BC Protocol: Structured Dual-Expert Dialogue for Eliciting High-Quality Chain-of-Thought Post-Training Data
Pith reviewed 2026-06-29 21:38 UTC · model grok-4.3
The pith
Structured dialogue between a domain expert and knowledge engineer produces chain-of-thought data with far more natural reasoning than experts writing alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
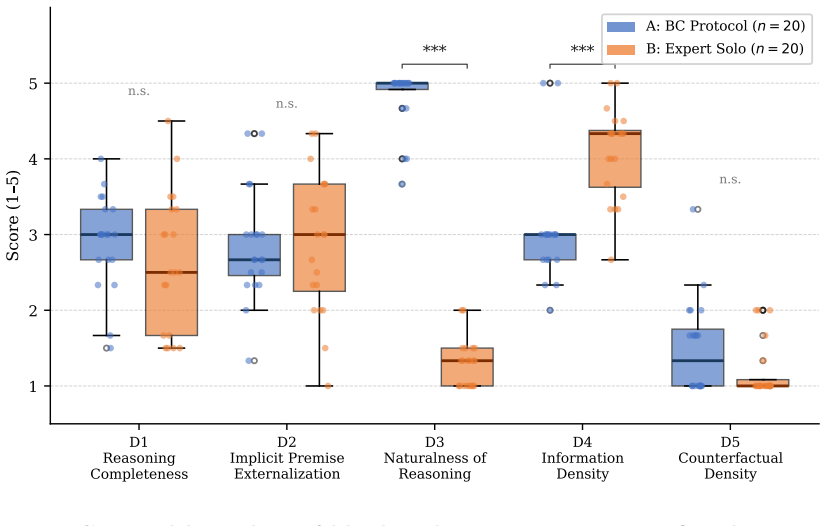
The BC Protocol elicits natural language reasoning chains by systematically externalizing a domain expert's implicit judgments through interaction with a knowledge engineer, achieving an overwhelming advantage in naturalness of reasoning process with Group A mean 4.80 versus Group B mean 1.30 (p=2.4×10^{-8}, Cliff's δ=1.0) in blind evaluations across 600 ratings from GPT-4o, Claude Opus 4.5, and Gemini 2.5 Pro.
What carries the argument
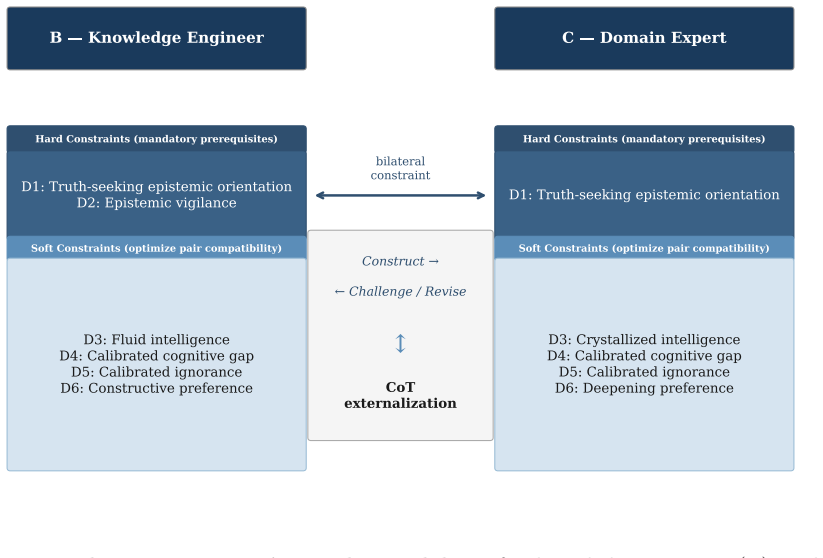
The BC Protocol structured dual-expert dialogue, which pairs a domain expert (crystallized intelligence) with a knowledge engineer (fluid intelligence) to externalize implicit judgments as explicit reasoning chains.
If this is right
- The method produces CoT data rated substantially higher in naturalness of reasoning process than independent expert writing.
- Selection of participants according to the Participant Aptitude Model improves elicitation quality more than prescriptive process adjustments.
- Calibrated Ignorance enables the knowledge engineer to surface steps the domain expert would otherwise omit.
