Proprioceptive-visual correspondence enables self-other distinction in humanoid robots
Pith reviewed 2026-06-27 06:51 UTC · model grok-4.3
The pith
A humanoid robot learns to distinguish itself from others and build a 3D body model using only proprioceptive-visual correspondence without labels or kinematic models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
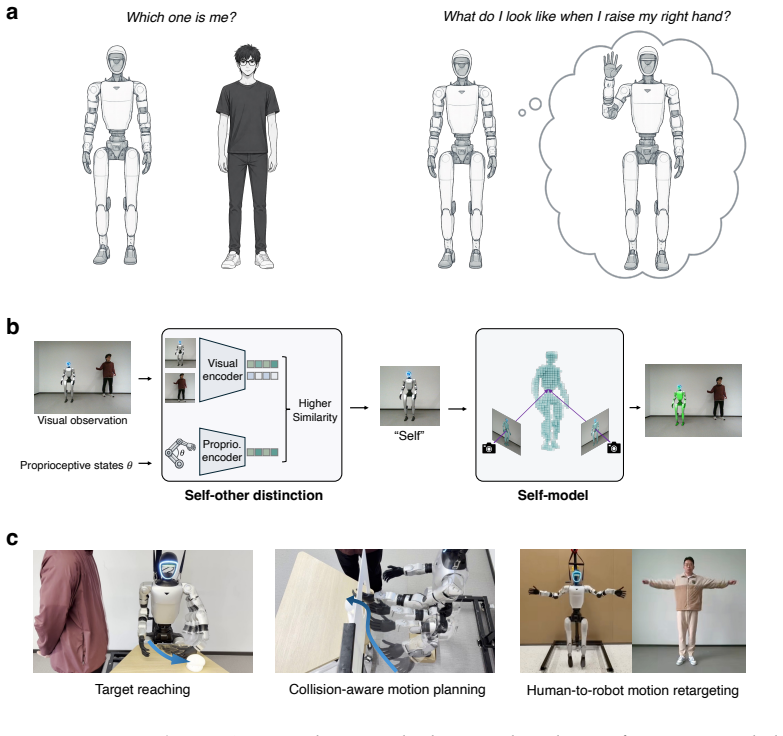
Proprioceptive-visual correspondence enables self-other distinction in humanoid robots without any identity labels or kinematic models. Once established, this distinction bootstraps a predictive self-model that maps joint configurations to three-dimensional body occupancy, capturing how the robot's body changes with action. In multi-agent scenes involving humans or morphologically identical robots, the system reliably identifies itself, learns the 3D self-model, and supports downstream tasks including target reaching, collision-aware motion planning, and human-to-robot motion retargeting.
What carries the argument
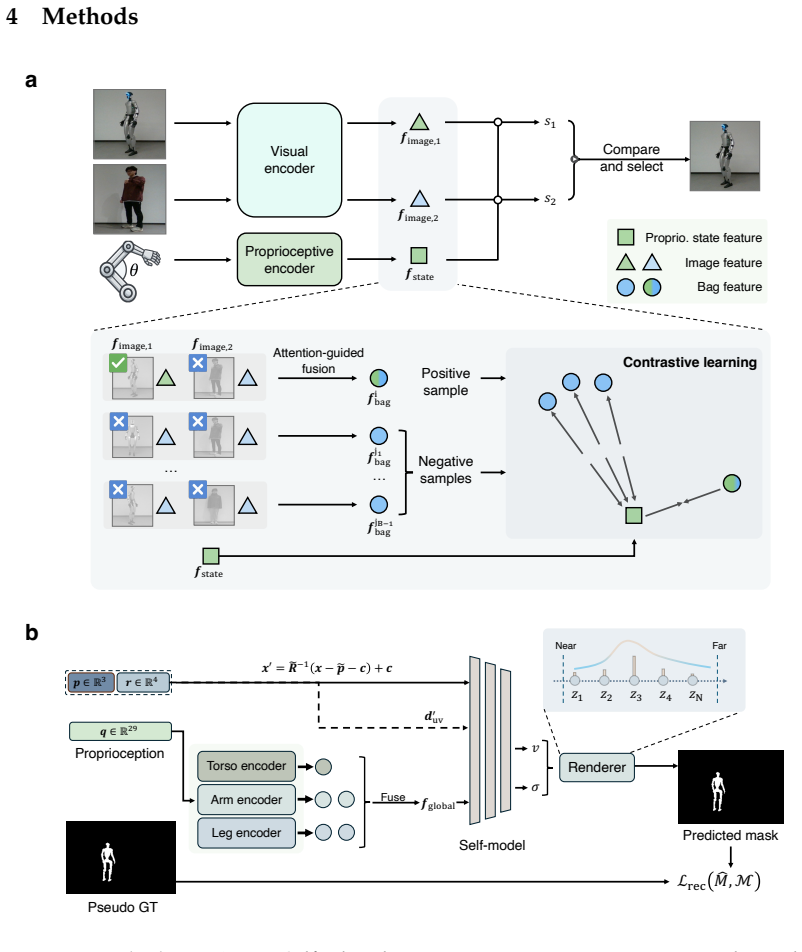
Proprioceptive-visual correspondence, the learned matching between proprioceptive joint states and visual observations, which separates self from others and then drives construction of the 3D occupancy model.
If this is right
- The robot identifies itself reliably in scenes containing humans or morphologically identical robots.
- It acquires a predictive 3D self-model linking joint configurations to body occupancy.
- The self-model supports target reaching, collision-aware motion planning, and human-to-robot motion retargeting.
Where Pith is reading between the lines
- The same correspondence principle could be tested with additional sensory channels such as touch or audio to strengthen self-model accuracy.
- Robots using this method might coordinate more effectively in teams by each maintaining an independent self-model.
- The approach could reduce reliance on manual calibration procedures when deploying robots in new environments.
Load-bearing premise
