Strategic Over-Parameterization for Generalizable Low-Rank Adaptation
Pith reviewed 2026-05-20 20:03 UTC · model grok-4.3
The pith
LoRA-Over adds auxiliary parameters during training to expand adaptation options then folds them back into low-rank form at inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
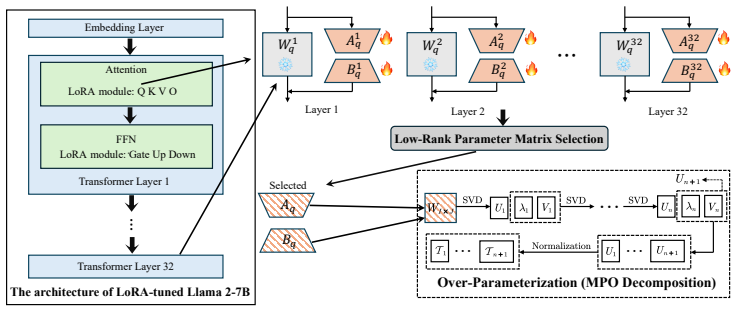
LoRA-Over injects auxiliary parameters into the low-rank adapters during training to broaden the effective hypothesis space, and through a decomposition-based reformulation folds them back into a standard low-rank structure with negligible reconstruction error, keeping inference cost identical to vanilla LoRA. Scheduling strategies, either static or dynamic, allocate the extra capacity to the weight matrices that benefit most from it.
What carries the argument
The decomposition-based reformulation that absorbs auxiliary parameters back into the base low-rank matrices while retaining the generalization gains from training.
If this is right
- LoRA-Over outperforms vanilla LoRA on language understanding benchmarks such as GLUE with T5-Base.
- The method improves results on dialogue, arithmetic reasoning, and code generation tasks using LLaMA 2-7B and LLaMA 3.1-8B.
- Static predefined and dynamic runtime scheduling direct extra capacity to the matrices that gain most from it.
- Inference cost and speed stay identical to standard LoRA across all tested scales.
Where Pith is reading between the lines
- The vanishing-over-parameterization principle could be tested on other parameter-efficient methods to see whether similar generalization lifts appear.
- Dynamic scheduling of extra capacity might become useful when adapting models much larger than 8B where layer-wise needs vary sharply.
- If reconstruction error stays negligible in practice, designers could safely increase the amount of temporary capacity without deployment penalties.
Load-bearing premise
The auxiliary parameters added during training can be folded back into the low-rank structure with negligible reconstruction error while preserving the generalization benefits.
What would settle it
Measure the reconstruction error after the folding step on a held-out task; if error remains low yet performance gains disappear compared with vanilla LoRA, the central claim would be falsified.
Figures


read the original abstract
Adapting large language models (LLMs) to downstream tasks via full fine-tuning is increasingly impractical due to its computational and memory demands. Parameter-efficient fine-tuning (PEFT) approaches such as Low-Rank Adaptation (LoRA) mitigate this by confining updates to a compact set of trainable parameters, but this aggressive reduction often sacrifices generalization, especially under transfer across heterogeneous tasks and domains. We revisit the tension between parameter efficiency and adaptation capacity, and ask whether the two are truly at odds. We answer in the negative by introducing LoRA-Over, a framework grounded in a simple principle: enrich the optimization landscape during training, then collapse the enrichment at inference. LoRA-Over injects auxiliary parameters into the low-rank adapters during training to broaden the effective hypothesis space, and through a decomposition-based reformulation folds them back into a standard low-rank structure with negligible reconstruction error, keeping inference cost identical to vanilla LoRA. Since not all weight matrices benefit equally from added capacity, we further propose two scheduling strategies, one statically predefined and one dynamically determined at runtime, that direct extra capacity where most needed. We evaluate LoRA-Over on language understanding (GLUE, T5-Base), dialogue (MT-Bench), arithmetic reasoning (GSM8K), and code generation (HumanEval), using LLaMA 2-7B and LLaMA 3.1-8B. Across all benchmarks and scales, LoRA-Over consistently outperforms vanilla LoRA, showing that principled over-parameterization designed to vanish at inference is an effective lever for improving PEFT generalization. Code will be released upon acceptance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces LoRA-Over, a PEFT method that augments standard LoRA adapters with auxiliary parameters during training to expand the hypothesis space, then applies a decomposition-based reformulation to recover an equivalent low-rank structure at inference with negligible reconstruction error. Two scheduling strategies (static and dynamic) allocate the extra capacity selectively across weight matrices. Experiments on GLUE and T5-Base for language understanding, MT-Bench for dialogue, GSM8K for arithmetic reasoning, and HumanEval for code generation, using LLaMA 2-7B and LLaMA 3.1-8B, report consistent outperformance over vanilla LoRA while preserving identical inference cost.
