IEA: Amateur-Friendly Conversational Image Editing Agent via Three Stages of Multitask Alignment
Pith reviewed 2026-06-27 20:17 UTC · model grok-4.3
The pith
IEA trains a vision-language model to edit images by sequentially calling 16 parameterized tools through a three-stage pipeline.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
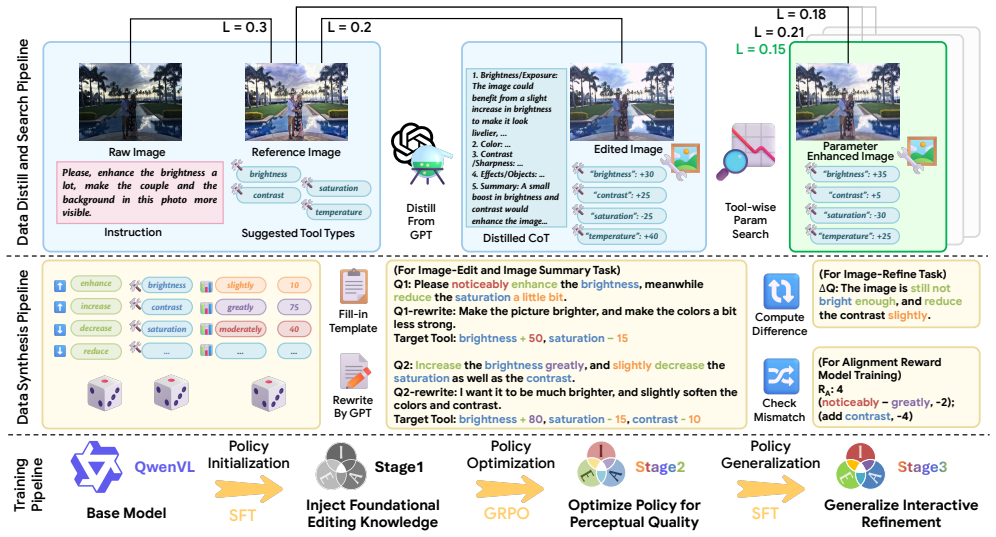
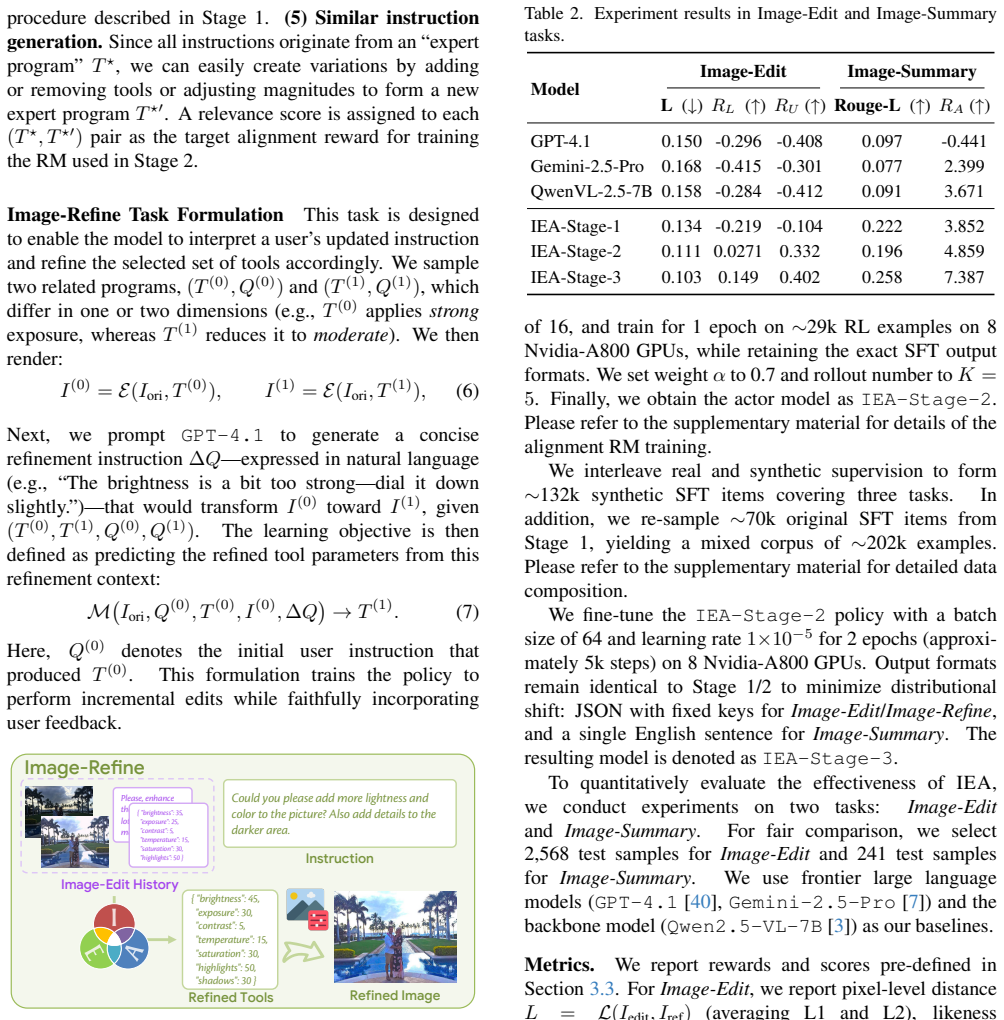
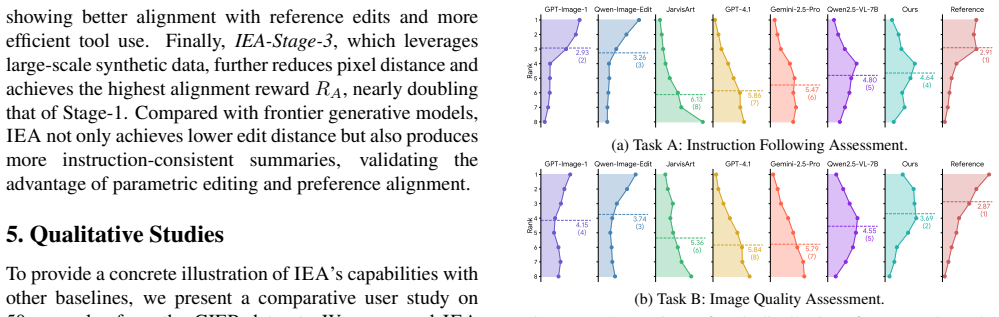
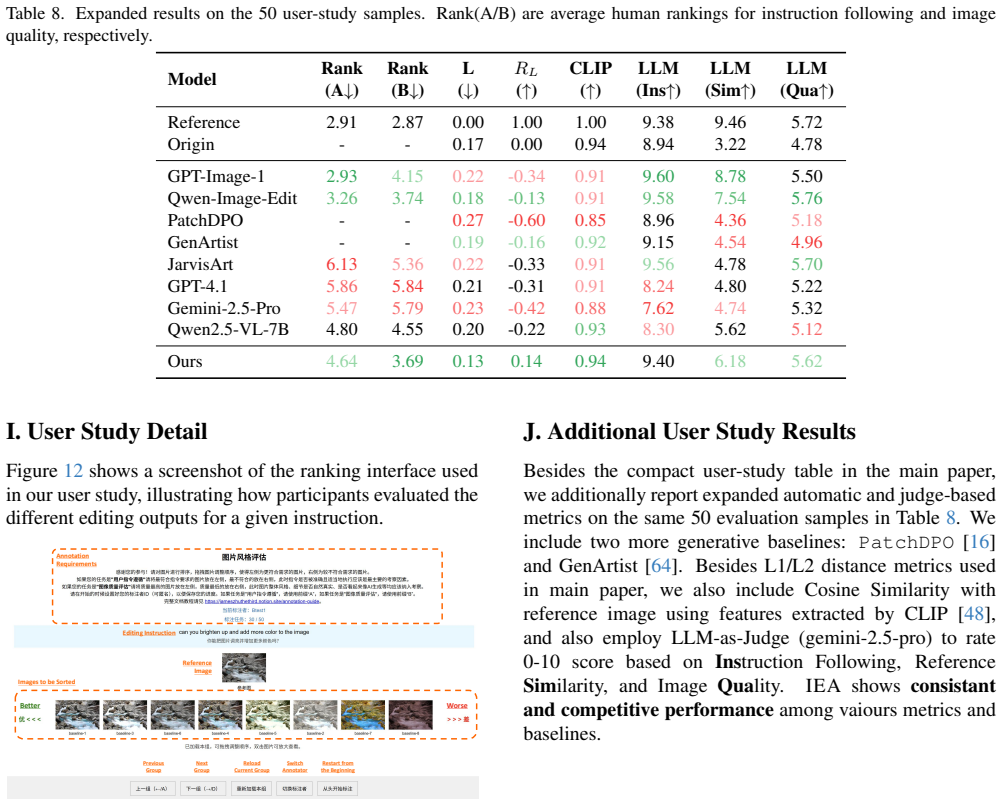
IEA is trained via a three-stage multitask pipeline: supervised fine-tuning on distilled expert edits, GRPO optimization with composite rewards for likeness improvement, tool usefulness and intent summarization, and large-scale synthetic fine-tuning. This allows the model to manipulate 16 editing tools step by step in an explicit action space, producing transparent edit traces. Quantitative results show lower pixel distance on the edit task and higher ROUGE-L on the summary task than strong baselines, while user studies rank it highest among tool-calling methods for instruction following and above generative methods for perceptual quality.
What carries the argument
The three-stage multitask alignment pipeline (SFT on distilled edits, GRPO with composite rewards, synthetic fine-tuning) that trains the model to operate 16 parameterized editing tools sequentially.
If this is right
- The agent attains lower pixel distance on the edit task than strong baselines.
- It records higher ROUGE-L scores on the intent summarization task than strong baselines.
- It ranks first among tool-calling methods for instruction following in user studies.
- It exceeds generative methods in overall perceptual quality according to user ratings.
Where Pith is reading between the lines
- The explicit tool traces could be logged and replayed inside conventional photo software, allowing hybrid human-AI retouching sessions.
