Provably Efficient Personalized Multi-Objective Bandits with Proactive Conversational Queries
Pith reviewed 2026-06-27 18:25 UTC · model grok-4.3
The pith
Proactive conversational queries accelerate preference estimation and improve regret scaling in personalized multi-objective bandits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
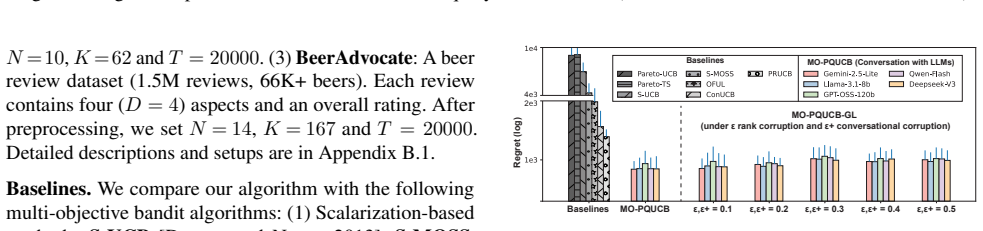
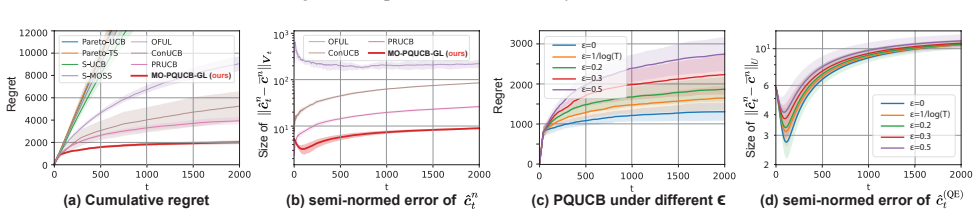
Proactive queries, when integrated via shift-invariant regularization in the MO-PQUCB algorithm, accelerate preference estimation and produce improved regret scaling over prior preference-aware multi-objective multi-armed bandit methods; under corrupted queries the robust estimator achieves near-optimal performance when corruption is sparse.
What carries the argument
MO-PQUCB algorithm, which integrates query-based preference anchoring with bandit feedback through shift-invariant regularization and dual-exploration UCB.
If this is right
- Preference learning converges faster because queries supply direct signals instead of requiring inference from reward observations alone.
- Overall regret scales better than in prior methods that entangle preference learning with reward exploration.
- The shift-invariance barrier is overcome, allowing unique recovery of preference parameters.
- Sparse corruptions in queries can be handled without losing near-optimal guarantees.
Where Pith is reading between the lines
- The same anchoring technique could be tested in other sequential decision settings where partial preference information arrives through natural language.
- Interface designs that prompt users for queries at specific times might further reduce the number of arm pulls needed for personalization.
- If the Plackett-Luce assumption is relaxed to other choice models, the regularization step may require adjustment to preserve the regret improvement.
Load-bearing premise
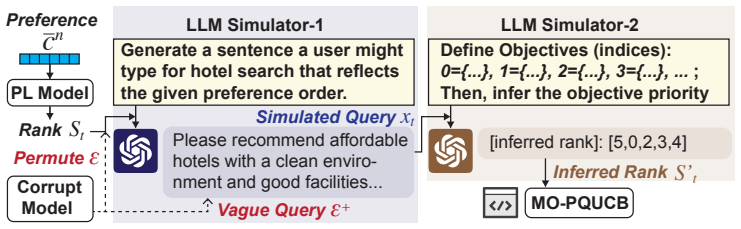
User queries provide structured, unbiased preference signals that can be accurately modeled by the Plackett-Luce subset choice model and integrated via shift-invariant regularization without distorting the underlying reward estimation.
What would settle it
A simulation or real-user experiment showing that regret does not improve when queries are added, or that the robust estimator fails to achieve near-optimal performance even with sparse corruptions.