Significance. If the central claim holds, the approach offers a practical lever for improving generalization in parameter-efficient fine-tuning without deployment overhead, which could influence standard practice for adapting large models. The planned code release supports reproducibility and is a positive contribution.
major comments (2)
- [§3.2] §3.2 (Decomposition reformulation): The assertion that auxiliary parameters are folded back 'with negligible reconstruction error' while preserving generalization gains is load-bearing for the central claim, yet the manuscript provides no quantitative reconstruction error values, layer-wise error statistics, or theoretical bound on the projection error; without this, it remains unclear whether the training-time benefit survives the decomposition step.
- [§4.3] §4.3 and Table 3 (Ablation studies): The reported gains are not accompanied by an ablation that isolates the contribution of the auxiliary-parameter stage from the scheduling strategies; this weakens the ability to attribute outperformance specifically to the over-parameterization principle rather than to the scheduling heuristics.
minor comments (2)
- [Eq. (5)] The notation distinguishing the auxiliary parameters (e.g., in Eq. (5)) from the base LoRA matrices could be made more explicit to avoid reader confusion during the decomposition derivation.
- [Figure 2] Figure 2 (scheduling visualization) would benefit from an additional panel or caption detail showing how the dynamic schedule evolves over training epochs on a representative task.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major point below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Decomposition reformulation): The assertion that auxiliary parameters are folded back 'with negligible reconstruction error' while preserving generalization gains is load-bearing for the central claim, yet the manuscript provides no quantitative reconstruction error values, layer-wise error statistics, or theoretical bound on the projection error; without this, it remains unclear whether the training-time benefit survives the decomposition step.
Authors: We agree that explicit quantitative support for the reconstruction error claim would improve clarity. The decomposition is an exact algebraic reformulation (via SVD on the augmented low-rank factors), so the error is theoretically zero in exact arithmetic and arises only from floating-point precision. In the revised manuscript we will add a new paragraph and table in §3.2 reporting (i) mean and maximum Frobenius-norm reconstruction error across all layers and runs (observed values < 5×10^{-6}), (ii) layer-wise statistics for both LLaMA-2-7B and LLaMA-3.1-8B, and (iii) a simple theoretical bound derived from the operator norm of the auxiliary-parameter injection. These additions will confirm that the error is negligible and does not erode the reported generalization gains. revision: yes
-
Referee: [§4.3] §4.3 and Table 3 (Ablation studies): The reported gains are not accompanied by an ablation that isolates the contribution of the auxiliary-parameter stage from the scheduling strategies; this weakens the ability to attribute outperformance specifically to the over-parameterization principle rather than to the scheduling heuristics.
