Learning Entropy and Spatial Adaptation Dynamics of Multilayer Perceptrons for Structural Point Extraction
Pith reviewed 2026-06-27 17:18 UTC · model grok-4.3
The pith
Spatial Learning Entropy from MLP weight adaptations identifies image points by their impact on network learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
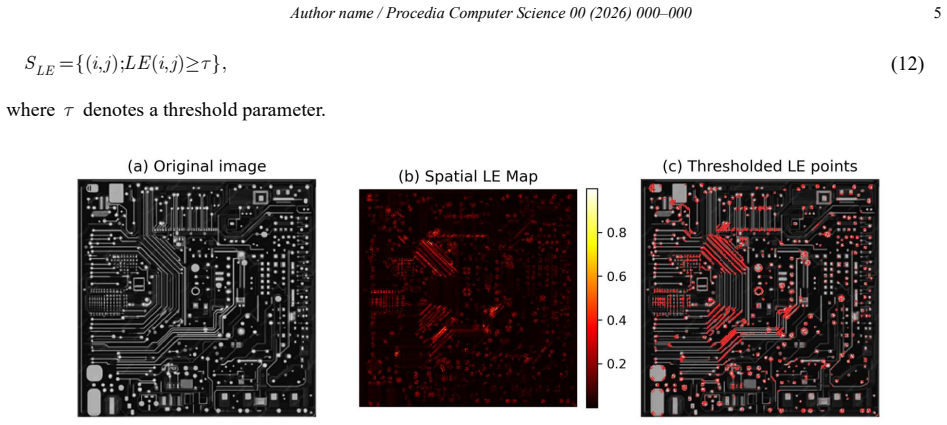
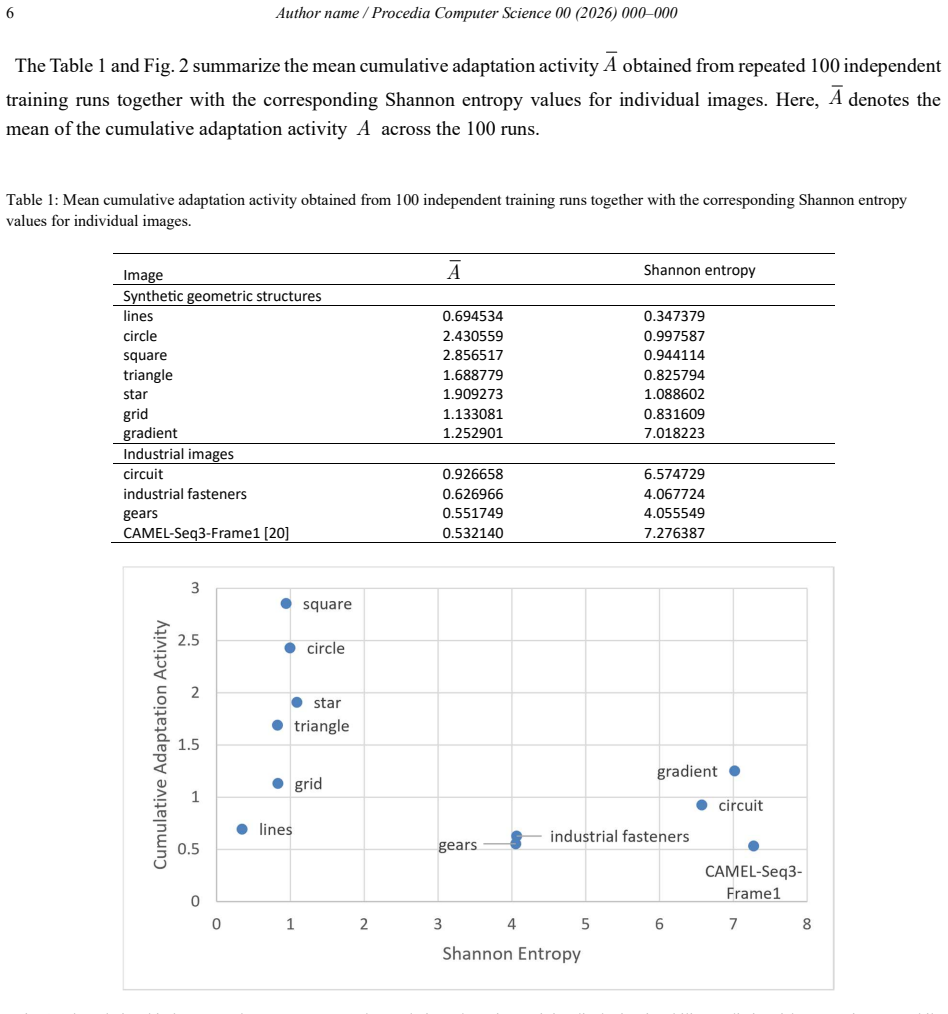
