The Illusion of Opting in AI-Mediated Consequential Decisions
Pith reviewed 2026-06-29 12:27 UTC · model grok-4.3
The pith
AI systems create an illusion of opting in consequential decisions by weakening the agency needed for genuine choice.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
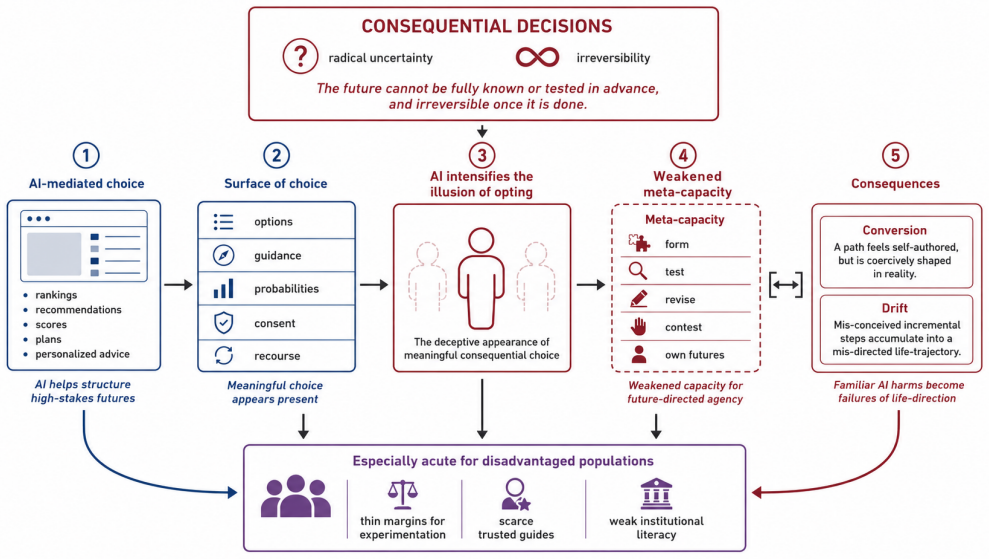
Current AI systems raise the ethical problem of the illusion of opting, where the appearance of consequential choice masks weakened agency. Rather than optimizing given ends, AI should be assessed by whether it protects and cultivates meta-capacity—the socially scaffolded ability to form, contest, revise, and own means and ends. This reframing calls for three normative imperatives in AI-mediated decisions: existential honesty acknowledging prediction limits, ecological rationality situating guidance in lived ecologies, and counterfactual reparation repairing foreclosed alternatives.
What carries the argument
The illusion of opting: the deceptive appearance of meaningful consequential choice while the agency needed to become genuinely capable of choosing is weakened.
If this is right
- AI systems should acknowledge the limits of their predictions rather than presenting choices as settled.
- Guidance from AI must be situated within the heterogeneous lived ecologies of users.
- AI-mediated decisions that fail should include mechanisms to repair foreclosed alternatives.
- Evaluation of AI is especially urgent for disadvantaged populations least able to absorb costs of misdirected behavior.
Where Pith is reading between the lines
- Systems designed with these imperatives might reduce long-term regret in users by preserving alternative paths.
- This framing could extend to non-AI automated systems like bureaucratic algorithms that limit personal agency.
- Empirical tests could measure reported sense of agency before and after interacting with AI decision aids.
Load-bearing premise
Ullmann-Margalit's concept of opting as transformative, irrevocable, and shadowed by foreclosed alternatives applies directly to AI-mediated decisions and identifies a gap not addressed by existing AI ethics.
What would settle it
A study showing that users retain full capacity for transformative choice and experience no weakening of agency when using AI for consequential decisions would challenge the existence of the illusion.
Figures
read the original abstract
Drawing on Ullmann-Margalit's concept of opting (transformative, irrevocable, and shadowed by foreclosed alternatives), we show that current AI systems raise a profound ethical problem that existing AI ethics has not fully captured: the illusion of opting, in which persons and groups encounter the deceptive appearance of meaningful consequential choice while the agency needed to become genuinely capable of choosing is weakened. Against approaches that treat AI primarily as an optimizer of already given ends, we argue that AI systems should be evaluated by whether they protect and cultivate meta-capacity against the illusion of opting: the socially and institutionally scaffolded agentive capacity through which means and ends can be formed, contested, revised, and owned. This reframing is especially urgent for disadvantaged populations, who are least able to absorb the costs of the illusion of opting when AI-mediated pathways misdirect behavior and action. We propose three normative imperatives for AI-mediated consequential decisions: existential honesty, which acknowledges the limits of prediction; ecological rationality, which situates guidance within heterogeneous lived ecologies; and counterfactual reparation, which acknowledges and repairs foreclosed alternatives when AI-mediated decision-making pathways fail.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that current AI systems in consequential decisions create an 'illusion of opting,' where individuals face the deceptive appearance of meaningful choice while their agency is weakened, drawing on Ullmann-Margalit's concept of opting. It argues that AI should be evaluated by whether they protect 'meta-capacity'—the scaffolded capacity to form, contest, revise, and own means and ends—and proposes three normative imperatives: existential honesty, ecological rationality, and counterfactual reparation, with urgency for disadvantaged populations.