Figures



read the original abstract
Personalized decision-making in multi-objective bandits requires learning user-specific trade-offs among competing objectives. Since arm utility depends on both unknown rewards and unknown preferences, existing methods infer preferences only from utility feedback, entangling preference learning with reward exploration. In practice, however, users often reveal their priorities through proactive conversational queries (e.g., "cheap and clean hotel"), yet this structured signal is not leveraged. We formalize a proactive query-based framework in which user queries provide structured preference signals. Modeling these signals via a Plackett-Luce subset choice model, we show that query-only learning is insufficient due to a fundamental shift-invariance barrier. To resolve this, we introduce MO-PQUCB, a hybrid algorithm that integrates query-based preference anchoring with bandit feedback through shift-invariant regularization and dual-exploration UCB. We prove that proactive queries accelerate preference estimation and yield improved regret scaling over prior preference-aware MO-MAB methods. Under corrupted queries, we further characterize statistical limits and design a robust estimator achieving near-optimal performance when the corruption is sparse. Experiments validate both theoretical and practical gains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formalizes a proactive query-based framework for personalized multi-objective bandits, where user queries supply structured preference signals modeled by the Plackett-Luce subset choice model. It identifies a shift-invariance barrier that prevents query-only learning from fully resolving preferences and introduces the MO-PQUCB algorithm, which combines query-based preference anchoring with standard bandit feedback through shift-invariant regularization and dual-exploration UCB. The central claims are that proactive queries yield improved regret scaling relative to prior preference-aware MO-MAB methods, and that a robust estimator achieves near-optimal performance under sparse query corruption. Experiments are said to validate both the theoretical improvements and practical gains.
Significance. If the stated regret bounds and robustness results hold under the given modeling assumptions, the work provides a concrete way to leverage conversational signals that are already available in many recommendation and decision-making interfaces. The hybrid regularization approach and the characterization of statistical limits under corruption are technically substantive extensions of existing preference-aware bandit literature. The contribution is conditional on the Plackett-Luce modeling choice but, within that scope, appears to deliver a measurable improvement in sample efficiency for preference estimation.
minor comments (2)
- [Abstract] Abstract: the phrase 'improved regret scaling' is used without stating the precise dependence on the number of objectives, query budget, or corruption fraction; adding the leading terms of the bound would allow readers to immediately compare against prior work.
- The weakest modeling assumption (Plackett-Luce subset choice plus shift-invariance) is stated clearly but its sensitivity is not quantified; a short paragraph or remark on what happens when the choice model is mildly misspecified would strengthen the practical interpretation.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work on proactive query-based personalized multi-objective bandits and the recommendation for minor revision. No specific major comments were provided in the report.
Circularity Check
No significant circularity
full rationale
The paper formalizes a proactive query framework, adopts the Plackett-Luce model for preference signals, identifies a shift-invariance issue, and introduces MO-PQUCB with shift-invariant regularization to derive improved regret bounds. These steps rely on new modeling assumptions and algorithm design rather than any self-definitional reduction, fitted parameter renamed as prediction, or load-bearing self-citation chain. No equations or claims in the abstract reduce a derived result to its own inputs by construction; the central guarantees are conditional on the stated model and are presented as independent theoretical contributions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Plackett-Luce subset choice model accurately represents structured preference signals from proactive queries
Reference graph
Works this paper leans on
-
[1]
International Conference on Frontiers in Handwriting Recognition , pages=
Real-time segmentation of on-line handwritten arabic script , author=. International Conference on Frontiers in Handwriting Recognition , pages=. 2014 , organization=
2014
-
[2]
International Conference of Soft Computing and Pattern Recognition , pages=
Fast classification of handwritten on-line Arabic characters , author=. International Conference of Soft Computing and Pattern Recognition , pages=. 2014 , organization=
2014
-
[3]
