Understanding Parallel Samplers in Masked Diffusion via Random Walks on Graphs
Pith reviewed 2026-06-26 08:49 UTC · model grok-4.3
The pith
Random walks on graphs show that lowest-entropy parallel unmasking is not always better than random sampling in masked diffusion models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
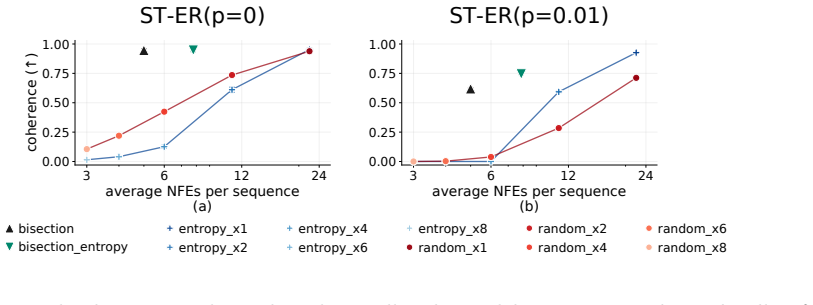
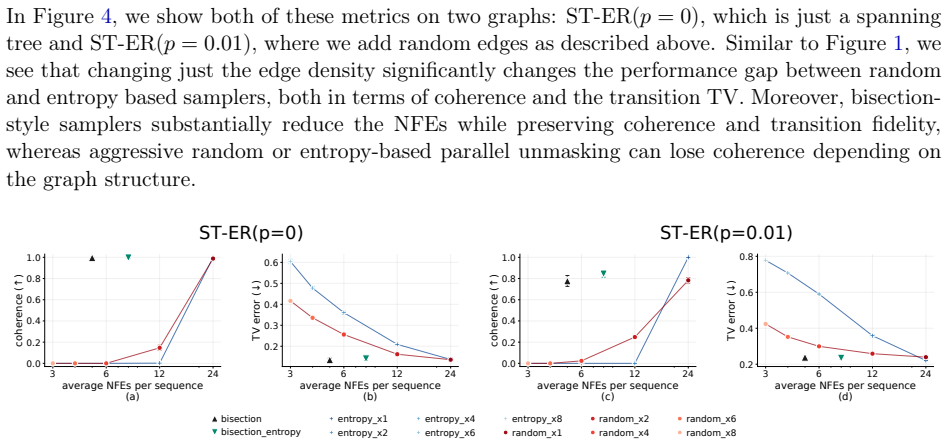
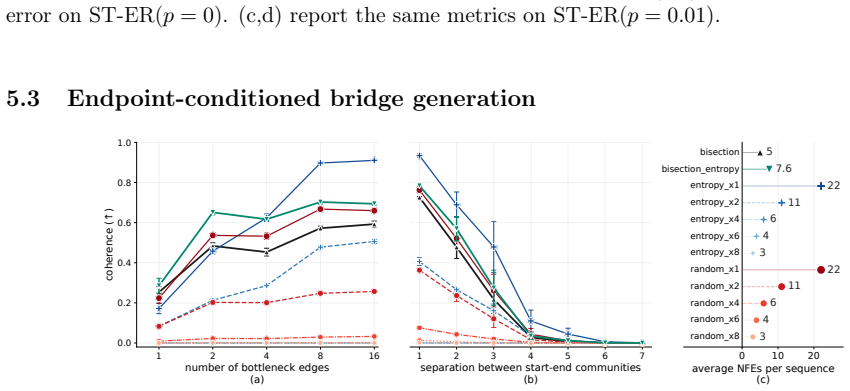
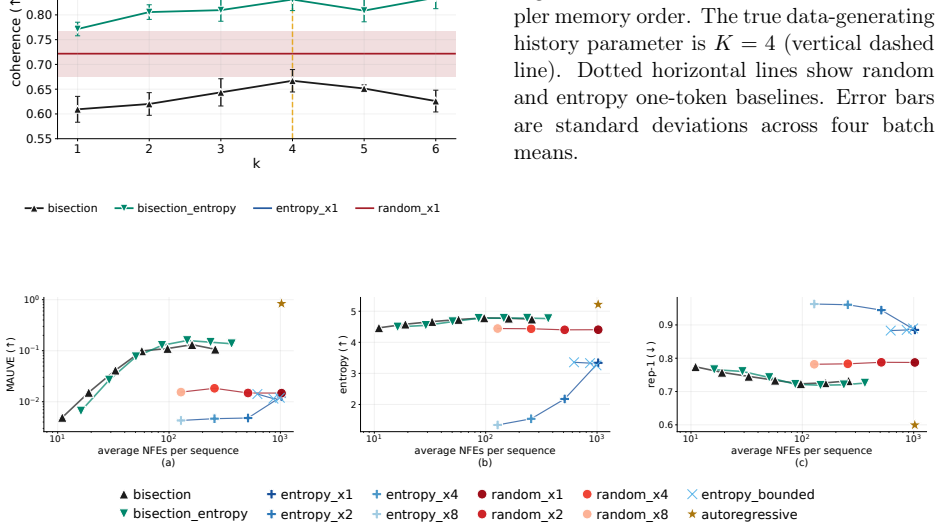
Random walks on graphs act as a controllable latent structure for training masked diffusion models, allowing exact verification that outputs are valid walks and that the recovered kernel matches the original; under this setup, lowest-entropy parallel unmasking is not uniformly superior to random parallel sampling, and a bisection sampler achieves logarithmic steps while remaining exact under perfect training.