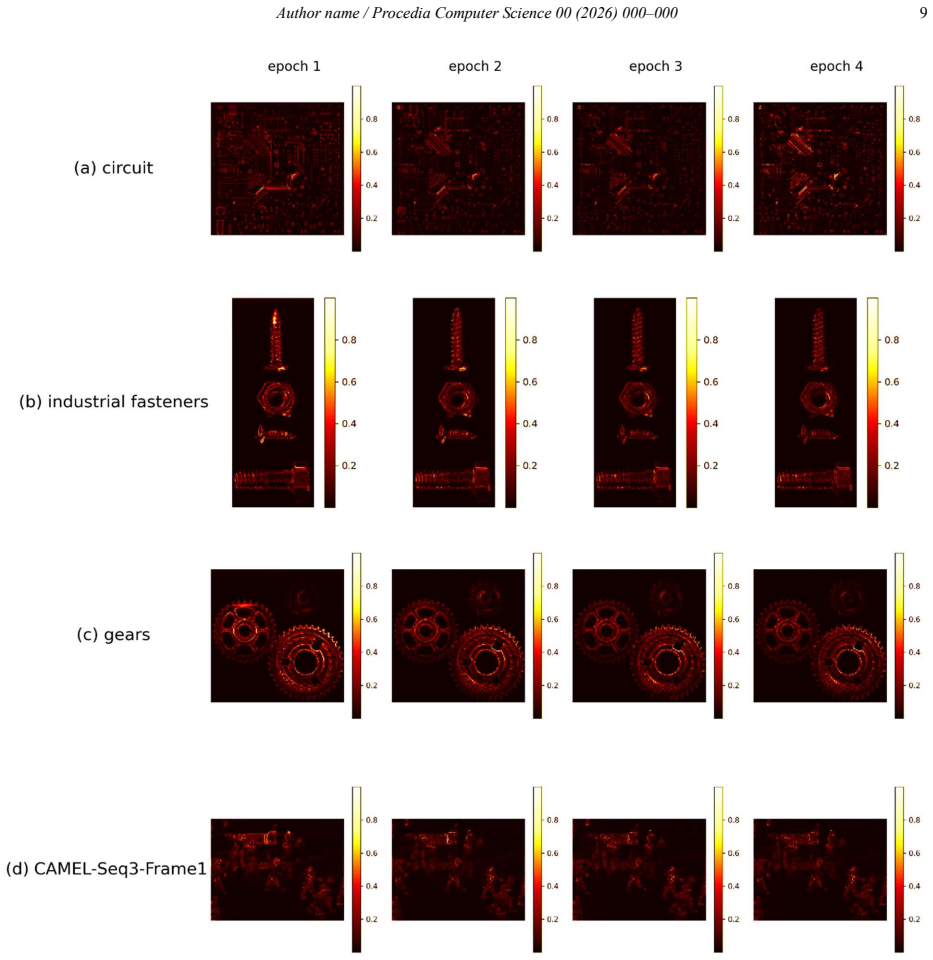
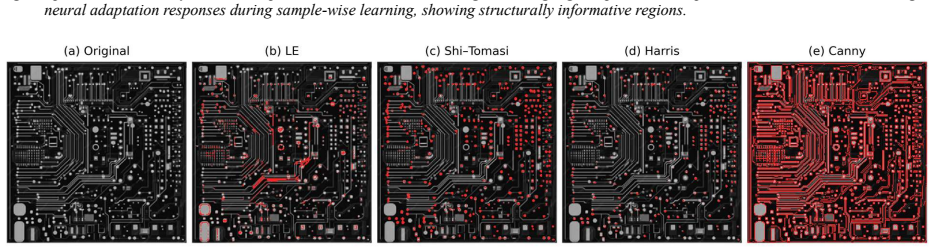
Training an MLP to reconstruct center-pixel intensity from neighboring spatial context and then computing Learning Entropy on the incremental weight changes across those samples produces Spatial Learning Entropy Maps that locate points and regions with a significant role in the learning process, distinct from maps generated by direct structural analysis of the image.