Estimate and Replace: A Novel Approach to Integrating Deep Neural Networks with Existing Applications , author=. arXiv preprint arXiv:1804.09028 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
2019 , publisher=
Probability: theory and examples , author=. 2019 , publisher=
2019
-
[5]
SIAM journal on computing , volume=
The nonstochastic multiarmed bandit problem , author=. SIAM journal on computing , volume=. 2002 , publisher=
2002
-
[6]
1999 , publisher=
Elements of information theory , author=. 1999 , publisher=
1999
-
[7]
Machine learning , volume=
Finite-time analysis of the multiarmed bandit problem , author=. Machine learning , volume=. 2002 , publisher=
2002
-
[8]
2018 , publisher=
High-dimensional probability: An introduction with applications in data science , author=. 2018 , publisher=
2018
-
[9]
Euler--Lehmer constants and a conjecture of Erd
Murty, M Ram and Saradha, N , journal=. Euler--Lehmer constants and a conjecture of Erd. 2010 , publisher=
2010
-
[10]
The American Mathematical Monthly , volume=
Partial sums of the harmonic series , author=. The American Mathematical Monthly , volume=. 1971 , publisher=
1971
-
[11]
Advances in Neural Information Processing Systems , volume=
Improved algorithms for linear stochastic bandits , author=. Advances in Neural Information Processing Systems , volume=
-
[12]
Proceedings of the 19th international conference on World wide web , pages=
A contextual-bandit approach to personalized news article recommendation , author=. Proceedings of the 19th international conference on World wide web , pages=
-
[13]
Bulletin of the American Mathematical Society , volume=
Eigenvalues, invariant factors, highest weights, and Schubert calculus , author=. Bulletin of the American Mathematical Society , volume=
-
[14]
On Upper-Confidence Bound Policies for Non-Stationary Bandit Problems
On upper-confidence bound policies for non-stationary bandit problems , author=. arXiv preprint arXiv:0805.3415 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
International Conference on Machine Learning , pages=
Multi-objective bandits: Optimizing the generalized gini index , author=. International Conference on Machine Learning , pages=. 2017 , organization=
2017
-
[16]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
A combinatorial-bandit algorithm for the online joint bid/budget optimization of pay-per-click advertising campaigns , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[17]
Proceedings of the Web Conference , pages=
Stochastic bandits for multi-platform budget optimization in online advertising , author=. Proceedings of the Web Conference , pages=
-
[18]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Online evaluation of audiences for targeted advertising via bandit experiments , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[19]
Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , pages=
Online context-aware recommendation with time varying multi-armed bandit , author=. Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , pages=
-
[20]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
A hybrid bandit framework for diversified recommendation , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[21]
Machine Learning for Healthcare Conference , pages=
Contextual bandits for adapting treatment in a mouse model of de novo carcinogenesis , author=. Machine Learning for Healthcare Conference , pages=. 2018 , organization=
2018
-
[22]
Life , volume=
A contextual-bandit-based approach for informed decision-making in clinical trials , author=. Life , volume=. 2022 , publisher=
2022
-
[23]
The International Joint Conference on Neural Networks , pages=
Designing multi-objective multi-armed bandits algorithms: A study , author=. The International Joint Conference on Neural Networks , pages=. 2013 , organization=
2013
-
[24]
Proceedings of the ACM Conference on Recommender Systems , pages=
A pareto-efficient algorithm for multiple objective optimization in e-commerce recommendation , author=. Proceedings of the ACM Conference on Recommender Systems , pages=
-
[25]
Proceedings of the International Joint Conference on Artificial Intelligence , pages=
Multi-objective generalized linear bandits , author=. Proceedings of the International Joint Conference on Artificial Intelligence , pages=
-
[26]
Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , pages=
Bandit based optimization of multiple objectives on a music streaming platform , author=. Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , pages=
-
[27]
IEEE Transactions on Neural Networks and Learning Systems , volume=
Covariance matrix adaptation for multiobjective multiarmed bandits , author=. IEEE Transactions on Neural Networks and Learning Systems , volume=. 2018 , publisher=
2018
-
[28]
International Conference on Artificial Intelligence and Statistics , pages=
Multi-objective contextual bandit problem with similarity information , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2018 , organization=
2018
-
[29]
Proceedings of the ACM Conference on Recommender Systems , pages=
