Self-Trained Verification for Training- and Test-Time Self-Improvement
Pith reviewed 2026-06-29 08:22 UTC · model grok-4.3
The pith
Training a verifier to imitate its reference-aware self improves verification-refinement loops on hard problems and raises standalone generator accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
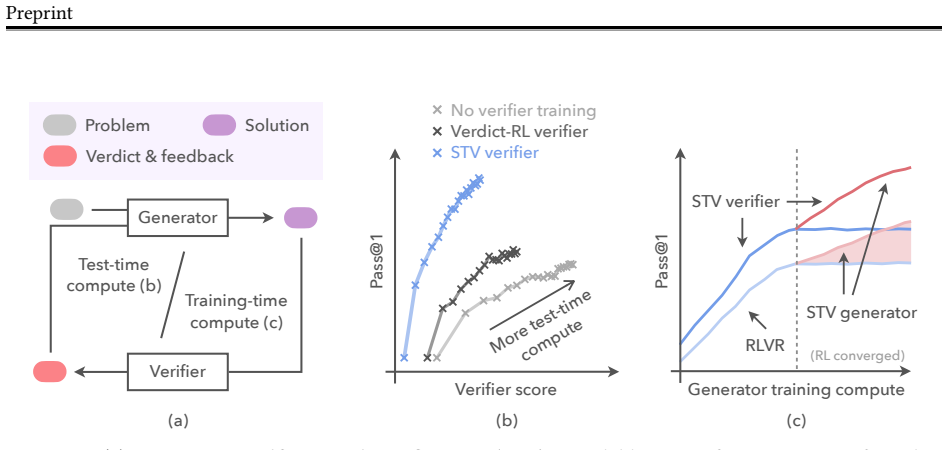
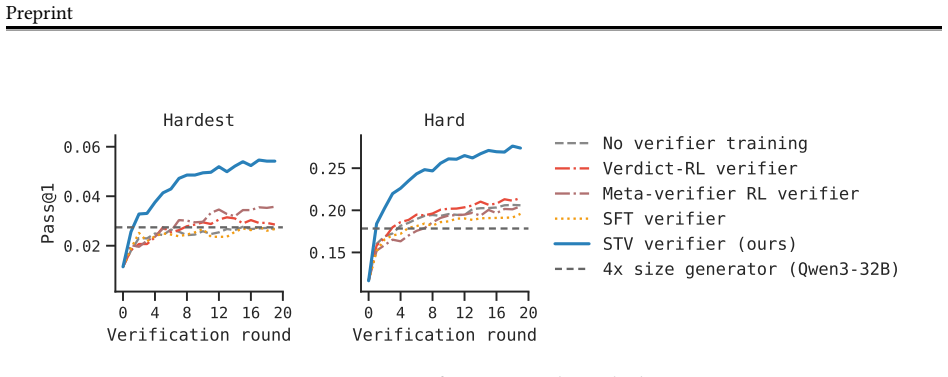
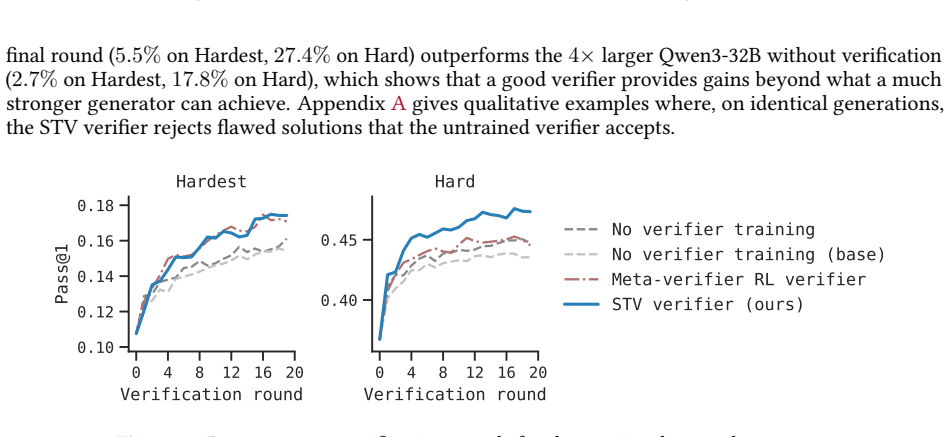
