JAM-Flow: Joint Audio-Motion Synthesis with Flow Matching
Pith reviewed 2026-05-22 00:42 UTC · model grok-4.3
The pith
A unified flow-matching model with coupled audio and motion transformers jointly synthesizes speech and facial animation from text, audio, or motion inputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
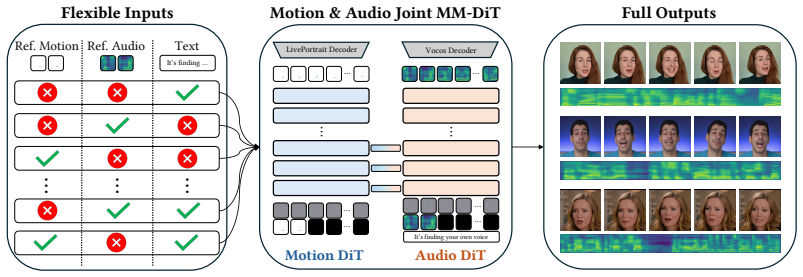
JAM-Flow is a unified framework that leverages flow matching and a novel Multi-Modal Diffusion Transformer (MM-DiT) architecture to simultaneously synthesize and condition on both facial motion and speech. Specialized Motion-DiT and Audio-DiT modules are coupled via selective joint attention layers that use temporally aligned positional embeddings and localized joint attention masking. Trained with an inpainting-style objective, the model supports conditioning on text, reference audio, and reference motion to perform synchronized talking-head generation from text, audio-driven animation, and additional tasks inside one model.
What carries the argument
Multi-Modal Diffusion Transformer (MM-DiT) whose Motion-DiT and Audio-DiT modules are coupled through selective joint attention layers with localized masking and aligned positional embeddings.
If this is right
- Text prompts alone can drive synchronized talking-head video output.
- Reference audio can animate a source face without separate lip-sync modules.
- Reference motion can condition speech generation in the reverse direction.
- An inpainting objective lets the same weights handle missing modalities at inference time.
- Multiple audio-visual tasks run inside one coherent trained network rather than separate models.
Where Pith is reading between the lines
- The same joint-attention pattern could be tested on full-body motion paired with audio or on longer video clips with background sound.
- Training on mixed conditioning might reduce the need for task-specific fine-tuning in animation or virtual-agent pipelines.
- If the localized masking proves robust, similar selective coupling could be applied to other paired modalities such as gesture and text.
- The flow-matching backbone may allow faster sampling than diffusion baselines when generating both streams together.
Load-bearing premise
The selective joint attention layers and localized masking enable effective cross-modal interaction while still preserving each modality's independent strengths.
What would settle it
If a model trained with the same data but without the joint attention layers produces audio-motion pairs that are measurably less synchronized or lower in quality on standard benchmarks, the benefit of the coupled architecture would be refuted.
Figures


read the original abstract
The intrinsic link between facial motion and speech is often overlooked in generative modeling, where talking head synthesis and text-to-speech (TTS) are typically addressed as separate tasks. This paper introduces JAM-Flow, a unified framework to simultaneously synthesize and condition on both facial motion and speech. Our approach leverages flow matching and a novel Multi-Modal Diffusion Transformer (MM-DiT) architecture, integrating specialized Motion-DiT and Audio-DiT modules. These are coupled via selective joint attention layers and incorporate key architectural choices, such as temporally aligned positional embeddings and localized joint attention masking, to enable effective cross-modal interaction while preserving modality-specific strengths. Trained with an inpainting-style objective, JAM-Flow supports a wide array of conditioning inputs-including text, reference audio, and reference motion-facilitating tasks such as synchronized talking head generation from text, audio-driven animation, and much more, within a single, coherent model. JAM-Flow significantly advances multi-modal generative modeling by providing a practical solution for holistic audio-visual synthesis. project page: https://joonghyuk.com/jamflow-web
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces JAM-Flow, a unified framework for simultaneous synthesis and conditioning on facial motion and speech. It employs flow matching together with a novel Multi-Modal Diffusion Transformer (MM-DiT) that couples specialized Motion-DiT and Audio-DiT modules via selective joint attention layers, temporally aligned positional embeddings, and localized joint attention masking. The model is trained with an inpainting-style objective and supports conditioning on text, reference audio, and reference motion to enable tasks such as text-conditioned talking-head generation and audio-driven animation within a single coherent model.
