The Unseen Hand: Manipulating Model Fairness and SHAP with Targeted Identity Re-Association Attacks
Pith reviewed 2026-06-26 09:05 UTC · model grok-4.3
The pith
Targeted identity re-association attacks can drive fairness metrics to ideal values while reducing SHAP attribution for protected features to zero.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TIRA attacks, through the algorithms Probabilistic Micro-Shuffling (PMiS) and Probabilistic Rank-Shift Micro-Perturbation (PRSMP), iteratively and probabilistically manipulate model outputs to push fairness metrics toward ideal values and confound SHAP-based explanations, leaving effectively zero residual attribution for protected features, without requiring access to the model's internals or feature representations and without leaving detectable artifacts.
What carries the argument
Targeted Identity Re-Association (TIRA) attacks, which apply localized adjacent swaps or small randomized rank shifts to re-associate identities in the input data and thereby alter model outputs and attributions.
Load-bearing premise
The attacks can be performed iteratively and probabilistically to manipulate outputs without requiring access to the model's internals or feature representations while leaving no detectable artifacts.
What would settle it
Apply a TIRA attack to a dataset with known protected features, retrain or query the model, compute SHAP values, and check whether the attribution scores for the protected features remain at or near zero.
Figures
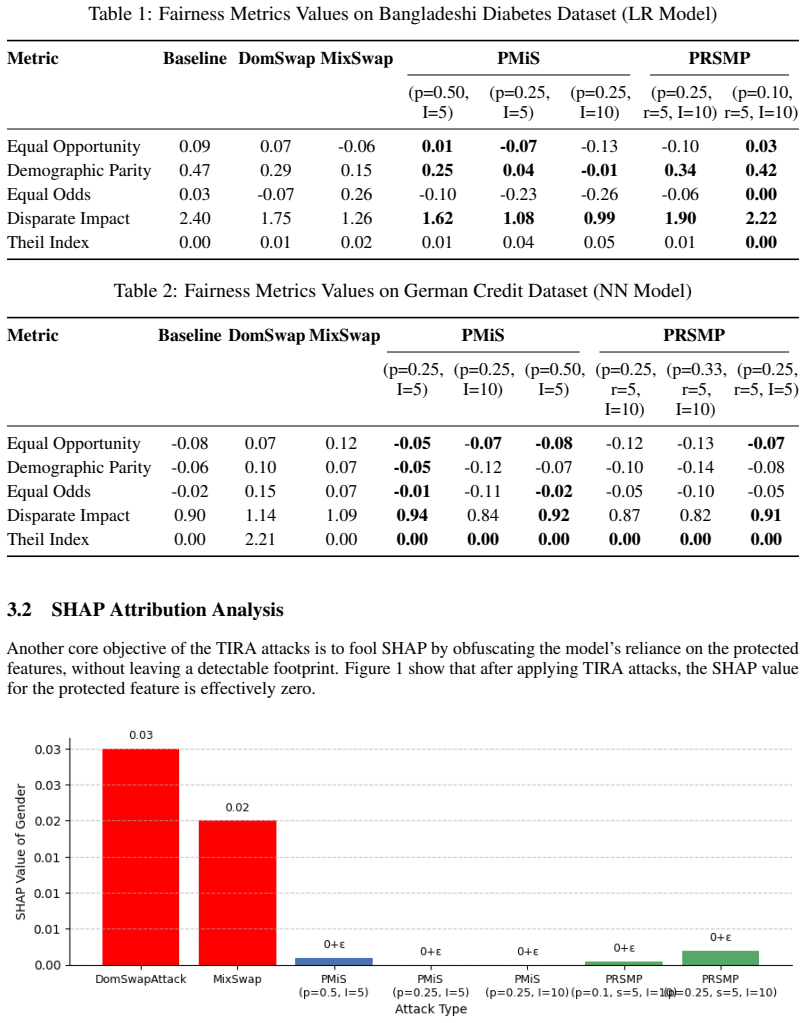
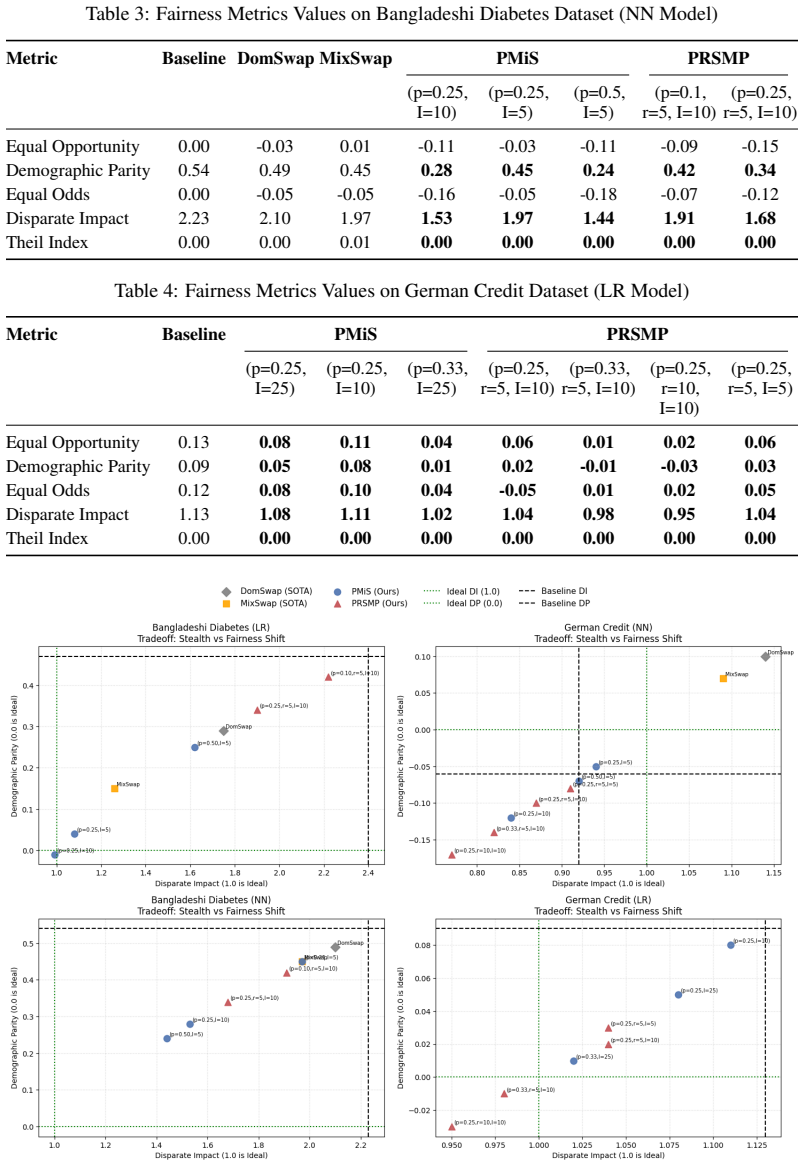
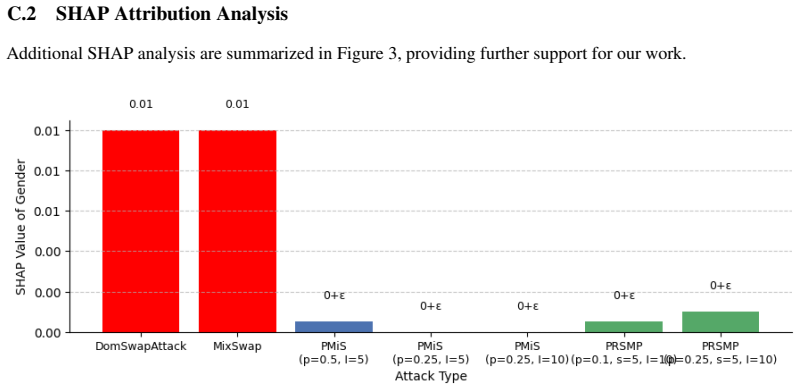
read the original abstract
As machine learning models grow more influential and opaque, algorithmic fairness and explainability are critical for ensuring accountability. However, we demonstrate that these auditing mechanisms are themselves vulnerable to subtle manipulation, camouflaging the influence of protected features. While prior work on data-agnostic attacks has exposed this vulnerability, they leave behind detectable artifacts that compromise their stealth. We introduce Targeted Identity Re-Association (TIRA) attacks, a novel family of attacks that iteratively and probabilistically manipulate