SpaceEra++: A Unified Framework Towards 3D Spatial Reasoning in Video
Pith reviewed 2026-07-03 16:14 UTC · model grok-4.3
The pith
SpaceEra++ adds selective video frame sampling and pairwise object alignment to improve 3D spatial reasoning from video in vision-language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SpaceEra++ overcomes insufficient video input and weak spatial constraints by introducing ScenePick, which samples frames to balance spatial coverage with semantic importance, and SpaceAlign, which jointly optimizes absolute coordinates and relative object relations during training, producing better 3D spatial understanding from video without altering base model size or data volume.
What carries the argument
ScenePick, a frame sampling strategy that balances spatial coverage with object semantics, together with SpaceAlign, a training step that enforces pairwise object constraints using both absolute coordinates and relative spatial relations.
If this is right
- The combined use of ScenePick and SpaceAlign produces consistent accuracy gains across multiple spatial-reasoning benchmarks.
- Removing either component individually reduces performance, confirming each contributes to the overall improvement.
- The same design choices supply concrete directions for strengthening spatial capabilities in other video-based models.
- The approach works without increasing training data size or replacing the underlying vision-language model.
Where Pith is reading between the lines
- If the sampling and alignment steps succeed, similar selection rules could be tested on other video tasks such as action prediction or navigation planning.
- The method may lower reliance on large 3D-labeled datasets by extracting more spatial signal from ordinary video.
- Applying the same frame and constraint logic to real robot camera streams could test whether benchmark gains appear in physical environments.
Load-bearing premise
The assumption that insufficient scanning-video input and weak reasoning constraints are the primary bottlenecks and that ScenePick plus SpaceAlign will reliably fix them without changes to data scale or base model architecture.
What would settle it
A side-by-side test on the same benchmarks where the full SpaceEra++ model performs no better than the original SpaceEra or strong baselines, or where ablating ScenePick or SpaceAlign leaves accuracy unchanged, would show the new components do not deliver the claimed gains.
Figures




read the original abstract
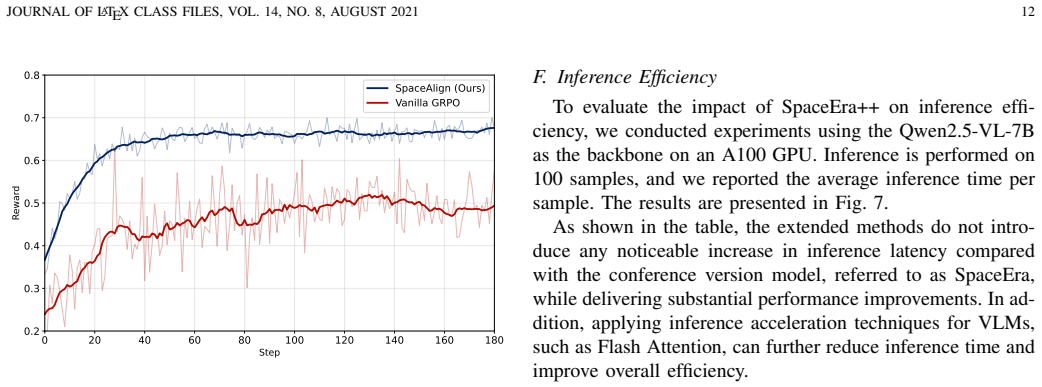
Visual-spatial understanding, defined as the ability to infer object relationships and scene layouts from visual inputs, is fundamental to downstream tasks such as robotic navigation and embodied interaction. However, pre-trained vision-language models (VLMs) remain constrained by spatial uncertainty stemming from inherently 2D observations and by the scarcity of data for 3D spatial understanding. To address these limitations, we proposed a novel framework, SpaceEra, in the NeurIPS 2025 Spotlight paper. Although it achieved significant performance gains, we further observed that its effectiveness is hindered by insufficient input from scanning videos and weak reasoning constraints. To tackle these newly emerged challenges, we extend the original framework into a comprehensive system, termed SpaceEra++, which spans data construction, model design, training optimization, and prompting inference. Specifically, to alleviate input insufficiency, we introduce ScenePick, a frame sampling strategy that balances spatial coverage with object semantics to produce compact yet comprehensive scene representations. In addition, to enhance spatial reasoning, we develop SpaceAlign, which