- The same staged alignment approach might transfer to other sequential visual tasks such as video clip editing or 3D scene adjustment where step-by-step actions matter.
- If the reward signals prove robust, the pipeline offers a template for aligning agents in other creative domains that currently rely on opaque generative outputs.
Load-bearing premise
The three-stage training on expert demonstrations and synthetic data produces genuine generalization to real amateur instructions rather than overfitting to the reward signals and data distribution.
What would settle it
A held-out test set of editing instructions collected directly from amateur users that produces no reduction in pixel distance or user preference scores relative to the baselines.
Figures








read the original abstract
Current image editing software often hinges on fixed filters or expert tuning, leaving a gap between amateur users' intent and outcomes. Creations by generative models may contain artifacts, implausible details, or stylistic drift away from photorealism and offer little insight into why an edit was made. We propose IEA, a conversational Image Editing Agent that learns to operate parameterized tools in an explicit, interpretable action space. IEA is trained via a three-stage multitask pipeline: (1) SFT on distilled expert edits, (2) GRPO with rewards for likeness improvement, tool usefulness, and intent summarization, and (3) large-scale synthetic fine-tuning to jointly master image editing, refinement, and user intent summarization. By manipulating 16 editing tools step by step, IEA produces transparent edit traces that can be inspected and debugged. In quantitative experiments, it attains a lower pixel distance on the edit task and a higher ROUGE-L on the summary task than strong baselines. In user studies, it ranks best among tool-calling methods for instruction following while surpassing generative methods in overall perceptual quality. Our results validate interpretable, tool-centric VLMs as a reliable path to human instruction-guided image retouching.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes IEA, a conversational image editing agent that manipulates 16 parameterized tools in an explicit action space. It is trained via a three-stage multitask pipeline: (1) SFT on distilled expert edits, (2) GRPO using a composite reward (likeness improvement + tool usefulness + intent summarization), and (3) large-scale synthetic fine-tuning. The central claims are quantitative superiority (lower pixel distance on edits, higher ROUGE-L on summaries) over baselines and superior user-study rankings for instruction following and perceptual quality versus tool-calling and generative methods.
Significance. If the generalization claims hold, the work would demonstrate that interpretable, tool-centric VLMs can reliably translate amateur instructions into debuggable edit traces, addressing a practical gap between generative artifacts and fixed-filter software. The explicit three-stage alignment and composite reward formulation are notable technical contributions; reproducible code or parameter-free derivations are not mentioned.
major comments (2)
- [§4] §4 (Experiments): the quantitative claims of lower pixel distance and higher ROUGE-L rest on unspecified dataset sizes, baseline implementations, statistical tests, and error bars. Without these, it is impossible to assess whether the reported gains exceed variance or reflect genuine out-of-distribution performance on real amateur intents.
- [§3.2–3.3] §3.2–3.3 (GRPO and synthetic fine-tuning): no ablation isolates the contribution of each stage or tests whether the composite reward and synthetic data distribution correlate with the reported metrics. This is load-bearing for the central claim that the pipeline yields generalization rather than reward hacking or distribution matching.
minor comments (2)
- [Abstract, §1] Abstract and §1: the description of the 16 tools and their parameterization is referenced but not enumerated; a table or appendix listing the tools would improve reproducibility.
- [User studies] User-study protocol: the ranking methodology (pairwise vs. absolute, number of participants, inter-rater agreement) is not detailed enough to interpret the claim that IEA ranks best among tool-calling methods.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below.
read point-by-point responses
-
Referee: [§4] §4 (Experiments): the quantitative claims of lower pixel distance and higher ROUGE-L rest on unspecified dataset sizes, baseline implementations, statistical tests, and error bars. Without these, it is impossible to assess whether the reported gains exceed variance or reflect genuine out-of-distribution performance on real amateur intents.
Authors: We agree that these details are necessary for proper evaluation of the claims. The revised manuscript will report the exact training and evaluation dataset sizes, full implementation details and hyperparameters for all baselines, error bars on all quantitative results, and the outcomes of statistical significance tests. We will also expand the evaluation section to clarify the out-of-distribution nature of the amateur intent test set. revision: yes
-
Referee: [§3.2–3.3] §3.2–3.3 (GRPO and synthetic fine-tuning): no ablation isolates the contribution of each stage or tests whether the composite reward and synthetic data distribution correlate with the reported metrics. This is load-bearing for the central claim that the pipeline yields generalization rather than reward hacking or distribution matching.
