ForecastBench-Sim: A Simulated-World Forecasting Benchmark
Pith reviewed 2026-06-26 21:26 UTC · model grok-4.3
The pith
A simulated strategy game benchmark generates forecasting questions at arbitrary time horizons that resolve immediately for scoring.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
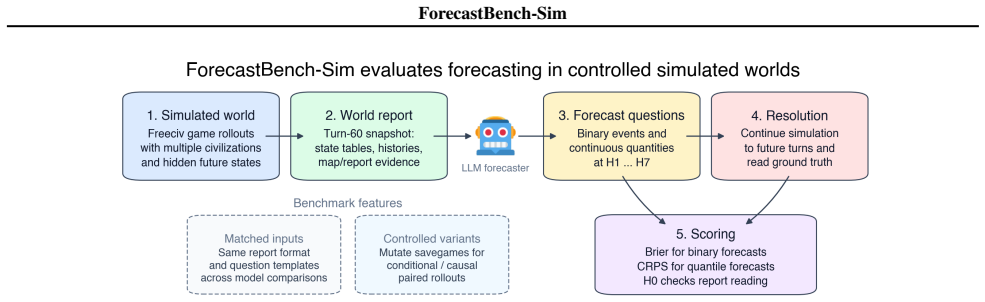
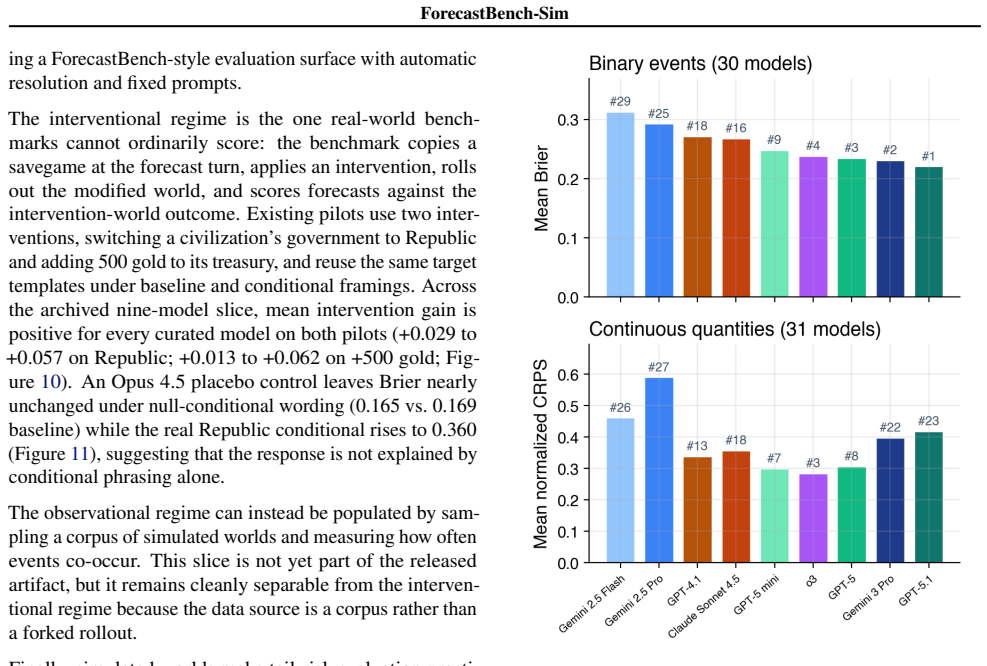
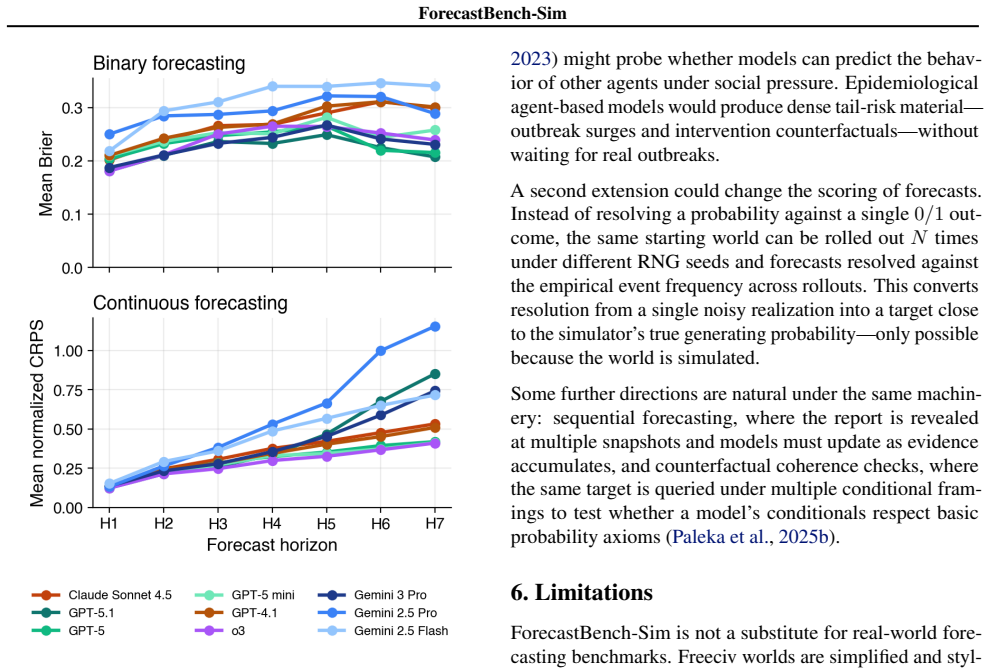
The benchmark is constructed by running rollouts in a simulated turn-based strategy environment. Forecasters receive a fixed structured snapshot of the current state and answer questions about hidden future states. The simulation then continues to reveal actual outcomes, enabling immediate scoring. This design supports generation of question families at arbitrary horizons along with paired intervention worlds and resolved examples of low-probability outcomes.
What carries the argument
