ScaleHP: Estimating Hand Pose in Metric Space
Pith reviewed 2026-06-25 21:03 UTC · model grok-4.3
The pith
Hand bone proportions encode absolute metric scale for single-image 3D pose estimation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
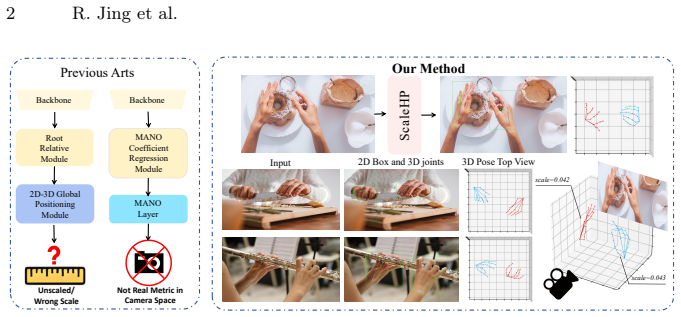
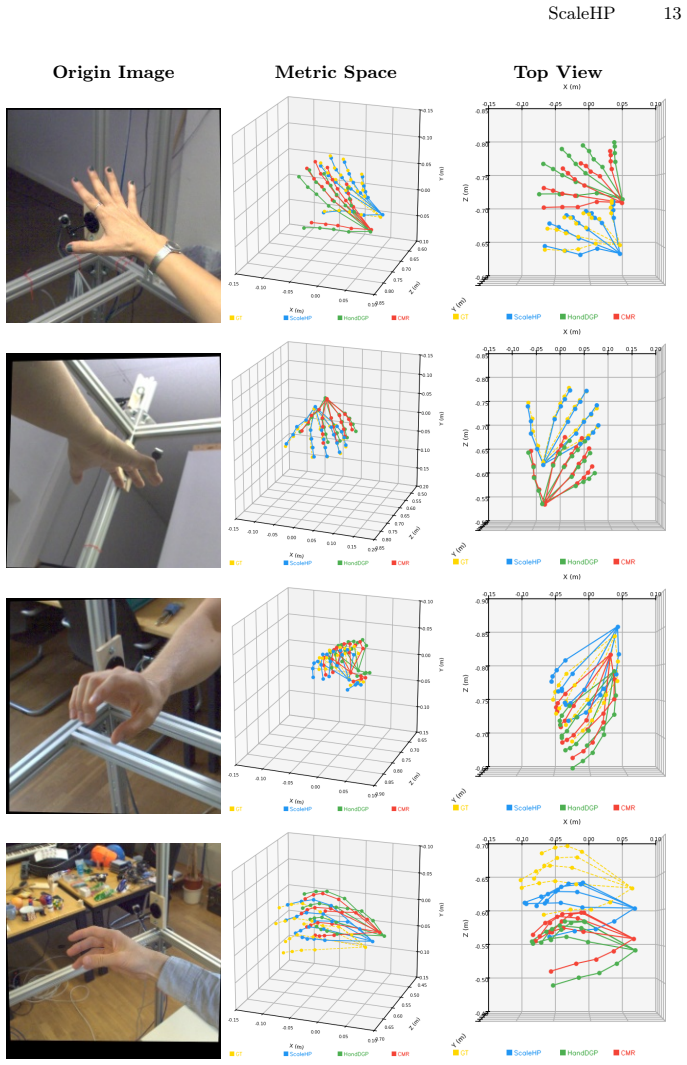
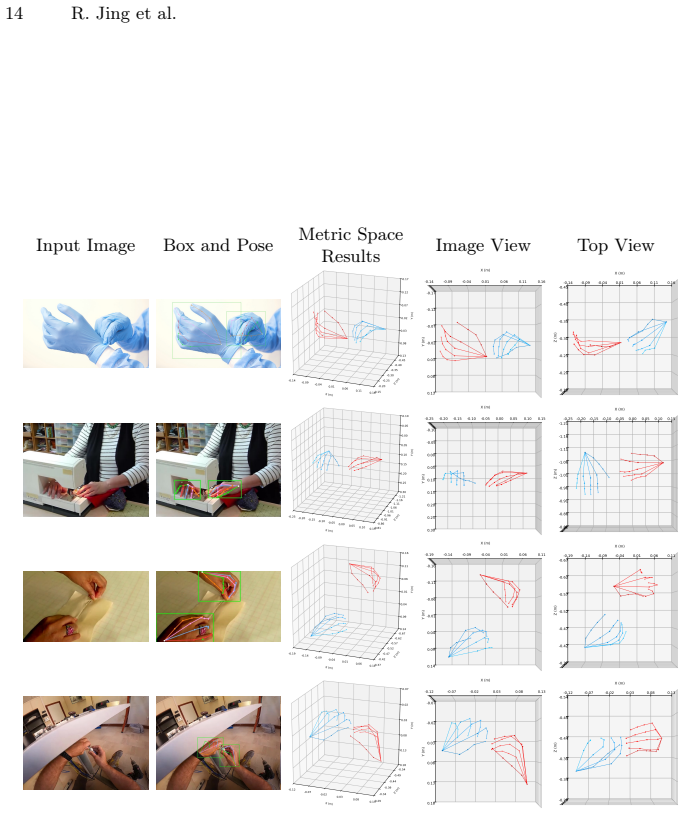
By observing that proportional relationships among human hand bones encode stable anthropometric priors that implicitly correlate with the overall metric size, ScaleHP recovers hand poses directly in metric space using an end-to-end framework with a scale token in a transformer decoder and perspective-constrained least-squares optimization, achieving 35.8 CS-MPJPE on FreiHand and 4.6/5.9 PA-MPJPE on DexYCB/HO3Dv3.
What carries the argument
The scale token in the transformer-based decoder that fuses multi-scale morphological and appearance features to enable metric coordinate recovery via perspective-constrained least-squares.
If this is right
- Internal biological constraints reduce both relative geometry and absolute metric errors in hand pose estimates.
- Metric-space hand tracking becomes possible without fragile extrinsic depth modules or person-specific calibration.
- State-of-the-art performance is achieved on FreiHand, DexYCB, and HO3Dv3 benchmarks.
- The approach offers a robust solution for generalized real-world hand tracking in human-computer interaction and robotics.
Where Pith is reading between the lines
- Similar proportion-based priors could apply to metric estimation for other articulated structures where stable ratios exist.
- Accuracy would drop if bone proportions vary substantially across populations not represented in training data.
- The least-squares step could combine with additional geometric cues such as known camera intrinsics for further gains.
Load-bearing premise
Hand bone length proportions remain stable across individuals and implicitly encode absolute metric scale without person-specific calibration.