Reliable proprioceptive-visual correspondence can be learned and used to separate self from morphologically identical agents without additional supervision, kinematic priors, or identity signals.
What would settle it
A demonstration in which the robot, after training the correspondence, still cannot reliably separate its own body from an identical robot or human in the same workspace, or in which the resulting 3D occupancy predictions do not match actual body positions during movement.
Figures


read the original abstract
Distinguishing self from others is a prerequisite for social intelligence, yet humanoid robots that increasingly share workspaces with humans still lack this ability. Here we show that a humanoid robot can learn self-other distinction from proprioceptive-visual correspondence, without any identity labels or kinematic models. Once established, this distinction bootstraps a predictive self-model that maps joint configurations to three-dimensional body occupancy, capturing how the robot's body changes with action. In multi-agent scenes involving humans or morphologically identical robots, the system reliably identifies itself, learns a 3D self-model, and supports downstream tasks including target reaching, collision-aware motion planning, and human-to-robot motion retargeting. Together, these results outline a route toward bodily self-representation in robots that act and coordinate alongside others in shared physical environments. Project page: https://euron-zc.github.io/humanoid-self-model/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a humanoid robot can learn self-other distinction solely from proprioceptive-visual correspondence, without identity labels or kinematic models. This distinction then bootstraps a predictive self-model mapping joint configurations to 3D body occupancy. The system is shown to operate in multi-agent scenes with humans or morphologically identical robots, supporting downstream tasks including target reaching, collision-aware motion planning, and human-to-robot motion retargeting.
