One Model, Two Roles: Emergent Specialization in a Shared Recurrent Transformer
Pith reviewed 2026-05-20 12:54 UTC · model grok-4.3
The pith
A clear state-identity signal induces stable functional roles inside a shared-parameter recurrent Transformer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In a two-state recurrent setting, a clear state-identity signal can induce stable, related functional roles inside a shared-parameter recurrent Transformer: zH behaves like a fully committed proposal state whereas zL retains local uncertainty and shifting intermediate structure, with the split arising when the model can tell the update types apart via input-injection asymmetry or a level token.
What carries the argument
Asymmetric Input Recurrence (AIR), a minimal two-state reasoning architecture that reuses the same Transformer parameters for both L and H updates while injecting the encoded input only during L-updates.
If this is right
- Freezing zH reduces content changes in zL while freezing zL increases changes in zH on Sudoku-Extreme.
- Freezing either state increases content changes in the other state on Maze.
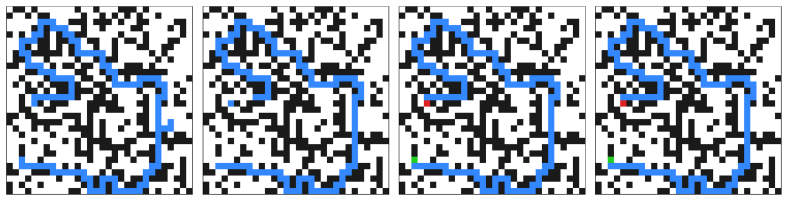
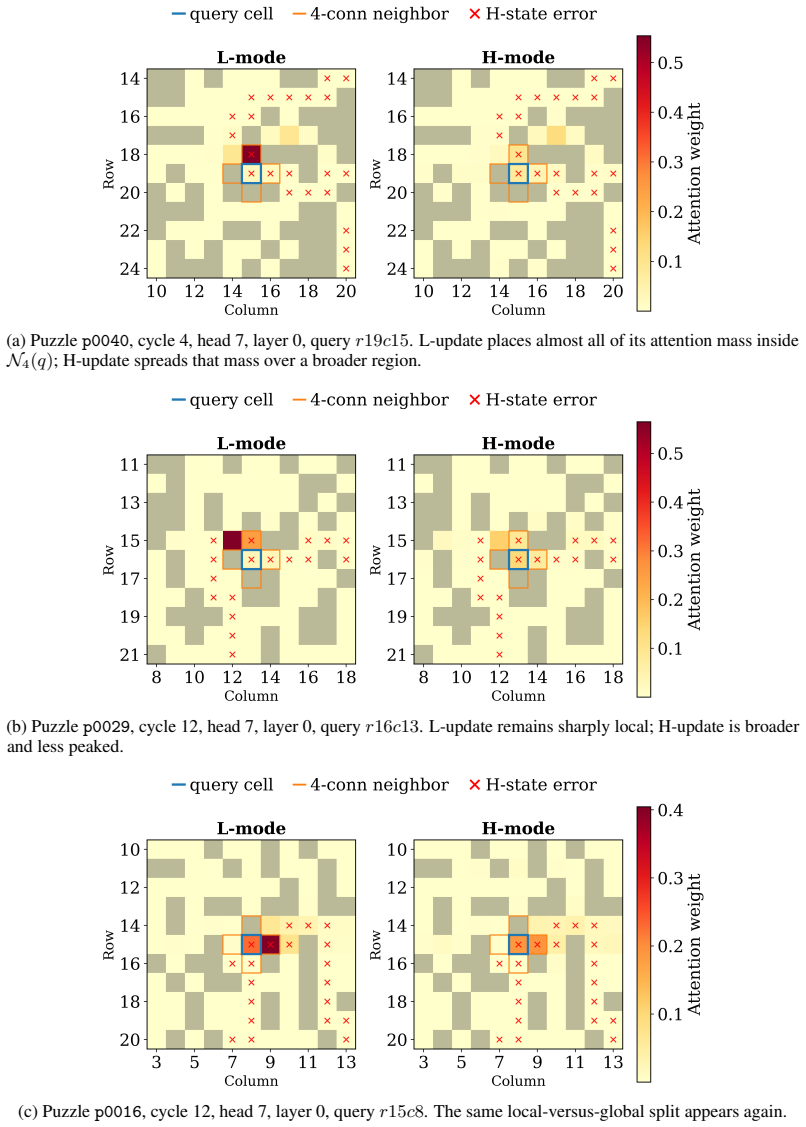
- L-updates produce consistently more local attention patterns than H-updates in both tasks.
