MapAgent: An Industrial-Grade Agentic Framework for City-scale Lane-level Map Generation
Pith reviewed 2026-06-28 06:46 UTC · model grok-4.3
The pith
MapAgent augments vector map backbones with a Judge-Planner-Worker loop to enforce mapping specifications at city scale.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MapAgent couples a vectorization backbone with a verification-driven Judge-Planner-Worker loop. The Judge diagnoses specification violations by jointly examining visual evidence and draft vectors. The Planner generates minimal corrective edits, and the Worker applies them deterministically before re-validation. Selective triggering on low-confidence tiles preserves throughput, allowing the framework to deliver specification-compliant lane networks at city scale.
What carries the argument
The bounded, verification-driven Judge-Planner-Worker loop that couples backbone perception with explicit specification verification and deterministic map editing.
If this is right
- The system produces consistent accuracy gains over strong production baselines, especially on long-tail and complex scenes.
- Selective activation on low-confidence tiles adds only modest overhead while maintaining city-scale throughput.
- Post-edit re-validation inside the loop reduces the volume of human corrections required.
- Deployment data show the framework supports lane-level mapping for over 360 cities with overall automation above 95 percent.
Where Pith is reading between the lines
- The same verification-loop pattern could be applied to other rule-governed geospatial outputs where visual data leave topology under-determined.
- Industrial map pipelines may increasingly favor hybrid perception-plus-verification stacks over purely learned end-to-end models.
- The selective-trigger design implies that full automation remains gated by the quality of the initial backbone confidence signal.
Load-bearing premise
The vision-language Judge can reliably detect specification violations from visual evidence and draft vectors in ambiguous scenes without introducing errors the Planner-Worker loop cannot fix.
What would settle it
A controlled test set of worn-marking or occluded intersections where the full MapAgent pipeline outputs lane vectors that still violate published mapping specifications at a rate equal to or higher than the backbone model alone.
Figures

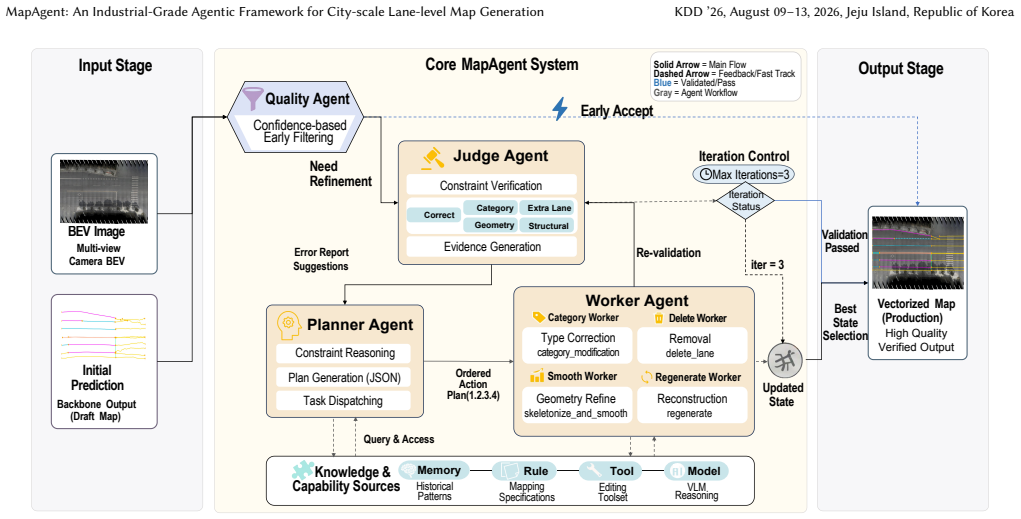
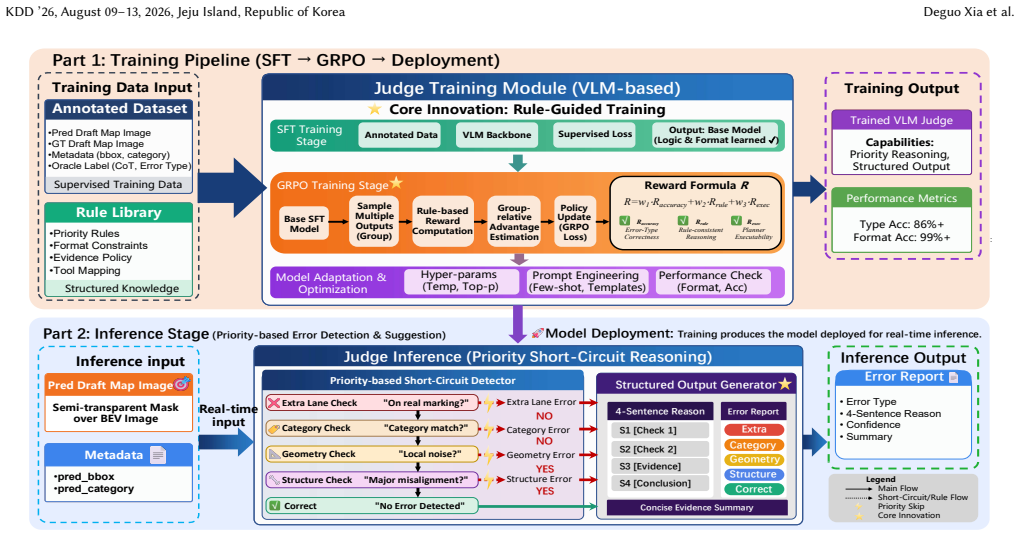

read the original abstract
Lane-level maps are critical infrastructure for autonomous driving and lane-level navigation, yet constructing and maintaining standardized lane networks for hundreds of cities remains highly labor-intensive. Recent end-to-end vectorized mapping methods can predict lane geometry and topology directly from sensor data, but they typically treat mapping specifications and traffic regulations as implicit, dataset-dependent supervision. Moreover, in complex scenes (e.g., worn or missing markings and occlusions), correct lane configurations are often under-determined by visual evidence alone, making specification violations a major source of human post-editing. We propose MapAgent, an industrial-grade agentic architecture that augments a vectorization backbone for specification-compliant lane-map production. Rather than merely adding an agent loop to map prediction, MapAgent couples backbone perception with explicit specification verification, constraint-aware reasoning, and deterministic map editing under a