a model's outputs without requiring access to the model's internals or feature representations. We formalize two algorithms: Probabilistic Micro-Shuffling (PMiS), which applies localized adjacent swaps, and Probabilistic Rank-Shift Micro-Perturbation (PRSMP), which introduces small, randomized rank shifts. We empirically demonstrate that TIRA attacks are highly effective at pushing fairness metrics towards ideal values. Crucially, TIRA attacks successfully confound SHAP-based explanations, leaving effectively zero residual attribution for protected features, a major improvement over prior work.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Targeted Identity Re-Association (TIRA) attacks, formalized as Probabilistic Micro-Shuffling (PMiS) and Probabilistic Rank-Shift Micro-Perturbation (PRSMP). These are claimed to iteratively and probabilistically alter model outputs to drive fairness metrics to ideal values and reduce protected-feature attributions in SHAP explanations to effectively zero, without requiring access to model internals or feature representations, and without the detectable artifacts left by prior data-agnostic attacks.
Significance. If the empirical claims were substantiated, the work would be significant for exposing vulnerabilities in both fairness auditing and post-hoc explainability methods, with potential implications for regulatory and deployment practices. The absence of any supporting experiments, however, prevents any assessment of whether those implications are warranted.
major comments (1)
- [Abstract] Abstract: the central claim that TIRA attacks are 'highly effective at pushing fairness metrics towards ideal values' and 'successfully confound SHAP-based explanations, leaving effectively zero residual attribution for protected features' is presented as an empirical result, yet the manuscript supplies no datasets, models, quantitative metrics, tables, figures, or experimental protocol. This absence renders the primary contribution unevaluable and is load-bearing for the paper's thesis.
Simulated Author's Rebuttal
