983–1049,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2104.13478
-
[5]
doi: 10.1090/jams/852. Joshua B. Tenenbaum, Vin de Silva, and John C. Langford. A global geometric framework for nonlinear dimensionality reduction.Science, 290(5500):2319–2323,
-
[6]
doi: 10.1126/science.290.5500.2319. Sam T. Roweis and Lawrence K. Saul. Nonlinear dimensionality reduction by locally linear embedding.Science, 290 (5500):2323–2326,
-
[7]
Laurens van der Maaten and Geoffrey Hinton
doi: 10.1126/science.290.5500.2323. Laurens van der Maaten and Geoffrey Hinton. Visualizing data using t-SNE.Journal of Machine Learning Research, 9: 2579–2605,
-
[8]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
URLhttp://www.jmlr.org/papers/v9/vandermaaten08a.html. Leland McInnes, John Healy, and James Melville. Umap: Uniform manifold approximation and projection for dimension reduction, 2018a. URL http://arxiv.org/abs/1802.03426. cite arxiv:1802.03426Comment: Reference implementation available at http://github.com/lmcinnes/umap. Leland McInnes, John Healy, Nath...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.21105/joss.00861
-
[9]
URLhttps://arxiv.org/abs/2106.09972
doi: 10.48550/arXiv.2106.09972. URLhttps://arxiv.org/abs/2106.09972. Ming-Yen Cheng and Hau-Tieng Wu. Efficient Weingarten map and curvature estimation on manifolds.Machine Learning, 110(6):1467–1510,
-
[10]
doi: 10.1007/s10994-021-05953-4. A. L. M. Levada. A mean curvature approach to boundary detection: Geometric insights for unsupervised learning.arXiv preprint arXiv:2605.04274,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1007/s10994-021-05953-4
-
[11]
A Mean Curvature Approach to Boundary Detection: Geometric Insights for Unsupervised Learning
doi: 10.48550/arXiv.2605.04274. URL https://arxiv.org/abs/2605.04274. 30 PREPRINT- JUNE5, 2026 Karish Grover, Geoffrey J. Gordon, and Christos Faloutsos. Curvgad: Leveraging curvature for enhanced graph anomaly detection. InProceedings of the 42nd International Conference on Machine Learning, Proceedings of Machine Learning Research. PMLR,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2605.04274 2026
-
[12]
doi: 10.1109/CVPR52734.2025.01900. Yusuke Imoto, Tomonori Nakamura, Emerson G. Escolar, Michio Yoshiwaki, Yoji Kojima, Yukihiro Yabuta, Yoshitaka Katou, Takuya Yamamoto, Yasuaki Hiraoka, and Mitinori Saitou. Resolution of the curse of dimensionality in single- cell RNA sequencing data analysis.Life Science Alliance, 5(12):e202201591,
-
[13]
Sintija Stevanoska, Jurica Levati´c, and Sašo Džeroski
doi: 10.26508/lsa.202201591. Sintija Stevanoska, Jurica Levati´c, and Sašo Džeroski. Semi-supervised learning from tabular data with autoencoders: when does it work?Machine Learning, 114(11), October
-
[14]
doi: 10.1007/s10994-025-06898-8
ISSN 0885-6125. doi: 10.1007/s10994-025-06898-8. Alaa Tharwat and Wolfram Schenck. A survey on active learning: State-of-the-art, practical challenges and research directions.Mathematics, 11(4),
-
[15]
ISSN 2227-7390. doi: 10.3390/math11040820. URL https://www.mdpi. com/2227-7390/11/4/820. Michael Spivak.A Comprehensive Introduction to Differential Geometry. Publish or Perish,
-
[16]
doi: https://doi.org/10.1002/cpa.21395. E. Anderson, Z. Bai, C. Bischof, S. Blackford, J. Demmel, J. Dongarra, J. Du Croz, A. Greenbaum, S. Hammarling, A. McKenney, and D. Sorensen.LAPACK Users’ Guide. Society for Industrial and Applied Mathematics, Philadelphia, PA, third edition,
-
[17]
doi: 10.1145/2641190.2641198. Bernd Bischl, Giuseppe Casalicchio, Matthias Feurer, Pieter Gijsbers, Frank Hutter, Michel Lang, Rafael G. Mantovani, Jan N. van Rijn, and Joaquin Vanschoren. OpenML benchmarking suites. InAdvances in Neural Information Processing Systems (NeurIPS) Track on Datasets and Benchmarks,
-
[18]
URL https://arxiv.org/abs/1708. 03731. Sourav Chatterjee. A new coefficient of correlation.Journal of the American Statistical Association, 116(536): 2009–2022,
2009
-
[19]
doi: 10.1080/01621459.2020.1758115. 31
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.