What carries the argument
Spatial Learning Entropy Maps (SLEM) computed from the magnitude of neural-weight adaptations while an MLP learns to predict pixel values from local spatial neighborhoods
If this is right
- SLEM can flag image locations that induce unusually large adaptation steps.
- The maps supply a perspective on image importance based on learning dynamics rather than local gradients or covariance.
- The same framework may be used for scene analysis tasks in computer vision, manufacturing inspection, and robotics.
- Points are ranked by the strength of their effect on the training trajectory instead of by static image features.
Where Pith is reading between the lines
- The approach could be tested on non-image data by defining analogous local prediction tasks on other structured inputs.
- High-entropy regions might serve as candidates for focused data collection or active learning loops.
- Combining SLEM with gradient-based saliency could produce maps that reflect both structure and learning impact.
Load-bearing premise
The size of weight changes during MLP training on spatial samples produces entropy values that mark points with an important role in the learning process.
What would settle it
A controlled test in which high-entropy points are removed from the training set and the resulting MLP performance or convergence speed is compared against removal of an equal number of low-entropy points.
Figures


read the original abstract
This paper extends the concept of Learning Entropy (LE) from temporal adaptive systems to spatial learning in multilayer perceptron networks (MLPs) applied to image data. Instead of evaluating image structure directly from gradients or covariance operators, as local neighborhood methods do, the proposed approach analyzes the learning process itself through Learning Entropy. An MLP is trained to predict the intensity of a center pixel from its surrounding spatial context, while LE is evaluated from the incremental adaptation of neural weights during learning across image-derived samples. The resulting Spatial Learning Entropy Maps (SLEM) identify unusual image points and regions that induce strong adaptation of the neural network and therefore have an important role in the learning process. The results indicate that spatial Learning Entropy provides a complementary perspective to conventional feature extraction and explainability methods by highlighting spatial locations that are particularly informative for network learning. Spatial Learning Entropy provides a complementary perspective to conventional feature extraction and explainability methods by identifying image points and regions according to their learning impact rather than their local structural properties. The proposed framework may open new directions for learning-driven image or scene analysis in computer vision, manufacturing, and robotics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper extends Learning Entropy from temporal systems to spatial MLP training on image patches, where an MLP predicts center-pixel intensity from surrounding context and Learning Entropy is computed from incremental weight adaptations across samples. The resulting Spatial Learning Entropy Maps (SLEM) are claimed to identify image points and regions with high learning impact, providing a perspective complementary to gradient- or covariance-based feature extraction.
Significance. If empirically validated, the method could supply a learning-dynamics-based alternative for point importance in computer vision and robotics. The construction is parameter-free in its core definition and directly ties importance to adaptation rather than local operators, which is a conceptual strength; however, the absence of any supporting experiments, benchmarks, or error analysis limits immediate significance.
major comments (2)
- [Abstract] Abstract: the claim that 'the results indicate that spatial Learning Entropy provides a complementary perspective...' and that SLEM maps 'identify unusual image points... that have an important role in the learning process' is unsupported; no experiments, tables, figures, quantitative comparisons, or validation against ground-truth structural importance are presented anywhere in the manuscript.
- [Abstract] The central claim of complementarity rests on the assumption that high-entropy points under this adaptation process are distinct from those flagged by local gradients or covariance; without any cross-method comparison or correlation analysis, this remains an untested assertion rather than a demonstrated result.
minor comments (1)
- [Abstract] Abstract contains two nearly identical consecutive sentences describing the complementarity claim; this repetition should be removed.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We agree that the abstract makes unsupported empirical claims and will revise the text to accurately reflect the conceptual nature of the work.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'the results indicate that spatial Learning Entropy provides a complementary perspective...' and that SLEM maps 'identify unusual image points... that have an important role in the learning process' is unsupported; no experiments, tables, figures, quantitative comparisons, or validation against ground-truth structural importance are presented anywhere in the manuscript.