Authors: We recognize that ablations are required to substantiate the contribution of the three-stage pipeline. In the revision we will add stage-wise ablations (removing GRPO or synthetic fine-tuning) together with an analysis of how each reward term correlates with the final pixel-distance and ROUGE-L metrics. These additions will directly address concerns about reward hacking versus genuine generalization. revision: yes
Circularity Check
No significant circularity; empirical pipeline self-contained with no equations or reductions
full rationale
The paper describes a three-stage multitask training pipeline (SFT on distilled edits, GRPO with composite rewards, synthetic fine-tuning) and reports empirical results on pixel distance, ROUGE-L, and user studies. No equations, fitted parameters renamed as predictions, or self-citational uniqueness theorems appear in the provided text. The central claims rest on experimental comparisons to baselines rather than any derivation that reduces outputs to inputs by construction. This is the expected outcome for an applied ML methods paper without mathematical derivation chains.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Do as i can and not as i say: Grounding language in robotic affordances
Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Chebotar, Omar Cortes, Byron David, Chelsea Finn, Chuyuan Fu, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Daniel Ho, Jasmine Hsu, Julian Ibarz, Brian Ichter, Alex Irpan, Eric Jang, Rosario Jauregui Ruano, Kyle Jeffrey, Sally Jesmonth, Nikhil Joshi, Ryan Julian, Dmitry Kalashnikov, Yuheng Kuang, Kua...
Pith/arXiv arXiv 2022
-
[2]
Blended diffusion for text-driven editing of natural images
Omri Avrahami, Dani Lischinski, and Ohad Fried. Blended diffusion for text-driven editing of natural images. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 18208–18218, 2022. 2
2022
-
[3]
Qwen2.5-vl technical report.arXiv preprint arXiv:2502.13923, 2025
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report.ar...
Pith/arXiv arXiv 2025
-
[4]
In- structpix2pix: Learning to follow image editing instructions
Tim Brooks, Aleksander Holynski, and Alexei A Efros. In- structpix2pix: Learning to follow image editing instructions. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18392–18402, 2023. 2
2023
-
[5]
Learning photographic global tonal adjustment with a database of input / output image pairs
Vladimir Bychkovsky, Sylvain Paris, Eric Chan, and Fr ´edo Durand. Learning photographic global tonal adjustment with a database of input / output image pairs. InThe Twenty-Fourth IEEE Conference on Computer Vision and Pattern Recognition, 2011. 5, 16
2011
-
[6]
Haoyu Chen, Keda Tao, Yizao Wang, Xinlei Wang, Lei Zhu, and Jinjin Gu. Photoartagent: Intelligent photo retouching with language model-based artist agents.arXiv preprint arXiv:2505.23130, 2025. 2, 3
arXiv 2025
-
[7]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025. 2, 6, 7, 17
Pith/arXiv arXiv 2025
-
[8]
Conde, Zihao Lu, and Radu Timofte
Marcos V . Conde, Zihao Lu, and Radu Timofte. Pixtalk: Controlling photorealistic image processing and editing with language. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 19269– 19279, 2025. 2
2025
-
[9]
Turboedit: Text-based image editing using few-step diffusion models, 2024
Gilad Deutch, Rinon Gal, Daniel Garibi, Or Patashnik, and Daniel Cohen-Or. Turboedit: Text-based image editing using few-step diffusion models, 2024. 2
2024
-
[10]
A survey on rag meeting llms: Towards retrieval-augmented large language models
Wenqi Fan, Yujuan Ding, Liangbo Ning, Shijie Wang, Hengyun Li, Dawei Yin, Tat-Seng Chua, and Qing Li. A survey on rag meeting llms: Towards retrieval-augmented large language models. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, page 6491–6501, New York, NY , USA, 2024. Association for Computing Machinery. 3
2024
-
[11]
Guiding instruction-based image editing via multimodal large language models
Tsu-Jui Fu, Wenze Hu, Xianzhi Du, William Yang Wang, Yinfei Yang, and Zhe Gan. Guiding instruction-based image editing via multimodal large language models. InThe Twelfth International Conference on Learning Representations, 2024. 2
2024
-
[12]
Efficient tool use with chain-of-abstraction reasoning
Silin Gao, Jane Dwivedi-Yu, Ping Yu, Xiaoqing Ellen Tan, Ramakanth Pasunuru, Olga Golovneva, Koustuv Sinha, Asli Celikyilmaz, Antoine Bosselut, and Tianlu Wang. Efficient tool use with chain-of-abstraction reasoning. InProceedings of the 31st International Conference on Computational Linguistics, pages 2727–2743, Abu Dhabi, UAE, 2025. Association for Comp...
