Reversa: A Reverse Documentation Engineering Framework for Converting Legacy Software into Operational Specifications for AI Agents
Pith reviewed 2026-05-20 08:54 UTC · model grok-4.3
The pith
Reversa turns legacy code into traceable operational specifications using a multi-agent pipeline that marks confidence levels and preserves gaps for human review.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
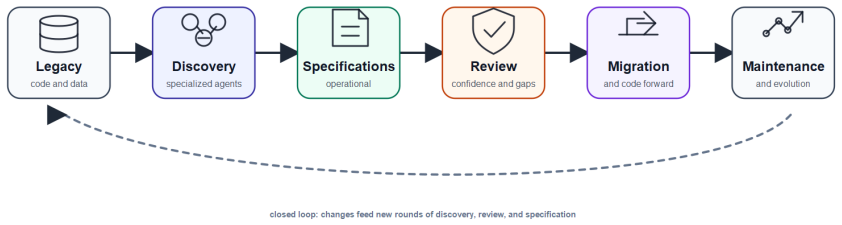
Reversa organizes the reverse documentation process as a multi-agent pipeline that produces traceable operational specifications for AI agents, with explicit confidence marking and preservation of gaps for human validation. The pipeline includes agents for project surface mapping, module analysis, implicit rule extraction, architecture synthesis, unit-level specification writing, and claim review. Traceability connects generated claims directly to code locations, confidence indices flag reliability, and gaps are registered rather than auto-filled. In the reported case study on an ATM system, the pipeline produced 517 claims, 10 registered gaps, 53 Gherkin parity scenarios, and advanced nine
What carries the argument
The multi-agent pipeline of specialized agents for surface mapping, module analysis, implicit rule extraction, architecture synthesis, unit specification writing, and claim review, supported by traceability links, confidence marking, and explicit gap preservation.
If this is right
- Traceable specifications let AI agents reference exact code origins when proposing changes, reducing risk of unintended side effects.
- Confidence marking allows teams to focus human validation on lower-scoring claims first.
- Registered gaps prevent AI agents from acting on incomplete knowledge by surfacing areas that need manual input.
- The Node.js CLI with SHA-256 manifest supports safe installation and updates across different agent engines.
- The proposed evaluation metrics for coverage, traceability, confidence, utility, and cost provide a structured way to compare future reverse documentation methods.
Where Pith is reading between the lines
- If the pipeline generalizes beyond the COBOL case, organizations could use it to create AI-usable contracts for other legacy languages without full manual re-documentation.
- The gap-preservation mechanism could be extended to track how human-filled gaps affect downstream AI modification success rates.
- Connecting Reversa-style pipelines to automated testing frameworks might create closed-loop validation where generated specs are immediately checked against running systems.
- This method could lower the barrier for incremental modernization by giving AI agents operational contracts instead of raw code dumps.
Load-bearing premise
The multi-agent pipeline can reliably extract implicit rules and synthesize accurate specifications from legacy code without introducing critical errors or omissions.
What would settle it
Completing the parity validation and cutover in the ATM case study and finding substantial mismatches between the generated specifications and the original system's observed behavior would show the pipeline does not produce sufficiently accurate results.
Figures


read the original abstract
Legacy systems concentrate business rules, architectural decisions, and operational exceptions that often remain implicit in code, data, configuration, and maintenance practices. At the same time, language-model-based coding agents depend on reliable context, correctness criteria, and behavioral contracts to modify real systems with lower risk. This paper presents Reversa, a reverse documentation engineering framework for converting legacy software into traceable operational specifications for AI agents. Reversa organizes this process as a multi-agent pipeline: specialized agents map the project surface, analyze modules, extract implicit rules, synthesize architecture, write unit-level specifications, and review generated claims. The proposal emphasizes three mechanisms: traceability between code and specification, explicit confidence marking, and preservation of gaps for human validation. The framework is distributed as a Node.js CLI, installs skills across multiple agent engines, and uses a SHA-256 manifest to preserve modified files during update or uninstall operations. In addition to the architectural description, we report an exploratory case study on migrating an ATM from COBOL to Go, in which the pipeline produced 517 claims classified by an internal confidence index, 10 registered gaps, 53 Gherkin parity scenarios, and a reconstruction plan with 9 of 11 tasks completed at inventory time. Final parity validation and cutover were not completed in this study. We do not claim broad empirical superiority; we position the contribution with respect to the literature on reverse engineering, LLM-based documentation, and software agents, and propose an evaluation protocol with metrics for coverage, traceability, confidence, utility, and cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Reversa, a multi-agent reverse documentation engineering framework that converts legacy code into traceable operational specifications for AI agents. The framework organizes the process via specialized agents for project mapping, module analysis, rule extraction, architecture synthesis, unit specification writing, and claim review, with built-in traceability, confidence marking, and explicit gap preservation for human review. It is implemented as a Node.js CLI tool and evaluated in an exploratory case study migrating an ATM system from COBOL to Go, which produced 517 claims, 10 gaps, and 53 Gherkin scenarios; the study notes that final parity validation and cutover were not completed and makes no claim of broad empirical superiority.
