X-Mind: Efficient Visual Chain-of-Thought via Predictive World Model for End-to-End Driving
Pith reviewed 2026-06-30 09:46 UTC · model grok-4.3
The pith
X-Mind internalizes a predictive world model as visual chain-of-thought so driving policies must imagine future states before selecting actions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
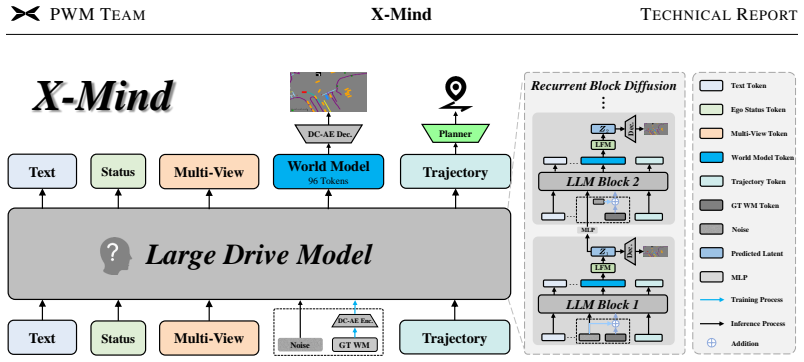
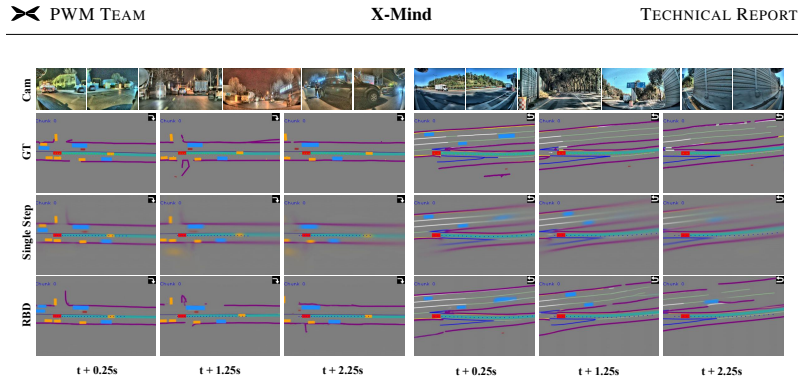
Rather than attaching a predictive world model as an external auxiliary module, X-Mind embeds it as the Visual Chain-of-Thought: the model must first produce a compact future sketch before emitting an action. The sketch fuses BEV layout with abstract driving priors and is generated at 96 tokens via DC-AE compression and recurrent block diffusion, so that the policy is constrained to reason over future consequences within one forward pass and without cascaded latency.
What carries the argument
Visual Chain-of-Thought realized as an abstract BEV-plus-priors sketch, compressed by Deep Compression Autoencoder to 96 tokens and produced by recurrent block diffusion folded into the backbone.
If this is right
- The driving policy must simulate environmental evolution before acting, making decisions aware of future consequences.
- Future prediction adds no external latency because the 96-token rollout is generated inside the single model forward pass.
- Competitive end-to-end performance is achieved while deploying the reasoning directly on resource-constrained vehicle platforms.
- Large-scale VLA models can incorporate predictive reasoning without prohibitive compute or cascaded modules.
Where Pith is reading between the lines
- The same internal-sketch approach could be tested on other embodied control tasks where reactive policies fail on dynamic environments.
- If the compressed sketch loses critical details in rare events, an ablation that increases token count while keeping latency fixed would isolate the information bottleneck.
- The method suggests that any VLA model could gain foresight by inserting a similar compressed future-generation step before action output.
Load-bearing premise
The abstract sketch and recurrent diffusion together preserve enough future dynamics to improve policy robustness without introducing critical errors or hidden latency.
What would settle it
A controlled test showing that X-Mind produces more collisions or near-misses than a reactive baseline in scenarios that require accurate long-horizon prediction would falsify the claim that the internalized rollout improves grounding.