enforces pairwise object constraints by jointly exploiting absolute coordinates and relative spatial relations, thereby aligning optimization with spatial accuracy. Extensive experiments across multiple benchmarks demonstrate consistent improvements over strong baselines, while ablation studies validate both the individual and joint contributions of each component, and further analyses provide guidance for future research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper extends the prior SpaceEra framework (NeurIPS 2025 Spotlight) into SpaceEra++ to improve 3D spatial reasoning in video for VLMs. It identifies two new limitations (insufficient input from scanning videos and weak reasoning constraints) and introduces ScenePick (semantic-aware frame sampling for compact scene representations) and SpaceAlign (joint absolute+relative pairwise object constraints). The manuscript claims that these components, together with data construction, training optimization, and prompting, yield consistent gains over strong baselines on multiple benchmarks, with ablations confirming individual and joint contributions and additional analyses offering future guidance.
Significance. If the attribution of gains to ScenePick and SpaceAlign holds under controlled conditions, the work would offer a practical unified pipeline for mitigating 2D-to-3D spatial uncertainty in VLMs, building directly on a prior accepted paper and supplying concrete sampling and alignment techniques plus benchmark guidance. The emphasis on both data and model design elements is a strength.
major comments (1)
- [Abstract / Experiments section] The central attribution—that ScenePick and SpaceAlign reliably resolve the stated bottlenecks and produce the reported gains—requires controlled experiments that hold total training tokens, base VLM architecture, and training schedule fixed. The abstract asserts that ablation studies validate component contributions, but without such isolation the causal claim remains untested and load-bearing for the extension narrative.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our extension of the SpaceEra framework. We address the major comment point-by-point below.
read point-by-point responses
-
Referee: [Abstract / Experiments section] The central attribution—that ScenePick and SpaceAlign reliably resolve the stated bottlenecks and produce the reported gains—requires controlled experiments that hold total training tokens, base VLM architecture, and training schedule fixed. The abstract asserts that ablation studies validate component contributions, but without such isolation the causal claim remains untested and load-bearing for the extension narrative.
Authors: We agree that rigorous isolation of ScenePick and SpaceAlign contributions is essential for the causal claims. All ablation variants in the manuscript use the identical base VLM architecture, the same pre-trained weights, and the exact same training schedule (optimizer, learning rate, epochs, and batch size). ScenePick operates purely at inference-time frame selection and does not change the per-sample token budget; SpaceAlign adds only a pairwise loss term without altering input token counts. We will revise the Experiments section to explicitly tabulate total training tokens per ablation variant and add a sentence confirming these controls, thereby strengthening the attribution without requiring new runs. revision: partial
Circularity Check
No circularity: empirical framework validated on external benchmarks
full rationale