What carries the argument
The bisection sampler, which repeatedly bisects the masked positions to decide the next parallel unmasking set and thereby reduces the number of sampling steps to logarithmic in sequence length.
If this is right
- Performance ordering among parallel samplers changes with the underlying graph, so no single unmasking rule is universally best.
- The bisection sampler produces exact samples in logarithmic steps whenever training recovers the hidden kernel.
- The same validity and kernel-recovery checks can be used to compare any new parallel sampler on the same hidden-graph tasks.
- Bisection-style schedules improve the speed-quality tradeoff on a pretrained language masked diffusion model.
Where Pith is reading between the lines
- The same hidden-structure testbed could be applied to other sequence domains whose generative process has an unobserved graph or tree component.
- If the bisection sampler generalizes, it could reduce the number of forward passes needed for high-quality text generation without sacrificing distribution fidelity.
- Kernel-recovery diagnostics might be adapted to detect when a diffusion model has failed to learn long-range dependencies in real data.
Load-bearing premise
The model can recover the latent graph structure and transition kernel from walk samples alone, without ever being shown the graph or kernel.
What would settle it
On a simple cycle or path graph, generate many sequences with the bisection sampler after perfect training and check whether the fraction of invalid walks is zero and whether the empirical transition counts exactly match the true kernel.
Figures


read the original abstract
In this paper, we propose using random walks on graphs as a verifiable sandbox to study different parallel sampling strategies in masked diffusion models (MDMs). We train an MDM on random walk samples from a fixed graph. The graph or the transition kernel is never shown to the model explicitly and plays the role of latent structure in the sequences, albeit one that is controllable and can be used for quantitative evaluation. Thus, this framework enjoys a Sudoku-like validity check: verifying that an output is a valid walk and estimating the Markov kernel from the walks to measure distribution fidelity. Using simple graphs, we theoretically prove that parallel unmasking via widely used scores like lowest entropy is not uniformly better than a random parallel sampler; the performance critically depends on the structure of the underlying graph. We develop a new bisection sampler for random walks, which takes logarithmic steps in the sequence length and is provably exact under perfect training. Experiments on various graph walk tasks show that different parallel samplers are better for different graphs even in practice. Our initial experiments on a pretrained OpenWebText MDM show that the bisection-style samplers improve speed-quality tradeoffs even for language generation. Together, these results position graph random walks as a mechanistic benchmark for diagnosing and designing parallel samplers for masked diffusion models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes random walks on graphs as a controllable, verifiable sandbox for studying parallel sampling strategies in masked diffusion models (MDMs). An MDM is trained exclusively on sequences generated by random walks on a fixed but latent graph (never shown explicitly to the model), enabling Sudoku-style checks: verifying that generated sequences are valid walks on the graph and recovering the Markov transition kernel to assess distributional fidelity. Theoretical analysis on simple graphs shows that parallel unmasking ordered by lowest entropy is not uniformly superior to random parallel sampling and that performance depends on graph structure. A new bisection sampler is introduced that requires only logarithmic steps in sequence length and is provably exact under perfect training. Experiments on multiple graph families confirm that sampler ranking varies with graph structure; preliminary results on a pretrained OpenWebText MDM indicate that bisection-style samplers improve speed-quality trade-offs in language generation.