Figures



read the original abstract
Predicting future states is essential for autonomous agents, yet current Vision-Language-Action (VLA) models fundamentally lack this capability, relying instead on reactive perception-action mapping. While integrating Predictive World Models (PWMs) addresses this gap, existing approaches either incur prohibitive cascaded latency or act as shallow terminal tasks that fail to deeply embed forward-looking reasoning. To endow VLA models with this reasoning capability, we propose X-Mind. Rather than treating PWMs as an external auxiliary module, this framework internalizes them as the Visual Chain-of-Thought (Visual CoT). By enforcing a world rollout prior to action, the model is constrained to imagine future evolution first, yielding a driving policy that is robustly grounded in environmental dynamics and aware of the future consequences its actions will unfold. The challenge here is efficiency, and we tackle it on two fronts. First, we introduce a compact representation of visual thinking: an abstract sketch that fuses a Bird's-Eye-View (BEV) layout with abstract driving priors (e.g., navigation intents and traffic rules). Rather than rolling out dense future frames, the model reasons over this sketch as a mental canvas; aided by a Deep Compression Autoencoder (DC-AE), a 12-frame future rollout is reduced to merely 96 tokens, alleviating the long-context computational bottleneck. Second, to accelerate generation further, we propose a recurrent block diffusion scheme that unrolls the denoising steps across the layers of the large drive model, folding iterative refinement into the backbone's one forward pass. Trained and validated on large-scale real-world data, X-Mind achieves competitive end-to-end driving performance, which makes it a highly practical, low-latency solution that successfully deploys large-scale cognitive reasoning directly onto resource-constrained vehicle platforms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes X-Mind, a framework that internalizes Predictive World Models as Visual Chain-of-Thought within Vision-Language-Action models for end-to-end driving. It introduces a compact BEV sketch fusing layout with driving priors, compressed via Deep Compression Autoencoder (DC-AE) to 96 tokens for 12-frame rollouts, and a recurrent block diffusion scheme to fold denoising into a single backbone forward pass. The central claim is that enforcing world rollout prior to action yields a driving policy robustly grounded in environmental dynamics, achieving competitive performance with low latency on resource-constrained platforms when trained and validated on large-scale real-world data.
Significance. If the empirical claims hold, the work would offer a practical advance in embedding forward-looking predictive reasoning into deployable driving policies without cascaded latency costs. The specific efficiency mechanisms (96-token budget and recurrent diffusion) directly target bottlenecks in scaling world models for real-time vehicle use, potentially improving robustness over purely reactive VLA baselines.
major comments (2)
- [Abstract] Abstract: The abstract asserts competitive performance and low latency but supplies no quantitative metrics, baselines, ablation results, or error analysis; central claims rest on unshown validation. This prevents assessment of whether the 96-token DC-AE compression and recurrent diffusion preserve sufficient future dynamics.
- [Method] Method (recurrent block diffusion and DC-AE sections): The description of how the recurrent scheme unrolls denoising across layers and reduces a 12-frame rollout to 96 tokens lacks any reported prediction-error metrics or ablation on rollout accuracy; without these, it is impossible to verify the claim that the internalized Visual CoT improves policy robustness without introducing critical errors.
Simulated Author's Rebuttal
We appreciate the referee's comments on the abstract and method sections. We will revise the manuscript to include more quantitative details to better support our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract asserts competitive performance and low latency but supplies no quantitative metrics, baselines, ablation results, or error analysis; central claims rest on unshown validation. This prevents assessment of whether the 96-token DC-AE compression and recurrent diffusion preserve sufficient future dynamics.
Authors: We agree with the observation that the abstract lacks specific quantitative metrics. The full paper contains extensive experimental results, including performance comparisons and ablations. To address this concern directly, we will revise the abstract to include key metrics such as end-to-end driving success rates, latency figures, and baseline comparisons from our large-scale real-world evaluations. revision: yes
-
Referee: [Method] Method (recurrent block diffusion and DC-AE sections): The description of how the recurrent scheme unrolls denoising across layers and reduces a 12-frame rollout to 96 tokens lacks any reported prediction-error metrics or ablation on rollout accuracy; without these, it is impossible to verify the claim that the internalized Visual CoT improves policy robustness without introducing critical errors.