2025
-
[13]
ToolkenGPT: Augmenting frozen language models with massive tools via tool embeddings
Shibo Hao, Tianyang Liu, Zhen Wang, and Zhiting Hu. ToolkenGPT: Augmenting frozen language models with massive tools via tool embeddings. InThirty-seventh Conference on Neural Information Processing Systems,
-
[14]
Prompt-to-prompt image editing with cross attention control.arXiv preprint arXiv:2208.01626, 2022
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to-prompt image editing with cross attention control.arXiv preprint arXiv:2208.01626, 2022. 2
Pith/arXiv arXiv 2022
-
[15]
Exposure: A white-box photo post-processing framework.ACM Transactions on Graphics (TOG), 37(2): 1–17, 2018
Yuanming Hu, Hao He, Chenxi Xu, Baoyuan Wang, and Stephen Lin. Exposure: A white-box photo post-processing framework.ACM Transactions on Graphics (TOG), 37(2): 1–17, 2018. 2
2018
-
[16]
PatchDPO: Patch-level dpo for finetuning-free personalized image generation
Qihan Huang, Long Chan, Jinlong Liu, Wanggui He, Hao Jiang, Mingli Song, and Jie Song. PatchDPO: Patch-level dpo for finetuning-free personalized image generation. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 18369–18378, 2025. 18
2025
-
[17]
Smartedit: Exploring complex instruction-based image editing with multimodal large language models
Yuzhou Huang, Liangbin Xie, Xintao Wang, Ziyang Yuan, Xiaodong Cun, Yixiao Ge, Jiantao Zhou, Chao Dong, Rui Huang, Ruimao Zhang, and Ying Shan. Smartedit: Exploring complex instruction-based image editing with multimodal large language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 8362–8371, 2024. 2
2024
-
[18]
Survey of hallucination in natural language generation.ACM Comput
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. Survey of hallucination in natural language generation.ACM Comput. Surv., 55(12), 2023. 3
2023
-
[19]
Imagic: Text-based real image editing with diffusion models
Bahjat Kawar, Shiran Zada, Oran Lang, Omer Tov, Huiwen Chang, Tali Dekel, Inbar Mosseri, and Michal Irani. Imagic: Text-based real image editing with diffusion models. In CVPR, pages 6007–6017, 2023. 2 9
2023
-
[20]
Zhanghan Ke, Yuhao Liu, Lei Zhu, Nanxuan Zhao, and Rynson W.H. Lau. Neural preset for color style transfer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14173–14182, 2023. 2
2023
-
[21]
Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114, 2013
Diederik P Kingma and Max Welling. Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114, 2013. 1
Pith/arXiv arXiv 2013
-
[22]
Learning Action and Reasoning-Centric Image Editing from Videos and Simulations
Benno Krojer, Dheeraj Vattikonda, Luis Lara, Varun Jampani, Eva Portelance, Christopher Pal, and Siva Reddy. Learning Action and Reasoning-Centric Image Editing from Videos and Simulations. InNeurIPS, 2024. Spotlight Paper. 2
2024
-
[23]
Zhu, and Mengyue Wu
Kunyao Lan, Bingrui Jin, Zichen Zhu, Siyuan Chen, Shu Zhang, Kenny Q. Zhu, and Mengyue Wu. Depression diagnosis dialogue simulation: Self-improving psychiatrist with tertiary memory, 2024. 3
2024
-
[24]
Cliptone: Unsupervised learning for text-based image tone adjustment
Hyeongmin Lee, Kyoungkook Kang, Jungseul Ok, and Sunghyun Cho. Cliptone: Unsupervised learning for text-based image tone adjustment. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2942–2951, 2024. 2
2024
-
[25]
Unsupervised dense retrieval with relevance-aware contrastive pre-training
Yibin Lei, Liang Ding, Yu Cao, Changtong Zan, Andrew Yates, and Dacheng Tao. Unsupervised dense retrieval with relevance-aware contrastive pre-training. InFindings of the Association for Computational Linguistics: ACL 2023, pages 10932–10940, Toronto, Canada, 2023. Association for Computational Linguistics. 3
2023
-
[26]
Api-bank: A comprehensive benchmark for tool-augmented llms
Minghao Li, Yingxiu Zhao, Bowen Yu, Feifan Song, Hangyu Li, Haiyang Yu, Zhoujun Li, Fei Huang, and Yongbin Li. Api-bank: A comprehensive benchmark for tool-augmented llms. InEMNLP, pages 3102–3116, 2023. 3
2023
-
[27]
ROUGE: A package for automatic evaluation of summaries
Chin-Yew Lin. ROUGE: A package for automatic evaluation of summaries. InText Summarization Branches Out, pages 74–81, Barcelona, Spain, 2004. Association for Computational Linguistics. 6
2004
-
[28]
Yunlong Lin, Zixu Lin, Kunjie Lin, Jinbin Bai, Panwang Pan, Chenxin Li, Haoyu Chen, Zhongdao Wang, Xinghao Ding, Wenbo Li, et al. Jarvisart: Liberating human artistic creativity via an intelligent photo retouching agent.arXiv preprint arXiv:2506.17612, 2025. 2, 3
arXiv 2025
-
[29]
Toolnet: Connecting large language models with massive tools via tool graph
Xukun Liu, Zhiyuan Peng, Xiaoyuan Yi, Xing Xie, Lirong Xiang, Yuchen Liu, and Dongkuan Xu. Toolnet: Connecting large language models with massive tools via tool graph. CoRR, abs/2403.00839, 2024. 3
arXiv 2024
-
[30]
Agentbench: Evaluating LLMs as agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Aohan Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tianjun Zhang, Yu Su, Huan Sun, Minlie Huang, Yuxiao Dong, and Jie Tang. Agentbench: Evaluating LLMs as agents. InThe Twelfth International Conference on Learning R...