- Specialization disappears when the model has no signal to distinguish the two update types.
Where Pith is reading between the lines
- The same minimal asymmetry could produce analogous role splits in other multi-step recurrent reasoning domains.
- Scaling the architecture while preserving the input-injection rule would test whether the proposal-uncertainty division persists at larger model sizes.
- Comparing attention locality across additional tasks would clarify whether the local-versus-global pattern is a general consequence of the L/H distinction.
Load-bearing premise
The observed functional split between zH and zL is caused by the input-injection asymmetry or level token rather than by task-specific training dynamics or other unablated factors.
What would settle it
Train the same models on Sudoku-Extreme and Maze after removing both the input-injection asymmetry and the level token; if the proposal-versus-uncertainty split still appears in decoded rollouts and freeze experiments, the claim is false.
Figures











read the original abstract
Can a shared-weight recurrent Transformer develop distinct internal roles without being partitioned into separate modules? We study this in Asymmetric Input Recurrence (AIR), a minimal two-state reasoning architecture in which the same Transformer model is reused for both updates (per literature, L and H) and the only built-in difference in the update rule is that the encoded input is injected during L-updates but not H-updates. Across Sudoku-Extreme and Maze, decoded rollouts reveal a consistent split: $\zH$ behaves like a fully committed proposal state, whereas $\zL$ retains local uncertainty and shifting intermediate structure. Freeze experiments show that this split is, in practice, related to the model's state dynamics: in Sudoku, freezing $\zH$ reduces $\zL$'s content changes whereas freezing $\zL$ increases $\zH$'s, while in Maze, freezing either state increases content changes in the other state. Ablations show that to induce specialization, the shared model needs to be able to tell the two update types apart, either from input injection asymmetry or from a separate level token. Mechanistically, attention analysis shows that L-updates are consistently more local than H-updates in both Sudoku and Maze. Together, these results show that, in a two-state recurrent setting, a clear state-identity signal can induce stable, related functional roles inside a shared-parameter recurrent Transformer. Code is available at \href{https://github.com/juchengshen/air}{\textcolor{blue}{https://github.com/juchengshen/air}}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Asymmetric Input Recurrence (AIR), a minimal two-state recurrent Transformer in which a shared-parameter model is reused for L- and H-updates, with the sole built-in asymmetry being input injection during L-updates (or an explicit level token). Across Sudoku-Extreme and Maze, decoded rollouts show zH behaving as a committed proposal state while zL retains local uncertainty and shifting structure. Freeze experiments demonstrate interdependence between the states, ablations confirm that distinguishability of update types is required for the split, and attention analysis reveals consistently more local attention in L-updates than H-updates. The central claim is that a clear state-identity signal suffices to induce stable, related functional roles inside a shared recurrent Transformer.
Significance. If the causal link between the minimal asymmetry and the observed specialization holds, the result provides evidence that functional differentiation can emerge in shared-weight recurrent architectures without explicit modularization. This is relevant to designs for multi-step reasoning models. The public code release supports reproducibility and is a positive feature.
major comments (1)
- Abstract and freeze-experiment description: the reported interdependence (freezing zH reduces zL changes in Sudoku; freezing either increases changes in the other in Maze) is correlational and does not isolate whether the specific functional roles (zH as committed proposal, zL as uncertain local structure) are induced by the input-injection asymmetry or level token versus arising from task-specific training dynamics that reward phased proposal/refinement once states are distinguishable. The ablations establish only that distinguishability is necessary, not that it is sufficient to produce these particular roles independent of Sudoku-Extreme and Maze objectives.