The paper introduces ScenePick and SpaceAlign as new modules extending prior SpaceEra work, with performance claims resting entirely on ablation studies and benchmark comparisons rather than any derivation, equation, or fitted parameter that reduces to its own inputs by construction. The self-citation to the authors' NeurIPS 2025 paper provides background context but does not serve as load-bearing justification for the current results; no uniqueness theorems, ansatzes, or renamings are invoked. The derivation chain is self-contained because improvements are measured against independent external benchmarks and controlled ablations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Thinking in Space: How Multimodal Large Language Models See, Remember, and Recall Spaces
J. Yang, S. Yang, A. W. Gupta, R. Han, L. Fei-Fei, and S. Xie, “Thinking in space: How multimodal large language models see, remember, and recall spaces,”arXiv preprint arXiv:2412.14171, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Llava-vsd: Large language-and-vision assistant for visual spatial description,
Y . Jin, J. Li, J. Zhang, J. Hu, Z. Gan, X. Tan, Y . Liu, Y . Wang, C. Wang, and L. Ma, “Llava-vsd: Large language-and-vision assistant for visual spatial description,” inProceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 11 420–11 425
2024
-
[3]
Drivevlm: The convergence of autonomous driving and large vision-language models,
X. Tian, J. Gu, B. Li, Y . Liu, Y . Wang, Z. Zhao, K. Zhan, P. Jia, X. Lang, and H. Zhao, “Drivevlm: The convergence of autonomous driving and large vision-language models,” in8th Annual Conference on Robot Learning
-
[4]
Attribute-guided collaborative learning for partial person re- identification,
H. Zhang, M. Liu, Y . Li, M. Yan, Z. Gao, X. Chang, and L. Nie, “Attribute-guided collaborative learning for partial person re- identification,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 12, pp. 14 144–14 160, 2023
2023
-
[5]
Palm-e: an embodied multimodal language model,
D. Driess, F. Xia, M. S. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson, Q. Vuong, T. Yuet al., “Palm-e: an embodied multimodal language model,” inProceedings of the 40th International Conference on Machine Learning, 2023, pp. 8469–8488
2023
-
[6]
Hourvideo: 1-hour video- language understanding,
K. Chandrasegaran, A. Gupta, L. M. Hadzic, T. Kota, J. He, C. Eyza- guirre, Z. Durante, M. Li, J. Wu, and F.-F. Li, “Hourvideo: 1-hour video- language understanding,”Advances in Neural Information Processing Systems, vol. 37, pp. 53 168–53 197, 2024
2024
-
[7]
Exo2ego: Exocentric knowledge guided mllm for egocentric video understanding,
H. Zhang, Q. Chu, M. Liu, H. Shi, Y . Wang, and L. Nie, “Exo2ego: Exocentric knowledge guided mllm for egocentric video understanding,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 15, 2026, pp. 12 502–12 510
2026
-
[8]
Spatialvlm: Endowing vision-language models with spatial reasoning capabilities,
B. Chen, Z. Xu, S. Kirmani, B. Ichter, D. Sadigh, L. Guibas, and F. Xia, “Spatialvlm: Endowing vision-language models with spatial reasoning capabilities,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 14 455–14 465
2024
-
[9]
Spatialrgpt: Grounded spatial reasoning in vision-language models,
A.-C. Cheng, H. Yin, Y . Fu, Q. Guo, R. Yang, J. Kautz, X. Wang, and S. Liu, “Spatialrgpt: Grounded spatial reasoning in vision-language models,”Advances in Neural Information Processing Systems, vol. 37, pp. 135 062–135 093, 2025
2025
-
[10]
Spatialbot: Precise spatial understanding with vision language models,
W. Cai, I. Ponomarenko, J. Yuan, X. Li, W. Yang, H. Dong, and B. Zhao, “Spatialbot: Precise spatial understanding with vision language models,” arXiv preprint arXiv:2406.13642, 2024
-
[11]
Ll3da: Visual interactive instruction tuning for omni-3d understanding reasoning and planning,