Authors: We agree with this assessment. The manuscript presents a conceptual extension of Learning Entropy to spatial MLP training on image patches without any experiments or quantitative results. We will revise the abstract to remove all references to 'results indicate' and 'the results indicate that spatial Learning Entropy provides a complementary perspective', instead describing the method as a proposed framework that may offer such a perspective. We will also add a brief discussion noting the absence of empirical validation and the need for future benchmarks. revision: yes
-
Referee: [Abstract] The central claim of complementarity rests on the assumption that high-entropy points under this adaptation process are distinct from those flagged by local gradients or covariance; without any cross-method comparison or correlation analysis, this remains an untested assertion rather than a demonstrated result.
Authors: We accept this criticism. Complementarity is asserted on conceptual grounds (adaptation dynamics versus local operators) but is not demonstrated. We will revise the abstract and introduction to state that the approach is designed around learning impact rather than local structure, while explicitly noting that distinctiveness from gradient- or covariance-based methods remains to be verified through future comparative analysis. No new experiments or comparisons will be added in this revision. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and description define Spatial Learning Entropy directly from observed weight adaptation dynamics during MLP training on spatial patches, then use the resulting values to flag points with high adaptation impact. This is a definitional construction of the proposed measure rather than a derivation in which a claimed prediction or result reduces to the inputs by construction (no equations shown). No self-citations, uniqueness theorems, or ansatzes imported from prior author work are referenced as load-bearing. The complementarity claim is framed as an empirical perspective to be validated externally, leaving the method self-contained.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Learning Entropy Signature for Image Representation and Classification
Learning Entropy Signatures are formed from the K largest locations in Spatial Learning Entropy Maps generated via sequential MLP learning on image pixel neighborhoods and shown to retain discriminative power for clas...
Reference graph
Works this paper leans on
-
[1]
A Combined Corner and Edge Detector,
C. Harris and M. Stephens, “A Combined Corner and Edge Detector,” in Procedings of the Alvey Vision Conference 1988, Manchester: Alvey Vision Club, 1988, p. 23.1-23.6. doi: 10.5244/C.2.23
-
[2]
Jianbo Shi and Tomasi, “Good features to track,” in Proceedings of IEEE Conference on Computer Vision and Pattern Recognition CVPR-94, Seattle, WA, USA: IEEE Comput. Soc. Press, 1994, pp. 593–600. doi: 10.1109/CVPR.1994.323794
-
[3]
J. Canny, “A Computational Approach to Edge Detection,” IEEE Trans. Pattern Anal. Mach. Intell., vol. PAMI-8, no. 6, pp. 679–698, Nov. 1986, doi: 10.1109/TPAMI.1986.4767851
-
[4]
Deep learning.Nature, 521(7553):436– 444, 2015
Y. LeCun, Y. Bengio, and G. Hinton, “Deep learning,” Nature, vol. 521, no. 7553, pp. 436–444, May 2015, doi: 10.1038/nature14539
-
[5]
Goodfellow, Y
I. Goodfellow, Y. Bengio, and A. Courville, Deep learning. 2016. Accessed: Nov. 29, 2017. [Online]. Available: http://www.deeplearningbook.org/
2016
-
[6]
Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps,
K. Simonyan, A. Vedaldi, and A. Zisserman, “Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps,” Dec. 2013, Accessed: May 21, 2026. [Online]. Available: https://openreview.net/forum?id=cO4ycnpqxKcS9
2013
-
[7]
Axiomatic Attribution for Deep Networks
M. Sundararajan, A. Taly, and Q. Yan, “Axiomatic Attribution for Deep Networks,” 2017, arXiv. doi: 10.48550/ARXIV.1703.01365
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1703.01365 2017
-
[8]