Rollouts in a simulated turn-based strategy environment that supply structured world reports as input and continue the simulation to produce ground truth for scoring predictions on future states.
Load-bearing premise
The simulation dynamics and world reports provide a faithful proxy for the challenges of real-world forecasting, including tail events and dynamic state changes.
What would settle it
A finding that model performance rankings on questions from the simulated benchmark show little or no correlation with rankings on established real-world forecasting tasks would indicate the simulation does not serve as an effective proxy.
Figures

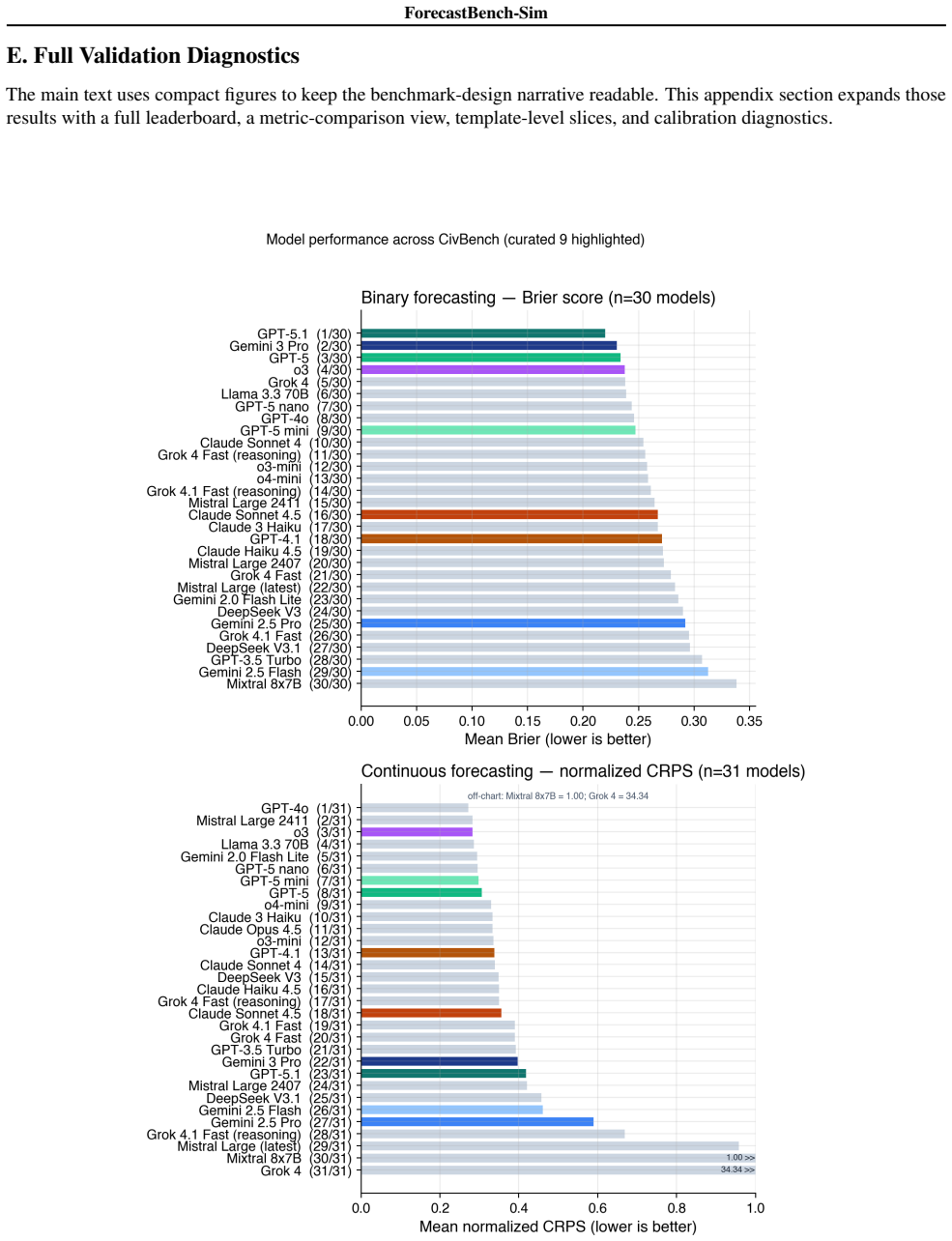
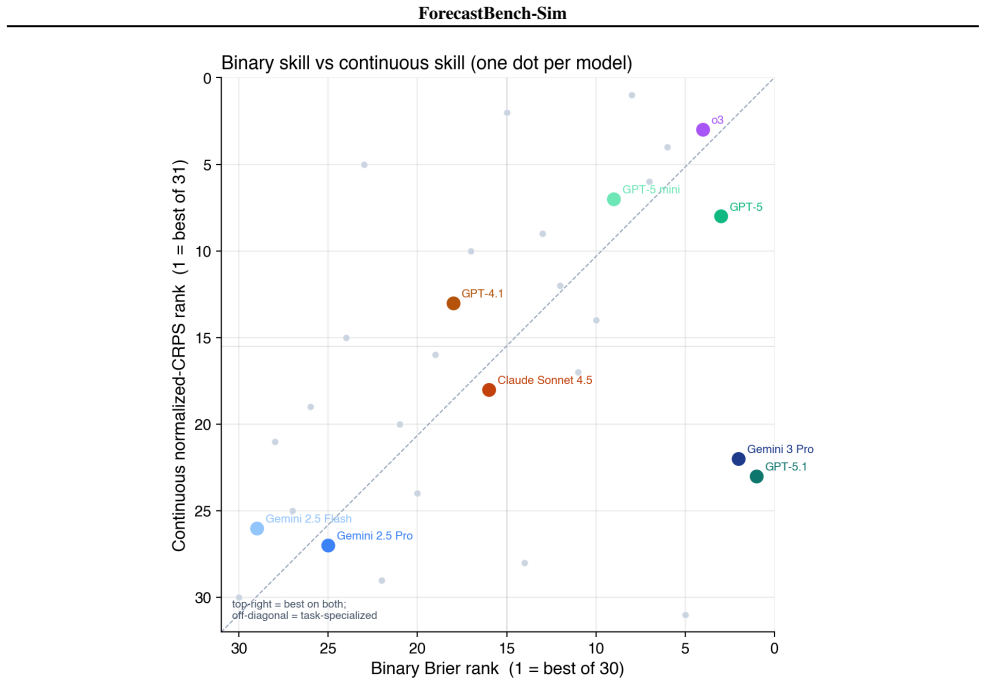
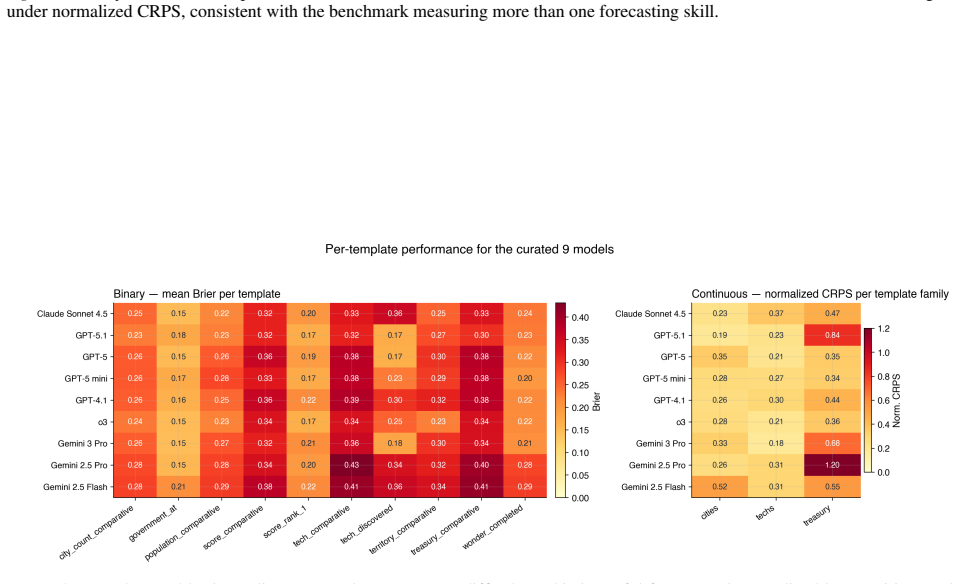
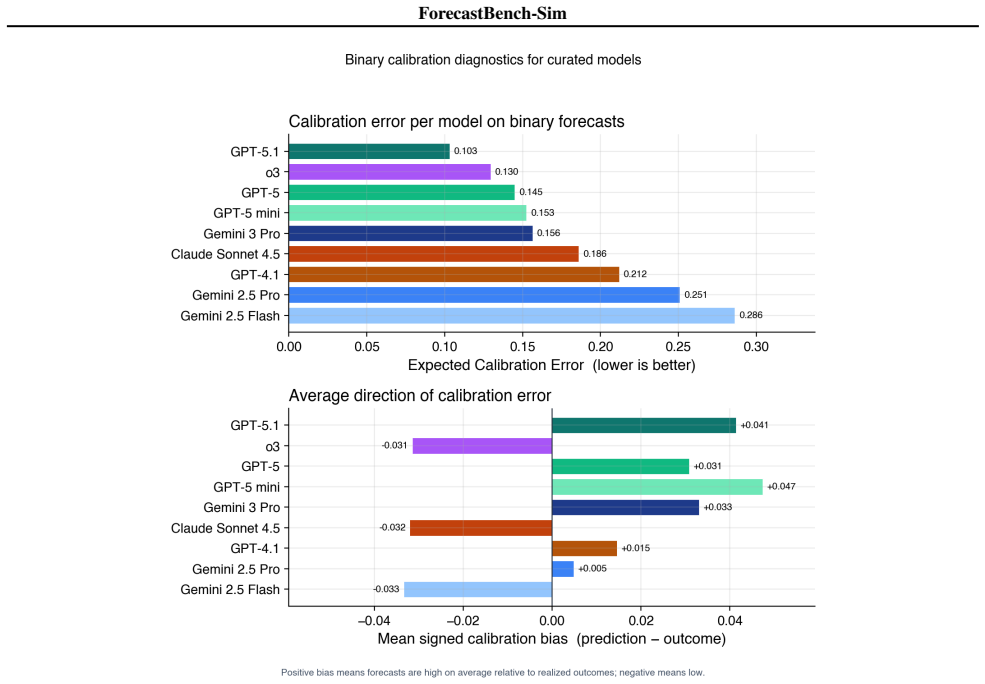
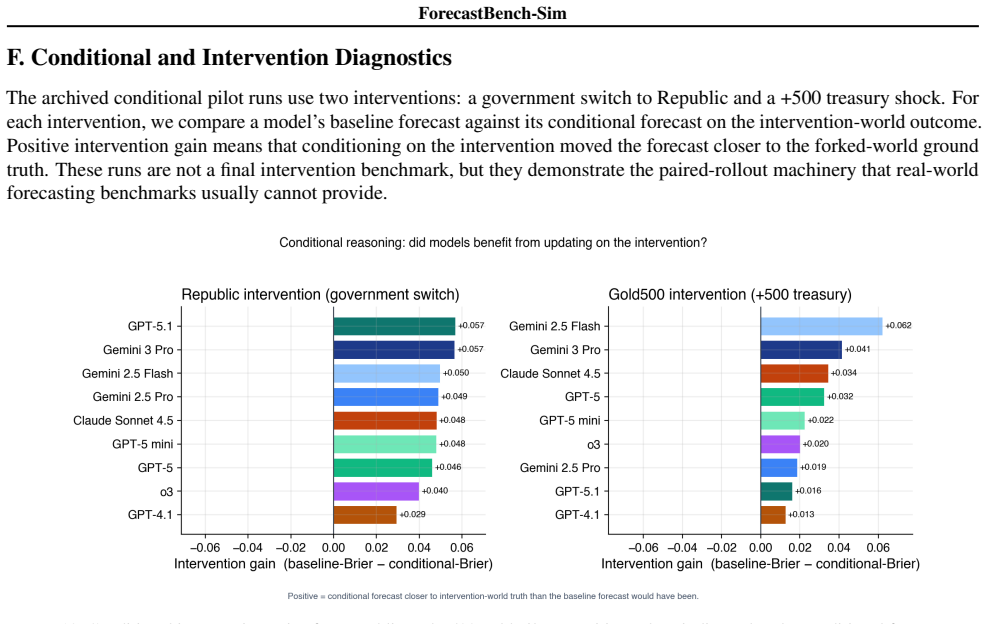
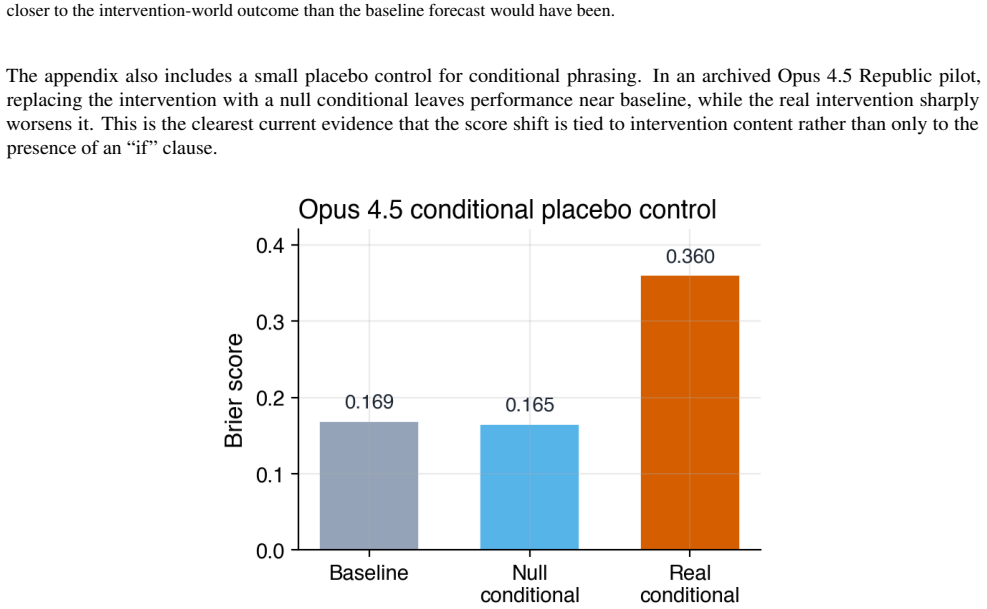
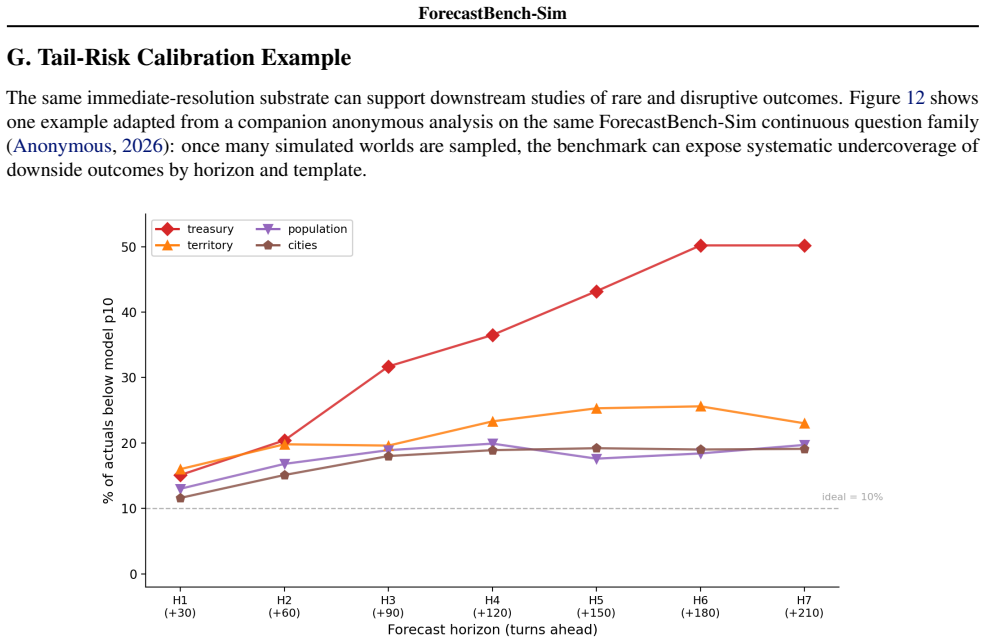
read the original abstract
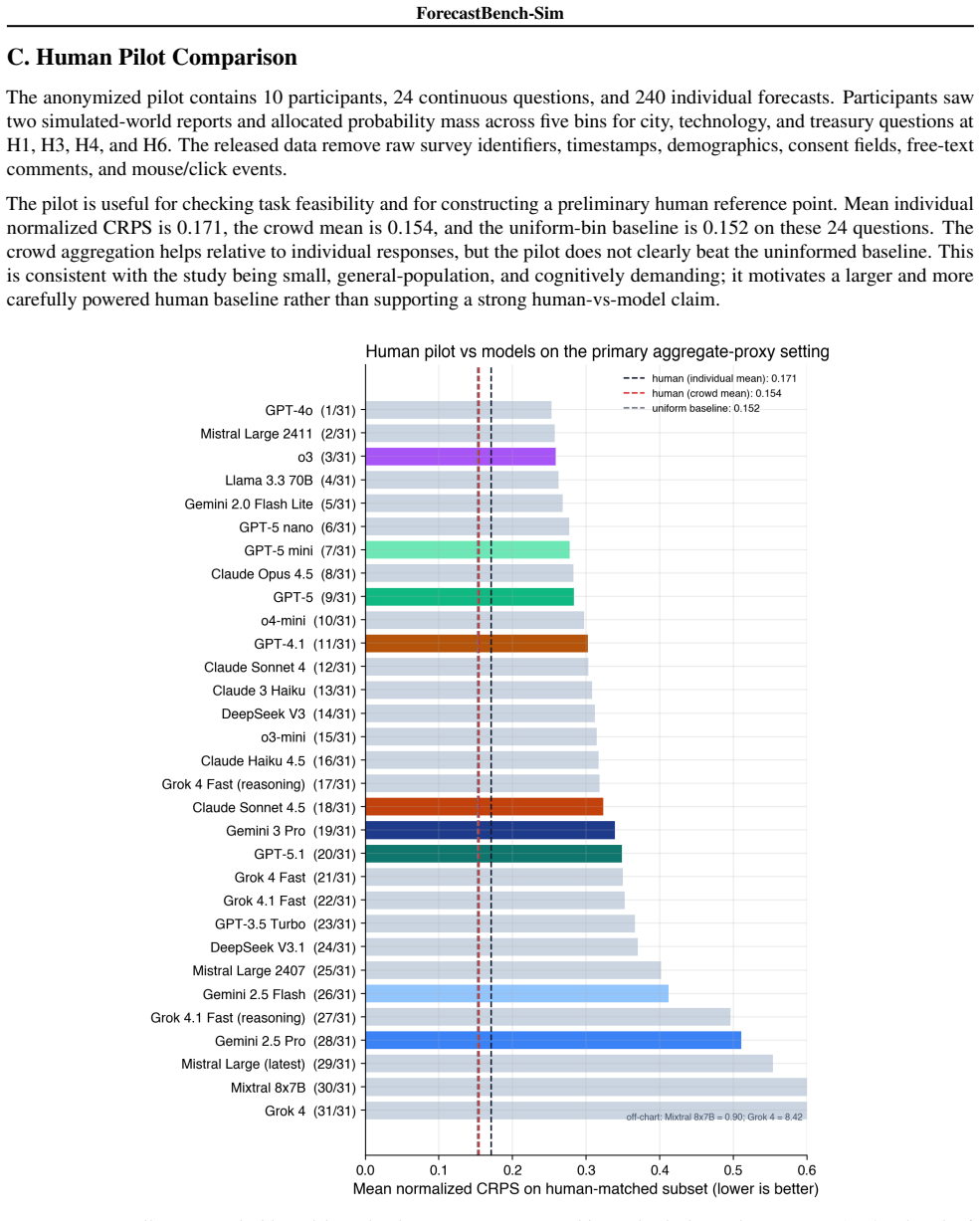