S. Chen, X. Chen, C. Zhang, M. Li, G. Yu, H. Fei, H. Zhu, J. Fan, and T. Chen, “Ll3da: Visual interactive instruction tuning for omni-3d understanding reasoning and planning,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 26 428–26 438
2024
-
[12]
3d-llm: Injecting the 3d world into large language models,
Y . Hong, H. Zhen, P. Chen, S. Zheng, Y . Du, Z. Chen, and C. Gan, “3d-llm: Injecting the 3d world into large language models,”Advances in Neural Information Processing Systems, vol. 36, pp. 20 482–20 494, 2023
2023
-
[13]
Gpt4scene: Under- stand 3d scenes from videos with vision-language models
Z. Qi, Z. Zhang, Y . Fang, J. Wang, and H. Zhao, “Gpt4scene: Understand 3d scenes from videos with vision-language models,”arXiv preprint arXiv:2501.01428, 2025
-
[14]
H. Zhang, M. Liu, Z. Li, H. Wen, W. Guan, Y . Wang, and L. Nie, “Spatial understanding from videos: Structured prompts meet simulation data,” arXiv preprint arXiv:2506.03642, 2025
-
[15]
Embspatial-bench: Benchmarking spatial understanding for embodied tasks with large JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 14 vision-language models,
M. Du, B. Wu, Z. Li, X.-J. Huang, and Z. Wei, “Embspatial-bench: Benchmarking spatial understanding for embodied tasks with large JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 14 vision-language models,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), 2024, pp. 346–355
2021
-
[16]
Sphere: Unveiling spatial blind spots in vision-language mod- els through hierarchical evaluation,
W. Zhang, W. E. Ng, L. Ma, Y . Wang, J. Zhao, A. Koenecke, B. Li, and L. Wang, “Sphere: Unveiling spatial blind spots in vision-language mod- els through hierarchical evaluation,”arXiv preprint arXiv:2412.12693, 2024
-
[17]
Spatialpin: Enhancing spatial reasoning capabilities of vision-language models through prompting and interacting 3d priors,
C. Ma, K. Lu, T.-Y . Cheng, N. Trigoni, and A. Markham, “Spatialpin: Enhancing spatial reasoning capabilities of vision-language models through prompting and interacting 3d priors,” inThe Thirty-eighth Annual Conference on Neural Information Processing Systems
-
[18]
Rag-guided large language models for visual spatial description with adaptive hallucination corrector,
J. Yu, Y . Zhang, Z. Zhang, Z. Yang, G. Zhao, F. Sun, F. Zhang, Q. Liu, J. Sun, J. Lianget al., “Rag-guided large language models for visual spatial description with adaptive hallucination corrector,” inProceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 11 407–11 413
2024
-
[19]
Robopoint: A vision-language model for spatial affordance prediction in robotics,
W. Yuan, J. Duan, V . Blukis, W. Pumacay, R. Krishna, A. Murali, A. Mousavian, and D. Fox, “Robopoint: A vision-language model for spatial affordance prediction in robotics,” in8th Annual Conference on Robot Learning
-
[20]
Robospatial: Teaching spatial understanding to 2d and 3d vision- language models for robotics,
C. H. Song, V . Blukis, J. Tremblay, S. Tyree, Y . Su, and S. Birchfield, “Robospatial: Teaching spatial understanding to 2d and 3d vision- language models for robotics,”arXiv preprint arXiv:2411.16537, 2024
-
[21]
Y . Liu, D. Chi, S. Wu, Z. Zhang, Y . Hu, L. Zhang, Y . Zhang, S. Wu, T. Cao, G. Huanget al., “Spatialcot: Advancing spatial reasoning through coordinate alignment and chain-of-thought for embodied task planning,”arXiv preprint arXiv:2501.10074, 2025
-
[22]
Arkitscenes: A diverse real-world dataset for 3d indoor scene understanding using mobile rgb-d data,
G. Baruch, Z. Chen, A. Dehghan, Y . Feigin, P. Fu, T. Gebauer, D. Kurz, T. Dimry, B. Joffe, A. Schwartzet al., “Arkitscenes: A diverse real-world dataset for 3d indoor scene understanding using mobile rgb-d data,” inThirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 1)
