Understanding-Enhanced Model Collaboration for Long-Tailed Egocentric Mistake Detection
Pith reviewed 2026-06-28 15:11 UTC · model grok-4.3
The pith
A small model branch checking workflow consistency collaborates with a large model checking action details to detect rare mistakes in egocentric videos.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
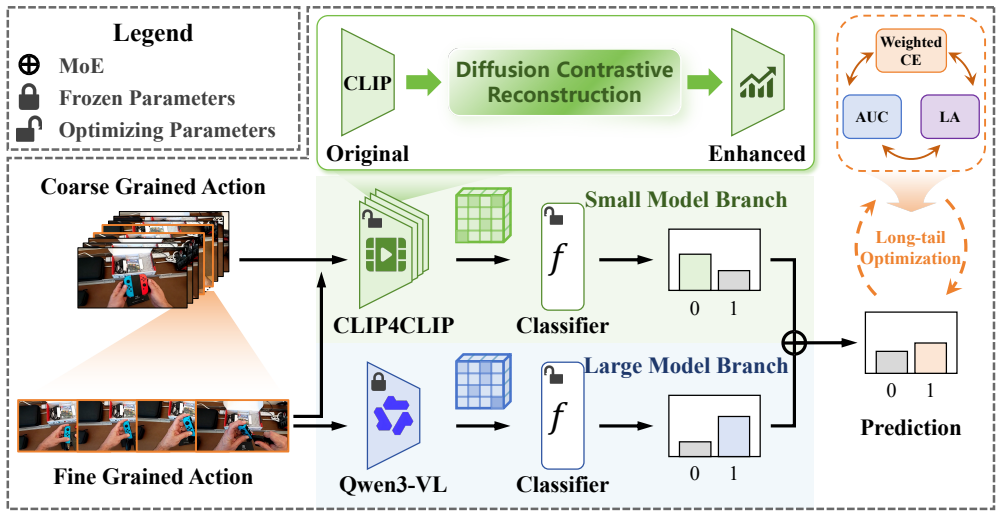
The authors claim that their understanding-enhanced model collaboration method succeeds because the small branch, built on an enhanced video encoder and given both coarse video and fine segment, can surface actions that are locally correct yet inconsistent with the overall workflow, the large branch extracts high-capacity representations to judge fine-grained correctness, the two predictions are fused by a collaboration gate, and the classifiers are trained with reweighted cross-entropy, AUC-oriented learning, and label-aware adjustment to handle long-tailed mistake distributions, yielding a system that balances speed and accuracy on subtle, rare, and ambiguous mistakes.
What carries the argument
The adaptive collaboration gate that fuses the small-branch prediction of workflow inconsistency with the large-branch prediction of action error.
If this is right
- The system can flag mistakes that are correct in isolation but break the larger task sequence.
- Multiple complementary training objectives together address the long-tailed distribution of mistake types.
- The fused model maintains usable speed while reaching higher accuracy than either branch alone.
- The approach targets subtle and ambiguous errors that are common in instructional video settings.
Where Pith is reading between the lines
- The same two-branch structure could be tested on other sequential video tasks where local correctness must be weighed against global context.
- Replacing the fixed gate with a learned router might allow the system to route easy cases to the small branch more often.
- Applying the workflow-consistency check to non-instructional egocentric footage would reveal whether the inconsistency signal generalizes beyond task sequences.
Load-bearing premise
The small model branch can reliably identify actions that are locally correct but inconsistent with the overall workflow when given both the coarse-grained video and the fine-grained segment.
What would settle it
A test set of egocentric videos containing actions that are locally correct yet violate the task sequence, on which the small branch shows no better than chance performance at flagging the inconsistency, would falsify the central claim.