What would settle it
Empirical measurement of hand bone proportions across a diverse population showing variations large enough to cause substantial metric pose estimation errors on the reported benchmarks.
Figures

read the original abstract
Accurate metric-space hand pose estimation (HPE) is essential for immersive human-computer interaction and robotics. However, most existing methods predict poses in a root-relative coordinate system and cannot estimate the hand in absolute metric scale. In this work, we observe that the intrinsic proportional relationships among human hand bones encode stable anthropometric priors that implicitly correlate with the overall metric size of the hand. Leveraging this insight, we present ScaleHP, an end-to-end one-stage hand pose estimation framework that bypasses fragile extrinsic depth modules to recover the hand in metric space. ScaleHP employs a transformer-based decoder with a novel scale token to fuse multi-scale morphological and appearance features. By solving for metric coordinates through a perspective-constrained least-squares approach, we achieve high-precision pose estimation in the camera coordinate system. ScaleHP delivers state-of-the-art performance, including 35.8 CS-MPJPE on FreiHand and 4.6/5.9 PA-MPJPE on DexYCB and HO3Dv3. These results demonstrate that internal biological constraints significantly reduce relative geometry and absolute metric errors, offering a robust solution for generalized, real-world hand tracking.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that intrinsic proportional relationships among human hand bones encode stable anthropometric priors correlating with overall metric hand size; ScaleHP uses a transformer decoder with a novel scale token to fuse features and a perspective-constrained least-squares solver to recover absolute metric pose in camera coordinates, achieving SOTA results of 35.8 CS-MPJPE on FreiHand and 4.6/5.9 PA-MPJPE on DexYCB/HO3Dv3 without external depth or calibration.