-
[23]
Matterport3d: Learning from rgb-d data in indoor environments,
A. Chang, A. Dai, T. Funkhouser, M. Halber, M. Niebner, M. Savva, S. Song, A. Zeng, and Y . Zhang, “Matterport3d: Learning from rgb-d data in indoor environments,” inInternational Conference on 3D Vision (3DV), 2017
2017
-
[24]
Scannet: Richly-annotated 3d reconstructions of indoor scenes,
A. Dai, A. X. Chang, M. Savva, M. Halber, T. Funkhouser, and M. Nießner, “Scannet: Richly-annotated 3d reconstructions of indoor scenes,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 5828–5839
2017
-
[25]
Procthor: Large- scale embodied ai using procedural generation,
M. Deitke, E. VanderBilt, A. Herrasti, L. Weihs, K. Ehsani, J. Salvador, W. Han, E. Kolve, A. Kembhavi, and R. Mottaghi, “Procthor: Large- scale embodied ai using procedural generation,”Advances in Neural Information Processing Systems, vol. 35, pp. 5982–5994, 2022
2022
-
[26]
Multiscan: Scalable rgbd scanning for 3d environments with articulated objects,
Y . Mao, Y . Zhang, H. Jiang, A. Chang, and M. Savva, “Multiscan: Scalable rgbd scanning for 3d environments with articulated objects,” Advances in neural information processing systems, vol. 35, pp. 9058– 9071, 2022
2022
-
[27]
Habitat-matterport 3d dataset (hm3d): 1000 large-scale 3d environments for embodied ai,
S. K. Ramakrishnan, A. Gokaslan, E. Wijmans, O. Maksymets, A. Clegg, J. M. Turner, E. Undersander, W. Galuba, A. Westbury, A. X. Changet al., “Habitat-matterport 3d dataset (hm3d): 1000 large-scale 3d environments for embodied ai,” inThirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)
-
[28]
Scannet++: A high- fidelity dataset of 3d indoor scenes,
C. Yeshwanth, Y .-C. Liu, M. Nießner, and A. Dai, “Scannet++: A high- fidelity dataset of 3d indoor scenes,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 12–22
2023
-
[29]
Softgroup for 3d instance segmentation on point clouds,
T. Vu, K. Kim, T. M. Luu, T. Nguyen, and C. D. Yoo, “Softgroup for 3d instance segmentation on point clouds,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 2708– 2717
2022
-
[30]
Point transformer v3: Simpler faster stronger,
X. Wu, L. Jiang, P.-S. Wang, Z. Liu, X. Liu, Y . Qiao, W. Ouyang, T. He, and H. Zhao, “Point transformer v3: Simpler faster stronger,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 4840–4851
2024
-
[31]
Open3dis: Open-vocabulary 3d instance segmentation with 2d mask guidance,
P. Nguyen, T. D. Ngo, E. Kalogerakis, C. Gan, A. Tran, C. Pham, and K. Nguyen, “Open3dis: Open-vocabulary 3d instance segmentation with 2d mask guidance,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 4018–4028
2024
-
[32]
Unscene3d: Unsupervised 3d instance segmentation for indoor scenes,
D. Rozenberszki, O. Litany, and A. Dai, “Unscene3d: Unsupervised 3d instance segmentation for indoor scenes,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 19 957–19 967
2024
-
[33]
arXiv preprint arXiv:2309.00615 , year=
Z. Guo, R. Zhang, X. Zhu, Y . Tang, X. Ma, J. Han, K. Chen, P. Gao, X. Li, H. Liet al., “Point-bind & point-llm: Aligning point cloud with multi-modality for 3d understanding, generation, and instruction following,”arXiv preprint arXiv:2309.00615, 2023
-
[34]
Shapellm: Universal 3d object understanding for embodied interaction,
Z. Qi, R. Dong, S. Zhang, H. Geng, C. Han, Z. Ge, L. Yi, and K. Ma, “Shapellm: Universal 3d object understanding for embodied interaction,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 214– 238
2024
-
[35]
Lion: Linear group rnn for 3d object detection in point clouds,
Z. Liu, J. Hou, X. Wang, X. Ye, J. Wang, H. Zhao, and X. Bai, “Lion: Linear group rnn for 3d object detection in point clouds,”Advances in Neural Information Processing Systems, vol. 37, pp. 13 601–13 626, 2024