Significance. If the central empirical results hold, the work offers a label-free, correspondence-driven route to bodily self-representation that could scale to real shared workspaces. The avoidance of explicit supervision and kinematic priors, combined with demonstrations on identical morphologies, would mark a meaningful step beyond model-based or supervised self-modeling approaches in robotics.
major comments (1)
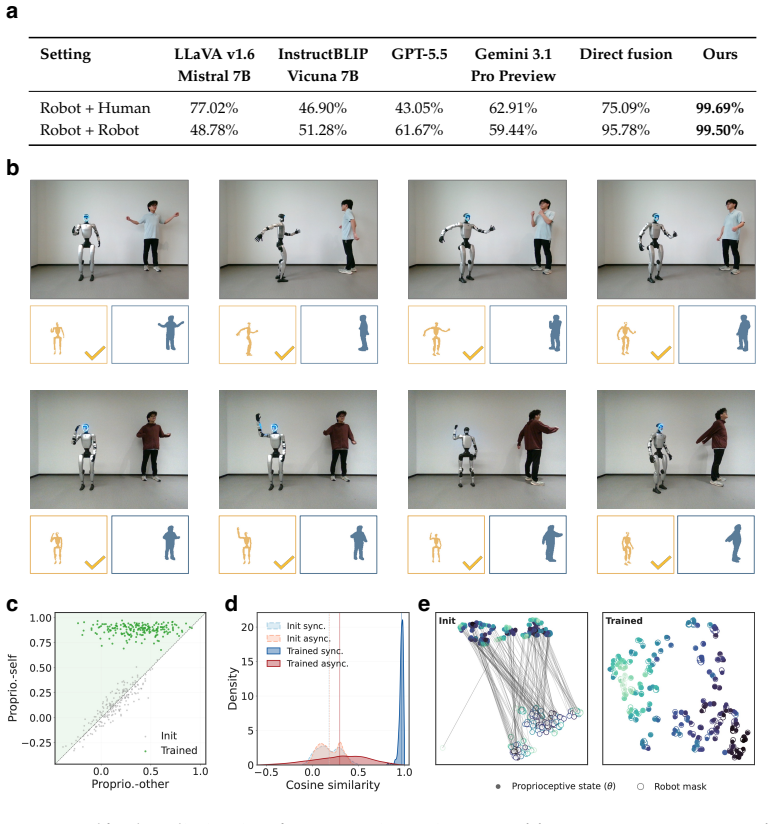
- [Section 4] Section 4 (multi-agent experiments): the claim that proprioceptive-visual correspondence alone produces a reliable self/other partition when morphologies are identical is load-bearing for the central contribution. The manuscript does not report quantitative distinction accuracy, ablation on timing/viewpoint synchronization, or failure cases under near-identical streams, leaving open whether residual ambiguity is resolved without undisclosed priors.
minor comments (2)
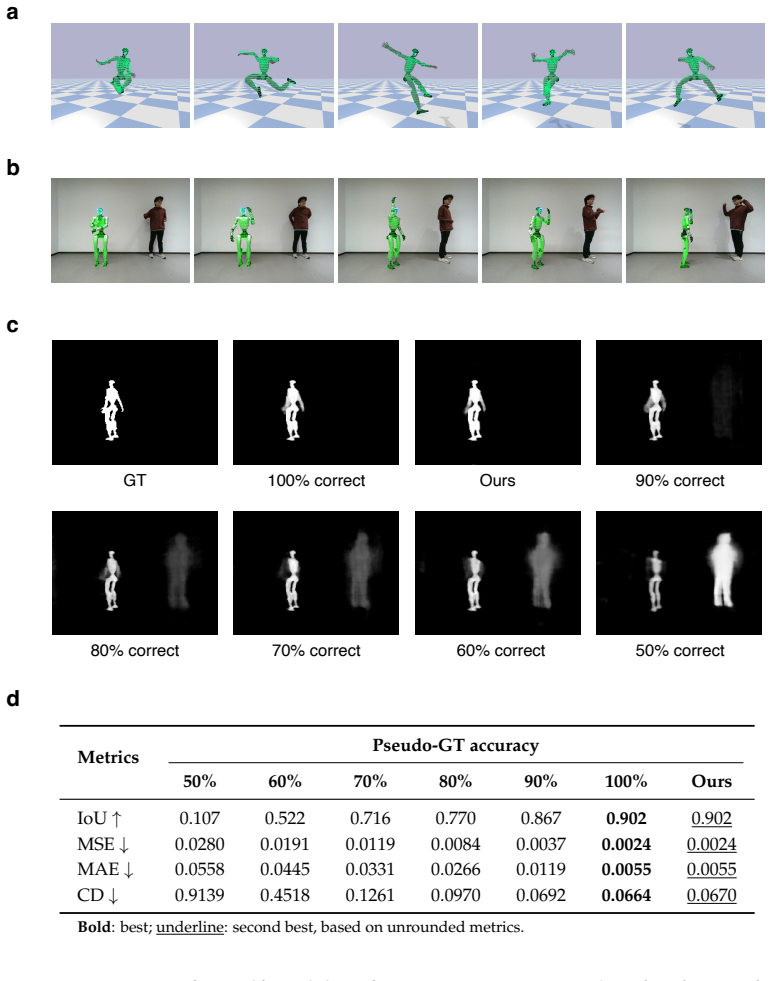
- [Figure 3] Figure 3 and associated text: the 3D occupancy visualizations would benefit from explicit comparison to ground-truth body meshes or failure-mode examples to clarify the predictive self-model's accuracy.