Significance. If the multi-agent pipeline can be shown to reliably extract implicit rules and produce accurate specifications, the work would offer a practical bridge between legacy systems and LLM-based agents by supplying verifiable behavioral contracts. The explicit mechanisms for traceability and gap handling address a real pain point in software modernization, and the open CLI distribution plus proposed evaluation protocol (coverage, traceability, confidence, utility, cost) could support future comparative studies. Current evidence from a single incomplete case study, however, leaves the practical utility and error rates unquantified.
major comments (1)
- [Case study description] Case study description (and abstract): the manuscript reports that the pipeline generated 517 claims, 10 gaps, and 53 Gherkin scenarios for the ATM-to-Go migration but explicitly states that 'Final parity validation and cutover were not completed in this study.' Because no direct comparison between the synthesized specifications and the original legacy behavior was performed, there is no measurement of discrepancies, omissions, or introduced errors. This directly weakens support for the central claim that the multi-agent pipeline reliably extracts implicit rules without critical errors or omissions.
minor comments (2)
- [Framework architecture] The description of the six specialized agents would benefit from a table or diagram showing their inputs, outputs, and hand-off points to make the pipeline flow easier to follow.
- [Case study] The reconstruction plan is said to have 9 of 11 tasks completed; listing the two incomplete tasks and their status would clarify the scope of the reported results.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment below and have made revisions to better clarify the exploratory nature of the case study.
read point-by-point responses
-
Referee: Case study description (and abstract): the manuscript reports that the pipeline generated 517 claims, 10 gaps, and 53 Gherkin scenarios for the ATM-to-Go migration but explicitly states that 'Final parity validation and cutover were not completed in this study.' Because no direct comparison between the synthesized specifications and the original legacy behavior was performed, there is no measurement of discrepancies, omissions, or introduced errors. This directly weakens support for the central claim that the multi-agent pipeline reliably extracts implicit rules without critical errors or omissions.
Authors: We agree that the case study does not include direct parity validation or measurement of discrepancies against the original legacy behavior, as the manuscript already states explicitly in the abstract and case study section. However, the paper does not advance a central claim that the pipeline 'reliably extracts implicit rules without critical errors or omissions.' It is positioned as an exploratory case study that demonstrates the Reversa framework's application, producing 517 claims, 10 gaps, and 53 Gherkin scenarios, while noting that validation and cutover were not completed and making no claim of broad empirical superiority. The primary contribution is the multi-agent pipeline design with traceability, confidence scoring, and explicit gap handling. To address the concern and prevent misinterpretation, we will revise the abstract and case study section to add a dedicated limitations discussion that emphasizes the exploratory scope, the absence of validation metrics, and plans for future empirical studies on accuracy and error rates. revision: yes
Circularity Check
No significant circularity in framework description or case study
full rationale
The paper describes Reversa as a multi-agent pipeline for converting legacy code into traceable specifications, emphasizing traceability, confidence marking, and gap preservation. It reports an exploratory case study producing 517 claims, 10 gaps, and 53 Gherkin scenarios from an ATM-to-Go migration, with explicit note that final parity validation and cutover were not completed. No mathematical derivations, equations, fitted parameters, or self-referential definitions appear in the provided text. Claims rest on the described process and observed outputs rather than any reduction to inputs by construction. The contribution is positioned with respect to existing literature on reverse engineering and LLM-based documentation without load-bearing self-citations that would make the central premise circular. This is a standard descriptive framework paper with an incomplete exploratory study, self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Legacy systems concentrate business rules, architectural decisions, and operational exceptions that often remain implicit in code, data, configuration, and maintenance practices.
invented entities (1)
-
Multi-agent pipeline consisting of specialized agents for project mapping, module analysis, rule extraction, architecture synthesis, unit specification writing, and claim review.