Fairness-aware group recommendation with pareto-efficiency , author=. Proceedings of the ACM Conference on Recommender Systems , pages=
-
[30]
Proceedings of the ACM Conference on Recommender Systems , pages=
Pareto-efficient hybridization for multi-objective recommender systems , author=. Proceedings of the ACM Conference on Recommender Systems , pages=
-
[31]
Proceedings of the ACM Conference on Recommender Systems , pages=
Optimizing multiple objectives in collaborative filtering , author=. Proceedings of the ACM Conference on Recommender Systems , pages=
-
[32]
International Conference on Algorithmic Learning Theory , pages=
Tuning bandit algorithms in stochastic environments , author=. International Conference on Algorithmic Learning Theory , pages=. 2007 , organization=
2007
-
[33]
Conference on Learning Theory , pages=
Minimax policies for adversarial and stochastic bandits , author=. Conference on Learning Theory , pages=
-
[34]
IEEE Symposium on Adaptive Dynamic Programming and Reinforcement Learning , pages=
Pareto upper confidence bounds algorithms: an empirical study , author=. IEEE Symposium on Adaptive Dynamic Programming and Reinforcement Learning , pages=
-
[35]
, author=
Knowledge Gradient for Multi-objective Multi-armed Bandit Algorithms. , author=. International Conference on Agents and Artificial Intelligence , pages=
-
[36]
Operations Research , volume=
The knowledge gradient algorithm for a general class of online learning problems , author=. Operations Research , volume=. 2012 , publisher=
2012
-
[37]
IEEE Symposium on Adaptive Dynamic Programming and Reinforcement Learning , pages=
Annealing-pareto multi-objective multi-armed bandit algorithm , author=. IEEE Symposium on Adaptive Dynamic Programming and Reinforcement Learning , pages=. 2014 , organization=
2014
-
[38]
International Joint Conference on Neural Networks , pages=
Multi-objective -armed bandits , author=. International Joint Conference on Neural Networks , pages=. 2014 , organization=
2014
-
[39]
, author=
X-Armed Bandits. , author=. Journal of Machine Learning Research , volume=
-
[40]
International Conference on Machine Learning , pages=
Pareto regret analyses in multi-objective multi-armed bandit , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[41]
, author=
Learning Multi-Objective Rewards and User Utility Function in Contextual Bandits for Personalized Ranking. , author=. Proceedings of the International Joint Conference on Artificial Intelligence , volume=
-
[42]
IEEE Transactions on Systems, Man, and Cybernetics: Systems , volume=
Multiobjective reinforcement learning: A comprehensive overview , author=. IEEE Transactions on Systems, Man, and Cybernetics: Systems , volume=. 2014 , publisher=
2014
-
[43]
Structural and Multidisciplinary Optimization , volume=
Adaptive weighted sum method for multiobjective optimization: a new method for Pareto front generation , author=. Structural and Multidisciplinary Optimization , volume=. 2006 , publisher=
2006
-
[44]
Machine Learning , volume=
Multi-objective multi-armed bandit with lexicographically ordered and satisficing objectives , author=. Machine Learning , volume=. 2021 , publisher=
2021
-
[45]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Hierarchize Pareto Dominance in Multi-Objective Stochastic Linear Bandits , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[46]
2005 , publisher=
Multicriteria optimization , author=. 2005 , publisher=
2005
-
[47]
Advances in neural information processing systems , volume=
Adversarial attacks on stochastic bandits , author=. Advances in neural information processing systems , volume=
-
[48]
, author=
Thompson Sampling for Multi-Objective Multi-Armed Bandits Problem. , author=. ESANN , year=
-
[49]
International Conference on Artificial Intelligence and Statistics , year=
Stochastic linear bandits robust to adversarial attacks , author=. International Conference on Artificial Intelligence and Statistics , year=
-
[50]
International Conference on Artificial Intelligence and Statistics , year=
A simple approach for non-stationary linear bandits , author=. International Conference on Artificial Intelligence and Statistics , year=
-
[51]
Advances in Neural Information Processing Systems , volume=
Efficient batched algorithm for contextual linear bandits with large action space via soft elimination , author=. Advances in Neural Information Processing Systems , volume=
-
[52]
IEEE Wireless Communications Letters , volume=
Piecewise-stationary multi-objective multi-armed bandit with application to joint communications and sensing , author=. IEEE Wireless Communications Letters , volume=. 2023 , publisher=
2023
-
[53]
Proceedings of the Web Conference 2021 , pages=
Personalized approximate pareto-efficient recommendation , author=. Proceedings of the Web Conference 2021 , pages=
2021
-
[54]
Proceedings of the 23rd International Conference on Autonomous Agents and Multiagent Systems , pages=
Interactively Learning the User's Utility for Best-Arm Identification in Multi-Objective Multi-Armed Bandits , author=. Proceedings of the 23rd International Conference on Autonomous Agents and Multiagent Systems , pages=