- The approach directly addresses structural limits of crowdsourcing, solo writing, and RLHF for reasoning-chain production.
Where Pith is reading between the lines
- The protocol could extend to technical domains such as mathematics or programming where experts commonly skip intermediate steps.
- If the quality gains hold, the method offers a route to reasoning data that complements or partially substitutes for preference-based RLHF.
- The Selection-over-Prescription principle may apply to other implicit-knowledge tasks outside LLM post-training.
Load-bearing premise
Ratings from the three LLM judge models reliably and unbiasedly measure naturalness of reasoning in a manner that aligns with human judgment of CoT quality.
What would settle it
A replication of the blind evaluation using human raters on the same Group A and Group B CoT samples that finds no significant difference or reverses the reported naturalness advantage.
Figures
read the original abstract
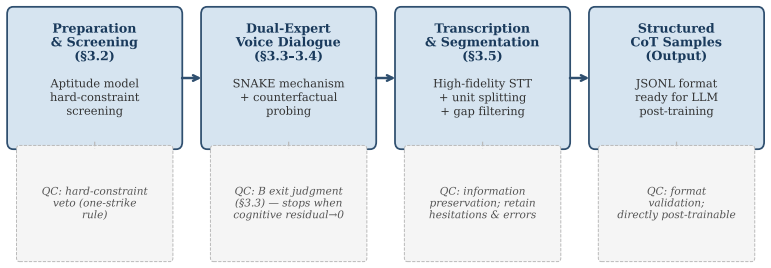
High-quality expert chain-of-thought (CoT) data is one of the core bottlenecks in large language model (LLM) post-training. Existing data production methods each have structural limitations: crowdsourced annotation lacks deep reasoning paths; expert solo writing is constrained by the "expert blind spot" -- experts structurally skip reasoning steps they consider obvious; RLHF only produces preference signals rather than reasoning chains. This paper proposes the BC Protocol -- a structured dual-expert elicitation method for LLM post-training data production. The method carefully pairs a domain expert (crystallized intelligence) with a knowledge engineer (fluid intelligence), systematically externalizing the expert's implicit judgments as natural language reasoning chains. We introduce the Participant Aptitude Model, which defines six participant characteristic dimensions that affect elicitation quality. "Calibrated Ignorance" is an original concept proposed in this paper. We further propose "Selection-over-Prescription" as a methodological principle: for implicit knowledge elicitation tasks, investing quality-control resources in personnel selection yields a higher return than investing the same resources in process design. In a controlled experiment in the narrative fiction domain, we directly compared CoT produced by BC Protocol dual dialogue (Group A, (n=20)) against CoT written independently by the same domain expert (Group B, (n=20)). Three cross-vendor judge models -- GPT-4o, Claude Opus 4.5, and Gemini 2.5 Pro -- conducted blind evaluation across five dimensions (600 ratings total). Results show that the BC Protocol achieves an overwhelming advantage in "naturalness of reasoning process" (Group A mean 4.80 vs. Group B mean 1.30, (p=2.4\times10^{-8}), Cliff's (\delta=1.0)).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the BC Protocol, a structured dual-expert dialogue method pairing a domain expert (crystallized intelligence) with a knowledge engineer (fluid intelligence) to elicit high-quality chain-of-thought (CoT) data for LLM post-training. It introduces the Participant Aptitude Model (six dimensions), the concept of Calibrated Ignorance, and the principle of Selection-over-Prescription. In a controlled experiment in the narrative fiction domain, BC Protocol dual-dialogue CoTs (Group A, n=20) are compared to solo expert writing (Group B, n=20); three LLM judges (GPT-4o, Claude Opus 4.5, Gemini 2.5 Pro) perform blind 5-dimension ratings (600 total), claiming overwhelming superiority for BC Protocol on naturalness of reasoning process (means 4.80 vs 1.30, p=2.4×10^{-8}, Cliff's δ=1.0).