bounded, verification-driven Judge-Planner-Worker loop. A vision-language Judge diagnoses errors by jointly inspecting visual evidence and draft vectors, while a tool-calling Planner generates minimal corrective edits with post-edit re-validation. To remain scalable for city-scale production, MapAgent is selectively triggered only on tiles with low backbone confidence, adding modest overhead while preserving throughput. Experiments on real-world datasets show consistent gains over strong production baselines, especially in complex and long-tail scenarios. Additionally, MapAgent has been integrated into Baidu Maps, supporting lane-level map generation for over 360 cities nationwide and elevating the overall production automation to over 95%, demonstrating MapAgent's practicality and effectiveness for large-scale lane-level map generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MapAgent, an agentic architecture that augments a vectorization backbone with a bounded Judge-Planner-Worker loop. A vision-language Judge jointly inspects visual evidence and draft vectors to diagnose specification violations; a tool-calling Planner generates minimal corrective edits; and a Worker applies them with post-edit re-validation. The system is selectively triggered only on low-confidence tiles for city-scale scalability. The manuscript claims consistent gains over production baselines on real-world datasets and reports integration into Baidu Maps, supporting lane-level map generation for over 360 cities while raising overall production automation above 95%.
Significance. If the deployment metrics and performance claims are substantiated, the work would demonstrate a practical industrial system that explicitly encodes mapping specifications and traffic regulations to reduce post-editing in under-determined scenes, addressing a key bottleneck in scaling lane-level maps for autonomous driving. The selective-trigger design and verification-driven loop are notable for preserving throughput at city scale.
major comments (2)
- [Abstract] Abstract: the central claim that MapAgent 'elevat[es] the overall production automation to over 95%' across 'over 360 cities' is presented without any definition of the automation metric, pre-deployment baseline, production-scale error rates, or quantitative linkage between Judge-Planner-Worker performance on real tiles and the reported figure. This assertion is load-bearing for the practicality conclusion.
- [Abstract] Abstract: the statement that 'Experiments on real-world datasets show consistent gains over strong production baselines, especially in complex and long-tail scenarios' supplies no numerical results, baseline identities, city-scale statistics, ablation on Judge false-positive rate under occlusion or worn markings, or error distributions. These omissions leave the experimental support for the framework's effectiveness unverifiable from the manuscript.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We address each point below and will revise the manuscript to improve clarity and verifiability of the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that MapAgent 'elevat[es] the overall production automation to over 95%' across 'over 360 cities' is presented without any definition of the automation metric, pre-deployment baseline, production-scale error rates, or quantitative linkage between Judge-Planner-Worker performance on real tiles and the reported figure. This assertion is load-bearing for the practicality conclusion.