Significance. If the reframing is successful, it provides a new normative framework for AI ethics that moves beyond optimizing given ends to safeguarding the conditions for genuine agency in decision-making, potentially leading to more robust design principles for AI in high-stakes areas.
major comments (2)
- [Abstract] The applicability of Ullmann-Margalit's opting concept (transformative, irrevocable, shadowed by foreclosed alternatives) to AI-mediated decisions is asserted without addressing potential mismatches, such as the often revocable or non-transformative nature of AI recommendations; this is load-bearing for the central claim of a new ethical problem, and a concrete test would be to identify specific AI use cases that satisfy the original criteria.
- [Abstract] The claim that existing AI ethics has not fully captured the illusion of opting is made without reference to particular approaches or literature, risking an overstatement of novelty that underpins the need for the proposed reframing.
minor comments (1)
- The abstract is conceptually dense; expanding on how the three imperatives operationalize the protection of meta-capacity would improve accessibility.
Simulated Author's Rebuttal
We thank the referee for their insightful comments, which identify key areas where the manuscript's central claims require further substantiation. We address each point below and indicate revisions to strengthen the argument.
read point-by-point responses
-
Referee: [Abstract] The applicability of Ullmann-Margalit's opting concept (transformative, irrevocable, shadowed by foreclosed alternatives) to AI-mediated decisions is asserted without addressing potential mismatches, such as the often revocable or non-transformative nature of AI recommendations; this is load-bearing for the central claim of a new ethical problem, and a concrete test would be to identify specific AI use cases that satisfy the original criteria.
Authors: We acknowledge the need for explicit engagement with potential mismatches. Although AI outputs are often technically revocable, the illusion of opting emerges through cumulative path dependencies that render alternatives practically foreclosed, especially for disadvantaged groups. We will revise the manuscript to include a dedicated subsection with concrete use cases (e.g., AI in recidivism prediction and automated hiring) that map onto Ullmann-Margalit's criteria by showing how initial AI-mediated pathways produce transformative effects and shadow viable alternatives. revision: yes
-
Referee: [Abstract] The claim that existing AI ethics has not fully captured the illusion of opting is made without reference to particular approaches or literature, risking an overstatement of novelty that underpins the need for the proposed reframing.
Authors: The referee correctly identifies that the abstract does not cite specific literature to support the novelty claim. While the body of the manuscript contrasts the proposed framework with optimization-based approaches, we will revise the abstract and introduction to explicitly reference key works in AI ethics (e.g., on value alignment, algorithmic fairness, and autonomy) and delineate how they presuppose given ends rather than safeguarding meta-capacity against the illusion of opting. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper advances a normative reframing by applying Ullmann-Margalit's external concept of opting to AI-mediated decisions and introducing 'illusion of opting' and 'meta-capacity' as interpretive terms within that argument. No equations, fitted parameters, predictions, or self-citations appear in the provided text. The derivation chain consists of conceptual application and prescriptive imperatives that do not reduce to the inputs by construction under any of the enumerated patterns. The central claim remains an independent interpretive proposal rather than a self-referential reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Ullmann-Margalit's opting concept applies directly to AI-mediated consequential decisions
invented entities (2)
-
meta-capacity
no independent evidence
-
illusion of opting
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Is Meaningful Human Control Over Personalised AI Assistants Possible? Ethical Design Requirements for the New Generation of Artificially Intelligent Agents.Philos- ophy & Technology, 38. Laukkonen, R.; Krier, S.; Bakalar, C.; Chandaria, S.; Kringelbach, M.; Elwood, A.; Ford, D.; Rosas, F.; Bohacek, M.; Franklin, M.; Toma ˇsev, N.; Chan, S.; Rieser, V .; P...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
In Proceedings of the 2024 ACM Conference on Fairness, Ac- countability, and Transparency
Should Users Trust Advanced AI Assistants? Justi- fied Trust as a Function of Competence and Alignment. In Proceedings of the 2024 ACM Conference on Fairness, Ac- countability, and Transparency. Marusich, L. R.; Bakdash, J. Z.; Zhou, Y .; and Kantarcioglu, M. 2024. Using AI Uncertainty Quantification to Improve Human Decision-Making. ArXiv:2309.10852. May...
-
[3]
Towards Understanding Sycophancy in Language Models
On Faithfulness and Factuality in Abstractive Sum- marization. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 1906–1919. Association for Computational Linguistics. Mittelstadt, B.; Russell, C.; and Wachter, S. 2019. Explain- ing Explanations in AI. InProceedings of the Conference on Fairness, Accountability, and...
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[4]
Vasconcelos, H.; J¨orke, M.; Grunde-McLaughlin, M.; Ger- stenberg, T.; Bernstein, M
New York: ACM. Vasconcelos, H.; J¨orke, M.; Grunde-McLaughlin, M.; Ger- stenberg, T.; Bernstein, M. S.; and Krishna, R. 2023. Ex- planations Can Reduce Overreliance on AI Systems dur- ing Decision-Making.Proceedings of the ACM on Human- Computer Interaction, 7(CSCW1): Article 129. Venkatasubramanian, S.; and Alfano, M. 2020. The Philo- sophical Basis of A...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.