618–626.doi:10.1109/ICCV.2017.74
R. R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh, and D. Batra, “Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization,” in 2017 IEEE International Conference on Computer Vision (ICCV), Venice: IEEE, Oct. 2017, pp. 618–626. doi: 10.1109/ICCV.2017.74
-
[9]
"Why Should I Trust You?": Explaining the Predictions of Any Classifier
M. T. Ribeiro, S. Singh, and C. Guestrin, “‘Why Should I Trust You?’: Explaining the Predictions of Any Classifier,” 2016, arXiv. doi: 10.48550/ARXIV.1602.04938
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1602.04938 2016
-
[10]
A Unified Approach to Interpreting Model Predictions
S. Lundberg and S.-I. Lee, “A Unified Approach to Interpreting Model Predictions,” 2017, arXiv. doi: 10.48550/ARXIV.1705.07874
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1705.07874 2017
-
[11]
Haykin, Adaptive filter theory, 4
S. Haykin, Adaptive filter theory, 4. ed., International ed. in Prentice Hall informations and system sciences series. Upper Saddle River, NJ: Prentice Hall, 2002
2002
-
[12]
Widrow and S
B. Widrow and S. D. Stearns, Adaptive signal processing. in Prentice-Hall signal processing series. Englewood Cliffs, N.J: Prentice- Hall, 1985
1985
-
[13]
A continual learning survey: Defying forgetting in classification tasks,
M. Delange et al., “A continual learning survey: Defying forgetting in classification tasks,” IEEE Trans. Pattern Anal. Mach. Intell., pp. 1–1, 2021, doi: 10.1109/TPAMI.2021.3057446
-
[14]
Gerstner and W
W. Gerstner and W. M. Kistler, Spiking Neuron Models: Single Neurons, Populations, Plasticity, 1st ed. Cambridge University Press,
-
[15]
doi: 10.1017/CBO9780511815706
-
[16]
Anomaly detection: A survey.ACM Computing Surveys, 41(3):1–58, 2009
V. Chandola, A. Banerjee, and V. Kumar, “Anomaly detection: A survey,” ACM Comput. Surv., vol. 41, no. 3, pp. 1–58, Jul. 2009, doi: 10.1145/1541880.1541882
-
[17]
N. Cesa-Bianchi and G. Lugosi, Prediction, Learning, and Games, 1st ed. Cambridge University Press, 2006. doi: 10.1017/CBO9780511546921
-
[18]
Learning Entropy: Multiscale Measure for Incremental Learning,
I. Bukovsky, “Learning Entropy: Multiscale Measure for Incremental Learning,” Entropy, vol. 15, no. 10, pp. 4159–4187, Sep. 2013, Author name / Procedia Computer Science 00 (2026) 000–000 13 Preprint submitted for publication to Elsevier on May 31, 2026. The manuscript is currently under review. doi: 10.3390/e15104159
-
[19]
Learning Entropy as a Learning-Based Information Concept,
I. Bukovsky, W. Kinsner, and N. Homma, “Learning Entropy as a Learning-Based Information Concept,” Entropy, vol. 21, no. 2, p. 166, Feb. 2019, doi: 10.3390/e21020166
-
[20]
Learning Entropy of Adaptive Filters via Clustering Techniques,
Ivo Bukovsky, Gejza Dohnal, Pavel Steinbauer, Ondrej Budik, Kei Ichiji, and Homma Noriyasu, “Learning Entropy of Adaptive Filters via Clustering Techniques,” in 2020 Sensor Signal Processing for Defence Conference (SSPD), IEEE, virtual conference, Edinburgh, UK, pp. 66–70. [Online]. Available: https://sspd.eng.ed.ac.uk/sspd-2020-session-5
2020
-
[21]
Camel dataset for visual and thermal infrared multiple object detection and tracking,
E. Gebhardt and M. Wolf, “Camel dataset for visual and thermal infrared multiple object detection and tracking,” in 2018 15th IEEE international conference on advanced video and signal based surveillance (AVSS), IEEE, 2018, pp. 1–6. Accessed: May 28, 2026. [Online]. Available: https://ieeexplore.ieee.org/abstract/document/8639094/?casa_token=XTIaGraQL7oAA...
arXiv 2018
-
[22]
Deep Learning: Basics and Convolutional Neural Networks (CNNs),
M. Vakalopoulou, S. Christodoulidis, N. Burgos, O. Colliot, and V. Lepetit, “Deep Learning: Basics and Convolutional Neural Networks (CNNs),” in Machine Learning for Brain Disorders, vol. 197, O. Colliot, Ed., in Neuromethods, vol. 197. , New York, NY: Springer US, 2023, pp. 77–115. doi: 10.1007/978-1-0716-3195-9_3
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.