Significance. If the bone-proportion-to-metric-scale correlation holds with sufficient tightness, the work would be significant for enabling calibration-free metric HPE in HCI and robotics. The reported empirical results on three standard datasets are competitive and the one-stage design is a practical strength; however, the significance is limited by the absence of explicit quantification of the prior's correlation strength or generalization tests.
major comments (3)
- [Abstract] Abstract: the claim that bone length proportions 'implicitly correlate with the overall metric size' is load-bearing, yet ratios are scale-invariant by construction; no quantitative correlation analysis, variance statistics, or ablation across demographics/ages/ethnicities is supplied to show that the statistical association is tight enough to determine absolute scale independently of the training distribution.
- [Method (perspective-constrained least-squares)] Method description of the perspective-constrained least-squares solver: the solve is presented at high level with no derivation, objective function, or error analysis; it is therefore impossible to verify whether the metric output is independent of the morphological features already used to define the scale token prior or whether it reduces to a data-driven fit.
- [Results] Results section: the reported CS-MPJPE and PA-MPJPE numbers are given without an ablation isolating the contribution of the bone-proportion prior versus the transformer backbone or the least-squares step, leaving the central claim that 'internal biological constraints significantly reduce ... absolute metric errors' unsupported by controlled evidence.
minor comments (1)
- Notation for the scale token and the least-squares variables is introduced without an explicit equation or table summarizing symbols.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help strengthen the presentation of our work. We address each major point below and will incorporate the suggested clarifications and analyses in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that bone length proportions 'implicitly correlate with the overall metric size' is load-bearing, yet ratios are scale-invariant by construction; no quantitative correlation analysis, variance statistics, or ablation across demographics/ages/ethnicities is supplied to show that the statistical association is tight enough to determine absolute scale independently of the training distribution.
Authors: We agree the claim requires quantitative backing. In revision we will add correlation analysis on the training sets (Pearson coefficients and variance between bone ratios and metric hand size) plus explicit discussion of the assumption's validity within the adult-centric distributions of FreiHand, DexYCB and HO3Dv3. We cannot supply cross-demographic ablations without new data. revision: partial
-
Referee: [Method (perspective-constrained least-squares)] Method description of the perspective-constrained least-squares solver: the solve is presented at high level with no derivation, objective function, or error analysis; it is therefore impossible to verify whether the metric output is independent of the morphological features already used to define the scale token prior or whether it reduces to a data-driven fit.
Authors: We will expand the method section with the full derivation, objective function (reprojection error minimized subject to the scale-token prior and perspective constraints), and error analysis demonstrating that the geometric solve recovers metric scale independently of the learned morphological features while using them only for initialization. revision: yes
-
Referee: [Results] Results section: the reported CS-MPJPE and PA-MPJPE numbers are given without an ablation isolating the contribution of the bone-proportion prior versus the transformer backbone or the least-squares step, leaving the central claim that 'internal biological constraints significantly reduce ... absolute metric errors' unsupported by controlled evidence.
Authors: We will add controlled ablations comparing (i) transformer backbone alone, (ii) backbone plus scale token without the least-squares solver, and (iii) the full model, thereby quantifying the prior's isolated contribution to absolute metric accuracy. revision: yes