-
[55]
Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics , pages=
Contextual bandits with linear payoff functions , author=. Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics , pages=. 2011 , organization=
2011
-
[56]
Advances in neural information processing systems , volume=
Nearly optimal algorithms for linear contextual bandits with adversarial corruptions , author=. Advances in neural information processing systems , volume=
-
[57]
Advances in Neural Information Processing Systems , volume=
Weighted linear bandits for non-stationary environments , author=. Advances in Neural Information Processing Systems , volume=
-
[58]
Conference on Learning Theory , pages=
Nearly minimax optimal reinforcement learning for linear mixture markov decision processes , author=. Conference on Learning Theory , pages=. 2021 , organization=
2021
-
[59]
Journal of Machine Learning Research , volume=
Profile-based bandit with unknown profiles , author=. Journal of Machine Learning Research , volume=
-
[60]
arXiv preprint arXiv:2502.13457 , year=
Provably Efficient Multi-Objective Bandit Algorithms under Preference-Centric Customization , author=. arXiv preprint arXiv:2502.13457 , year=
-
[61]
Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining , pages=
Towards conversational recommender systems , author=. Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining , pages=
-
[62]
Proceedings of the web conference 2020 , pages=
Conversational contextual bandit: Algorithm and application , author=. Proceedings of the web conference 2020 , pages=
2020
-
[63]
Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
Comparison-based conversational recommender system with relative bandit feedback , author=. Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
-
[64]
Proceedings of the ACM Web Conference 2022 , pages=
Knowledge-aware conversational preference elicitation with bandit feedback , author=. Proceedings of the ACM Web Conference 2022 , pages=
2022
-
[65]
Advances in neural information processing systems , volume=
Stochastic multi-armed-bandit problem with non-stationary rewards , author=. Advances in neural information processing systems , volume=
-
[66]
The 22nd International Conference on Artificial Intelligence and Statistics , pages=
Learning to optimize under non-stationarity , author=. The 22nd International Conference on Artificial Intelligence and Statistics , pages=. 2019 , organization=
2019
-
[67]
Algorithmic Learning Theory , pages=
PAC battling bandits in the plackett-luce model , author=. Algorithmic Learning Theory , pages=. 2019 , organization=
2019
-
[68]
The method of paired comparisons , author=
Rank analysis of incomplete block designs: I. The method of paired comparisons , author=. Biometrika , volume=. 1952 , publisher=
1952
-
[69]
International Conference on Machine Learning , pages=
Principled reinforcement learning with human feedback from pairwise or k-wise comparisons , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[70]
Advances in neural information processing systems , volume=
Deep reinforcement learning from human preferences , author=. Advances in neural information processing systems , volume=
-
[71]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[72]
Advances in Neural Information Processing Systems , volume=
Is RLHF more difficult than standard RL? a theoretical perspective , author=. Advances in Neural Information Processing Systems , volume=
-
[73]
Forty-first International Conference on Machine Learning , year=
Iterative preference learning from human feedback: Bridging theory and practice for rlhf under kl-constraint , author=. Forty-first International Conference on Machine Learning , year=
-
[74]
Journal of Machine Learning Research , volume=
Estimation from pairwise comparisons: Sharp minimax bounds with topology dependence , author=. Journal of Machine Learning Research , volume=
-
[75]
Advances in Neural Information Processing Systems , volume=
Minimax-optimal inference from partial rankings , author=. Advances in Neural Information Processing Systems , volume=
-
[76]
Advances in Neural Information Processing Systems , volume=
Byzantine spectral ranking , author=. Advances in Neural Information Processing Systems , volume=
-
[77]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Robust Reinforcement Learning from Corrupted Human Feedback , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[78]
Foundations of computational mathematics , volume=
User-friendly tail bounds for sums of random matrices , author=. Foundations of computational mathematics , volume=. 2012 , publisher=
2012
-
[79]
Combinatorics, Probability and Computing , volume=
A large-deviation inequality for vector-valued martingales , author=. Combinatorics, Probability and Computing , volume=
-
[80]
LaMDA: Language Models for Dialog Applications
Lamda: Language models for dialog applications , author=. arXiv preprint arXiv:2201.08239 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.