Significance. If the claimed cross-modal benefits materialize, JAM-Flow would constitute a practical advance in multi-modal generative modeling by replacing separate talking-head and TTS pipelines with a single flow-matching model that handles a wide range of conditioning inputs. The architectural emphasis on preserving modality-specific strengths while enabling interaction is a potentially useful design pattern for other audio-visual tasks.
major comments (1)
- [MM-DiT architecture description] The central claim that the selective joint attention layers and localized joint attention masking in the MM-DiT produce effective cross-modal interaction while preserving modality-specific strengths is load-bearing for the paper's contribution. No ablation results are presented that isolate these components against independent Motion-DiT/Audio-DiT modules or simpler fusion baselines; therefore it remains unclear whether any observed gains on joint tasks arise from the proposed attention mechanism or simply from the shared flow-matching objective and inpainting loss.
minor comments (1)
- [Abstract] The abstract would be strengthened by including at least one quantitative result or baseline comparison to support the claim of a 'significant advance.'
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for highlighting the importance of isolating the contributions of the MM-DiT components. We address the major comment below and describe the planned revisions.
read point-by-point responses
-
Referee: [MM-DiT architecture description] The central claim that the selective joint attention layers and localized joint attention masking in the MM-DiT produce effective cross-modal interaction while preserving modality-specific strengths is load-bearing for the paper's contribution. No ablation results are presented that isolate these components against independent Motion-DiT/Audio-DiT modules or simpler fusion baselines; therefore it remains unclear whether any observed gains on joint tasks arise from the proposed attention mechanism or simply from the shared flow-matching objective and inpainting loss.
Authors: We agree that the absence of targeted ablations leaves the specific contribution of the selective joint attention layers and localized joint attention masking insufficiently isolated. The current results demonstrate end-to-end performance but do not directly compare against independent Motion-DiT and Audio-DiT modules or simpler fusion baselines such as feature concatenation or standard cross-attention. In the revised manuscript we will add these ablation experiments on the same training and evaluation splits, reporting both quantitative metrics (e.g., synchronization error, perceptual quality) and qualitative visualizations that highlight the effect of the proposed masking and joint-attention design choices. revision: yes
Circularity Check
No circularity: model architecture and training described without self-referential derivations
full rationale
The paper proposes JAM-Flow as a new unified framework combining flow matching with a custom MM-DiT architecture that couples Motion-DiT and Audio-DiT via selective joint attention, temporally aligned embeddings, and localized masking, trained under an inpainting-style objective. No equations, predictions, or first-principles results are shown that reduce by construction to fitted inputs, self-citations, or renamed known results. All components are presented as design choices justified by their intended cross-modal behavior on external data, leaving the central claims independent of any circular reduction.