2024
-
[36]
Pointllm: Empowering large language models to understand point clouds,
R. Xu, X. Wang, T. Wang, Y . Chen, J. Pang, and D. Lin, “Pointllm: Empowering large language models to understand point clouds,” in European Conference on Computer Vision. Springer, 2024, pp. 131– 147
2024
-
[37]
Lexicon3d: Probing visual foundation models for complex 3d scene understanding,
Y . Man, S. Zheng, Z. Bao, M. Hebert, L. Gui, and Y .-X. Wang, “Lexicon3d: Probing visual foundation models for complex 3d scene understanding,”Advances in Neural Information Processing Systems, vol. 37, pp. 76 819–76 847, 2024
2024
-
[38]
Improved visual-spatial reasoning via r1-zero-like training,
Z. Liao, Q. Xie, Y . Zhang, Z. Kong, H. Lu, Z. Yang, and Z. Deng, “Improved visual-spatial reasoning via r1-zero-like training,”arXiv preprint arXiv:2504.00883, 2025
-
[39]
F. Zhu, H. Wang, Y . Xie, J. Gu, T. Ding, J. Yang, and H. Jiang, “Struct2d: A perception-guided framework for spatial reasoning in large multimodal models,”arXiv preprint arXiv:2506.04220, 2025
-
[40]
SpaceR: Reinforcing MLLMs in Video Spatial Reasoning
K. Ouyang, Y . Liu, H. Wu, Y . Liu, H. Zhou, J. Zhou, F. Meng, and X. Sun, “Spacer: Reinforcing mllms in video spatial reasoning,”arXiv preprint arXiv:2504.01805, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
A. Jaech, A. Kalai, A. Lerer, A. Richardson, A. El-Kishky, A. Low, A. Helyar, A. Madry, A. Beutel, A. Carneyet al., “Openai o1 system card,”arXiv preprint arXiv:2412.16720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
Deepseek-r1 incentivizes reasoning in llms through reinforcement learning,
D. Guo, D. Yang, H. Zhang, J. Song, P. Wang, Q. Zhu, R. Xu, R. Zhang, S. Ma, X. Biet al., “Deepseek-r1 incentivizes reasoning in llms through reinforcement learning,”Nature, vol. 645, no. 8081, pp. 633–638, 2025
2025
-
[43]
Kimi k1.5: Scaling Reinforcement Learning with LLMs
K. Team, A. Du, B. Gao, B. Xing, C. Jiang, C. Chen, C. Li, C. Xiao, C. Du, C. Liaoet al., “Kimi k1. 5: Scaling reinforcement learning with llms,”arXiv preprint arXiv:2501.12599, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y . Li, Y . Wuet al., “Deepseekmath: Pushing the limits of mathematical reasoning in open language models,”arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
LMM-R1: Empowering 3B LMMs with Strong Reasoning Abilities Through Two-Stage Rule-Based RL
Y . Peng, G. Zhang, M. Zhang, Z. You, J. Liu, Q. Zhu, K. Yang, X. Xu, X. Geng, and X. Yang, “Lmm-r1: Empowering 3b lmms with strong reasoning abilities through two-stage rule-based rl,”arXiv preprint arXiv:2503.07536, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Spatial-MLLM: Boosting MLLM Capabilities in Visual-based Spatial Intelligence
D. Wu, F. Liu, Y .-H. Hung, and Y . Duan, “Spatial-mllm: Boosting mllm capabilities in visual-based spatial intelligence,”arXiv preprint arXiv:2505.23747, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Spartun3d: Situated spatial understanding of 3d world in large language models,
Y . Zhang, Z. Xu, Y . Shen, P. Kordjamshidi, and L. Huang, “Spartun3d: Situated spatial understanding of 3d world in large language models,” arXiv preprint arXiv:2410.03878, 2024
-
[48]
Multi- modal situated reasoning in 3d scenes,
X. Linghu, J. Huang, X. Niu, X. S. Ma, B. Jia, and S. Huang, “Multi- modal situated reasoning in 3d scenes,”Advances in Neural Information Processing Systems, vol. 37, pp. 140 903–140 936, 2024
2024
-
[49]
3d-front: 3d furnished rooms with layouts and semantics,
H. Fu, B. Cai, L. Gao, L.-X. Zhang, J. Wang, C. Li, Q. Zeng, C. Sun, R. Jia, B. Zhaoet al., “3d-front: 3d furnished rooms with layouts and semantics,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 10 933–10 942