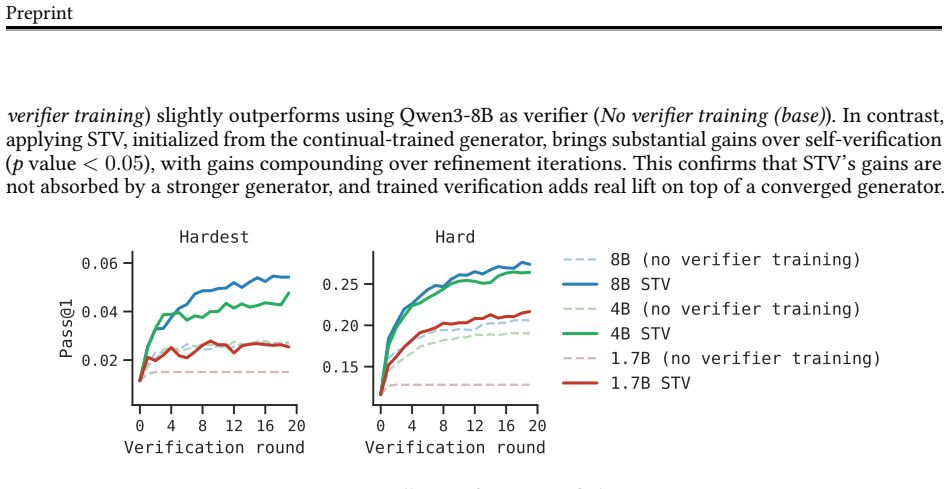
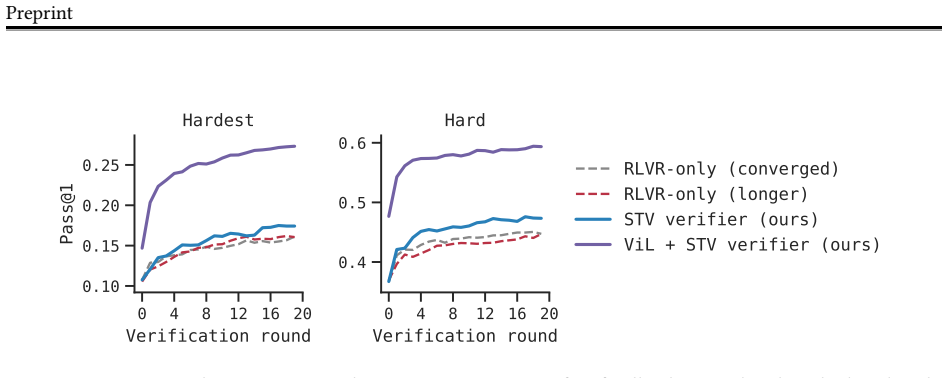
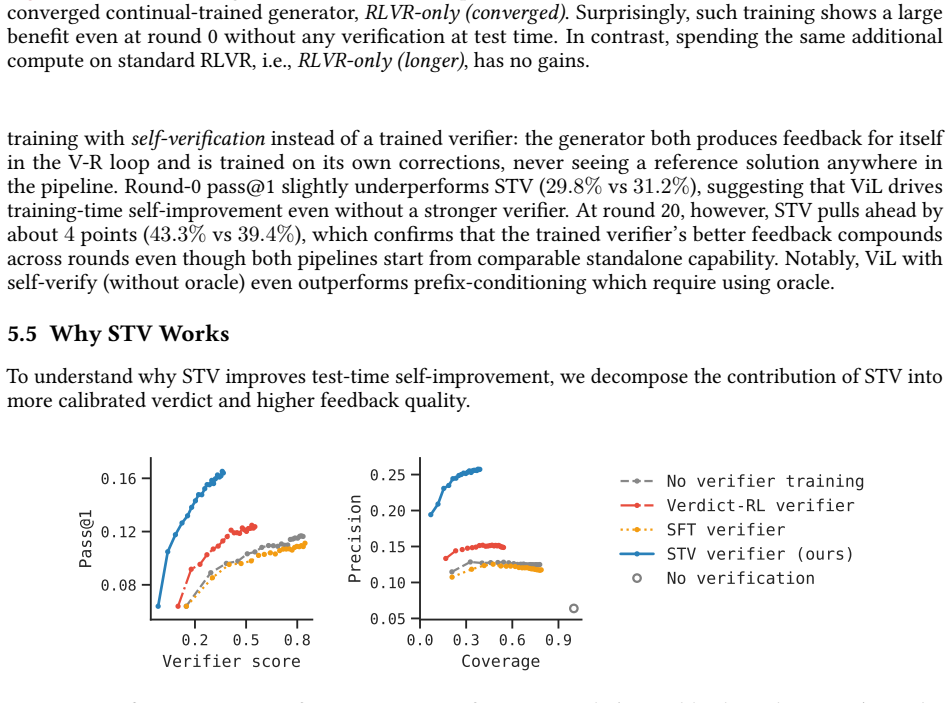
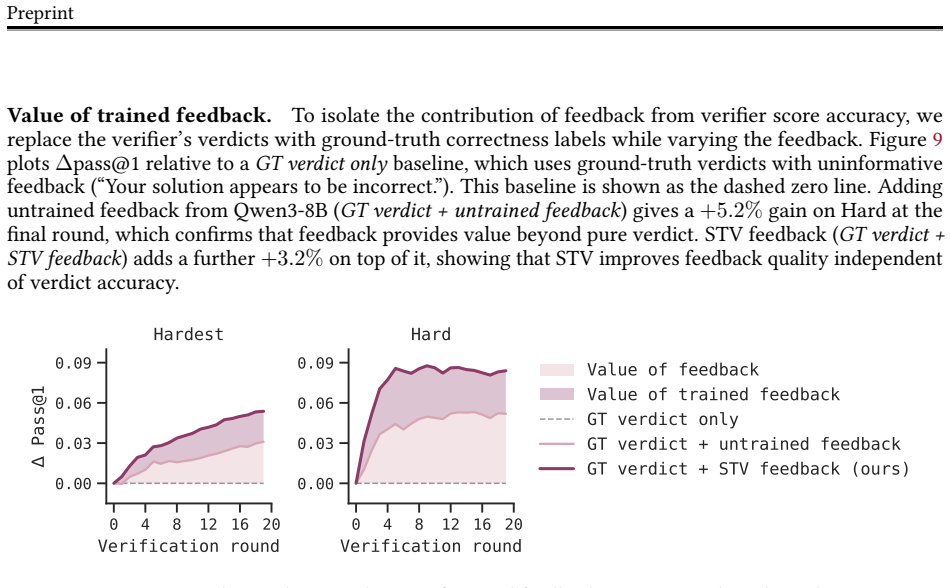
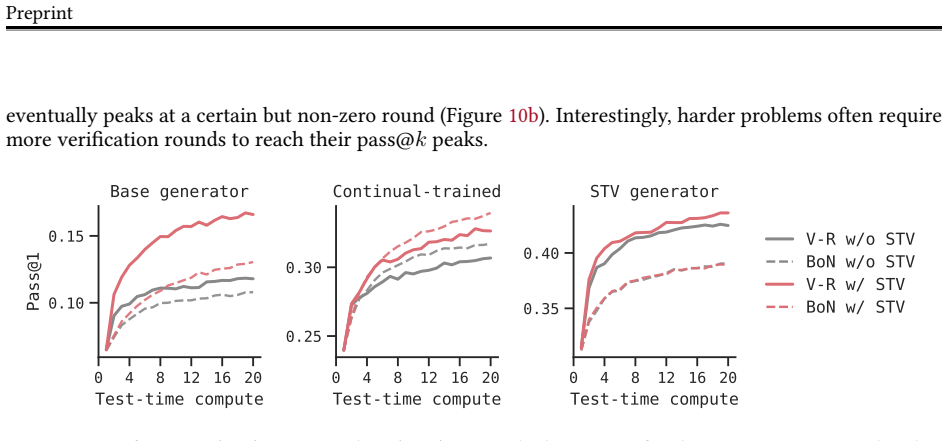
Self-trained verification converts the performance gap between reference-assisted and reference-free verification into a supervision target, so the verifier learns to imitate its stronger reference-informed behavior. When inserted into verification-refinement loops, the trained verifier raises accuracy on hard math problems by roughly a factor of two and lifts scientific reasoning accuracy from 1.5 percent to 21 percent. When the same verifier is used inside verifier-in-the-loop training, pass@1 improves an additional 33 percent and the generator's standalone accuracy climbs 30 percent past the point where standard reinforcement learning had plateaued.
