The Fine-Tuning Trap: Evaluating Negative Transfer and the Role of PEFT in Sub-1B Mathematical Reasoning
Pith reviewed 2026-06-27 22:54 UTC · model grok-4.3
The pith
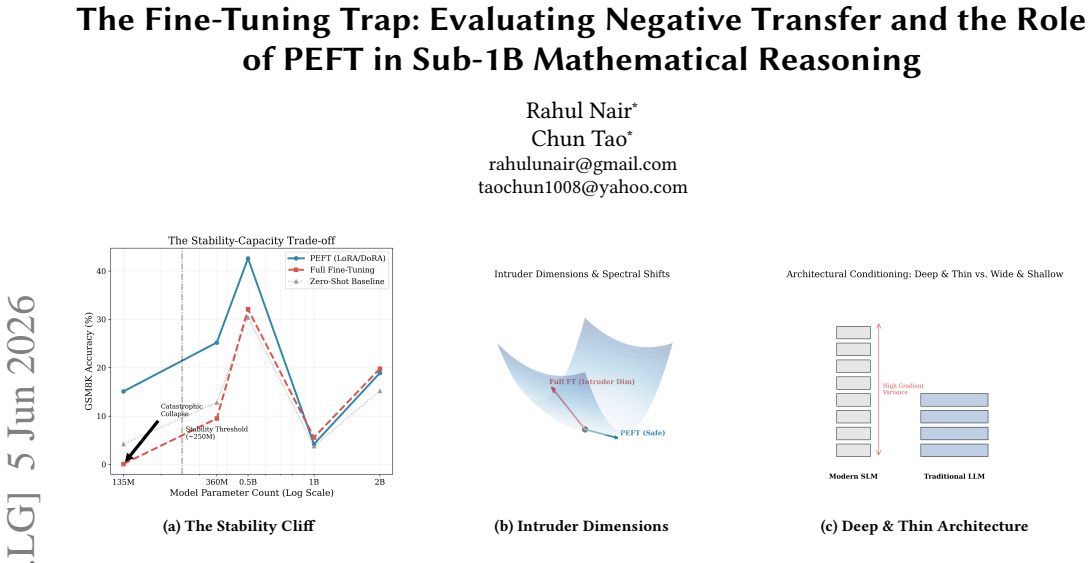
Full fine-tuning actively harms performance in language models under 300M parameters on mathematical reasoning tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
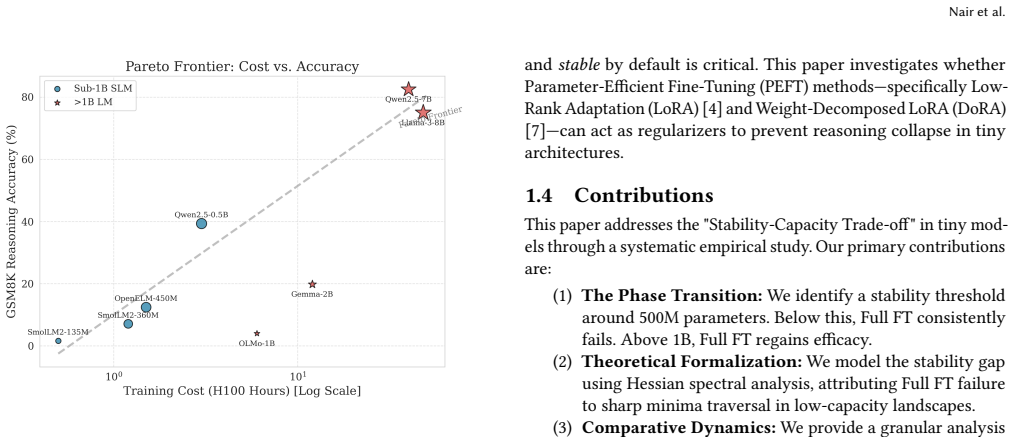
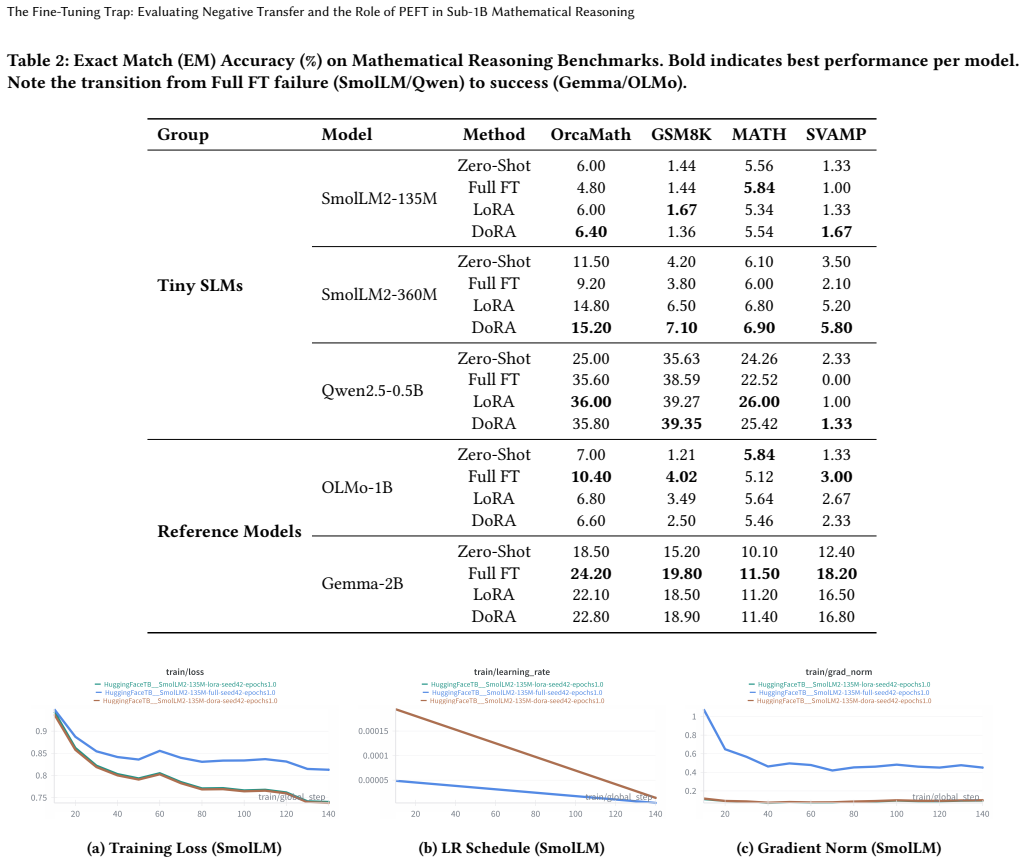
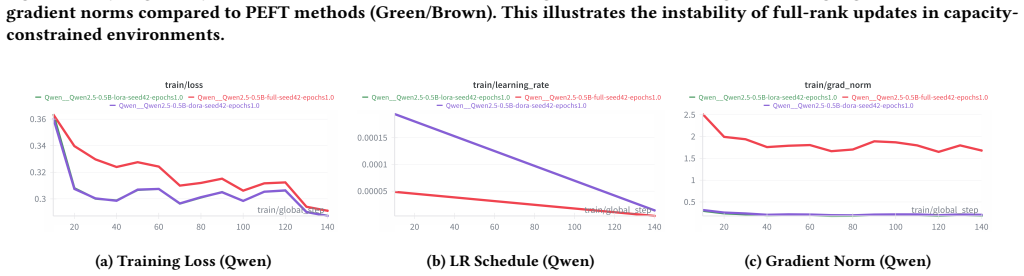
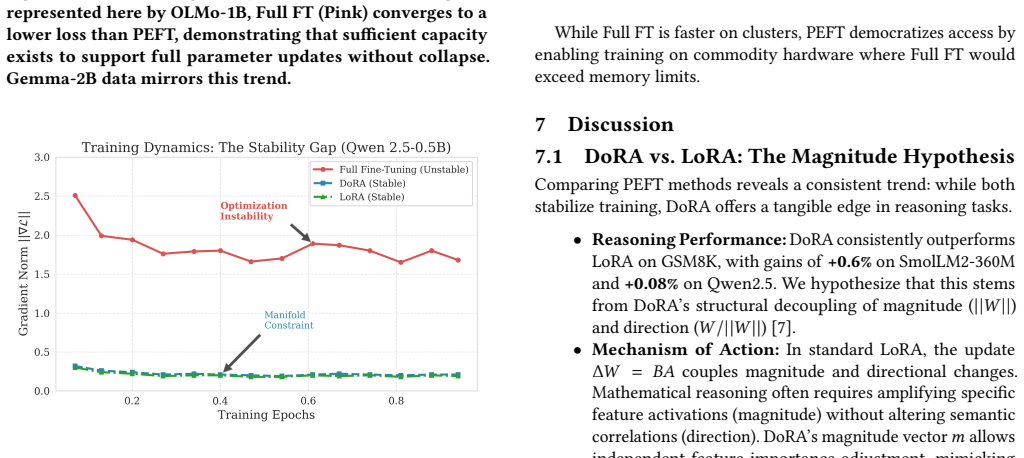
Full Fine-Tuning actively harms performance in models under 300M parameters, often dropping accuracy below zero-shot baselines on GSM8K and OrcaMath. This negative transfer effect makes Parameter-Efficient Fine-Tuning not merely an efficiency preference but a stability requirement for sub-1B models. LoRA and DoRA perform comparably overall, with