Forecasting benchmarks for general-purpose AI systems usually inherit the constraints of the real world: outcomes resolve slowly, tail events are rare, and counterfactual questions are difficult to score. We introduce ForecastBench-Sim, a simulated-world forecasting benchmark built on game rollouts from Freeciv, a turn-based strategy game modelled on the Civilization series. Forecasters receive a fixed world report (a structured snapshot of the current game state) and answer questions about hidden future states; the benchmark then continues the simulation and scores forecasts. Because the world is simulated, the same setup can generate continuous or binary forecasting questions at arbitrary time horizons, paired intervention worlds for conditional or causal questions, and resolved examples of rare or disruptive outcomes. We describe the benchmark pipeline, question families, scoring protocol, and release artifacts, and report validation slices from model evaluations and an anonymized human pilot. ForecastBench-Sim is intended to complement real-world forecasting benchmarks by providing controlled, immediately resolvable tasks for studying probabilistic reasoning under dynamic world states.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ForecastBench-Sim, a simulated-world forecasting benchmark built on Freeciv game rollouts. Forecasters receive fixed world reports (structured game-state snapshots) and answer questions about future hidden states; the simulation is continued to score the forecasts. The design enables generation of continuous or binary questions at arbitrary time horizons, paired intervention worlds for conditional/causal questions, and resolved examples of rare or disruptive outcomes. The manuscript describes the benchmark pipeline, question families, scoring protocol, and release artifacts, and reports validation slices from model evaluations