Authors: We acknowledge that the existing ablations in Table 3 vary the over-parameterization ratio and compare static versus dynamic scheduling, but do not fully decouple the auxiliary-parameter injection from the scheduling mechanism. In the revision we will add a new row to Table 3 (and corresponding text in §4.3) that reports results for LoRA-Over with auxiliary parameters but uniform (non-strategic) allocation. This configuration isolates the benefit of the over-parameterization stage itself from the scheduling heuristics and will allow readers to attribute performance gains more precisely. revision: yes
Circularity Check
No significant circularity; empirical gains rest on held-out benchmarks rather than definitional reduction.
full rationale
The paper proposes LoRA-Over by adding auxiliary parameters to broaden the training hypothesis space and then applying a decomposition-based reformulation to recover a standard low-rank adapter at inference. The central claim of improved generalization is supported by direct evaluation on external benchmarks (GLUE, MT-Bench, GSM8K, HumanEval) using LLaMA models, not by any equation or self-citation that reduces the reported outperformance to a fitted quantity or prior result by construction. No load-bearing step equates a prediction to its own inputs; the method and its benefits are independently testable outside the paper's fitted values.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The low-rank decomposition of the enriched adapter matrices can be performed with reconstruction error small enough not to erase the generalization gains obtained during training.
invented entities (1)
-
auxiliary parameters injected into low-rank adapters
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
LoRA-Over injects auxiliary parameters into the low-rank adapters during training to broaden the effective hypothesis space, and through a decomposition-based reformulation folds them back into a standard low-rank structure with negligible reconstruction error
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we employ the Matrix Product Operator (MPO) from quantum many-body physics as our primary method for matrix decomposition
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
D. Arpit and Y . Bengio. The benefits of over-parameterization at initialization in deep relu networks. arXiv preprint arXiv:1901.03611,
- [2]
- [3]
-
[4]
K. Büyükakyüz. Olora: Orthonormal low-rank adaptation of large language models.arXiv preprint arXiv:2406.01775,
-
[5]
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. D. O. Pinto, J. Kaplan, H. Edwards, Y . Burda, N. Joseph, G. Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Training Verifiers to Solve Math Word Problems
K. Cobbe, V . Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pages 4171–4186,
work page 2019
-
[8]
S. S. Du, X. Zhai, B. Poczos, and A. Singh. Gradient descent provably optimizes over-parameterized neural networks.arXiv preprint arXiv:1810.02054,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks
J. Frankle and M. Carbin. The lottery ticket hypothesis: Finding sparse, trainable neural networks. arXiv preprint arXiv:1803.03635,
work page internal anchor Pith review Pith/arXiv arXiv
- [10]
- [11]
-
[12]
Ultimate tensorization: compressing convolutional and FC layers alike
T. Garipov, D. Podoprikhin, A. Novikov, and D. Vetrov. Ultimate tensorization: compressing convolutional and fc layers alike.arXiv preprint arXiv:1611.03214,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Lora+: Efficient low rank adaptation of large models.arXiv preprint arXiv:2402.12354, 2024
S. Hayou, N. Ghosh, and B. Yu. Lora+: Efficient low rank adaptation of large models.arXiv preprint arXiv:2402.12354,
- [15]
-
[16]
Fedpara: Low-rank hadamard product for communication-efficient federated learning,
N. Hyeon-Woo, M. Ye-Bin, and T.-H. Oh. Fedpara: Low-rank hadamard product for communication- efficient federated learning.arXiv preprint arXiv:2108.06098,
-
[17]
A Rank Stabilization Scaling Factor for Fine-Tuning with LoRA
D. Kalajdzievski. A rank stabilization scaling factor for fine-tuning with lora.arXiv preprint arXiv:2312.03732,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
P. Liu, Z.-F. Gao, W. X. Zhao, Z.-Y . Xie, Z.-Y . Lu, and J.-R. Wen. Enabling lightweight fine-tuning for pre-trained language model compression based on matrix product operators.arXiv preprint arXiv:2106.02205, 2021a. S. Liu, L. Yin, D. C. Mocanu, and M. Pechenizkiy. Do we actually need dense over-parameterization? in-time over-parameterization in sparse...