minor comments (1)
- Clarify the precise definition and implementation of the level token versus input-injection asymmetry in the methods section; the abstract treats them as interchangeable but the mechanistic implications may differ.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comment below and have revised the manuscript to clarify the scope of our claims.
read point-by-point responses
-
Referee: Abstract and freeze-experiment description: the reported interdependence (freezing zH reduces zL changes in Sudoku; freezing either increases changes in the other in Maze) is correlational and does not isolate whether the specific functional roles (zH as committed proposal, zL as uncertain local structure) are induced by the input-injection asymmetry or level token versus arising from task-specific training dynamics that reward phased proposal/refinement once states are distinguishable. The ablations establish only that distinguishability is necessary, not that it is sufficient to produce these particular roles independent of Sudoku-Extreme and Maze objectives.
Authors: We agree that the freeze experiments demonstrate correlational interdependence and do not by themselves establish that the input-injection asymmetry (or level token) is what induces the precise functional roles observed. The ablations show that distinguishability between update types is necessary for any specialization to emerge. We maintain that the consistent appearance of the same roles (committed zH proposal state and shifting zL uncertainty) across two tasks with different objectives and structures provides supporting evidence that the minimal asymmetry plays a causal enabling role. Nevertheless, we acknowledge that task-specific training dynamics may also shape the exact roles once distinguishability is present. We have revised the abstract and the freeze-experiment discussion to more precisely describe the evidence as showing necessity via ablations plus observed consistency, while noting the correlational nature of the interdependence results. revision: yes
Circularity Check
No circularity: empirical observations from ablations and rollouts do not reduce to fitted inputs or self-referential definitions.
full rationale
The paper reports an empirical investigation of emergent specialization in a shared recurrent Transformer under Asymmetric Input Recurrence. Claims rest on decoded rollouts, freeze experiments showing interdependence between states, ablations requiring distinguishable update types, and attention locality differences across Sudoku-Extreme and Maze. No derivation chain, first-principles equations, or predictions are presented that reduce by construction to fitted parameters, self-definitions, or self-citation load-bearing premises. The central result—that a state-identity signal can induce functional roles—is supported by direct experimental contrasts rather than any renaming or smuggling of prior results into the current analysis.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Sudoku-Extreme and Maze tasks are representative environments in which state specialization can be reliably observed and measured.
Reference graph
Works this paper leans on
-
[1]
Andreas, Jacob and Rohrbach, Marcus and Darrell, Trevor and Klein, Dan , title =. CVPR , year =
-
[2]
8th ICML Workshop on Automated Machine Learning , year =
Banino, Andrea and Balaguer, Jan and Blundell, Charles , title =. 8th ICML Workshop on Automated Machine Learning , year =
-
[3]
A Mechanistic Analysis of Looped Reasoning Language Models , journal =
Blayney, Hugh and Arroyo,. A Mechanistic Analysis of Looped Reasoning Language Models , journal =
-
[4]
Brinkmann, Jannik and Sheshadri, Abhay and Levoso, Victor and Swoboda, Paul and Bartelt, Christian , title =. Findings of ACL , pages =
- [5]
-
[6]
Universal Transformers , booktitle =
Dehghani, Mostafa and Gouws, Stephan and Vinyals, Oriol and Uszkoreit, Jakob and Kaiser,. Universal Transformers , booktitle =
-
[7]
Transformer Circuits Thread , year =
Elhage, Nelson and Nanda, Neel and Olsson, Catherine and Henighan, Tom and Joseph, Nicholas and Mann, Ben and Askell, Amanda and Bai, Yuntao and Chen, Anna and Conerly, Tom and DasSarma, Nova and Drain, Dawn and Ganguli, Deep and Hatfield-Dodds, Zac and Hernandez, Danny and Jones, Andy and Kernion, Jackson and Lovitt, Liane and Ndousse, Kamal and Amodei, ...