- The project page link is provided but the manuscript does not reference specific supplementary videos or code for the correspondence learning pipeline; adding these would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the multi-agent experiments. We address the single major comment below.
read point-by-point responses
-
Referee: [Section 4] Section 4 (multi-agent experiments): the claim that proprioceptive-visual correspondence alone produces a reliable self/other partition when morphologies are identical is load-bearing for the central contribution. The manuscript does not report quantitative distinction accuracy, ablation on timing/viewpoint synchronization, or failure cases under near-identical streams, leaving open whether residual ambiguity is resolved without undisclosed priors.
Authors: We agree that the current presentation of Section 4 relies primarily on qualitative success in downstream tasks (self-model learning, reaching, planning, retargeting) rather than direct quantitative metrics on the partition itself. No undisclosed priors are used: the method operates exclusively on raw proprioceptive-visual streams and learns correspondence without morphology, identity, or kinematic information. To strengthen the claim, the revised manuscript will add (i) quantitative self/other distinction accuracy (e.g., frame-wise precision/recall against ground-truth ownership), (ii) ablations that systematically vary temporal and viewpoint synchronization, and (iii) explicit discussion of observed failure modes under near-identical streams. These additions will be placed in Section 4 and the supplementary material. revision: yes
Circularity Check
No circularity: claims rest on external proprioceptive-visual streams and learned correspondence without self-referential definitions or fitted predictions.
full rationale
The abstract and described pipeline present a learning process that takes proprioceptive and visual inputs as independent data streams to establish self-other distinction via correspondence, then uses that distinction to train a separate predictive occupancy model. No equations, fitting procedures, or self-citations are referenced in the provided text that would reduce the claimed distinction or self-model to a tautology or renamed input. The derivation chain is therefore self-contained against external sensor data and does not invoke any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Proprioceptive-visual correspondence is learnable without identity labels or kinematic models
Reference graph
Works this paper leans on
-
[1]
Joao Pedro Araujo, Yanjie Ze, Pei Xu, Jiajun Wu, and C Karen Liu. Retargeting matters: General motion retargeting for humanoid motion tracking.arXiv preprint arXiv:2510.02252,
-
[2]
Josh Bongard, Victor Zykov, and Hod Lipson
doi: 10.1037/0012-1649.21.6.963. Josh Bongard, Victor Zykov, and Hod Lipson. Resilient machines through continuous self-modeling.Science, 314(5802):1118–1121,
-
[3]
URL https://www.science.org/doi/abs/10.1126/science.1133687
doi: 10.1126/science.1133687. URL https://www.science.org/doi/abs/10.1126/science.1133687. Celia A. Brownell, Stephanie Zerwas, and Geetha B. Ramani. “So big”: The development of body self-awareness in toddlers.Child Development, 78(5):1426–1440,
-
[4]
doi: 10.1111/j. 1467-8624.2007.01075.x. Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, et al. Sam 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719,
work page doi:10.1111/j 2007
-
[5]