What carries the argument
Self-trained verification (STV), the procedure that uses reference solutions only at training time to create imitation targets for the verifier so it can detect self-generated errors without references at test time.
If this is right
- Verification-refinement loops using the self-trained verifier roughly double accuracy on hard math tasks.
- The same loops raise scientific reasoning accuracy from 1.5 percent to 21 percent.
- Verifier-in-the-loop training starting from an RL-converged generator adds a further 33 percent gain in pass@1.
- After verifier-in-the-loop training the generator's standalone pass@1 improves 30 percent relative to the prior RL plateau even when no verifier is present at test time.
Where Pith is reading between the lines
- The same asymmetry-based training signal could be tested on other reasoning domains where reference solutions are available only during development.
- The observed rise in standalone generator performance suggests that verification training may refine internal reasoning steps that persist after the verifier is removed.
- Repeated cycles of self-trained verification followed by verifier-in-the-loop training could be examined to check whether gains compound across multiple rounds.
Load-bearing premise
The asymmetry between a model's ability to verify with versus without a reference solution provides a reliable and generalizable supervision signal that transfers to test-time verification without the reference.
What would settle it
Training an STV verifier on a fresh collection of hard math problems and measuring that verification-refinement loop accuracy stays no higher than the accuracy obtained from standard supervised fine-tuning or reinforcement learning on verifier scores would falsify the central claim.
Figures


read the original abstract
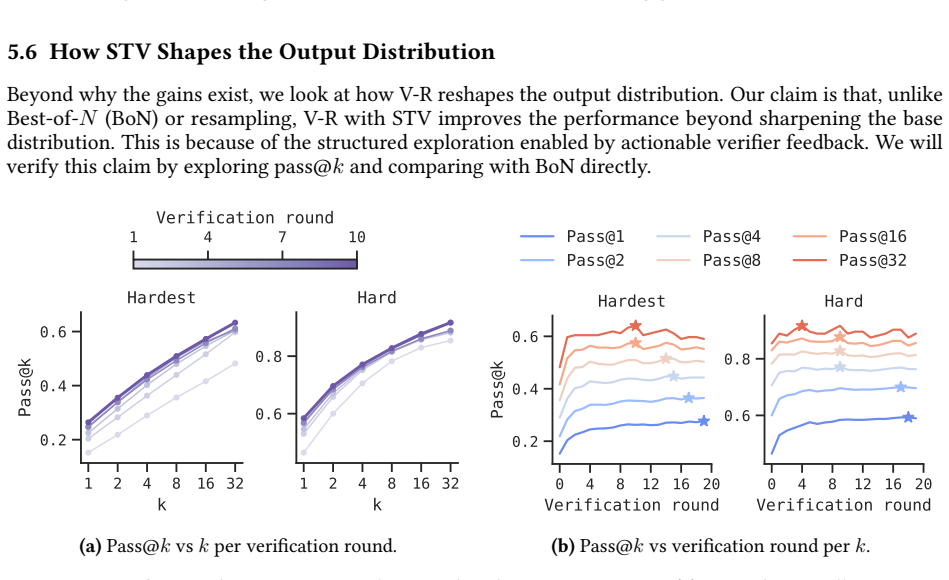
Self-improvement at scale has been a longstanding goal for reasoning models, and there are two natural places to do it: at test time, through verification-refinement (V-R) loops; and at training time, through self-training methods. Both are gated by the same bottleneck: the verifier. V-R loops stall when verifier scores inflate while accuracy stagnates, and when feedback is too generic to act on; self-training fails similarly when bad self-generated data are added to training. Better verification would unlock both, but the capability we want to train, i.e., catching self-generated errors, lacks training signal. To address this challenge, we propose self-trained verification (STV). Our key observation is that, while a model cannot catch these errors alone, it can when shown the reference solution. We turn this asymmetry into a supervision target and train the verifier to imitate a more informed version of itself. At test time, STV substantially improves V-R loops on hard problems, while alternatives (e.g., SFT, RL on verifier scores, and even meta-verifiers) do not. STV roughly doubles accuracy on hard math and lifts it 14x on scientific reasoning tasks (1.5% to 21%). At training time, we additionally train the generator using RL with STV verifier's feedback inside the V-R loop - a procedure we call verifier-in-the-loop training (ViL). Starting from an RL-converged generator, ViL yields a further 33% gain in pass@1. More notably, the generator's standalone pass@1, with no verifier at test time, climbs 30% relative past where standard RL had converged. Hence, the next frontier in reasoning on hard problems may lie in how we train for and with verification. Website: https://ar-forum.github.io/stv-webpage