-
[31]
Controlllm: Augment language models with tools by searching on graphs
Zhaoyang Liu, Zeqiang Lai, Zhangwei Gao, Erfei Cui, Ziheng Li, Xizhou Zhu, Lewei Lu, Qifeng Chen, Yu Qiao, Jifeng Dai, and Wenhai Wang. Controlllm: Augment language models with tools by searching on graphs. InComputer Vision – ECCV 2024: 18th European Conference, Milan, Italy, September 29–October 4, 2024, Proceedings, Part XII, page 89–105, Berlin, Heidelberg,
2024
-
[32]
Apigen: automated pipeline for generating verifiable and diverse function-calling datasets
Zuxin Liu, Thai Hoang, Jianguo Zhang, Ming Zhu, Tian Lan, Shirley Kokane, Juntao Tan, Weiran Yao, Zhiwei Liu, Yihao Feng, Rithesh Murthy, Liangwei Yang, Silvio Savarese, Juan Carlos Niebles, Huan Wang, Shelby Heinecke, and Caiming Xiong. Apigen: automated pipeline for generating verifiable and diverse function-calling datasets. In Proceedings of the 38th ...
2025
-
[33]
Chameleon: Plug-and-play compositional reasoning with large language models
Pan Lu, Baolin Peng, Hao Cheng, Michel Galley, Kai-Wei Chang, Ying Nian Wu, Song-Chun Zhu, and Jianfeng Gao. Chameleon: Plug-and-play compositional reasoning with large language models. InThe 37th Conference on Neural Information Processing Systems (NeurIPS), 2023. 3
2023
-
[34]
Repaint: Inpainting using denoising diffusion probabilistic models
Andreas Lugmayr, Martin Danelljan, Andres Romero, Fisher Yu, Radu Timofte, and Luc Van Gool. Repaint: Inpainting using denoising diffusion probabilistic models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11461–11471, 2022. 2
2022
-
[35]
TOOLVERIFIER: Generalization to new tools via self-verification
Dheeraj Mekala, Jason E Weston, Jack Lanchantin, Roberta Raileanu, Maria Lomeli, Jingbo Shang, and Jane Dwivedi-Yu. TOOLVERIFIER: Generalization to new tools via self-verification. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 5026–5041, Miami, Florida, USA, 2024. Association for Computational Linguistics. 3
2024
-
[36]
Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jiajun Wu, Jun-Yan Zhu, and Stefano Ermon. Sdedit: Guided image synthesis and editing with stochastic differential equations.arXiv preprint arXiv:2108.01073, 2021. 2
Pith/arXiv arXiv 2021
-
[37]
Null-text inversion for editing real images using guided diffusion models
Ron Mokady, Amir Hertz, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Null-text inversion for editing real images using guided diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6038–6047, 2023. 2
2023
-
[38]
Webgpt: Browser-assisted question-answering with human feedback, 2022
Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, Xu Jiang, Karl Cobbe, Tyna Eloundou, Gretchen Krueger, Kevin Button, Matthew Knight, Benjamin Chess, and John Schulman. Webgpt: Browser-assisted question-answering with human feedback, 2022. 3
2022
-
[39]
Introducing our latest image generation model in the api.https://openai.com/index/image- generation-api/, 2025
OpenAI. Introducing our latest image generation model in the api.https://openai.com/index/image- generation-api/, 2025. 2, 7
2025
-
[40]
Introducing gpt-4.1 in the api.https : / / openai.com/index/gpt-4-1/, 2025
OpenAI. Introducing gpt-4.1 in the api.https : / / openai.com/index/gpt-4-1/, 2025. 2, 4, 6, 7, 17
2025
-
[41]
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with 10 human feedba...
2022
-
[42]
Distort-and-recover: Color enhancement using deep reinforcement learning
Jongchan Park, Joon-Young Lee, Donggeun Yoo, and In So Kweon. Distort-and-recover: Color enhancement using deep reinforcement learning. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 5928–5936, 2018. 2
2018
-
[43]
Gonzalez
Shishir G Patil, Tianjun Zhang, Xin Wang, and Joseph E. Gonzalez. Gorilla: Large language model connected with massive APIs. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. 3
2024
-
[44]
Toolink: Linking toolkit creation and using through chain-of-solving on open-source model
Cheng Qian, Chenyan Xiong, Zhenghao Liu, and Zhiyuan Liu. Toolink: Linking toolkit creation and using through chain-of-solving on open-source model. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 831–854, Mexico City, Mexico, 20...
2024
-
[45]
ToolLLM: Facilitating large language models to master 16000+ real-world APIs
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, Sihan Zhao, Lauren Hong, Runchu Tian, Ruobing Xie, Jie Zhou, Mark Gerstein, dahai li, Zhiyuan Liu, and Maosong Sun. ToolLLM: Facilitating large language models to master 16000+ real-world APIs. InThe Twelfth International Conference on Learning...