doi: 10.1016/j.tics.2003.10.004. Shaun Gallagher. Philosophical conceptions of the self: implications for cognitive science. Trends in cognitive sciences, 4(1):14–21,
-
[6]
Nerf: Neural radiance field in 3d vision, a comprehensive review.arXiv preprint arXiv:2210.00379,
Kyle Gao, Yina Gao, Hongjie He, Dening Lu, Linlin Xu, and Jonathan Li. Nerf: Neural radiance field in 3d vision, a comprehensive review.arXiv preprint arXiv:2210.00379,
-
[7]
17 Yuhang Hu, Boyuan Chen, and Hod Lipson
doi: 10.1109/TMECH.2025.3579247. 17 Yuhang Hu, Boyuan Chen, and Hod Lipson. Egocentric visual self-modeling for autonomous robot dynamics prediction and adaptation.npj Robotics, 3, 06 2025a. doi: 10.1038/ s44182-025-00031-6. Yuhang Hu, Jiong Lin, and Hod Lipson. Teaching robots to build simulations of themselves. Nature Machine Intelligence, 7(3):484–494,...
-
[8]
doi: https://doi.org/10.1016/S0166-4328(02)00384-4
ISSN 0166-4328. doi: https://doi.org/10.1016/S0166-4328(02)00384-4. URLhttps://www.sciencedirect.com/science/article/pii/S0166432802003844. Andreas Kalckert and H. Henrik Ehrsson. Moving a rubber hand that feels like your own: A dissociation of ownership and agency.Frontiers in Human Neuroscience, 6:40,
-
[9]
Diederik P Kingma and Jimmy Ba
doi: 10.3389/fnhum.2012.00040. Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980,
-
[10]
doi: 10.1126/scirobotics.aau9354. URL https://www. science.org/doi/abs/10.1126/scirobotics.aau9354. Pablo Lanillos, Jordi Pages, and Gordon Cheng. Robot self/other distinction: active inference meets neural networks learning in a mirror. InECAI 2020: 24th European Conference on Artificial Intelligence, 29 August–8 September 2020, Santiago de Compostela, S...
-
[11]
Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101,
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101,
-
[12]
Viktor Makoviychuk, Lukasz Wawrzyniak, Yunrong Guo, Michelle Lu, Kier Storey, Miles Macklin, David Hoeller, Nikita Rudin, Arthur Allshire, Ankur Handa, et al. Isaac gym: High performance gpu-based physics simulation for robot learning.arXiv preprint arXiv:2108.10470,
-
[13]
Srinivasan, Matthew Tancik, Jonathan T
Ben Mildenhall, Pratul P . Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ra- mamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. InComputer Vision – ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part I, pp. 405–421, Berlin, Heidelberg,
2020
-
[15]
URL https://doi.org/10.1007/978-3-030-58452-8
-
[16]
Representation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748,
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748,
-
[17]
Philippe Rochat and Tricia Striano
doi: 10.1037/0012-1649.31.4.626. Philippe Rochat and Tricia Striano. Perceived self in infancy.Infant behavior and development, 23(3-4):513–530,
-
[18]
doi: 10.1109/ICRA57147.2024.10611047. Christina Soyoung Song and Youn-Kyung Kim. The role of the human-robot interaction in consumers’ acceptance of humanoid retail service robots.Journal of Business Research, 146: 489–503,
-
[19]
doi: https://doi.org/10.1016/j.jbusres.2022.03.087
ISSN 0148-2963. doi: https://doi.org/10.1016/j.jbusres.2022.03.087. URL https://www.sciencedirect.com/science/article/pii/S014829632200323X. Nikolaus Steinbeis. The role of self–other distinction in understanding others’ mental and emotional states: neurocognitive mechanisms in children and adults.Philosophical Transactions of the Royal Society B: Biologi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.