-
[8]
and Novak, Roman and Liu, Peter J
Everett, Katie and Xiao, Lechao and Wortsman, Mitchell and Alemi, Alexander A. and Novak, Roman and Liu, Peter J. and Gur, Izzeddin and Sohl-Dickstein, Jascha and Kaelbling, Leslie Pack and Lee, Jaehoon and Pennington, Jeffrey , title =. ICML , year =
-
[9]
Ge, Renee and Liao, Qianli and Poggio, Tomaso , title =. arXiv:2510.00355 , year =
-
[10]
and Papailiopoulos, Dimitris , title =
Giannou, Angeliki and Rajput, Shashank and Sohn, Jy-yong and Lee, Kangwook and Lee, Jason D. and Papailiopoulos, Dimitris , title =. ICML , year =
-
[11]
Recurrent Independent Mechanisms , booktitle =
Goyal, Anirudh and Lamb, Alex and Hoffmann, Jordan and Sodhani, Shagun and Levine, Sergey and Bengio, Yoshua and Sch. Recurrent Independent Mechanisms , booktitle =
-
[12]
Adaptive Computation Time for Recurrent Neural Networks
Graves, Alex , title =. arXiv:1603.08983 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Hao, Shibo and Sukhbaatar, Sainbayar and Su, DiJia and Li, Xian and Hu, Zhiting and Weston, Jason and Tian, Yuandong , title =. COLM , year =
-
[14]
Hong, Guan Zhe and Dikkala, Nishanth and Luo, Enming and Rashtchian, Cyrus and Wang, Xin and Panigrahy, Rina , title =. NeurIPS , year =
-
[15]
Less is More: Recursive Reasoning with Tiny Networks
Jolicoeur-Martineau, Alexia , title =. arXiv:2510.04871 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Maze 30 30 Hard 1k Dataset , howpublished =
-
[17]
Show Your Work: Scratchpads for Intermediate Computation with Language Models
Nye, Maxwell and Andreassen, Anders Johan and Gur-Ari, Guy and Michalewski, Henryk and Austin, Jacob and Bieber, David and Dohan, David and Lewkowycz, Aitor and Bosma, Maarten and Luan, David and Sutton, Charles and Odena, Augustus , title =. arXiv:2112.00114 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Transformer Circuits Thread , year =
Olsson, Catherine and Elhage, Nelson and Nanda, Neel and Joseph, Nicholas and DasSarma, Nova and Henighan, Tom and Mann, Ben and Askell, Amanda and Bai, Yuntao and Chen, Anna and Conerly, Tom and Drain, Dawn and Ganguli, Deep and Hatfield-Dodds, Zac and Hernandez, Danny and Johnston, Scott and Jones, Andy and Kernion, Jackson and Lovitt, Liane and Ndousse...
-
[19]
Prieto, Lucas and Barsbey, Melih and Mediano, Pedro A. M. and Birdal, Tolga , title =. ICLR , year =
-
[20]
Schwarzschild, Avi and Borgnia, Eitan and Gupta, Arjun and Huang, Furong and Vishkin, Uzi and Goldblum, Micah and Goldstein, Tom , title =. NeurIPS , year =
-
[21]
Tomoda, Yuki and Tsuda, Ichiro and Yamaguti, Yutaka , title =. arXiv:2507.12858 , year =
-
[22]
Wang, Guan and Li, Jin and Sun, Yuhao and Chen, Xing and Liu, Changling and Wu, Yue and Lu, Meng and Song, Sen and Yadkori, Yasin Abbasi , title =. arXiv:2506.21734 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Wei, Jason and Wang, Xuezhi and Schuurmans, Dale and Bosma, Maarten and Ichter, Brian and Xia, Fei and Chi, Ed and Le, Quoc and Zhou, Denny , title =. NeurIPS , year =
-
[24]
Williams, Ronald J. and Peng, Jing , title =. Neural Computation , volume =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.