Authors: We agree that the abstract would be strengthened by a concise definition of the automation metric and reference to the baseline. The manuscript body defines the automation rate as the percentage of tiles requiring no human post-editing after the full pipeline and reports the pre-deployment baseline along with before-and-after comparisons on production data. To address the concern directly in the abstract, we will revise it to include a brief definition of the metric and the baseline value. revision: yes
-
Referee: [Abstract] Abstract: the statement that 'Experiments on real-world datasets show consistent gains over strong production baselines, especially in complex and long-tail scenarios' supplies no numerical results, baseline identities, city-scale statistics, ablation on Judge false-positive rate under occlusion or worn markings, or error distributions. These omissions leave the experimental support for the framework's effectiveness unverifiable from the manuscript.
Authors: We acknowledge that the abstract summarizes the experimental outcomes at a high level without enumerating specific numbers or baselines. The full manuscript provides these details in the experiments section, including baseline identities, quantitative gains on real-world datasets, city-scale statistics, and ablations on false-positive rates. We will revise the abstract to incorporate key numerical results and baseline names to improve immediate verifiability while respecting length constraints. revision: yes
Circularity Check
No circularity: system description with no derivation chain or fitted predictions
full rationale
The manuscript describes an agentic framework (Judge-Planner-Worker loop) for map generation and asserts integration results (360 cities, >95% automation) without any equations, parameter fitting, predictions derived from inputs, or self-citation chains that reduce claims to tautologies. The central claims concern deployed performance metrics rather than first-principles derivations, and no load-bearing step equates outputs to inputs by construction. This is a standard non-circular engineering paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Floren- cia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report.arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Chebotar, Omar Cortes, Byron David, Chelsea Finn, Chuyuan Fu, Keerthana Gopalakrishnan, Karol Haus- man, et al . 2022. Do as i can, not as i say: Grounding language in robotic affordances.arXiv preprint arXiv:2204.01691(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. 2023. Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond.arXiv preprint arXiv:2308.12966(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Xu Cao, Tong Zhou, Yunsheng Ma, Wenqian Ye, Can Cui, Kun Tang, Zhipeng Cao, Kaizhao Liang, Ziran Wang, James M Rehg, et al. 2024. Maplm: A real-world large- scale vision-language benchmark for map and traffic scene understanding. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 21819–21830
2024
-
[5]
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, An- drew Huang, et al. 2025. Sam 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al . 2024. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 24185–24198
2024
-
[7]
Danny Driess, Fei Xia, Mehdi SM Sajjadi, Corey Lynch, Aakanksha Chowdhery, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, Wenlong Huang, et al. 2023. Palm-e: An embodied multimodal language model. (2023)
2023
-
[8]
Fabian Immel, Jan-Hendrik Pauls, Richard Fehler, Frank Bieder, Jonas Merkert, and Christoph Stiller. 2025. SDTagNet: Leveraging Text-Annotated Navigation Maps for Online HD Map Construction. InAdvances in Neural Information Pro- cessing Systems, Vol. 38
2025
-
[9]
Zhou Jiang, Zhenxin Zhu, Pengfei Li, Huan-ang Gao, Tianyuan Yuan, Yongliang Shi, Hang Zhao, and Hao Zhao. 2024. P-mapnet: Far-seeing map generator enhanced by both sdmap and hdmap priors.IEEE Robotics and Automation Letters (2024)
2024
-
[10]
Ehud Karpas, Omri Abend, Yonatan Belinkov, Barak Lenz, Opher Lieber, Nir Ratner, Yoav Shoham, Hofit Bata, Yoav Levine, Kevin Leyton-Brown, et al. 2022. MRKL Systems: A modular, neuro-symbolic architecture that combines large language models, external knowledge sources and discrete reasoning.arXiv preprint arXiv:2205.00445(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[11]