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Self-Trained Verification (STV) to address the verifier bottleneck in self-improvement for reasoning models. By training the verifier to imitate its reference-informed version, STV enables improved verification-refinement (V-R) loops at test time and verifier-in-the-loop (ViL) training at training time. The paper claims STV doubles accuracy on hard math problems and increases it 14-fold on scientific reasoning tasks, with additional gains in generator performance even without the verifier at test time.
Significance. If the results hold and the trained verifier genuinely captures reasoning verification rather than answer matching, the approach could significantly advance methods for scaling self-improvement in large language models on hard reasoning tasks. The finding that the generator improves standalone after ViL is particularly interesting as it suggests indirect benefits to the base model. The work also ships concrete experimental comparisons to SFT, RL, and meta-verifier baselines.
major comments (2)
- [§3.2] §3.2 (Supervision target construction): The description of how the reference solution is used to generate the imitation target does not specify whether supervision is derived from step-by-step reasoning audits or from final-answer comparison alone; without this, it is impossible to rule out that STV trains answer-matching rather than verification, which directly threatens transfer to reference-free test-time use and the claimed V-R gains.
- [§4] §4 (Experiments): Reported accuracy lifts (2× on hard math, 14× on scientific reasoning) and ViL gains are presented without details on number of independent runs, statistical significance, controls for prompt sensitivity or data leakage, or ablations isolating reference use from other training choices; this makes it difficult to attribute improvements to STV rather than implementation artifacts.
minor comments (1)
- [Figure 3] Figure 3 and Table 2: Axis labels and legend entries use inconsistent abbreviations (e.g., “STV-V” vs. “STV verifier”) that should be unified for readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript to improve clarity and experimental reporting.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Supervision target construction): The description of how the reference solution is used to generate the imitation target does not specify whether supervision is derived from step-by-step reasoning audits or from final-answer comparison alone; without this, it is impossible to rule out that STV trains answer-matching rather than verification, which directly threatens transfer to reference-free test-time use and the claimed V-R gains.