2021
-
[50]
Holodeck: Language guided generation of 3d embodied ai environments,
Y . Yang, F.-Y . Sun, L. Weihs, E. VanderBilt, A. Herrasti, W. Han, J. Wu, N. Haber, R. Krishna, L. Liuet al., “Holodeck: Language guided generation of 3d embodied ai environments,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 16 227–16 237
2024
-
[51]
Objaverse: A universe of annotated 3d objects,
M. Deitke, D. Schwenk, J. Salvador, L. Weihs, O. Michel, E. VanderBilt, L. Schmidt, K. Ehsani, A. Kembhavi, and A. Farhadi, “Objaverse: A universe of annotated 3d objects,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 13 142–13 153
2023
-
[52]
Vggt: Visual geometry grounded transformer,
J. Wang, M. Chen, N. Karaev, A. Vedaldi, C. Rupprecht, and D. Novotny, “Vggt: Visual geometry grounded transformer,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 5294– 5306
2025
-
[53]
Openeqa: Embod- ied question answering in the era of foundation models,
A. Majumdar, A. Ajay, X. Zhang, P. Putta, S. Yenamandra, M. Henaff, S. Silwal, P. Mcvay, O. Maksymets, S. Arnaudet al., “Openeqa: Embod- ied question answering in the era of foundation models,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 16 488–16 498
2024
-
[54]
Scanqa: 3d question answering for spatial scene understanding,
D. Azuma, T. Miyanishi, S. Kurita, and M. Kawanabe, “Scanqa: 3d question answering for spatial scene understanding,” inproceedings of JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 15 the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 19 129–19 139
2021
-
[55]
Sqa3d: Situated question answering in 3d scenes,
X. Ma, S. Yong, Z. Zheng, Q. Li, Y . Liang, S.-C. Zhu, and S. Huang, “Sqa3d: Situated question answering in 3d scenes,” inThe Eleventh International Conference on Learning Representations
-
[56]
A. Hurst, A. Lerer, A. P. Goucher, A. Perelman, A. Ramesh, A. Clark, A. Ostrow, A. Welihinda, A. Hayes, A. Radfordet al., “Gpt-4o system card,”arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[57]
SpaceVista: All-Scale Visual Spatial Reasoning from mm to km
P. Sun, S. Lang, D. Wu, Y . Ding, K. Feng, H. Liu, Z. Ye, R. Liu, Y .-H. Liu, J. Wanget al., “Spacevista: All-scale visual spatial reasoning from mm to km,”arXiv preprint arXiv:2510.09606, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[58]
Z. Chen, W. Wang, Y . Cao, Y . Liu, Z. Gao, E. Cui, J. Zhu, S. Ye, H. Tian, Z. Liuet al., “Expanding performance boundaries of open- source multimodal models with model, data, and test-time scaling,” arXiv preprint arXiv:2412.05271, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[59]
S. Bai, K. Chen, X. Liu, J. Wang, W. Ge, S. Song, K. Dang, P. Wang, S. Wang, J. Tanget al., “Qwen2. 5-vl technical report,”arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[60]
S. Bai, Y . Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Geet al., “Qwen3-vl technical report,”arXiv preprint arXiv:2511.21631, 2025. Weili Guanreceived the master’s degree from National University of Singapore, and the Ph.D. degree from Monash University. She has about 6 years of working experience at the enterprise. She is curr...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[61]
degree at the School of Information Science and Techonology, Harbin Institute of Techonology, Shenzhen, China
He is currently pursuing the Ph.D. degree at the School of Information Science and Techonology, Harbin Institute of Techonology, Shenzhen, China. His research has been published in top-tier confer- ences including CVPR. He has served as a reviewer for various conferences and journals, such as IEEE TPAMI, ACM MM and IEEE TCSVT. His main research interests ...
2005
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.