plus an anonymized human pilot. It positions the benchmark as a complement to real-world forecasting benchmarks for studying probabilistic reasoning under dynamic world states.
Significance. If the implementation details hold, ForecastBench-Sim supplies a controllable, immediately resolvable testbed that overcomes key constraints of real-world forecasting benchmarks (slow resolution, rarity of tail events, difficulty of counterfactual scoring). The simulation approach directly supports reproducible generation of arbitrary-horizon, paired-intervention, and rare-event questions, which could enable targeted experiments on dynamic-state probabilistic reasoning that are otherwise intractable.
minor comments (3)
- [Abstract] Abstract: the claim that 'the same setup can generate continuous or binary forecasting questions at arbitrary time horizons' is presented without an explicit statement of the supported horizon range or any constraints imposed by Freeciv turn mechanics; adding one sentence would clarify the scope.
- [Validation section] The manuscript states that validation slices from model evaluations and a human pilot are reported, yet no table or figure summarizing quantitative metrics (e.g., calibration scores, number of questions, or inter-rater agreement) is referenced in the provided abstract; ensure these appear with clear captions in the main text.
- [Introduction] Minor notation issue: the term 'fixed world report' is used repeatedly but never given a formal definition or example schema in the abstract; a short illustrative excerpt would aid readers.
Simulated Author's Rebuttal
We thank the referee for their positive summary of ForecastBench-Sim, recognition of its significance in addressing limitations of real-world forecasting benchmarks, and recommendation for minor revision. No specific major comments were listed in the report.
Circularity Check
No significant circularity; benchmark construction is self-contained
full rationale
The paper presents ForecastBench-Sim as a benchmark built directly on Freeciv game rollouts, with claims about generating questions, interventions, and resolved outcomes following immediately from the simulation design. No equations, fitted parameters, predictions, or derivations are present that reduce to inputs by construction. No self-citations are load-bearing for any uniqueness or ansatz, and the work does not rename prior results or import theorems from the authors' prior papers. The central contribution is the benchmark pipeline and artifacts, which are internally consistent by explicit construction without external validation dependencies that would create circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Freeciv game dynamics and structured world reports serve as a suitable proxy for real-world forecasting challenges including tail events and dynamic states.