- Ablation or quantitative analysis across demographics, ages, and ethnicities, as this requires new annotated datasets outside the scope of the current benchmarks.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's central claim rests on an empirical observation about anthropometric correlations in hand bone proportions, implemented via a learned transformer decoder with scale token and a perspective-constrained least-squares solver. No load-bearing step reduces a prediction to its inputs by construction, no self-citation chain justifies uniqueness, and no ansatz or renaming is smuggled in. The metric estimation is data-driven and externally validated on FreiHand, DexYCB, and HO3Dv3, making the derivation self-contained against benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Hand bone length proportions are stable across individuals and correlate with absolute hand size
Reference graph
Works this paper leans on
-
[1]
Baek, S., Kim, K.I., Kim, T.: Pushing the envelope for rgb-based dense 3d hand pose estimation via neural rendering. In: IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, June 16-20, 2019. pp. 1067–1076. Computer Vision Foundation / IEEE (2019).https://doi.org/ 10.1109/CVPR.2019.001163
-
[2]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Bhat, S.F., Alhashim, I., Wonka, P.: Adabins: Depth estimation using adaptive bins. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 4009–4018 (2021) 5
2021
-
[3]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Boukhayma, A., Bem, R.d., Torr, P.H.: 3d hand shape and pose from images in the wild. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10843–10852 (2019) 2
2019
-
[4]
In: European conference on computer vision
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., Zagoruyko, S.: End- to-end object detection with transformers. In: European conference on computer vision. pp. 213–229. Springer (2020) 4
2020
-
[5]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Chao,Y.W.,Yang,W.,Xiang, Y.,Molchanov,P.,Handa,A., Tremblay, J.,Narang, Y.S., Van Wyk, K., Iqbal, U., Birchfield, S., et al.: Dexycb: A benchmark for capturing hand grasping of objects. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 9044–9053 (2021) 10, 22
2021
-
[6]
Chen, X., Liu, Y., Dong, Y., Zhang, X., Ma, C., Xiong, Y., Zhang, Y., Guo, X.: Mobrecon: Mobile-friendly hand mesh reconstruction from monocular image. In: IEEE/CVFConferenceonComputerVisionandPatternRecognition,CVPR2022, New Orleans, LA, USA, June 18-24, 2022. pp. 20512–20522. IEEE (2022).https: //doi.org/10.1109/CVPR52688.2022.019894, 6, 12 ScaleHP 17
-
[7]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Chen, X., Liu, Y., Ma, C., Chang, J., Wang, H., Chen, T., Guo, X., Wan, P., Zheng, W.: Camera-space hand mesh recovery via semantic aggregation and adaptive 2d- 1d registration. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 13274–13283 (2021) 4, 6, 12, 22
2021
-
[8]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Chen, X., Song, Z., Jiang, X., Hu, Y., Yu, J., Zhang, L.: Handos: 3d hand re- construction in one stage. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 17304–17314 (2025) 6, 10, 12
2025
-
[9]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Chen, Y., Tu, Z., Kang, D., Bao, L., Zhang, Y., Zhe, X., Chen, R., Yuan, J.: Model-based 3d hand reconstruction via self-supervised learning. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10451–10460 (2021) 3
2021
-
[10]
2021 IEEE/CVF ConferenceonComputerVisionandPatternRecognition(CVPR)pp.10446–10455 (2021) 12
Chen, Y., Tu, Z., Kang, D., Bao, L., Zhang, Y., Zhe, X., Chen, R., Yuan, J.: Model-based 3d hand reconstruction via self-supervised learning. 2021 IEEE/CVF ConferenceonComputerVisionandPatternRecognition(CVPR)pp.10446–10455 (2021) 12
2021
-
[11]
In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J
Choi, H., Moon, G., Lee, K.M.: Pose2mesh: Graph convolutional network for 3d human pose and mesh recovery from a 2d human pose. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J. (eds.) Computer Vision - ECCV 2020 - 16th European Conference, Glasgow, UK, August 23-28, 2020, Proceedings, Part VII. Lecture Notes in Computer Science, vol. 12352, pp. 769–787. ...
-
[12]
In: Glober- sons, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J.M., Zhang, C