Authors: The method section provides the architectural details of the recurrent block diffusion and DC-AE. While the primary evaluation is on the end-to-end driving task, we recognize the value of including prediction-error metrics for the world model. We will add ablations and error analysis on the rollout accuracy in the revised manuscript to demonstrate that the Visual CoT does not introduce critical errors and enhances robustness. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and context describe an architectural proposal for internalizing predictive world models as Visual CoT via BEV sketches, DC-AE compression to 96 tokens, and recurrent block diffusion, with a claim of competitive end-to-end performance on real-world data. No equations, parameter-fitting procedures, self-citations, or derivation steps are supplied that reduce any prediction or result to its own inputs by construction. The central claims rest on stated design choices and empirical validation rather than self-referential definitions or fitted inputs renamed as predictions. This is the most common honest finding when no load-bearing circular steps can be quoted.
Axiom & Free-Parameter Ledger
free parameters (1)
- 96-token budget for 12-frame rollout
axioms (1)
- domain assumption Abstract sketch plus driving priors suffice to represent future evolution for policy improvement
Reference graph
Works this paper leans on
-
[1]
Junyu Chen, Han Cai, Junsong Chen, Enze Xie, Shang Yang, Haotian Tang, Muyang Li, Yao Lu, and Song Han. Deep compression autoencoder for efficient high-resolution diffusion models.ArXiv, abs/2410.10733, 2024
-
[2]
Haoyu Fu, Diankun Zhang, Zongchuang Zhao, Jianfeng Cui, Dingkang Liang, Chong Zhang, Dingyuan Zhang, Hongwei Xie, Bing Wang, and Xiang Bai. Orion: A holistic end-to-end autonomous driving framework by vision-language instructed action generation.2025 IEEE/CVF International Conference on Computer Vision (ICCV), pages 24823–24834, 2025. 12 PWM TEAMX-MindTEC...
2025
-
[3]
Magicdrive: Street view generation with diverse 3d geometry control.ArXiv, abs/2310.02601, 2023
Ruiyuan Gao, Kai Chen, Enze Xie, Lanqing Hong, Zhenguo Li, Dit-Yan Yeung, and Qiang Xu. Magicdrive: Street view generation with diverse 3d geometry control.ArXiv, abs/2310.02601, 2023
-
[4]
Stephen M. Kosslyn. Image and mind.HARVARD UNIVERSITY PRESS, 1980
1980
-
[5]
X-foresight: A joint vision-action causal forecasting network via predictive world modeling, 2026
Baolu Li, Jingyu Qian, Rui Guo, Yilun Chen, Hanpeng Liu, Yuanze Lin, Jun Zhou, Rui Liu, Willow Yang, Yutong Zheng, Zhenli Zhang, Te Gu, Zhuangzhuang Ding, Pengkun Zheng, Yu Zhang, and Xianming Liu. X-foresight: A joint vision-action causal forecasting network via predictive world modeling, 2026
2026
-
[6]
Jingyu Li, Junjie Wu, Dongnan Hu, Xiangkai Huang, Bin Sun, Zhihui Hao, XianPeng Lang, Xiatian Zhu, and Li Zhang. Sgdrive: Scene-to-goal hierarchical world cognition for autonomous driving.ArXiv, abs/2601.05640, 2026
-
[7]
DriveVLA-W0: World Models Amplify Data Scaling Law in Autonomous Driving
Yingyan Li, Shuyao Shang, Weisong Liu, Bing Zhan, Haochen Wang, Yu-Quan Wang, Yuntao Chen, Xiaoman Wang, Yasong An, Chufeng Tang, Lu Hou, Lue Fan, and Zhaoxiang Zhang. Drivevla-w0: World models amplify data scaling law in autonomous driving.ArXiv, abs/2510.12796, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
ReCogDrive: A Reinforced Cognitive Framework for End-to-End Autonomous Driving
Yongkang Li, Kaixin Xiong, Xiangyu Guo, Fang Li, Sixu Yan, Gangwei Xu, Lijun Zhou, Long Chen, Haiyang Sun, Bing Wang, Guang Chen, Hangjun Ye, Wenyu Liu, and Xinggang Wang. Recogdrive: A reinforced cognitive framework for end-to-end autonomous driving.ArXiv, abs/2506.08052, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.ArXiv, abs/2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[10]
4d driving scene generation with stereo forcing.arXiv preprint arXiv:2509.20251, 2025