Axiom & Free-Parameter Ledger
free parameters (1)
- localized joint attention masking parameters
axioms (1)
- domain assumption Temporally aligned positional embeddings maintain synchronization between audio and motion sequences
invented entities (1)
-
Multi-Modal Diffusion Transformer (MM-DiT)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our approach leverages flow matching and a novel Multi-Modal Diffusion Transformer (MM-DiT) architecture, integrating specialized Motion-DiT and Audio-DiT modules. These are coupled via selective joint attention layers and incorporate key architectural choices, such as temporally aligned positional embeddings and localized joint attention masking
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat induction and embed_strictMono unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we introduce Njoint layers of joint attention between the audio and motion streams... we apply scaled rotary positional embeddings (RoPE)... attention masking strategy that respects the temporal dynamics
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Generative adversarial nets, 2014
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets, 2014
work page 2014
-
[2]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In Conference on Neural Information Processing Systems (NeurIPS) , 2020
work page 2020
-
[3]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-Based Generative Modeling through Stochastic Differential Equations. In International Conference on Learning Representations (ICLR), 2021
work page 2021
-
[4]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Xingchao Liu, Chengyue Gong, et al. Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow. In International Conference on Learning Representations (ICLR) , 2023
work page 2023
-
[5]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matthew Le. Flow Matching for Generative Modeling. In International Conference on Learning Representations (ICLR) , 2023
work page 2023
-
[6]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2022
work page 2022
-
[7]
Liveportrait: Efficient portrait animation with stitching and retargeting control
Jianzhu Guo, Dingyun Zhang, Xiaoqiang Liu, Zhizhou Zhong, Yuan Zhang, Pengfei Wan, and Di Zhang. Liveportrait: Efficient portrait animation with stitching and retargeting control. arXiv preprint arXiv:2407.03168, 2024
-
[8]
X-portrait: Expressive portrait animation with hierarchical motion attention
You Xie, Hongyi Xu, Guoxian Song, Chao Wang, Yichun Shi, and Linjie Luo. X-portrait: Expressive portrait animation with hierarchical motion attention. In ACM SIGGRAPH, 2024
work page 2024
-
[9]
First order motion model for image animation
Aliaksandr Siarohin, Stéphane Lathuilière, Sergey Tulyakov, Elisa Ricci, and Nicu Sebe. First order motion model for image animation. Conference on Neural Information Processing Systems (NeurIPS) , 2019
work page 2019
-
[10]
Emoportraits: Emotion-enhanced multimodal one-shot head avatars
Nikita Drobyshev, Antoni Bigata Casademunt, Konstantinos V ougioukas, Zoe Landgraf, Stavros Petridis, and Maja Pantic. Emoportraits: Emotion-enhanced multimodal one-shot head avatars. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , 2024
work page 2024
-
[11]
One-shot free-view neural talking-head synthesis for video conferencing
Ting-Chun Wang, Arun Mallya, and Ming-Yu Liu. One-shot free-view neural talking-head synthesis for video conferencing. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , 2021
work page 2021
-
[12]
K. R. Prajwal, Rudrabha Mukhopadhyay, Vinay P. Namboodiri, and C. V . Jawahar. Wav2Lip: A lip sync expert is all you need for speech to lip generation in the wild. InProceedings of the 28th ACM International Conference on Multimedia (ACM MM) , 2020