Dong, H., Chharia, A., Gou, W., Carrasco, F.V., la Torre, F.D.: Hamba: Single- view 3d hand reconstruction with graph-guided bi-scanning mamba. In: Glober- sons, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J.M., Zhang, C. (eds.) Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems...
2024
-
[13]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Ge, L., Ren, Z., Li, Y., Xue, Z., Wang, Y., Cai, J., Yuan, J.: 3d hand shape and pose estimation from a single rgb image. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10833–10842 (2019) 4, 6
2019
-
[14]
In: First conference on language modeling (2024) 4
Gu, A., Dao, T.: Mamba: Linear-time sequence modeling with selective state spaces. In: First conference on language modeling (2024) 4
2024
-
[15]
In: Proceedings of the IEEE/CVF Inter- national Conference on Computer Vision
Guizilini, V., Vasiljevic, I., Chen, D., Ambrus,, R., Gaidon, A.: Towards zero-shot scale-aware monocular depth estimation. In: Proceedings of the IEEE/CVF Inter- national Conference on Computer Vision. pp. 9233–9243 (2023) 5
2023
-
[16]
2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp
Hampali, S., Rad, M., Oberweger, M., Lepetit, V.: Honnotate: A method for 3d annotation of hand and object poses. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp. 3193–3203 (2019) 10, 22
2020
-
[17]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Hasson, Y., Tekin, B., Bogo, F., Laptev, I., Pollefeys, M., Schmid, C.: Leveraging photometric consistency over time for sparsely supervised hand-object reconstruc- tion. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 571–580 (2020) 2, 4
2020
-
[18]
In: Proceed- ings of the IEEE/CVF conference on computer vision and pattern recognition
Hasson, Y., Varol, G., Tzionas, D., Kalevatykh, I., Black, M.J., Laptev, I., Schmid, C.: Learning joint reconstruction of hands and manipulated objects. In: Proceed- ings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 11807–11816 (2019) 3, 12
2019
-
[19]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Huang, L., Lin, C.C., Lin, K., Liang, L., Wang, L., Yuan, J., Liu, Z.: Neural voting field for camera-space 3d hand pose estimation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 8969–8978 (2023) 4, 22 18 R. Jing et al
2023
-
[20]
In: Proceedings of the European conference on computer vision (ECCV)
Iqbal, U., Molchanov, P., Gall, T.B.J., Kautz, J.: Hand pose estimation via latent 2.5 d heatmap regression. In: Proceedings of the European conference on computer vision (ECCV). pp. 118–134 (2018) 3, 4
2018
-
[21]
In: Proceedings of the IEEE/CVF international conference on computer vision
Jiang, H., Liu, S., Wang, J., Wang, X.: Hand-object contact consistency reason- ing for human grasps generation. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 11107–11116 (2021) 3
2021
-
[22]
2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp
Jiang, Z., Rahmani, H., Black, S., Williams, B.M.: A probabilistic attention model withocclusion-awaretextureregressionfor3dhandreconstructionfromasinglergb image. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp. 758–768 (2023) 12
2023
-
[23]
Jin, S., Xu, L., Xu, J., Wang, C., Liu, W., Qian, C., Ouyang, W., Luo, P.: Whole- body human pose estimation in the wild. ArXivabs/2007.11858(2020) 10
arXiv 2007
-
[24]
A tutorial on chirp spread spectrum modulation for LoRaW AN: Basics and key advances,
Kamdjou, H.M., Baudry, D., Havard, V., Ouchani, S.: Resource-constrained ex- tended reality operated with digital twin in industrial internet of things. IEEE Open J. Commun. Soc.5, 928–950 (2024).https://doi.org/10.1109/OJCOMS. 2024.33565081
-
[25]
IEEE Access13, 135609–135633 (2025).https:// doi.org/10.1109/ACCESS.2025.35900731
Karim, M., Khalid, S., Lee, S., Almutairi, S.S., Namoun, A., Abohashrh, M.: Next generation human action recognition: A comprehensive review of state-of-the-art signal processing techniques. IEEE Access13, 135609–135633 (2025).https:// doi.org/10.1109/ACCESS.2025.35900731
-
[26]
In: Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition
Kim,J.,Gwon,M.G.,Park,H.,Kwon,H.,Um,G.M.,Kim,W.:Samplingismatter: Point-guided 3d human mesh reconstruction. In: Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition. pp. 12880–12889 (2023) 4
2023
-
[27]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Kulon, D., Guler, R.A., Kokkinos, I., Bronstein, M.M., Zafeiriou, S.: Weakly- supervised mesh-convolutional hand reconstruction in the wild. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 4990–5000 (2020) 4