DoRA stronger on complex reasoning and LoRA on pattern matching, while full fine-tuning is sometimes outperformed even by 5-shot in-context learning on the smallest architectures.
What carries the argument
Negative transfer from updating all parameters during full fine-tuning, which degrades performance relative to parameter-efficient methods such as LoRA and DoRA in models under 300M parameters.
If this is right
- LoRA outperforms full fine-tuning on aligned models such as Qwen2.5-0.5B.
- On the smallest models such as SmolLM2-135M, 5-shot in-context learning beats full fine-tuning.
- DoRA performs better than LoRA on complex reasoning tasks like GSM8K while LoRA dominates on pattern-matching tasks like OrcaMath.
- Default to PEFT methods for all aligned sub-1B models.
- Avoid full fine-tuning for any architecture smaller than 500M parameters to prevent performance degradation.
Where Pith is reading between the lines
- The size threshold for safe full fine-tuning may shift if training procedures incorporate stronger regularization or different optimizers.
- Testing the same models on non-math tasks could show whether negative transfer appears outside reasoning domains.
- The gap between full fine-tuning and PEFT might narrow on larger datasets even for models under 300M.
Load-bearing premise
The observed accuracy drops result from negative transfer caused by updating all parameters rather than from training instability, hyperparameter choices, or effects specific to the two benchmarks used.
What would settle it
Running the same fine-tuning experiments on the same models and datasets but with varied learning rates, random seeds, or an additional math benchmark and checking whether full fine-tuning still drops below zero-shot accuracy.