work page 2020
-
[13]
MakeItTalk: Speaker-aware talking-head animation
Yang Zhou, Xintong Han, Eli Shechtman, Jose Echevarria, Evangelos Kalogerakis, and Dingzeyu Li. MakeItTalk: Speaker-aware talking-head animation. In ACM SIGGRAPH Asia, 2020
work page 2020
-
[14]
Linrui Tian, Qi Wang, Bang Zhang, and Liefeng Bo. Emo: Emote portrait alive generating expressive portrait videos with audio2video diffusion model under weak conditions. In European Conference on Computer Vision (ECCV). Springer, 2024
work page 2024
-
[15]
Vasa-1: Lifelike audio-driven talking faces generated in real time
Sicheng Xu, Guojun Chen, Yu-Xiao Guo, Jiaolong Yang, Chong Li, Zhenyu Zang, Yizhong Zhang, Xin Tong, and Baining Guo. Vasa-1: Lifelike audio-driven talking faces generated in real time. Conference on Neural Information Processing Systems (NeurIPS) , 2024. 10
work page 2024
-
[16]
Gaojie Lin, Jianwen Jiang, Jiaqi Yang, Zerong Zheng, and Chao Liang. OmniHuman-1: Rethinking the scaling-up of one-stage conditioned human animation models. arXiv preprint arXiv:2502.01061, 2025
-
[17]
Wenxuan Zhang, Xiaodong Cun, Xuan Wang, Yong Zhang, Xi Shen, Yu Guo, Ying Shan, and Fei Wang. SadTalker: Learning realistic 3d motion coefficients for stylized audio-driven single image talking face animation. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , 2023
work page 2023
-
[18]
F5-TTS: High-fidelity text-to-speech via conditional flow matching and inpainting
Junyang Chen, Chenpeng Du, Zhenhui Ye, and Yanwei Fu. F5-TTS: High-fidelity text-to-speech via conditional flow matching and inpainting. arXiv preprint arXiv:2411.00000, 2024
-
[19]
Megatts 3: Sparse alignment enhanced latent diffusion transformer for zero-shot speech synthesis,
Ziyue Jiang, Yi Ren, Ruiqi Li, Shengpeng Ji, Boyang Zhang, Zhenhui Ye, Chen Zhang, Bai Jionghao, Xiaoda Yang, Jialong Zuo, et al. Megatts 3: Sparse alignment enhanced latent diffusion transformer for zero-shot speech synthesis. arXiv preprint arXiv:2502.18924, 2025
-
[20]
Scaling rectified flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow transformers for high-resolution image synthesis. In International Conference on Machine Learning (ICML) , 2024
work page 2024
-
[21]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023
work page 2023
-
[22]
Roformer: Enhanced transformer with rotary position embedding
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding. Neurocomputing, 568:127063, 2024
work page 2024
-
[23]
Black Forest Labs. Flux.1. https://blackforestlabs.ai/announcing-black-forest-labs/ ,
-
[24]
Accessed: November 2024
work page 2024
-
[25]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer. arXiv preprint arXiv:2408.06072, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Stylerig: Rigging stylegan for 3d control over portrait images
Ayush Tewari, Mohamed Elgharib, Gaurav Bharaj, Florian Bernard, Hans-Peter Seidel, Patrick Pérez, Michael Zollhofer, and Christian Theobalt. Stylerig: Rigging stylegan for 3d control over portrait images. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages 6142–6151, 2020
work page 2020
-
[27]
Tacotron: Towards End-to-End Speech Synthesis
Yuxuan Wang, RJ Skerry-Ryan, Daisy Stanton, Yonghui Wu, Ron J Weiss, Navdeep Jaitly, Zongheng Yang, Ying Xiao, Zhifeng Chen, Samy Bengio, et al. Tacotron: Towards end-to-end speech synthesis. arXiv preprint arXiv:1703.10135, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[28]
Fastspeech: Fast, robust and controllable text to speech
Yi Ren, Yangjun Ruan, Xu Tan, Tao Qin, Sheng Zhao, Zhou Zhao, and Tie-Yan Liu. Fastspeech: Fast, robust and controllable text to speech. Conference on Neural Information Processing Systems (NeurIPS) , 2019