We thank the referee for their careful reading and for highlighting this critical issue. We address the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that TIRA attacks are 'highly effective at pushing fairness metrics towards ideal values' and 'successfully confound SHAP-based explanations, leaving effectively zero residual attribution for protected features' is presented as an empirical result, yet the manuscript supplies no datasets, models, quantitative metrics, tables, figures, or experimental protocol. This absence renders the primary contribution unevaluable and is load-bearing for the paper's thesis.
Authors: We agree that the current manuscript does not contain the required experimental section, datasets, models, metrics, tables, figures, or protocol. The abstract's empirical claims are therefore unsupported in the submitted version. This constitutes a substantive omission. In the revised manuscript we will add a complete experimental evaluation section that specifies the datasets, models, fairness and SHAP metrics (with before/after values), quantitative results, tables, figures, and a reproducible experimental protocol. revision: yes
Circularity Check
No significant circularity
full rationale
The manuscript introduces TIRA attacks (PMiS and PRSMP) as empirical methods and reports their observed effects on fairness metrics and SHAP attributions. The provided text contains no equations, derivations, fitted parameters, or self-citations that could reduce any claim to its own inputs by construction. The central claims are presented as experimental outcomes rather than mathematical predictions or uniqueness theorems, so no load-bearing step matches any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A. B. Arrieta, N. Díaz-Rodríguez, J. Del Ser, A. Bennetot, S. Tabik, A. Barbado, S. García, S. Gil- López, D. Molina, R. Benjamins, R. Chatila, and F. Herrera. Explainable artificial intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI.Information Fusion, 2020. URLhttps://arxiv.org/abs/1910.10045
-
[2]
R. K. E. Bellamy, K. Dey, M. Hind, S. C. Hoffman, S. Houde, K. Kannan, P. Lohia, J. Martino, S. Mehta, A. Mojsilovic, S. Nagar, K. N. Ramamurthy, J. Richards, D. Saha, P. Sattigeri, M. Singh, K. R. Varshney, and Y . Zhang. AI fairness 360: An extensible toolkit for detecting and mitigating algorithmic bias.IBM Journal of Research and Development, 2019. UR...