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Reversa organizes this process as a multi-agent pipeline: specialized agents map the project surface, analyze modules, extract implicit rules, synthesize architecture, write unit-level specifications, and review generated claims.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The pipeline produced 517 claims classified by an internal confidence index, 10 registered gaps, 53 Gherkin parity scenarios
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Advancing requirements engineering through generative ai: Assessing the role of llms
Chetan Arora, John Grundy, and Mohamed Abdelrazek. Advancing requirements engineering through generative ai: Assessing the role of llms. Generative AI for Effective Software Development, 2024. doi:10.1007/978-3-031-55642-5_6
-
[2]
Contemporary software modernization: Perspectives and challenges to deal with legacy systems, 2024
Wesley Klewerton Guez Assuncao, Luciano Marchezan, Alexander Egyed, and Rudolf Ramler. Contemporary software modernization: Perspectives and challenges to deal with legacy systems, 2024. doi:10.48550/arXiv.2407.04017
-
[3]
Knowledgegraphbasedrepository-levelcodegeneration
MihirAthaleandVishalVaddina. Knowledgegraphbasedrepository-levelcodegeneration. In 2025 IEEE/ACM International Workshop on Large Language Models for Code (LLM4Code), pages 169–176, 2025. doi:10.1109/LLM4Code66737.2025.00026
-
[4]
Program Synthesis with Large Language Models
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and Charles Sutton. Program synthesis with large language models, 2021. doi:10.48550/arXiv.2108.07732
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2108.07732 2021
-
[5]
AutoReSpec: A Framework for Generating Specification using Large Language Models
Ragib Shahariar Ayon and Shibbir Ahmed. AutoReSpec: A framework for generating specification using large language models, 2026. doi:10.48550/arXiv.2604.03758
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.03758 2026
-
[6]
Addison- Wesley Professional, 4 edition, 2021
Len Bass, Paul Clements, and Rick Kazman.Software Architecture in Practice. Addison- Wesley Professional, 4 edition, 2021
work page 2021
-
[7]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, 14 Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mo- hammad Bav...
-
[8]
doi:10.48550/arXiv.2107.03374
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2107.03374
-
[9]
Knowledgegraphbasedrepository-levelcodegeneration
Nilesh Dhulshette, Sapan Shah, and Vinay Kulkarni. Hierarchical repository-level code summarization for business applications using local llms. In2025 IEEE/ACM International Workshop on Large Language Models for Code (LLM4Code), pages 145–152, 2025. doi: 10.1109/LLM4Code66737.2025.00023
-
[10]
Brunelle, and Samruddhi Thaker
Colin Diggs, Michael Doyle, Amit Madan, Siggy Scott, Emily Escamilla, Jacob Zimmer, Naveed Nekoo, Paul Ursino, Michael Bartholf, Zachary Robin, Anand Patel, Chris Glasz, William Macke, Paul Kirk, Jasper Phillips, Arun Sridharan, Doug Wendt, Scott Rosen, Nitin Naik, Justin F. Brunelle, and Samruddhi Thaker. Leveraging llms for legacy code modernization: Ch...
-
[11]
Hao Ding, Ziwei Fan, Ingo Guehring, Gaurav Gupta, Wooseok Ha, Jun Huan, Linbo Liu, Behrooz Omidvar-Tehrani, Shiqi Wang, and Hao Zhou. Reasoning and planning with large language models in code development. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 6480–6490, 2024. doi:10.1145/3637528. 3671452
-
[12]
Leveraging large language models for use case model generation from software requirements
Tobias Eisenreich, Nicholas Friedlaender, and Stefan Wagner. Leveraging large language models for use case model generation from software requirements. In2025 40th IEEE/ACM International Conference on Automated Software Engineering Workshops (ASEW), pages 221–227, 2025. doi:10.1109/ASEW67777.2025.00050
-
[13]
Muhammet Kursat Gormez, Murat Yilmaz, and Paul M. Clarke. Large language models for software engineering: A systematic mapping study. InSoftware Process Improvement and Capability Determination, pages 78–93. Springer, 2024. doi:10.1007/978-3-031-71139-8_ 5
-
[14]
Large language models for software engineering: A systematic literature review
Xinyi Hou, Yanjie Zhao, Yue Liu, Zhou Yang, Kailong Wang, Li Li, Xiapu Luo, David Lo, John Grundy, and Haoyu Wang. Large language models for software engineering: A systematic literature review.ACM Transactions on Software Engineering and Methodology, 33(8):1–79, 2024. doi:10.1145/3695988
-
[15]
Iso/iec/ieee 42010:2022, software, systems and enterprise – architecture description, 2022
ISO/IEC/IEEE. Iso/iec/ieee 42010:2022, software, systems and enterprise – architecture description, 2022
work page 2022
-
[16]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. SWE-bench: Can language models resolve real-world github issues? InThe Twelfth International Conference on Learning Representations, 2024. doi: 10.48550/arXiv.2310.06770