2024
-
[46]
Towards completeness-oriented tool retrieval for large language models
Changle Qu, Sunhao Dai, Xiaochi Wei, Hengyi Cai, Shuaiqiang Wang, Dawei Yin, Jun Xu, and Ji-Rong Wen. Towards completeness-oriented tool retrieval for large language models. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management, page 1930–1940, New York, NY , USA, 2024. Association for Computing Machinery. 3
1930
-
[47]
From exploration to mastery: Enabling LLMs to master tools via self-driven interactions
Changle Qu, Sunhao Dai, Xiaochi Wei, Hengyi Cai, Shuaiqiang Wang, Dawei Yin, Jun Xu, and Ji-Rong Wen. From exploration to mastery: Enabling LLMs to master tools via self-driven interactions. InThe Thirteenth International Conference on Learning Representations, 2025. 3
2025
-
[48]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 18
2021
-
[49]
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image gener- ation with clip latents.arXiv preprint arXiv:2204.06125, 1 (2):3, 2022. 2
Pith/arXiv arXiv 2022
-
[50]
Multimodal diffusion transformer: Learning versatile behavior from multimodal goals
Moritz Reuss, ¨Omer Erdinc ¸ Ya˘gmurlu, Fabian Wenzel, and Rudolf Lioutikov. Multimodal diffusion transformer: Learning versatile behavior from multimodal goals. In Robotics: Science and Systems, 2024. 1
2024
-
[51]
High-resolution image synthesis with latent diffusion models, 2021
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models, 2021. 1
2021
-
[52]
Toolformer: Language models can teach themselves to use tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dessi, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. In Thirty-seventh Conference on Neural Information Process- ing Systems, 2023. 3
2023
-
[53]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024. 4
Pith/arXiv arXiv 2024
-
[54]
Hugginggpt: solving ai tasks with chatgpt and its friends in hugging face
Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, and Yueting Zhuang. Hugginggpt: solving ai tasks with chatgpt and its friends in hugging face. In Proceedings of the 37th International Conference on Neural Information Processing Systems, Red Hook, NY , USA, 2023. Curran Associates Inc. 3
2023
-
[55]
Hybridflow: A flexible and efficient rlhf framework.arXiv preprint arXiv: 2409.19256, 2024
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework.arXiv preprint arXiv: 2409.19256, 2024. 6
Pith/arXiv arXiv 2024
-
[56]
A benchmark and baseline for language-driven image editing
Jing Shi, Ning Xu, Trung Bui, Franck Dernoncourt, Zheng Wen, and Chenliang Xu. A benchmark and baseline for language-driven image editing. InProceedings of the Asian Conference on Computer Vision, 2020. 2
2020
-
[57]
Learning by planning: Language-guided global image editing
Jing Shi, Ning Xu, Yihang Xu, Trung Bui, Franck Dernoncourt, and Chenliang Xu. Learning by planning: Language-guided global image editing. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13590–13599, 2021. 4, 5, 16
2021
-
[58]
Spaceedit: Learning a unified editing space for open-domain image color editing
Jing Shi, Ning Xu, Haitian Zheng, Alex Smith, Jiebo Luo, and Chenliang Xu. Spaceedit: Learning a unified editing space for open-domain image color editing. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 19730–19739, 2022. 2
2022
-
[59]
Learning to use tools via cooperative and interactive agents
Zhengliang Shi, Shen Gao, Xiuyi Chen, Yue Feng, Lingyong Yan, Haibo Shi, Dawei Yin, Pengjie Ren, Suzan Verberne, and Zhaochun Ren. Learning to use tools via cooperative and interactive agents. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 10642–10657, Miami, Florida, USA, 2024. Association for Computational Linguistics. 3
2024
-
[60]
META-GUI: Towards multi-modal conversational agents on mobile GUI
Liangtai Sun, Xingyu Chen, Lu Chen, Tianle Dai, Zichen Zhu, and Kai Yu. META-GUI: Towards multi-modal conversational agents on mobile GUI. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 6699–6712, Abu Dhabi, United Arab Emirates, 2022. Association for Computational Linguistics. 2
2022
-
[61]
Vipergpt: Visual inference via python execution for reasoning
D ´ıdac Sur´ıs, Sachit Menon, and Carl V ondrick. Vipergpt: Visual inference via python execution for reasoning. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 11888–11898, 2023. 3
2023
-
[62]
Qwen3 technical report, 2025
Qwen Team. Qwen3 technical report, 2025. 17
2025
-
[63]
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandku- mar. V oyager: An open-ended embodied agent with large language models.arXiv preprint arXiv: Arxiv-2305.16291,
-
[64]
GenArtist: Multimodal llm as an agent for unified image generation and editing.Advances in Neural Information Processing Systems, 37:128374–128395, 2024
Zhenyu Wang, Aoxue Li, Zhenguo Li, and Xihui Liu. GenArtist: Multimodal llm as an agent for unified image generation and editing.Advances in Neural Information Processing Systems, 37:128374–128395, 2024. 18