Figures
read the original abstract
In this report, we address the problem of determining whether a user performs an action incorrectly from egocentric video data. To this end, we propose an Understanding-Enhanced Model Collaboration Method (UE-MCM) that combines efficient coarse-grained video understanding with accurate fine-grained action reasoning. Specifically, UE-MCM contains a small model branch and a large model branch. The large model branch focuses on whether the fine-grained action itself is executed incorrectly, while the small model branch jointly takes the coarse-grained video and fine-grained segment as input to identify actions that may be locally correct but inconsistent with the overall workflow. The small model branch is built on a CLIP4CLIP video encoder initialized from a CLIP model enhanced by Diffusion Contrastive Reconstruction, and the large model branch uses the Qwen3-VL Embedding model to extract high-capacity representations from fine-grained action segments. The small-branch prediction and the large-branch prediction are then adaptively fused by a lightweight collaboration gate. To handle the long-tailed distribution of mistake instances, we optimize the classifiers with complementary objectives, including reweighted cross-entropy, AUC-oriented learning, and label-aware adjustment. The resulting system balances speed and accuracy, making it effective for detecting subtle, rare, and ambiguous mistakes in egocentric instructional videos.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Understanding-Enhanced Model Collaboration Method (UE-MCM) for long-tailed egocentric mistake detection in instructional videos. It describes a two-branch architecture: a small model branch built on CLIP4CLIP (initialized from CLIP and enhanced by Diffusion Contrastive Reconstruction) that jointly processes coarse-grained video and fine-grained segments to flag actions that are locally correct but inconsistent with the overall workflow; a large model branch using the Qwen3-VL Embedding model for high-capacity fine-grained action analysis; and a lightweight collaboration gate for adaptive fusion of the two predictions. Classifiers are optimized with reweighted cross-entropy, AUC-oriented learning, and label-aware adjustment to address long-tailed mistake distributions. The abstract asserts that the resulting system balances speed and accuracy for subtle, rare, and ambiguous mistakes.
Significance. If the architecture and training objectives perform as claimed, the work would address a practically relevant problem in egocentric vision by combining efficient coarse understanding with accurate fine-grained reasoning under long-tailed conditions. The model-collaboration design and complementary long-tail objectives are plausible directions, but the complete absence of any quantitative results, ablations, or validation details prevents assessment of whether these elements deliver the asserted balance of speed and accuracy.
major comments (2)
- [Abstract] Abstract: the central claim that 'the resulting system balances speed and accuracy, making it effective for detecting subtle, rare, and ambiguous mistakes' is unsupported by any experimental results, tables, figures, or validation details. This is load-bearing because the manuscript supplies only an architectural description and training objectives with no evidence that the small-branch workflow-inconsistency detection or the fused system achieves the stated performance.
- [Abstract] Abstract: the assumption that the small model branch (CLIP4CLIP + Diffusion Contrastive Reconstruction) can reliably identify actions that are locally correct but inconsistent with the overall workflow when jointly taking coarse-grained video and fine-grained segment as input is stated without derivation, example, or analysis. This assumption is load-bearing for the two-branch collaboration claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We acknowledge that the current manuscript provides only an architectural description and training objectives without quantitative validation or supporting analysis for the claims and assumptions in the abstract. We will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'the resulting system balances speed and accuracy, making it effective for detecting subtle, rare, and ambiguous mistakes' is unsupported by any experimental results, tables, figures, or validation details. This is load-bearing because the manuscript supplies only an architectural description and training objectives with no evidence that the small-branch workflow-inconsistency detection or the fused system achieves the stated performance.
Authors: We agree that the performance claim in the abstract is unsupported by any results in the submitted manuscript. The work as presented describes the UE-MCM architecture, the two-branch design, the collaboration gate, and the long-tail optimization objectives but contains no experiments, ablations, or validation. In the revision we will add a full experimental section reporting accuracy, AUC, F1, and inference latency on egocentric instructional video benchmarks, including comparisons against single-branch baselines and ablations of the collaboration gate and each loss term. The abstract will be revised to reflect the measured outcomes. revision: yes
-
Referee: [Abstract] Abstract: the assumption that the small model branch (CLIP4CLIP + Diffusion Contrastive Reconstruction) can reliably identify actions that are locally correct but inconsistent with the overall workflow when jointly taking coarse-grained video and fine-grained segment as input is stated without derivation, example, or analysis. This assumption is load-bearing for the two-branch collaboration claim.