Reference graph
Works this paper leans on
-
[1]
: 1950 , Verification of forecasts expressed in terms of probability
doi: 10.1175/1520-0493(1950)078 ⟨0001:VOFEIT⟩2.0 .CO;2. Epoch AI. Data on AI Capabilities and Benchmarking. ht tps://epoch.ai/benchmarks ,
-
[2]
FutureSearch, Wildman, J., Bosse, N
Accessed: 2026-06-16. FutureSearch, Wildman, J., Bosse, N. I., Hnyk, D., M¨uhlbacher, P., Hambly, F., Evans, J., Schwarz, D., and Phillips, L. Bench to the future: A pastcasting benchmark for forecasting agents.arXiv preprint arXiv:2506.21558,
arXiv 2026
-
[3]
Journal of the American Statistical Association , Year =
doi: 10.1198/016214506000001437. Halawi, D., Zhang, F., Yueh-Han, C., and Steinhardt, J. Ap- proaching human-level forecasting with language models. InAdvances in Neural Information Processing Systems (NeurIPS),
-
[5]
Jin, Z., Chen, Y ., Leeb, F., Gresele, L., Kamal, O., Lyu, Z., Blin, K., Adauto, F
URL https://arxiv.or g/abs/2512.00193. Jin, Z., Chen, Y ., Leeb, F., Gresele, L., Kamal, O., Lyu, Z., Blin, K., Adauto, F. G., Kleiman-Weiner, M., Sachan, M., and Sch¨olkopf, B. CLadder: Assessing causal reasoning in language models. InAdvances in Neural Information Processing Systems (NeurIPS),
-
[6]
Paleka, D., Goel, S., Geiping, J., and Tram`er, F
arXiv:2409.19839. Paleka, D., Goel, S., Geiping, J., and Tram`er, F. Pitfalls in evaluating language model forecasters.arXiv preprint arXiv:2506.00723, 2025a. URL https://arxiv.or g/abs/2506.00723. Paleka, D., Sudhir, A. P., Alvarez, A., Bhat, V ., Shen, A., Wang, E., and Tram `er, F. Consistency checks for lan- guage model forecasters. InInternational Co...
arXiv 2025
-
[7]
Requeima, J., Bronskill, J., Choi, D., Turner, R
arXiv:2401.10568. Requeima, J., Bronskill, J., Choi, D., Turner, R. E., and Du- venaud, D. LLM processes: Numerical predictive distri- butions conditioned on natural language. InAdvances in Neural Information Processing Systems (NeurIPS),
-
[8]
URLhttps://arxiv.org/abs/2405.12856. The Freeciv Project. Freeciv. https://www.freeciv. org/,
-
[9]
Tian, K., Mitchell, E., Zhou, A., Sharma, A., Rafailov, R., Yao, H., Finn, C., and Manning, C
Accessed 2026-05-06. Tian, K., Mitchell, E., Zhou, A., Sharma, A., Rafailov, R., Yao, H., Finn, C., and Manning, C. D. Just ask for calibration: Strategies for eliciting calibrated confi- dence scores from language models fine-tuned with hu- man feedback. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp. 5433–5442,
2026
-
[10]
Vezhnevets, A
URL https://aclantholo gy.org/2023.emnlp-main.330/. Vezhnevets, A. S., Agapiou, J. P., Matyas, A., Beyret, B., Aldridge, E., Lopez Guevara, T., Sunehag, P., Du ´e˜nez- Guzm´an, E. A., Webb, T., Bishop, J., Garrad, S., Vaughan, D., Ramos, D., Anderson, G., Rabinowitz, N., and Leibo, J. Z. Generative agent-based modeling with actions grounded in physical, s...
2023
-
[11]
5 ForecastBench-Sim A
URL https://icml.cc/virtual/ 2025/poster/44343. 5 ForecastBench-Sim A. Sample World Report Each forecasting task is built around a singleworld report: a structured text document, optionally accompanied by territory map images, that summarizes the state of a Freeciv game at the snapshot turn (currently turn 60). The report is the only world-specific input ...
2025
-
[12]
This appendix expands those numbers with per-horizon Spearman correlations and the underlying model lists
and a published real-world forecasting benchmark (ForecastBench Dataset Brier; Karger et al., 2024). This appendix expands those numbers with per-horizon Spearman correlations and the underlying model lists. Data sources.ECI scores are taken from the Epoch AI benchmarking hub (Epoch AI, 2026). ForecastBench Dataset Brier scores are zero-shot entries from ...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.