2020
-
[28]
arXiv preprint arXiv:2405.07167 (2024) 2, 4
Li, H., Chen, P.P., Zhou, Y.: 3d hand mesh recovery from monocular rgb in camera space. arXiv preprint arXiv:2405.07167 (2024) 2, 4
arXiv 2024
-
[29]
2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp
Li, K., Yang, L., Zhan, X., Lv, J., Xu, W., Li, J., Lu, C.: Artiboost: Boosting artic- ulated 3d hand-object pose estimation via online exploration and synthesis. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp. 2740–2750 (2021) 12
2022
-
[30]
IEEE Transactions on Image Processing33, 3964–3976 (2024) 5
Li, Z., Wang, X., Liu, X., Jiang, J.: Binsformer: Revisiting adaptive bins for monoc- ular depth estimation. IEEE Transactions on Image Processing33, 3964–3976 (2024) 5
2024
-
[31]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Lin, K., Wang, L., Liu, Z.: End-to-end human pose and mesh reconstruction with transformers. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 1954–1963 (2021) 4, 12
1954
-
[32]
In: Proceedings of the IEEE/CVF international conference on computer vision
Lin, K., Wang, L., Liu, Z.: Mesh graphormer. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 12939–12948 (2021) 4
2021
-
[33]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Liu, S., Jiang, H., Xu, J., Liu, S., Wang, X.: Semi-supervised 3d hand-object poses estimation with interactions in time. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 14687–14697 (2021) 3
2021
-
[34]
ArXivabs/2303.05499(2023) 8, 10
Liu, S., Zeng, Z., Ren, T., Li, F., Zhang, H., Yang, J., yue Li, C., Yang, J., Su, H., Zhu, J.J., Zhang, L.: Grounding dino: Marrying dino with grounded pre-training for open-set object detection. ArXivabs/2303.05499(2023) 8, 10
Pith/arXiv arXiv 2023
-
[35]
IEEE Transactions on Multimedia26, 6822–6833 (2024) 12 ScaleHP 19
Lu, H., Gou, S., Li, R.: Spmhand: Segmentation-guided progressive multi-path 3d hand pose and shape estimation. IEEE Transactions on Multimedia26, 6822–6833 (2024) 12 ScaleHP 19
2024
-
[36]
Heredity 89, 403–403 (2002) 2, 6
Manning, J.T.: Digit ratio: A pointer to fertility, behavior, and health. Heredity 89, 403–403 (2002) 2, 6
2002
-
[37]
In: European Con- ference on Computer Vision
Moon, G., Lee, K.M.: I2l-meshnet: Image-to-lixel prediction network for accurate 3d human pose and mesh estimation from a single rgb image. In: European Con- ference on Computer Vision. pp. 752–768. Springer (2020) 2, 3, 4, 12
2020
-
[38]
6m: A dataset and baseline for 3d interacting hand pose estimation from a single rgb image
Moon, G., Yu, S.I., Wen, H., Shiratori, T., Lee, K.M.: Interhand2. 6m: A dataset and baseline for 3d interacting hand pose estimation from a single rgb image. In: European Conference on Computer Vision. pp. 548–564. Springer (2020) 3
2020
-
[39]
Nostadt, N., Abbink, D.A., Christ, O., Beckerle, P.: Embodiment, presence, and their intersections: Teleoperation and beyond. ACM Trans. Hum. Robot Interact. 9(4), 28:1–28:19 (2020).https://doi.org/10.1145/33892101
-
[40]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Park, J., Oh, Y., Moon, G., Choi, H., Lee, K.M.: Handoccnet: Occlusion-robust 3d hand mesh estimation network. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 1496–1505 (2022) 4, 12
2022
-
[41]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Pavlakos, G., Shan, D., Radosavovic, I., Kanazawa, A., Fouhey, D., Malik, J.: Reconstructing hands in 3d with transformers. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 9826–9836 (2024) 4, 22, 23
2024
-
[42]
2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp
Pavlakos, G., Shan, D., Radosavovic, I., Kanazawa, A., Fouhey, D.F., Malik, J.: Reconstructing hands in 3d with transformers. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp. 9826–9836 (2023) 10
2024
-
[43]
2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp
Potamias, R.A., Zhang, J., Deng, J., Zafeiriou, S.: Wilor: End-to-end 3d hand local- ization and reconstruction in-the-wild. 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp. 12242–12254 (2024) 6
2025
-
[44]
Legal medicine10 4, 185–9 (2008) 2, 6
Rastogi, P., Nagesh, K.R., Yoganarasimha, K.: Estimation of stature from hand dimensions of north and south indians. Legal medicine10 4, 185–9 (2008) 2, 6
2008
-
[45]