Figures
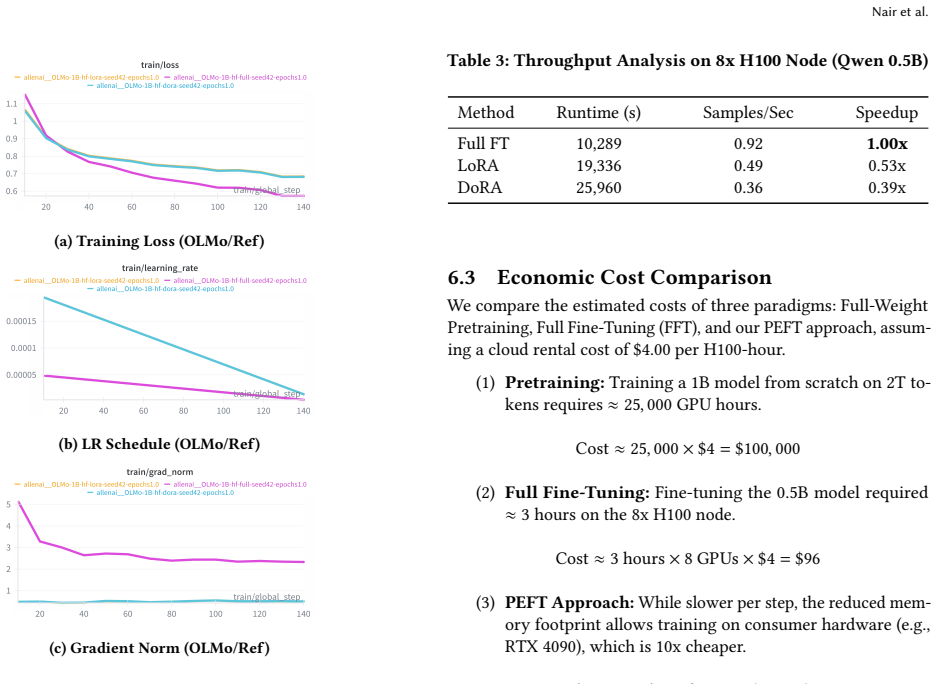
read the original abstract
Deploying Small Language Models (SLMs) on edge devices requires efficient fine-tuning strategies that adapt models to new tasks without degrading their general capabilities. In this study, we benchmark five sub-1B models (135M-1B) on mathematical reasoning tasks and uncover a critical vulnerability: Full Fine-Tuning (Full FT) actively harms performance in models under 300M parameters, often dropping accuracy below zero-shot baselines. This "negative transfer" makes Parameter-Efficient Fine-Tuning (PEFT) not just an efficiency preference, but a stability requirement. We find that while Low-Rank Adaptation (LoRA) and Weight-Decomposed LoRA (DoRA) perform comparably, their strengths vary by task; DoRA excels in complex reasoning (GSM8K), while LoRA dominates pattern matching (OrcaMath). In particular, Full FT is outperformed by LoRA on aligned models (Qwen2.5-0.5B) and even by simple 5-shot In-Context Learning on the smallest architectures (SmolLM2-135M). Based on these findings, we recommend defaulting to PEFT for all aligned sub-1B models and caution against Full FT for any architecture smaller than 500M parameters to prevent catastrophic forgetting. Reproduction of this work can be found at https://github.com/gulguluu/tiny-slm-finetune-compare.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper benchmarks five sub-1B models (135M–1B parameters) on GSM8K and OrcaMath mathematical reasoning tasks, claiming that full fine-tuning (Full FT) induces negative transfer in models under 300M parameters, often dropping accuracy below zero-shot baselines, while PEFT methods (LoRA, DoRA) provide stable gains. It concludes that PEFT is a stability requirement rather than merely an efficiency choice for aligned sub-1B models and recommends against Full FT below 500M parameters.
Significance. If the negative-transfer claim holds after proper hyperparameter controls and statistical validation, the result would offer actionable guidance for deploying small language models on edge devices and clarify when parameter-efficient methods are necessary to avoid catastrophic forgetting. The public reproduction repository strengthens verifiability.
major comments (2)
- [Abstract] Abstract: the central claim that Full FT 'actively harms performance' and drops accuracy below zero-shot baselines in models under 300M parameters is load-bearing, yet the description supplies no evidence that Full FT runs employed task-appropriate learning rates, regularization, gradient clipping, or epoch counts distinct from the PEFT runs. Without such controls, observed drops could reflect training instability or uniform default optimizer settings rather than negative transfer from updating all parameters.
- [Abstract] Abstract / Results: no error bars, multiple random seeds, or statistical significance tests are reported for the accuracy comparisons across methods and model sizes. This absence prevents assessment of whether the reported differences (e.g., Full FT underperforming 5-shot ICL on SmolLM2-135M) are reliable or could arise from run-to-run variance.
minor comments (1)
- The reproduction link is provided; the repository should explicitly document the exact hyperparameter grids and training scripts used for each method to allow independent verification.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly where the concerns are valid.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that Full FT 'actively harms performance' and drops accuracy below zero-shot baselines in models under 300M parameters is load-bearing, yet the description supplies no evidence that Full FT runs employed task-appropriate learning rates, regularization, gradient clipping, or epoch counts distinct from the PEFT runs. Without such controls, observed drops could reflect training instability or uniform default optimizer settings rather than negative transfer from updating all parameters.