Aviral Kumar, Vincent Zhuang, Rishabh Agarwal, Yi Su, John D Co-Reyes, Avi Singh, Kate Baumli, Shariq Iqbal, Colton Bishop, Rebecca Roelofs, et al . 2024. Training language models to self-correct via reinforcement learning.arXiv preprint arXiv:2409.12917(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Qi Li, Yue Wang, Yilun Wang, and Hang Zhao. 2022. Hdmapnet: An online hd map construction and evaluation framework. In2022 International Conference on Robotics and Automation (ICRA). IEEE, 4628–4634
2022
- [13]
- [14]
-
[15]
Yicheng Liu, Tianyuan Yuan, Yue Wang, Yilun Wang, and Hang Zhao. 2023. Vectormapnet: End-to-end vectorized hd map learning. InInternational Conference on Machine Learning. PMLR, 22352–22369
2023
-
[16]
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. 2023. Toolformer: Language models can teach themselves to use tools.Advances in Neural Information Processing Systems36 (2023), 68539–68551
2023
-
[17]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. Reflexion: Language agents with verbal reinforcement learning. Advances in Neural Information Processing Systems36 (2023), 8634–8652
2023
-
[18]
Chonghao Sima, Katrin Renz, Kashyap Chitta, Li Chen, Hanxue Zhang, Chengen Xie, Jens Beißwenger, Ping Luo, Andreas Geiger, and Hongyang Li. 2024. Drivelm: Driving with graph visual question answering. InEuropean conference on computer vision. Springer, 256–274
2024
-
[19]
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. 2023. Voyager: An open-ended embodied agent with large language models.arXiv preprint arXiv:2305.16291(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Rongxuan Wang, Xin Lu, Xiaoyang Liu, Xiaoyi Zou, Tongyi Cao, and Ying Li
-
[21]
arXiv preprint arXiv:2408.08802(2024)
Priormapnet: Enhancing online vectorized hd map construction with priors. arXiv preprint arXiv:2408.08802(2024)
-
[22]
Kuang Wu, Chuan Yang, and Zhanbin Li. 2025. InteractionMap: Improving Online Vectorized HDMap Construction with Interaction. InProceedings of the Computer Vision and Pattern Recognition Conference. 17176–17186
2025
-
[23]
Deguo Xia, Weiming Zhang, Xiyan Liu, Wei Zhang, Chenting Gong, Jizhou Huang, Mengmeng Yang, and Diange Yang. 2024. DuMapNet: An End-to-End Vectorization System for City-Scale Lane-Level Map Generation. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 6015–6024
2024
-
[24]
Deguo Xia, Weiming Zhang, Xiyan Liu, Wei Zhang, Chenting Gong, Xiao Tan, Jizhou Huang, Mengmeng Yang, and Diange Yang. 2025. LDMapNet-U: An End- to-End System for City-Scale Lane-Level Map Updating. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 1. 2693–2702
2025
-
[25]
Xuan Xiong, Yicheng Liu, Tianyuan Yuan, Yue Wang, Yilun Wang, and Hang Zhao. 2023. Neural map prior for autonomous driving. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 17535–17544
2023
-
[26]
Binfeng Xu, Zhiyuan Peng, Bowen Lei, Subhabrata Mukherjee, Yuchen Liu, and Dongkuan Xu. 2023. Rewoo: Decoupling reasoning from observations for efficient augmented language models.arXiv preprint arXiv:2305.18323(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. 2022. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations
2022
-
[28]
Dapeng Zhang, Dayu Chen, Peng Zhi, Yinda Chen, Zhenlong Yuan, Chenyang Li, Rui Zhou, Qingguo Zhou, et al. 2025. Mapexpert: Online hd map construction with simple and efficient sparse map element expert. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 14745–14753
2025
-
[29]
Yifan Zhang, Zhengting He, Jingxuan Li, Jianfeng Lin, Qingfeng Guan, and Wenhao Yu. 2024. MapGPT: an autonomous framework for mapping by integrat- ing large language model and cartographic tools.Cartography and Geographic Information Science51, 6 (2024), 717–743
2024
-
[30]
Zhixin Zhang, Yiyuan Zhang, Xiaohan Ding, Fusheng Jin, and Xiangyu Yue
- [31]
-
[32]
Yi Zhou, Hui Zhang, Jiaqian Yu, Yifan Yang, Sangil Jung, Seung-In Park, and ByungIn Yoo. 2024. Himap: Hybrid representation learning for end-to-end vector- ized hd map construction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 15396–15406. 10 MapAgent: An Industrial-Grade Agentic Framework for City-scale Lane-level ...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.