Significance. If the central claims hold, the work supplies a mechanistic benchmark that allows rigorous, quantitative diagnosis of parallel samplers—something currently missing from the MDM literature. The graph-walk construction provides an external ground truth for validity and kernel recovery that is independent of the learned model, enabling falsifiable tests of sampler quality. The theoretical demonstration that no single parallel strategy dominates across graphs, together with the bisection sampler’s logarithmic exactness guarantee under perfect training, supplies concrete, actionable insight. The language-model experiment, while preliminary, suggests the framework can transfer beyond the sandbox.
minor comments (3)
- [§3.2] §3.2: the statement that the bisection sampler is 'provably exact under perfect training' would benefit from an explicit statement of the induction hypothesis and the precise conditioning on the learned conditional distributions (currently only sketched).
- [Figure 4] Figure 4: the legend for the four samplers is difficult to read at the printed size; consider increasing font size or adding a table of per-graph win rates.
- [§4.3] §4.3: the OpenWebText experiment reports only aggregate MAUVE and speed; adding per-length perplexity or validity-proxy metrics would strengthen the claim that bisection-style sampling transfers.
Simulated Author's Rebuttal
We thank the referee for their positive and constructive review, which recognizes the value of the graph random walk sandbox as a mechanistic benchmark for parallel samplers in masked diffusion models. We are pleased with the recommendation for minor revision and note that no specific major comments were raised.
Circularity Check
No significant circularity detected
full rationale
The paper constructs its analysis around an external fixed graph that generates walk sequences; the model receives only the sequences and never the graph or kernel explicitly. Validity checks (Sudoku-style walk validation) and kernel estimation are defined independently of the learned distribution. Theoretical claims (non-uniformity of lowest-entropy unmasking, exactness of the bisection sampler under perfect training) are derived from the controllable graph structure and stated assumptions rather than from any fitted parameter or self-referential definition. Experiments on both synthetic graphs and a pretrained OpenWebText model remain falsifiable against the external benchmark. No load-bearing step reduces by construction to its own inputs, and no self-citation chain is invoked to justify uniqueness or ansatz choices.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The trained MDM can recover the latent transition kernel of the hidden graph from walk samples without explicit graph input.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2511.07869 , year =
Parallel Sampling via Autospeculation , author =. arXiv preprint arXiv:2511.07869 , year =
-
[2]
The Thirteenth International Conference on Learning Representations , year =
Block Diffusion: Interpolating Between Autoregressive and Diffusion Language Models , author =. The Thirteenth International Conference on Learning Representations , year =
-
[3]
Advances in Neural Information Processing Systems , volume =
Structured Denoising Diffusion Models in Discrete State-Spaces , author =. Advances in Neural Information Processing Systems , volume =
-
[4]
Advances in Neural Information Processing Systems , year =
Accelerated Sampling from Masked Diffusion Models via Entropy Bounded Unmasking , author =. Advances in Neural Information Processing Systems , year =
-
[5]
Science , volume =
Higher-order organization of complex networks , author =. Science , volume =. 2016 , doi =
2016
-
[6]
SIAM Review , volume=
The spacey random walk: A stochastic process for higher-order data , author=. SIAM Review , volume=. 2017 , publisher=
2017
-
[7]
Advances in Neural Information Processing Systems , volume =
A Continuous Time Framework for Discrete Denoising Models , author =. Advances in Neural Information Processing Systems , volume =
-
[8]
Proceedings of the 41st International Conference on Machine Learning , series =
Generative Flows on Discrete State-Spaces: Enabling Multimodal Flows with Applications to Protein Co-Design , author =. Proceedings of the 41st International Conference on Machine Learning , series =. 2024 , publisher =
2024
-
[9]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
MaskGIT: Masked Generative Image Transformer , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
-
[10]
Proceedings of the 21st international conference on World Wide Web , pages=
Are web users really markovian? , author=. Proceedings of the 21st international conference on World Wide Web , pages=
-
[11]
BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina , booktitle =. 2019 , publisher =. doi:10.18653/v1/N19-1423 , url =
-
[12]
Advances in Neural Information Processing Systems , volume =
Discrete Flow Matching , author =. Advances in Neural Information Processing Systems , volume =. 2024 , doi =
2024
-
[13]
OpenWebText Corpus , author=
-
[14]
The Eleventh International Conference on Learning Representations , year =
DiffuSeq: Sequence to Sequence Text Generation with Diffusion Models , author =. The Eleventh International Conference on Learning Representations , year =
-
[15]
He, Zhengfu and Sun, Tianxiang and Tang, Qiong and Wang, Kuanning and Huang, Xuanjing and Qiu, Xipeng , booktitle =. 2023 , address =. doi:10.18653/v1/2023.acl-long.248 , url =
-
[16]
Advances in Neural Information Processing Systems , volume =
Argmax Flows and Multinomial Diffusion: Learning Categorical Distributions , author =. Advances in Neural Information Processing Systems , volume =. 2021 , url =
2021
-
[17]
Proceedings of the 42nd International Conference on Machine Learning , year =
Train for the Worst, Plan for the Best: Understanding Token Ordering in Masked Diffusions , author =. Proceedings of the 42nd International Conference on Machine Learning , year =
-
[18]
Proceedings of the National Academy of Sciences , volume=
Spectral redemption in clustering sparse networks , author=. Proceedings of the National Academy of Sciences , volume=. 2013 , publisher=
2013
-
[19]
, booktitle =
Li, Xiang Lisa and Thickstun, John and Gulrajani, Ishaan and Liang, Percy and Hashimoto, Tatsunori B. , booktitle =. Diffusion-. 2022 , url =
2022
-
[20]
Proceedings of the 41st International Conference on Machine Learning , series =
Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution , author =. Proceedings of the 41st International Conference on Machine Learning , series =. 2024 , publisher =
2024
-
[21]
arXiv preprint arXiv:2502.09992 , year =
Large Language Diffusion Models , author =. arXiv preprint arXiv:2502.09992 , year =
-
[22]
The Thirteenth International Conference on Learning Representations , year =
Your Absorbing Discrete Diffusion Secretly Models the Conditional Distributions of Clean Data , author =. The Thirteenth International Conference on Learning Representations , year =
-
[23]
2021 , url =
Pillutla, Krishna and Swayamdipta, Swabha and Zellers, Rowan and Thickstun, John and Welleck, Sean and Choi, Yejin and Harchaoui, Zaid , booktitle =. 2021 , url =
2021
-
[24]
Nature communications , volume=
Memory in network flows and its effects on spreading dynamics and community detection , author=. Nature communications , volume=. 2014 , publisher=
2014
-
[25]
Advances in Neural Information Processing Systems , year =
Simple and Effective Masked Diffusion Language Models , author =. Advances in Neural Information Processing Systems , year =
-
[26]
Advances in Neural Information Processing Systems , year =
Simplified and Generalized Masked Diffusion for Discrete Data , author =. Advances in Neural Information Processing Systems , year =
-
[27]
Advances in Neural Information Processing Systems , volume =
Training and Inference on Any-Order Autoregressive Models the Right Way , author =. Advances in Neural Information Processing Systems , volume =
-
[28]
The Eleventh International Conference on Learning Representations , year =
Score-based Continuous-time Discrete Diffusion Models , author =. The Eleventh International Conference on Learning Representations , year =
-
[29]
Proceedings of the 31st International Conference on Machine Learning , series =
A Deep and Tractable Density Estimator , author =. Proceedings of the 31st International Conference on Machine Learning , series =. 2014 , publisher =
2014
-
[30]
Journal of Machine Learning Research , volume =
Neural Autoregressive Distribution Estimation , author =. Journal of Machine Learning Research , volume =
-
[31]
Advances in Neural Information Processing Systems , year =
Remasking Discrete Diffusion Models with Inference-Time Scaling , author =. Advances in Neural Information Processing Systems , year =
-
[32]
arXiv preprint arXiv:2506.10848 , year =
Accelerating Diffusion Large Language Models with SlowFast Sampling: The Three Golden Principles , author =. arXiv preprint arXiv:2506.10848 , year =
-
[33]
The Fourteenth International Conference on Learning Representations , year =
Fast-dLLM: Training-free Acceleration of Diffusion LLM by Enabling KV Cache and Parallel Decoding , author =. The Fourteenth International Conference on Learning Representations , year =
-
[34]
arXiv preprint arXiv:2308.12219 , year =
Diffusion Language Models Can Perform Many Tasks with Scaling and Instruction-Finetuning , author =. arXiv preprint arXiv:2308.12219 , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.