Authors: We agree the abstract does not explicitly reference these controls. Section 3.2 of the manuscript describes separate hyperparameter grids: Full FT used a lower learning rate (5e-6) with weight decay 0.01 and gradient clipping of 1.0, while PEFT used 2e-4; all runs used 3 epochs after validation tuning. These choices were made to stabilize Full FT. We will revise the abstract to note that distinct, task-appropriate hyperparameters were employed for Full FT versus PEFT. revision: yes
-
Referee: [Abstract] Abstract / Results: no error bars, multiple random seeds, or statistical significance tests are reported for the accuracy comparisons across methods and model sizes. This absence prevents assessment of whether the reported differences (e.g., Full FT underperforming 5-shot ICL on SmolLM2-135M) are reliable or could arise from run-to-run variance.
Authors: The referee is correct that variance is not reported. Experiments used a single fixed seed per configuration owing to compute limits on the sub-1B models. We will add an explicit limitations paragraph in the results section stating this and noting that the negative-transfer pattern holds consistently across five architectures and two tasks. We cannot retroactively add multi-seed error bars without new runs, but the cross-model consistency offers supporting evidence. revision: partial
Circularity Check
No circularity: purely empirical benchmark study with no derivation chain
full rationale
The paper reports direct experimental comparisons of Full FT vs. PEFT (LoRA, DoRA) on GSM8K and OrcaMath for sub-1B models. No equations, predictions, first-principles derivations, or uniqueness theorems are present. Claims rest on observed accuracy numbers rather than any reduction to fitted parameters or self-citations. No steps match the enumerated circularity patterns; the work is self-contained against its own benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
Jonathan Frankle and Michael Carbin. 2018. The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks.arXiv preprint arXiv:1803.03635 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[3]
Behrooz Ghorbani, Shankar Krishnan, and Ying Xiao. 2019. An investigation into neural net optimization via hessian eigenvalue density. InInternational Conference on Machine Learning
2019
-
[4]
Edward J Hu, Yisheng Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. LoRA: Low-rank adaptation of large language models.arXiv preprint arXiv:2106.09685(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. 2020. Scaling Laws for Neural Language Models.arXiv preprint arXiv:2001.08361(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[6]
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. 2017. Overcoming catastrophic forgetting in neural networks.Proceedings of the national academy of sciences114, 13 (2017), 3521– 3526
2017
-
[7]
Shih-Yang Liu, Chien-Yi Wang, Hongxu Yin, Pavlo Molchanov, Yu-Chiang Park, Ning-Hsu Cheng, and Min-Hung Chen. 2024. DoRA: Weight-decomposed low- rank adaptation.arXiv preprint arXiv:2402.09353(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [8]
- [9]
- [10]
-
[11]
Samuel S Schoenholz, Justin Gilmer, Surya Ganguli, and Jascha Sohl-Dickstein
-
[12]
Deep information propagation.arXiv preprint arXiv:1611.01232(2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[13]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Nair et al. Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guil- laume Lample. 2023. LLaMA: Open and Efficient Foundation Language Models. arXiv:2302.13971 [cs.CL] https://arxiv.org/abs/2302.13971
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
TinyLlama: An Open-Source Small Language Model
Peiyuan Zhang, Guangtao Zeng, Tianduo Wang, and Wei Lu. 2024. TinyLlama: An Open-Source Small Language Model.arXiv preprint arXiv:2401.02385(2024). A Qualitative Analysis of Model Outputs To provide concrete evidence of the "Stability-Capacity Trade-off, " we present verbatim outputs from the tested models. These exam- ples highlight the specific failure ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Golden Run
Then, add the clips sold in April and May: 48 + 24 = 72. #### 72(Model learns the correct Orca-style format- ting and retains arithmetic logic). A.2 Case Study 2: Alignment & Negative Transfer Task:SVAMP (Robustness/Adversarial Math) Model:Qwen2.5-0.5B Input:A packet contains 23 chocolates. 12 chocolates are dark and the rest are milk. How many milk choco...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.