Authors: We agree the current description in §3.2 is insufficiently precise on this point. The target is constructed by using the reference solution to produce an informed verification signal that identifies discrepancies in the reasoning chain (when the reference permits step-level auditing) rather than final-answer equality alone. We will revise §3.2 with an explicit algorithmic description and example showing how the imitation target incorporates step-wise error detection where the reference enables it. This revision will directly address the concern about answer-matching versus verification. revision: yes
-
Referee: [§4] §4 (Experiments): Reported accuracy lifts (2× on hard math, 14× on scientific reasoning) and ViL gains are presented without details on number of independent runs, statistical significance, controls for prompt sensitivity or data leakage, or ablations isolating reference use from other training choices; this makes it difficult to attribute improvements to STV rather than implementation artifacts.
Authors: We acknowledge that the experimental section would benefit from additional rigor. In the revision we will report results across multiple independent runs with means and standard deviations, include statistical significance tests, add controls for prompt sensitivity and checks against data leakage, and provide ablations that isolate the contribution of reference-informed target construction from other training decisions. These changes will strengthen the evidence that gains are attributable to STV. revision: yes
Circularity Check
No significant circularity; derivation uses independent external reference signal
full rationale
The paper trains the verifier by imitating its reference-informed counterpart using reference solutions as an external supervision target (abstract). This signal is independent of the test-time reference-free application. No equations, fitted parameters, or self-citations are presented that reduce any claimed prediction, uniqueness result, or central mechanism to the inputs by construction. The asymmetry observation is taken as given rather than derived from the method itself, and downstream claims (V-R gains, ViL) rest on empirical transfer rather than definitional equivalence. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reference solutions provide a reliable supervision signal for training verifiers that generalizes to reference-free settings.
Reference graph
Works this paper leans on
-
[1]
URLhttps://api.semanticscholar.org/CorpusID:285787286. DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Jun-Mei Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiaoling Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bing-Li Wang, Bochao Wu, Bei Feng, Chengda Lu, Cheng...
-
[2]
Distilling the Knowledge in a Neural Network
URLhttps://api.semanticscholar.org/CorpusID:259164722. Geoffrey E. Hinton, Oriol Vinyals, and Jeffrey Dean. Distilling the knowledge in a neural network.ArXiv, abs/1503.02531, 2015. URLhttps://api.semanticscholar.org/CorpusID:7200347. Arian Hosseini, Xingdi Yuan, Nikolay Malkin, Aaron C. Courville, Alessandro Sordoni, and Rishabh Agarwal. V-star: Training...
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[3]
Prover-verifier games improve legibility of LLM outputs.arXiv preprint arXiv:2407.13692, 2024
URLhttps://api.semanticscholar.org/CorpusID:279318695. Ryo Kamoi, Yusen Zhang, Nan Zhang, Jiawei Han, and Rui Zhang. When can llms actually correct their own mistakes? a critical survey of self-correction of llms.Transactions of the Association for Computational Linguistics, 12:1417–1440, 2024. URLhttps://api.semanticscholar.org/CorpusID:270218742. Jan He...
-
[4]
Deepseekmath-v2: Towards self-verifiable mathematical reasoning.arXiv preprint arXiv:2511.22570,
URLhttps://api.semanticscholar.org/CorpusID:285050190. Zhihong Shao, Yu-Wei Luo, Chengda Lu, Zehui Ren, Jiewen Hu, Tian Ye, Zhibin Gou, Shirong Ma, and Xi- aokang Zhang. Deepseekmath-v2: Towards self-verifiable mathematical reasoning.ArXiv, abs/2511.22570,
-
[5]
Self-Distillation Enables Continual Learning
URLhttps://api.semanticscholar.org/CorpusID:283438764. Idan Shenfeld, Mehul Damani, Jonas Hübotter, and Pulkit Agrawal. Self-distillation enables continual learn- ing.ArXiv, abs/2601.19897, 2026. URLhttps://api.semanticscholar.org/CorpusID:285071839. Noah Shinn, Federico Cassano, Beck Labash, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion:...
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.