Hao Lu, Zhuang Ma, Guangfeng Jiang, Wenhang Ge, Bohan Li, Yuzhan Cai, Wenzhao Zheng, Yun- peng Zhang, and Yingcong Chen. 4d driving scene generation with stereo forcing.arXiv preprint arXiv:2509.20251, 2025
-
[11]
Peebles and Saining Xie
William S. Peebles and Saining Xie. Scalable diffusion models with transformers.2023 IEEE/CVF International Conference on Computer Vision (ICCV), pages 4172–4182, 2022
2023
-
[12]
U-Net: Convolutional Networks for Biomedical Image Segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation.ArXiv, abs/1505.04597, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[13]
Drivelm: Driving withgraph visual question answering
Chonghao Sima, Katrin Renz, Kashyap Chitta, Li Chen, Hanxue Zhang, Chengen Xie, Jens Beiwenger, Ping Luo, Andreas Geiger, and Hongyang Li. Drivelm: Driving withgraph visual question answering. In European Conference on Computer Vision, 2025
2025
-
[14]
DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models
Xiaoyu Tian, Junru Gu, Bailin Li, Yicheng Liu, Chenxu Hu, Yang Wang, Kun Zhan, Peng Jia, Xianpeng Lang, and Hang Zhao. Drivevlm: The convergence of autonomous driving and large vision-language models.ArXiv, abs/2402.12289, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Shihao Wang, Zhiding Yu, Xiaohui Jiang, Shiyi Lan, Min Shi, Nadine Chang, Jan Kautz, Ying Li, and José M. Álvarez. Omnidrive: A holistic vision-language dataset for autonomous driving with counterfactual reasoning.2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 22442–22452, 2024
2025
-
[16]
Drivedreamer: Towards real-world-drive world models for autonomous driving
Xiaofeng Wang, Zheng Zhu, Guan Huang, Xinze Chen, Jiagang Zhu, and Jiwen Lu. Drivedreamer: Towards real-world-drive world models for autonomous driving. InEuropean Conference on Computer Vision, 2024
2024
-
[17]
Yu-Quan Wang, Jiawei He, Lue Fan, Hongxin Li, Yuntao Chen, and Zhaoxiang Zhang. Driving into the future: Multiview visual forecasting and planning with world model for autonomous driving.2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14749–14759, 2023
2024
-
[18]
Panacea: Panoramic and controllable video generation for autonomous driving.2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 6902– 6912, 2023
Yuqing Wen, Yucheng Zhao, Yingfei Liu, Fan Jia, Yanhui Wang, Chong Luo, Chi Zhang, Tiancai Wang, Xiaoyan Sun, and Xiangyu Zhang. Panacea: Panoramic and controllable video generation for autonomous driving.2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 6902– 6912, 2023
2024
-
[19]
Drivegpt4: Interpretable end-to-end autonomous driving via large language model
Zhenhua Xu, Yujia Zhang, Enze Xie, Zhen Zhao, Yong Guo, Kwan Yee K Wong, Zhenguo Li, and Hengshuang Zhao. Drivegpt4: Interpretable end-to-end autonomous driving via large language model. IEEE Robotics and Automation Letters, 2024
2024
-
[20]
Drivingsphere: Building a high-fidelity 4d world for closed-loop simulation.2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 27531–27541, 2024
Tianyi Yan, Dongming Wu, Wencheng Han, Junpeng Jiang, Xia Zhou, Kun Zhan, Cheng-Zhong Xu, and Jianbing Shen. Drivingsphere: Building a high-fidelity 4d world for closed-loop simulation.2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 27531–27541, 2024
2025
-
[21]
X-world: Controllable ego-centric multi-camera world models for scalable end-to-end driving, 2026
Chaoda Zheng, Sean Li, Jin-Sheng Deng, Zhennan Wang, Shijia Chen, Liqiang Xiao, Ziheng Chi, Hongbin Lin, Kangjie Chen, Boyang Wang, Yu Zhang, and Xianming Liu. X-world: Controllable ego-centric multi-camera world models for scalable end-to-end driving, 2026
2026
-
[22]
Zewei Zhou, Tianhui Cai, Seth Z. Zhao, Yun Zhang, Zhiyu Huang, Bolei Zhou, and Jiaqi Ma. Au- tovla: A vision-language-action model for end-to-end autonomous driving with adaptive reasoning and reinforcement fine-tuning.ArXiv, abs/2506.13757, 2025. 13
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.