Authors: We recognize that the manuscript states the intended role of the small branch without providing examples, a formal derivation, or empirical motivation for why joint coarse-plus-fine input enables workflow-inconsistency detection. In the revised version we will insert a dedicated subsection that (1) gives concrete video examples of locally correct yet workflow-inconsistent actions, (2) explains how the CLIP4CLIP encoder with Diffusion Contrastive Reconstruction is expected to capture the necessary long-range context, and (3) includes a qualitative analysis of the small-branch outputs on sample sequences. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents an architectural proposal for UE-MCM, a two-branch model collaboration system using CLIP4CLIP, Diffusion Contrastive Reconstruction, Qwen3-VL, and a collaboration gate, with standard loss terms for long-tailed data. No mathematical derivation, equations, or first-principles claims are present in the abstract or method description. All components are described as design choices without any reduction of outputs to fitted inputs or self-citations that bear the central claim. The system is therefore self-contained as an engineering description rather than a derived result.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Class-balanced loss based on effective number of samples
Yin Cui, Menglin Jia, Tsung-Yi Lin, Yang Song, and Serge Belongie. Class-balanced loss based on effective number of samples. InCVPR, pages 9268–9277, 2019. 2, 3
2019
-
[2]
Aucseg: Auc-oriented pixel-level long-tail semantic segmen- tation
Boyu Han, Qianqian Xu, Zhiyong Yang, Shilong Bao, Peisong Wen, Yangbangyan Jiang, and Qingming Huang. Aucseg: Auc-oriented pixel-level long-tail semantic segmen- tation. InNeurIPS, pages 126863–126907, 2024. 2
2024
-
[3]
Boyu Han, Qianqian Xu, Shilong Bao, Zhiyong Yang, Sicong Li, and Qingming Huang. Dual-stage reweighted moe for long-tailed egocentric mistake detection.arXiv preprint arXiv:2509.12990, 2025. 4
-
[4]
Guiding diffusion-based reconstruction with contrastive signals for balanced visual representation
Boyu Han, Qianqian Xu, Shilong Bao, Zhiyong Yang, Ruochen Cui, Xilin Zhao, and Qingming Huang. Guiding diffusion-based reconstruction with contrastive signals for balanced visual representation. InCVPR, 2026. 2, 3
2026
-
[5]
Lightfair: Towards an efficient alternative for fair t2i diffusion via debiasing pre-trained text encoders
Boyu Han, Qianqian Xu, Shilong Bao, Zhiyong Yang, Kan- gli Zi, and Qingming Huang. Lightfair: Towards an efficient alternative for fair t2i diffusion via debiasing pre-trained text encoders. InNeurIPS, pages 22671–22724, 2026. 1
2026
-
[6]
Dynamic hyperbolic attention net- work for fine hand-object reconstruction
Zhiying Leng, Shun-Cheng Wu, Mahdi Saleh, Antonio Mon- tanaro, Hao Yu, Yin Wang, Nassir Navab, Xiaohui Liang, and Federico Tombari. Dynamic hyperbolic attention net- work for fine hand-object reconstruction. InICCV, pages 14894–14904, 2023
2023
-
[7]
Hypersdfusion: Bridging hierarchical structures in language and geometry for enhanced 3d text2shape genera- tion
Zhiying Leng, Tolga Birdal, Xiaohui Liang, and Federico Tombari. Hypersdfusion: Bridging hierarchical structures in language and geometry for enhanced 3d text2shape genera- tion. InCVPR, pages 19691–19700, 2024. 1
2024
-
[8]
Mingxin Li, Yanzhao Zhang, Dingkun Long, Keqin Chen, Sibo Song, Shuai Bai, Zhibo Yang, Pengjun Xie, An Yang, Dayiheng Liu, et al. Qwen3-vl-embedding and qwen3-vl-reranker: A unified framework for state-of-the- art multimodal retrieval and ranking.arXiv preprint arXiv:2601.04720, 2026. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
Clip4clip: An empirical study of clip for end to end video clip retrieval and captioning.Neu- rocomputing, 508:293–304, 2022
Huaishao Luo, Lei Ji, Ming Zhong, Yang Chen, Wen Lei, Nan Duan, and Tianrui Li. Clip4clip: An empirical study of clip for end to end video clip retrieval and captioning.Neu- rocomputing, 508:293–304, 2022. 2, 3
2022
-
[10]
Long-tail learning via logit adjustment
Aditya Krishna Menon, Sadeep Jayasumana, Ankit Singh Rawat, Himanshu Jain, Andreas Veit, and Sanjiv Kumar. Long-tail learning via logit adjustment. InICLR, 2020. 2, 3
2020
-
[11]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InICML, pages 8748–8763, 2021. 2, 3
2021
-
[12]
Holoassist: an egocen- tric human interaction dataset for interactive ai assistants in the real world
Xin Wang, Taein Kwon, Mahdi Rad, Bowen Pan, Ishani Chakraborty, Sean Andrist, Dan Bohus, Ashley Feniello, Bu- gra Tekin, Felipe Vieira Frujeri, et al. Holoassist: an egocen- tric human interaction dataset for interactive ai assistants in the real world. InICCV, pages 20270–20281, 2023. 1, 4
2023
-
[13]
Yin Wang, Zhiying Leng, Haitian Liu, Frederick WB Li, Mu Li, and Xiaohui Liang. Dynamic worlds, dynamic hu- mans: Generating virtual human-scene interaction motion in dynamic scenes.arXiv preprint arXiv:2601.19484, 2026. 1
-
[14]
Learning with multiclass auc: Theory and algorithms.TPAMI, 44(11):7747–7763, 2021
Zhiyong Yang, Qianqian Xu, Shilong Bao, Xiaochun Cao, and Qingming Huang. Learning with multiclass auc: Theory and algorithms.TPAMI, 44(11):7747–7763, 2021. 2, 3
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.