work page 2019
-
[29]
Fastspeech 2: Fast and high-quality end-to-end text to speech
Yi Ren, Chenxu Hu, Xu Tan, Tao Qin, Sheng Zhao, Zhou Zhao, and Tie-Yan Liu. Fastspeech 2: Fast and high-quality end-to-end text to speech. arXiv preprint arXiv:2006.04558, 2020
-
[30]
Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers
Chengyi Wang, Sanyuan Chen, Yu Wu, Ziqiang Zhang, Long Zhou, Shujie Liu, Zhuo Chen, Yanqing Liu, Huaming Wang, Jinyu Li, et al. Neural codec language models are zero-shot text to speech synthesizers. arXiv preprint arXiv:2301.02111, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
Naturalspeech: End-to-end text-to-speech synthesis with human-level quality
Xu Tan, Jiawei Chen, Haohe Liu, Jian Cong, Chen Zhang, Yanqing Liu, Xi Wang, Yichong Leng, Yuanhao Yi, Lei He, et al. Naturalspeech: End-to-end text-to-speech synthesis with human-level quality. IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(6):4234–4245, 2024
work page 2024
-
[32]
Naturalspeech 3: Zero-shot speech synthesis with factorized codec and diffusion models
Zeqian Ju, Yuancheng Wang, Kai Shen, Xu Tan, Detai Xin, Dongchao Yang, Yanqing Liu, Yichong Leng, Kaitao Song, Siliang Tang, et al. Naturalspeech 3: Zero-shot speech synthesis with factorized codec and diffusion models. arXiv preprint arXiv:2403.03100, 2024
-
[33]
Naturalspeech 2: Latent diffusion models are natural and zero-shot speech and singing synthesizers
Kai Shen, Zeqian Ju, Xu Tan, Yanqing Liu, Yichong Leng, Lei He, Tao Qin, Sheng Zhao, and Jiang Bian. Naturalspeech 2: Latent diffusion models are natural and zero-shot speech and singing synthesizers. arXiv preprint arXiv:2304.09116, 2023
-
[34]
V oicebox: Text-guided multilingual universal speech generation at scale
Matthew Le, Apoorv Vyas, Bowen Shi, Brian Karrer, Leda Sarı, Rashel Moritz, Mary Williamson, Vimal Manohar, Yossi Adi, Jay Mahadeokar, and Wei-Ning Hsu. V oicebox: Text-guided multilingual universal speech generation at scale. In Conference on Neural Information Processing Systems (NeurIPS) , 2023
work page 2023
-
[35]
Ditto-tts: Efficient and scalable zero-shot text-to-speech with diffusion transformer
Keon Lee, Dong Won Kim, Jaehyeon Kim, and Jaewoong Cho. Ditto-tts: Efficient and scalable zero-shot text-to-speech with diffusion transformer. arXiv preprint arXiv:2406.11427, 2024. 11
-
[36]
E2 tts: Embarrassingly easy fully non-autoregressive zero-shot tts
Sefik Emre Eskimez, Xiaofei Wang, Manthan Thakker, Canrun Li, Chung-Hsien Tsai, Zhen Xiao, Hemin Yang, Zirun Zhu, Min Tang, Xu Tan, et al. E2 tts: Embarrassingly easy fully non-autoregressive zero-shot tts. In 2024 IEEE Spoken Language Technology Workshop (SLT), pages 682–689. IEEE, 2024
work page 2024
-
[37]
Learning to dub movies via hierarchical prosody models
Gaoxiang Cong, Liang Li, Yuankai Qi, Zheng-Jun Zha, Qi Wu, Wenyu Wang, Bin Jiang, Ming-Hsuan Yang, and Qingming Huang. Learning to dub movies via hierarchical prosody models. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , 2023
work page 2023
-
[38]
Styledubber: towards multi-scale style learning for movie dubbing
Gaoxiang Cong, Yuankai Qi, Liang Li, Amin Beheshti, Zhedong Zhang, Anton van den Hengel, Ming- Hsuan Yang, Chenggang Yan, and Qingming Huang. Styledubber: towards multi-scale style learning for movie dubbing. arXiv preprint arXiv:2402.12636, 2024
-
[39]
V oiceCraft-Dub: Automated Video Dubbing with Neural Codec Language Models
Kim Sung-Bin, Jeongsoo Choi, Puyuan Peng, Joon Son Chung, Tae-Hyun Oh, and David Harwath. V oiceCraft-Dub: Automated Video Dubbing with Neural Codec Language Models. arXiv preprint arXiv:2504.02386, 2025
-
[40]
Flow-guided one-shot talking face genera- tion with a high-resolution audio-visual dataset