work page internal anchor Pith review Pith/arXiv arXiv 2019
- [3]
-
[4]
B. Dimanov, U. Bhatt, M. Jamnik, and A. Weller. You shouldn’t trust me: Learning models which conceal unfairness from multiple explanation methods. InECAI, 2020. URL https://ebooks.iospress.nl/ pdf/doi/10.3233/FAIA200380
-
[5]
S. A. Friedler, C. Scheidegger, S. Venkatasubramanian, S. Choudhary, E. P. Hamilton, and D. Roth. A comparative study of fairness-enhancing interventions in machine learning. InProceedings of the Conference on Fairness, Accountability, and Transparency, 2019. URLhttps://arxiv.org/abs/1802. 04422
2019
-
[6]
H. Hofmann. Statlog (german credit data). UCI Machine Learning Repository, 1994. DOI: https: //doi.org/10.24432/C5NC77
-
[7]
Islam, R
M. Islam, R. Ferdousi, S. Rahman, and H. Y . Bushra. Likelihood prediction of diabetes at early stage using data mining techniques. InComputer Vision and Machine Intelligence in Medical Image Analysis: International Symposium, ISCMM 2019, 2020. URL https://link.springer.com/chapter/10. 1007/978-981-15-2428-2_10
2019
-
[8]
G. Laberge, U. Aïvodji, S. Hara, M. Marchand, and F. Khomh. Fool SHAP with stealthily biased sampling. InICLR, 2023. URLhttps://arxiv.org/abs/2205.15419
-
[9]
A Unified Approach to Interpreting Model Predictions
S. Lundberg and S. I. Lee. A unified approach to interpreting model predictions. InNeurIPS, 2017. URL https://arxiv.org/abs/1705.07874
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[10]
"Why Should I Trust You?": Explaining the Predictions of Any Classifier
M. T. Ribeiro, S. Singh, and C. Guestrin. "why should i trust you?": Explaining the predictions of any classifier. InKDD, 2016. URLhttps://arxiv.org/abs/1602.04938
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[11]
C. Rudin. Stop explaining black box machine learning models for high-stakes decisions and use inter- pretable models instead.Nature Machine Intelligence, 2019. URL https://pmc.ncbi.nlm.nih.gov/ articles/PMC9122117/pdf/nihms-1058031.pdf
2019
- [12]
- [13]
-
[14]
T. Speicher, H. Heidari, N. Grgic-Hlaca, K. P. Gummadi, A. Singla, A. Weller, and M. B. Zafar. A unified approach to quantifying algorithmic unfairness: Measuring individual & group unfairness via inequality indices. InACM SIGKDD International Conference on Knowledge Discovery and Data Mining Proceedings, 2018. URLhttps://arxiv.org/abs/1807.00787
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[15]
Axiomatic Attribution for Deep Networks
M. Sundararajan, A. Taly, and Q. Yan. Axiomatic attribution for deep networks. InICML, 2017. URL https://arxiv.org/abs/1703.01365
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[16]
J. Yuan and A. Dasgupta. Fooling SHAP with output shuffling attacks. InAAAI, 2024. URL https: //arxiv.org/abs/2408.06509. 5 A Related Work Explainability aims to render opaque deep learning models understandable and transparent [ 11]. Rooted in co-operative game theory, SHAP stands as a cornerstone of post-hoc explainability. SHAP offers a theoretically g...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.