Ren, K., Hu, L., Zhang, Z., Ye, Y., Xia, S.: Learning transformation-isomorphic latent space for accurate hand pose estimation (2025) 12
2025
-
[46]
ACM Transactions on Graphics (TOG)36, 1 – 17 (2017) 22
Romero, J., Tzionas, D., Black, M.J.: Embodied hands. ACM Transactions on Graphics (TOG)36, 1 – 17 (2017) 22
2017
-
[47]
ACM Transactions on Graphics (TOG)36(6), 1–17 (2017) 3
Romero, J., Tzionas, D., Black, M.J.: Embodied hands: modeling and capturing hands and bodies together. ACM Transactions on Graphics (TOG)36(6), 1–17 (2017) 3
2017
-
[48]
Saleem, M.U., Pinyoanuntapong, E., Patel, M.J., Xue, H., Helmy, A., Das, S., Wang, P.: Maskhand: Generative masked modeling for robust hand mesh recon- struction in the wild (2024) 12
2024
-
[49]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Shi, D., Wei, X., Li, L., Ren, Y., Tan, W.: End-to-end multi-person pose estima- tion with transformers. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 11069–11078 (2022) 4
2022
-
[50]
In: European Conference on Computer Vision
Spurr, A., Iqbal, U., Molchanov, P., Hilliges, O., Kautz, J.: Weakly supervised 3d hand pose estimation via biomechanical constraints. In: European Conference on Computer Vision. Springer (2020) 4
2020
-
[51]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Sun, Q., Wang, Y., Zeng, A., Yin, W., Wei, C., Wang, W., Mei, H., Leung, C.S., Liu, Z., Yang, L., et al.: Aios: All-in-one-stage expressive human pose and shape estimation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 1834–1843 (2024) 4
2024
-
[52]
Frontiers Robotics AI7, 14 (2020).https://doi.org/10
Toet,A.,Kuling,I.A.,Krom,B.N.,vanErp,J.B.F.:Towardenhancedteleoperation through embodiment. Frontiers Robotics AI7, 14 (2020).https://doi.org/10. 3389/FROBT.2020.000141 20 R. Jing et al
arXiv 2020
-
[53]
In: European Conference on Computer Vision
Valassakis, E., Garcia-Hernando, G.: Handdgp: Camera-space hand mesh predic- tion with differentiable global positioning. In: European Conference on Computer Vision. pp. 479–496. Springer (2024) 4, 12
2024
-
[54]
The Journal of Medical Research (2015) 2, 6
Varu, P., Manvar, P.J., Mangal, H.M., Kyada, H.C., Vadgama, D.K., Bhuva, S.D.: Determination of stature from hand dimensions. The Journal of Medical Research (2015) 2, 6
2015
-
[55]
arXiv preprint arXiv:2511.13282 (2025) 2, 4
Wang, K., Zheng, K., Shi, Y., Guo, C., Wu, J.: Towards metric-aware multi-person mesh recovery by jointly optimizing human crowd in camera space. arXiv preprint arXiv:2511.13282 (2025) 2, 4
arXiv 2025
-
[56]
arXiv preprint arXiv:2507.02546 (2025) 5
Wang, R., Xu, S., Dong, Y., Deng, Y., Xiang, J., Lv, Z., Sun, G., Tong, X., Yang, J.: Moge-2: Accurate monocular geometry with metric scale and sharp details. arXiv preprint arXiv:2507.02546 (2025) 5
Pith/arXiv arXiv 2025
-
[57]
2023 IEEE International Conference on Multimedia and Expo (ICME) pp
Wang, S., Wang, S., Yang, D., Li, M., Qian, Z., Su, L., Zhang, L.: Handgcat: Occlusion-robust 3d hand mesh reconstruction from monocular images. 2023 IEEE International Conference on Multimedia and Expo (ICME) pp. 2495–2500 (2023) 12
2023
-
[58]
IEEE Transactions on Circuits and Systems for Video Technology29, 3258–3268 (2019) 10
Wang, Y., Peng, C., Liu, Y.: Mask-pose cascaded cnn for 2d hand pose estimation from single color image. IEEE Transactions on Circuits and Systems for Video Technology29, 3258–3268 (2019) 10
2019
-
[59]
2023 IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR) pp
Xu, H., Wang, T., Tang, X., Fu, C.W.: H2onet: Hand-occlusion-and-orientation- aware network for real-time 3d hand mesh reconstruction. 2023 IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR) pp. 17048–17058 (2023) 12
2023
-
[60]
arXiv preprint arXiv:2302.01593 (2023) 4
Yang, J., Zeng, A., Liu, S., Li, F., Zhang, R., Zhang, L.: Explicit box detection unifies end-to-end multi-person pose estimation. arXiv preprint arXiv:2302.01593 (2023) 4
arXiv 2023
-
[61]
2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) pp
Yang, L., Li, B., Yang, G., Chang, Y., Liu, Z., Jiang, B., Xiao, J.: Deep neural network based visual inspection with 3d metric measurement of concrete defects using wall-climbing robot. 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) pp. 2849–2854 (2019) 2
2019
-
[62]
In: Proceedings of the IEEE/CVF international conference on computer vision