Significance. If the result holds, the BC Protocol would offer a practical method for externalizing implicit expert reasoning into explicit natural-language chains, addressing documented limitations of crowdsourcing, solo expert writing, and RLHF. The direct head-to-head experimental design and use of multiple cross-vendor LLM judges for blind evaluation are strengths that support falsifiability of the core claim.
major comments (1)
- [controlled experiment (abstract and results section)] The central empirical claim (naturalness means 4.80 vs 1.30, p=2.4×10^{-8}, δ=1.0) rests solely on aggregate scores from three LLM judges performing blind ratings. No human raters, no reported correlation between LLM and human judgments on the naturalness dimension, and no inter-judge agreement statistics with humans are mentioned. Because the BC Protocol is explicitly designed to produce more explicit, step-by-step reasoning, the judges' training distributions may systematically favor Group A outputs irrespective of actual reasoning quality or human preference.
minor comments (1)
- [Experiment description] The abstract and experiment description provide no details on participant selection criteria, exact dialogue structure, rating rubrics, or inter-judge agreement among the three LLM models, limiting assessment of the controlled comparison despite the small per-group n=20.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The major comment regarding reliance on LLM judges for the controlled experiment is addressed below. We take the concern seriously and provide our response.
read point-by-point responses
-
Referee: The central empirical claim (naturalness means 4.80 vs 1.30, p=2.4×10^{-8}, δ=1.0) rests solely on aggregate scores from three LLM judges performing blind ratings. No human raters, no reported correlation between LLM and human judgments on the naturalness dimension, and no inter-judge agreement statistics with humans are mentioned. Because the BC Protocol is explicitly designed to produce more explicit, step-by-step reasoning, the judges' training distributions may systematically favor Group A outputs irrespective of actual reasoning quality or human preference.
Authors: We appreciate the referee highlighting this methodological point. Our use of three cross-vendor LLM judges (GPT-4o, Claude Opus 4.5, Gemini 2.5 Pro) in a fully blind protocol was chosen to increase robustness against single-model artifacts, and the effect size (Cliff's δ=1.0) is extreme enough that systematic favoritism toward explicit reasoning alone is unlikely to account for the full separation. However, we agree that the lack of human rater data and reported correlation with human judgments on naturalness is a genuine limitation of the present study. In revision we will add an explicit limitations subsection discussing LLM-judge validity, report inter-judge agreement statistics, and qualify the strength of the empirical claim accordingly while retaining the current results as evidence under the stated evaluation protocol. revision: partial
Circularity Check
No circularity: direct empirical comparison with no derivation chain
full rationale
The paper's central claim rests on a controlled head-to-head experiment (BC Protocol dual dialogue vs. solo expert writing) evaluated by three LLM judges on 40 samples across five dimensions. No equations, fitted parameters, predictions, self-citations, uniqueness theorems, or ansatzes are invoked; the result is presented as raw experimental output (means, p-value, Cliff's delta) rather than any reduction to inputs by construction. Concepts like Participant Aptitude Model and Selection-over-Prescription are introduced but not used in any load-bearing derivation that loops back to themselves.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Domain experts possess implicit reasoning steps that can be systematically externalized through structured dialogue with a knowledge engineer.
invented entities (3)
-
Participant Aptitude Model
no independent evidence
-
Calibrated Ignorance
no independent evidence
-
Selection-over-Prescription
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Training language models to follow instructions with human feedback
Baumeister, R. F., Bratslavsky, E., Muraven, M., & Tice, D. M. (1998). Ego depletion: Is the active self a limited resource?Journal of Personality and Social Psychology,74(5), 1252–1265. Bjork, R. A. (1994). Memory and metamemory considerations in the training of human 41 beings. In J. Metcalfe & A. P. Shimamura (Eds.),Metacognition: Knowing about knowing...
work page internal anchor Pith review Pith/arXiv arXiv 1998
-
[2]
Calibrated Surprise: An Information-Theoretic Account of Creative Quality
(pp. 13484–13508). Waterman, D. A. (1986).A guide to expert systems. Addison-Wesley. Wegner, D. M. (1987). Transactive memory: A contemporary analysis of the group mind. In B. Mullen & G. R. Goethals (Eds.),Theories of group behavior(pp. 185–208). Springer. 43 Wu, T., Ribeiro, M. T., Heer, J., & Weld, D. S. (2021). Polyjuice: Generating counterfactuals fo...
work page internal anchor Pith review Pith/arXiv arXiv 1986
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.