Zhimeng Zhang, Lincheng Li, Yu Ding, and Changjie Fan. Flow-guided one-shot talking face genera- tion with a high-resolution audio-visual dataset. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021
work page 2021
-
[41]
DreamTalk: When Emotional Talking Head Generation Meets Diffusion Probabilistic Models,
Yifeng Ma, Shiwei Zhang, Jiayu Wang, Xiang Wang, Yingya Zhang, and Zhidong Deng. Dreamtalk: When expressive talking head generation meets diffusion probabilistic models. arXiv preprint arXiv:2312.09767, 2(3), 2023
-
[42]
AniPortrait: Audio-Driven Synthesis of Photorealistic Portrait Animation,
Huawei Wei, Zejun Yang, and Zhisheng Wang. Aniportrait: Audio-driven synthesis of photorealistic portrait animation. arXiv preprint arXiv:2403.17694, 2024
-
[43]
Hallo: Hierarchical Audio-Driven Visual Synthesis for Portrait Image Animation,
Mingwang Xu, Hui Li, Qingkun Su, Hanlin Shang, Liwei Zhang, Ce Liu, Jingdong Wang, Yao Yao, and Siyu Zhu. Hallo: Hierarchical audio-driven visual synthesis for portrait image animation. arXiv preprint arXiv:2406.08801, 2024
-
[44]
Hallo3: Highly dynamic and realistic portrait image animation with diffusion transformer networks
Jiahui Cheng, Yuqi Ma, Shan Mu, Hang Zhou, Jingdong Wang, and Siyu Zhu. Hallo3: Highly dynamic and realistic portrait image animation with diffusion transformer networks. arXiv preprint arXiv:2412.00733, 2024
-
[45]
Librispeech: an asr corpus based on public domain audio books
Vassil Panayotov, Guoguo Chen, Daniel Povey, and Sanjeev Khudanpur. Librispeech: an asr corpus based on public domain audio books. In 2015 IEEE international conference on acoustics, speech and signal processing (ICASSP), pages 5206–5210. IEEE, 2015
work page 2015
-
[46]
Zhihao Du, Qian Chen, Shiliang Zhang, Kai Hu, Heng Lu, Yexin Yang, Hangrui Hu, Siqi Zheng, Yue Gu, Ziyang Ma, et al. Cosyvoice: A scalable multilingual zero-shot text-to-speech synthesizer based on supervised semantic tokens. arXiv preprint arXiv:2407.05407, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[47]
Fireredtts: A foundation text-to-speech framework for industry-level generative speech applications
Hao-Han Guo, Yao Hu, Kun Liu, Fei-Yu Shen, Xu Tang, Yi-Chen Wu, Feng-Long Xie, Kun Xie, and Kai-Tuo Xu. Fireredtts: A foundation text-to-speech framework for industry-level generative speech applications. arXiv preprint arXiv:2409.03283, 2024
-
[48]
V oicecraft: Zero-shot speech editing and text-to-speech in the wild
Puyuan Peng, Po-Yao Huang, Shang-Wen Li, Abdelrahman Mohamed, and David Harwath. V oicecraft: Zero-shot speech editing and text-to-speech in the wild. arXiv preprint arXiv:2403.16973, 2024
-
[49]
Celebv-hq: A large-scale video facial attributes dataset
Hao Zhu, Wayne Wu, Wentao Zhu, Liming Jiang, Siwei Tang, Li Zhang, Ziwei Liu, and Chen Change Loy. Celebv-hq: A large-scale video facial attributes dataset. In European Conference on Computer Vision (ECCV), 2022
work page 2022
-
[50]
Celebv-text: A large-scale facial text-video dataset
Jianhui Yu, Hao Zhu, Liming Jiang, Chen Change Loy, Weidong Cai, and Wayne Wu. Celebv-text: A large-scale facial text-video dataset. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023
work page 2023
-
[51]
Gans trained by a two time-scale update rule converge to a local nash equilibrium
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. Conference on Neural Information Processing Systems (NeurIPS), 2017
work page 2017
-
[52]
Towards Accurate Generative Models of Video: A New Metric & Challenges
Thomas Unterthiner, Sjoerd Van Steenkiste, Karol Kurach, Raphael Marinier, Marcin Michalski, and Sylvain Gelly. Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:1812.01717, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[53]