Yang, L., Chen, S., Yao, A.: Semihand: Semi-supervised hand pose estimation with consistency. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 11364–11373 (2021)
2021
-
[63]
arXiv preprint arXiv:2008.05079 (2020) 3
Yang, L., Li, J., Xu, W., Diao, Y., Lu, C.: Bihand: Recovering hand mesh with multi-stage bisected hourglass networks. arXiv preprint arXiv:2008.05079 (2020) 3
arXiv 2008
-
[64]
In: Proceedings of the IEEE/CVF international conference on computer vision
Yang, L., Zhan, X., Li, K., Xu, W., Li, J., Lu, C.: Cpf: Learning a contact poten- tial field to model the hand-object interaction. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 11097–11106 (2021) 3
2021
-
[65]
In: Proceed- ings of the IEEE/CVF international conference on computer vision
Yin, W., Zhang, C., Chen, H., Cai, Z., Yu, G., Wang, K., Chen, X., Shen, C.: Metric3d: Towards zero-shot metric 3d prediction from a single image. In: Proceed- ings of the IEEE/CVF international conference on computer vision. pp. 9043–9053 (2023) 5
2023
-
[66]
In: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition
Yoshiyasu, Y.: Deformable mesh transformer for 3d human mesh recovery. In: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 17006–17015 (2023) 4, 12
2023
-
[67]
Zhang, B., Wang, Y., Deng, X., Zhang, Y., Tan, P., Ma, C., Wang, H.: Interacting two-hand3dposeandshapereconstructionfromsinglecolorimage.In:Proceedings of the IEEE/CVF international conference on computer vision. pp. 11354–11363 (2021) 3 ScaleHP 21
2021
-
[68]
In: The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023
Zhang, H., Li, F., Liu, S., Zhang, L., Su, H., Zhu, J., Ni, L.M., Shum, H.: DINO: DETR with improved denoising anchor boxes for end-to-end object detection. In: The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net (2023) 4
2023
-
[69]
arXiv e-prints pp
Zhang, H., Song, C., Zhang, H., Yu, T.: Metrichmr: Metric human mesh recovery from monocular images. arXiv e-prints pp. arXiv–2506 (2025) 5
2025
-
[70]
In: Proceedings of the IEEE/CVF international conference on computer vision
Zhang, X., Huang, H., Tan, J., Xu, H., Yang, C., Peng, G., Wang, L., Liu, J.: Hand image understanding via deep multi-task learning. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 11281–11292 (2021) 3
2021
-
[71]
In: Proceedings of the IEEE/CVF international conference on computer vision
Zhang, X., Li, Q., Mo, H., Zhang, W., Zheng, W.: End-to-end hand mesh recov- ery from a monocular rgb image. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 2354–2364 (2019) 3
2019
-
[72]
In: Proceedings of the IEEE/CVF international conference on computer vision
Zhao, Z., Zhao, X., Wang, Y.: Travelnet: Self-supervised physically plausible hand motion learning from monocular color images. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 11666–11676 (2021) 3
2021
-
[73]
IEEE Robotics and Automation Letters5, 1540–1547 (2020) 2
Zhong, F., Wang, Z., Chen, W., He, K., Wang, Y., hui Liu, Y.: Hand-eye calibration of surgical instrument for robotic surgery using interactive manipulation. IEEE Robotics and Automation Letters5, 1540–1547 (2020) 2
2020
-
[74]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zhou, Y., Habermann, M., Xu, W., Habibie, I., Theobalt, C., Xu, F.: Monocular real-time hand shape and motion capture using multi-modal data. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5346–5355 (2020)
2020
-
[75]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zhou, Z., Zhou, S., Lv, Z., Zou, M., Tang, Y., Liang, J.: A simple baseline for efficient hand mesh reconstruction. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 1367–1376 (2024) 12
2024
-
[76]
In: 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021
Zhu, X., Su, W., Lu, L., Li, B., Wang, X., Dai, J.: Deformable DETR: deformable transformers for end-to-end object detection. In: 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net (2021),https://openreview.net/forum?id=gZ9hCDWe6ke8
2021
-
[77]
In: Proceedings of the IEEE/CVF international conference on computer vision
Zimmermann, C., Ceylan, D., Yang, J., Russell, B., Argus, M., Brox, T.: Freihand: A dataset for markerless capture of hand pose and shape from single rgb images. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 813–822 (2019) 10, 12, 22 22 R. Jing et al. Supplementary Material S1 Evaluation Dataset Description We evaluate t...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.