2024
-
[65]
Visual chatgpt: Talking, drawing and editing with visual foundation models, 2023
Chenfei Wu, Shengming Yin, Weizhen Qi, Xiaodong Wang, Zecheng Tang, and Nan Duan. Visual chatgpt: Talking, drawing and editing with visual foundation models, 2023. 3
2023
-
[66]
Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025. 2
Pith/arXiv arXiv 2025
-
[67]
Alignment for efficient tool calling of large language models, 2025
Hongshen Xu, Zihan Wang, Zichen Zhu, Lei Pan, Xingyu Chen, Lu Chen, and Kai Yu. Alignment for efficient tool calling of large language models, 2025. 3
2025
-
[68]
Delusions of large language models, 2025
Hongshen Xu, Zixv yang, Zichen Zhu, Kunyao Lan, Zihan Wang, Mengyue Wu, Ziwei Ji, Lu Chen, Pascale Fung, and Kai Yu. Delusions of large language models, 2025. 3
2025
-
[69]
Reducing tool hallucination via reliability alignment
Hongshen Xu, Zichen Zhu, Lei Pan, Zihan Wang, Su Zhu, Da Ma, Ruisheng Cao, Lu Chen, and Kai Yu. Reducing tool hallucination via reliability alignment. InForty-second International Conference on Machine Learning, 2025. 3
2025
-
[70]
Inversion-free image editing with language-guided diffusion models
Sihan Xu, Yidong Huang, Jiayi Pan, Ziqiao Ma, and Joyce Chai. Inversion-free image editing with language-guided diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9452–9461, 2024. 2
2024
-
[71]
Paint by example: Exemplar-based image editing with diffusion models
Binxin Yang, Shuyang Gu, Bo Zhang, Ting Zhang, Xuejin Chen, Xiaoyan Sun, Dong Chen, and Fang Wen. Paint by example: Exemplar-based image editing with diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 18381–18391, 2023. 2
2023
-
[72]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe Eleventh International Conference on Learning Representations, 2023. 3
2023
-
[73]
Craft: Customizing llms by creating and retrieving from specialized toolsets
Lifan Yuan, Yangyi Chen, Xingyao Wang, Yi Fung, Hao Peng, and Heng Ji. Craft: Customizing llms by creating and retrieving from specialized toolsets. InICLR, 2024. 3
2024
-
[74]
Socratic models: Composing zero-shot multimodal reasoning with language
Andy Zeng, Maria Attarian, brian ichter, Krzysztof Marcin Choromanski, Adrian Wong, Stefan Welker, Federico Tombari, Aveek Purohit, Michael S Ryoo, Vikas Sindhwani, Johnny Lee, Vincent Vanhoucke, and Pete Florence. Socratic models: Composing zero-shot multimodal reasoning with language. InThe Eleventh International Conference on Learning Representations, 2023. 3
2023
-
[75]
UFO: A UI-Focused Agent for Windows OS Interaction.arXiv preprint arXiv:2402.07939, 2024
Chaoyun Zhang, Liqun Li, Shilin He, Xu Zhang, Bo Qiao, Si Qin, Minghua Ma, Yu Kang, Qingwei Lin, Saravan Rajmohan, Dongmei Zhang, and Qi Zhang. UFO: A UI-Focused Agent for Windows OS Interaction.arXiv preprint arXiv:2402.07939, 2024. 2, 3
arXiv 2024
-
[76]
Magicbrush: A manually annotated dataset for instruction-guided image editing.Advances in Neural Information Processing Systems, 36:31428–31449, 2023
Kai Zhang, Lingbo Mo, Wenhu Chen, Huan Sun, and Yu Su. Magicbrush: A manually annotated dataset for instruction-guided image editing.Advances in Neural Information Processing Systems, 36:31428–31449, 2023. 2
2023
-
[77]
Zhehao Zhang, Ryan A. Rossi, Branislav Kveton, Yijia Shao, Diyi Yang, Hamed Zamani, Franck Dernoncourt, Joe Barrow, Tong Yu, Sungchul Kim, Ruiyi Zhang, Jiuxiang Gu, Tyler Derr, Hongjie Chen, Junda Wu, Xiang Chen, Zichao Wang, Subrata Mitra, Nedim Lipka, Nesreen Ahmed, and Yu Wang. Personalization of large language models: A survey,
-
[78]
Ultraedit: Instruction-based fine-grained image editing at scale
Haozhe Zhao, Xiaojian Ma, Liang Chen, Shuzheng Si, Rujie Wu, Kaikai An, Peiyu Yu, Minjia Zhang, Qing Li, and Baobao Chang. Ultraedit: Instruction-based fine-grained image editing at scale. InAdvances in Neural Information Processing Systems, pages 3058–3093. Curran Associates, Inc., 2024. 2
2024
-
[79]
ToolRerank: Adaptive and hierarchy-aware reranking for tool retrieval
Yuanhang Zheng, Peng Li, Wei Liu, Yang Liu, Jian Luan, and Bin Wang. ToolRerank: Adaptive and hierarchy-aware reranking for tool retrieval. InProceedings of the 2024 Joint International Conference on Computational Linguis- tics, Language Resources and Evaluation (LREC-COLING 2024), pages 16263–16273, Torino, Italia, 2024. ELRA and ICCL. 3
2024
-
[80]
MobA: Multifaceted memory-enhanced adaptive planning for efficient mobile task automation
Zichen Zhu, Hao Tang, Yansi Li, Dingye Liu, Hongshen Xu, Kunyao Lan, Danyang Zhang, Yixuan Jiang, Hao Zhou, Chenrun Wang, Situo Zhang, Liangtai Sun, Yixiao Wang, Yuheng Sun, Lu Chen, and Kai Yu. MobA: Multifaceted memory-enhanced adaptive planning for efficient mobile task automation. InProceedings of the 2025 Conference of the Nations of the Americas Cha...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.