-
[19]
Y . Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, and V . Stoy- anov. Roberta: A robustly optimized bert pretraining approach.arXiv preprint arXiv:1907.11692,
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[20]
Decoupled Weight Decay Regularization
I. Loshchilov and F. Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Pruning Convolutional Neural Networks for Resource Efficient Inference
P. Molchanov, S. Tyree, T. Karras, T. Aila, and J. Kautz. Pruning convolutional neural networks for resource efficient inference.arXiv preprint arXiv:1611.06440,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
S. Prasanna, A. Rogers, and A. Rumshisky. When bert plays the lottery, all tickets are winning.arXiv preprint arXiv:2005.00561,
-
[23]
Llama 2: Open Foundation and Fine-Tuned Chat Models
H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y . Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned
E. V oita, D. Talbot, F. Moiseev, R. Sennrich, and I. Titov. Analyzing multi-head self-attention: Specialized heads do the heavy lifting, the rest can be pruned.arXiv preprint arXiv:1905.09418,
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[25]
A. Wang, A. Singh, J. Michael, F. Hill, O. Levy, and S. R. Bowman. Glue: A multi-task benchmark and analysis platform for natural language understanding.arXiv preprint arXiv:1804.07461,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
L. Yu, W. Jiang, H. Shi, J. Yu, Z. Liu, Y . Zhang, J. T. Kwok, Z. Li, A. Weller, and W. Liu. Meta- math: Bootstrap your own mathematical questions for large language models.arXiv preprint arXiv:2309.12284,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
AdaLoRA: Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning
Q. Zhang, M. Chen, A. Bukharin, N. Karampatziakis, P. He, Y . Cheng, W. Chen, and T. Zhao. Adalora: Adaptive budget allocation for parameter-efficient fine-tuning.arXiv preprint arXiv:2303.10512,
work page internal anchor Pith review Pith/arXiv arXiv
- [28]
-
[29]
13 A Details of tensors A.1 Tensor and matrix product operators As introduced in [Gao et al., 2020], a tensor is precisely characterized as follows: Tensor.Let D1, D2,· · ·, D P ∈N denote index upper bounds. A tensor T ∈R D1,D2,···,D P of order P is a P -way array where elements T[d 1, d2,· · ·, d P ] are indexed by dp ∈ {1,2,· · ·, D P } for1≤p≤P. Matrix...
work page 2020
-
[30]
Require:matrixM, the number of local tensorsm
Algorithm 1MPO decomposition for a matrix. Require:matrixM, the number of local tensorsm. Ensure:: MPO tensor list{T (s)}m s=1. 1:fors= 1→mdo 2:M[I, J]→M[d s−1 ×i s ×j s,−1] 3:UλV T = SVD(M) 4:U[d s−1 ×i s ×j s, ds]→ U[d s−1, is, js, ds] 5:T (s) :=U 6:M:=λV T 7:end for 8:T (s) :=M 9:Normalization 10:return{T (k)}n k=1 The pseudocode for the selection of o...
work page 2022
-
[31]
All generation is performed with top_p= 0.95 and temperature T= 0.8
For natural language generation tasks, we fine-tune Llama 2-7B [Touvron et al., 2023] with a sequence length of 1024, a training batch size of 32, a weight decay of 0, and fine-tune Llama 3.1-8B [Grattafiori et al., 2024] with a sequence length of 512, a training batch size of 64, a weight decay of 5e−4 . All generation is performed with top_p= 0.95 and t...
work page 2023
-
[32]
LoRA-Over-MPOR HumanEval1e-4 7e-5 4 28 50 Table 7: Summary of the MPO structure (Llama 2-7B and Llama 3.1-8B). Shape MT-Bench GSM8K HumanEval Llama 2-7B [Touvron et al., 2023] SVD (4096,8) T 64,64 2,4 (D) T 64,64 2,4 (D) T 64,64 2,4 (D) (8,4096) T 2,4 64,64(D) T 2,4 64,64(D) T 2,4 64,64(D) (11008,8) T 86,128 2,4 (D) T 86,128 2,4 (D) T 86,128 2,4 (D) (8,11...
work page 2023
-
[33]
Our methodology is grounded in the theoretical foundation established by OPF [Gao et al., 2023], which posits that over-parameterization significantly enhances the optimization process during fine-tuning. However, a critical distinction lies in the migration of the application domain and the expansion of the theoretical boundaries. While OPF primarily exp...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.