Identity-preserving talking face generation with landmark and appearance priors
Weizhi Zhong, Chaowei Fang, Yinqi Cai, Pengxu Wei, Gangming Zhao, Liang Lin, and Guanbin Li. Identity-preserving talking face generation with landmark and appearance priors. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023. 12
work page 2023
-
[54]
Robust speech recognition via large-scale weak supervision
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision. In International Conference on Learning Representations (ICLR), 2023
work page 2023
-
[55]
Spleeter: a fast and efficient music source separation tool with pre-trained models
Romain Hennequin, Anis Khlif, Felix V oituret, and Manuel Moussallam. Spleeter: a fast and efficient music source separation tool with pre-trained models. Journal of Open Source Software, 5(50):2154, 2020
work page 2020
-
[56]
Audio-visual speech representation expert for enhanced talking face video generation and evaluation
Dogucan Yaman, Fevziye Irem Eyiokur, Leonard Bärmann, Seymanur Akti, Hazım Kemal Ekenel, and Alexander Waibel. Audio-visual speech representation expert for enhanced talking face video generation and evaluation. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshop, 2024
work page 2024
-
[57]
Sidgan: High-resolution dubbed video generation via shift-invariant learning
Urwa Muaz, Wondong Jang, Rohun Tripathi, Santhosh Mani, Wenbin Ouyang, Ravi Teja Gadde, Baris Gecer, Sergio Elizondo, Reza Madad, and Naveen Nair. Sidgan: High-resolution dubbed video generation via shift-invariant learning. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , 2023
work page 2023
-
[58]
Out of time: automated lip sync in the wild
Joon Son Chung and Andrew Zisserman. Out of time: automated lip sync in the wild. In Computer Vision–ACCV 2016 Workshops: ACCV 2016 International Workshops, Taipei, Taiwan, November 20-24, 2016, Revised Selected Papers, Part II 13, pages 251–263. Springer, 2017
work page 2016
-
[59]
LTX-Video: Realtime Video Latent Diffusion
Yoav HaCohen, Nisan Chiprut, Benny Brazowski, Daniel Shalem, Dudu Moshe, Eitan Richardson, Eran Levin, Guy Shiran, Nir Zabari, Ori Gordon, et al. Ltx-video: Realtime video latent diffusion.arXiv preprint arXiv:2501.00103, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[60]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314, 2025. 13 A Qualitative Comparisons, User Study, and Discussions A.1 Qualitative Analysis We provide extensive qualitative comparisons across fi...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[61]
Project input to QKV: (q1, k1, v1) ← attn1.TOQKV (x1) (q2, k2, v2) ← attn2.TOQKV (x2)
-
[62]
Apply rotary embeddings (if provided): if rope1 exists then (q1, k1) ← APPLYROPE(q1, k1, rope1) if rope2 exists then (q2, k2) ← APPLYROPE(q2, k2, rope2)
-
[63]
Construct joint token pools: if α1 = 1 then q⋆ 1 ← [q1; q2], k⋆ 1 ← [k1; k2], v⋆ 1 ← [v1; v2] else (q⋆ 1, k⋆ 1, v⋆
-
[64]
← (q1, k1, v1) if α2 = 1 then q⋆ 2 ← [q2; q1], k⋆ 2 ← [k2; k1], v⋆ 2 ← [v2; v1] else (q⋆ 2, k⋆ 2, v⋆
-
[65]
Split heads and apply masks: (q⋆ 1, k⋆ 1, v⋆
-
[66]
← SPLIT HEADS (q⋆ 1, k⋆ 1, v⋆ 1) (q⋆ 2, k⋆ 2, v⋆
-
[67]
← SPLIT HEADS (q⋆ 2, k⋆ 2, v⋆ 2) if mask1 ̸= ∅ ∧ α1 = 1 then M1 ← CUSTOM DIAGMASK (L1, L2, mask1) else M1 ← ∅ if mask2 ̸= ∅ ∧ α2 = 1 then M2 ← CUSTOM DIAGMASK (L2, L1, mask2) else M2 ← ∅
-
[68]
Compute scaled dot-product attention: o⋆ 1 ← SDPA(q⋆ 1, k⋆ 1, v⋆ 1, M1) o⋆ 2 ← SDPA(q⋆ 2, k⋆ 2, v⋆ 2, M2)
-
[69]
Merge heads, trim to original length, and project: o1 ← MERGE HEADS (o⋆ 1)[:, : L1], o1 ← attn1.OUT PROJ(o1) o2 ← MERGE HEADS (o⋆ 2)[:, : L2], o2 ← attn2.OUT PROJ(o2) return (o1, o2) 5
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.