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.06770 2024
-
[17]
Morescient gai for software engineering, 2024
Marcus Kessel and Colin Atkinson. Morescient gai for software engineering, 2024. doi: 10.48550/arXiv.2406.04710. 15
-
[18]
CEGen: Cause-effect graph generation using large language models
Hiroyuki Kirinuki. CEGen: Cause-effect graph generation using large language models. In 2024 31st Asia-Pacific Software Engineering Conference (APSEC), pages 521–522, 2024. doi:10.1109/APSEC65559.2024.00073
-
[19]
Using llms in software requirements specifications: An empirical evaluation
Madhava Krishna, Bhagesh Gaur, Arsh Verma, and Pankaj Jalote. Using llms in software requirements specifications: An empirical evaluation. In2024 IEEE 32nd International Requirements Engineering Conference (RE), pages 475–483, 2024. doi:10.1109/RE59067. 2024.00056
-
[20]
Reproducible, explainable, and effective evaluations of agentic ai for software engineering, 2026
Jingyue Li and Andre Storhaug. Reproducible, explainable, and effective evaluations of agentic ai for software engineering, 2026. doi:10.48550/arXiv.2604.01437
-
[21]
Junwei Liu, Kaixin Wang, Yixuan Chen, Xin Peng, Zhenpeng Chen, Lingming Zhang, and Yiling Lou. Large language model-based agents for software engineering: A survey.ACM Transactions on Software Engineering and Methodology, 2026. doi:10.1145/3796507
-
[22]
Zhuang Liu, Hailong Wang, Tongtong Xu, and Bei Wang. RAG-driven multiple assertions generation with large language models.Empirical Software Engineering, 30(4), 2025. doi: 10.1007/s10664-025-10641-1
-
[23]
RepoAgent: An llm-powered open-source framework for repository-level code documentation generation,
Qinyu Luo, Yining Ye, Shihao Liang, Zhong Zhang, Yujia Qin, Yaxi Lu, Yesai Wu, Xin Cong, Yankai Lin, Yingli Zhang, Xiaoyin Che, Zhiyuan Liu, and Maosong Sun. RepoAgent: An llm-powered open-source framework for repository-level code documentation generation,
-
[24]
doi:10.48550/arXiv.2402.16667
-
[25]
Testingthe effect of code documentation on large language model code understanding
William Macke and Michael Doyle. Testingthe effect of code documentation on large language model code understanding. InFindings of the Association for Computational Linguistics: NAACL 2024, pages 1044–1050, 2024. doi:10.18653/v1/2024.findings-naacl.66
-
[26]
Arsalan Masoudifard, Mohammad Mowlavi Sorond, Moein Madadi, Mohammad Sabokrou, and Elahe Habibi. Integrating graph retrieval augmented generation method with large language models to improve software requirement specification, 2024. doi:10.2139/ssrn. 4961380
-
[27]
Consciousness and Cognition20(2011) https://doi.org/10.1016/j
Thakshila Imiya Mohottige, Artem Polyvyanyy, Colin J. Fidge, Rajkumar Buyya, and Alistair Barros. Reengineering software systems into microservices: State-of-the-art and future directions.Information and Software Technology, 183:107732, 2025. doi:10.1016/j. infsof.2025.107732
work page doi:10.1016/j 2025
-
[28]
C hat D ev: Communicative Agents for Software Development
Chen Qian, Wei Liu, Hongzhang Liu, Nuo Chen, Yufan Dang, Jiahao Li, Cheng Yang, Weize Chen, Yusheng Su, Xin Cong, Juyuan Xu, Dahai Li, Zhiyuan Liu, and Maosong Sun. ChatDev: Communicative agents for software development. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15174–15186, 20...
-
[29]
XIS-Reverse: A model-driven reverse engineering approach for legacy information systems
Andre Reis and Alberto Rodrigues da Silva. XIS-Reverse: A model-driven reverse engineering approach for legacy information systems. InProceedings of the 5th International Conference on Model-Driven Engineering and Software Development, pages 196–207, 2017. doi:10. 5220/0006271501960207
work page 2017
-
[30]
Robert, Ipek Ozkaya, and Douglas C
John E. Robert, Ipek Ozkaya, and Douglas C. Schmidt. Transforming software engineering and software acquisition with large language models. Artificial Intelligence and Large Language Models, 2026. doi:10.1201/9781003492252-7
-
[31]
The future of ai-driven software engineering, 2024
Valerio Terragni, Annie Vella, Partha Roop, and Kelly Blincoe. The future of ai-driven software engineering, 2024. doi:10.48550/arXiv.2406.07737. 16
-
[32]
The impact of traceability on software maintenance and evolution: A mapping study
Fangchao Tian, Tianlu Wang, Peng Liang, Chong Wang, Arif Ali Khan, and Muhammad Ali Babar. The impact of traceability on software maintenance and evolution: A mapping study. Journal of Software: Evolution and Process, 33(10), 2021. doi:10.1002/smr.2374
-
[33]
Software architecture in practice: Challenges and opportunities
Zhiyuan Wan, Yun Zhang, Xin Xia, Yi Jiang, and David Lo. Software architecture in practice: Challenges and opportunities. InProceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, pages 1457–1469, 2023. doi:10.1145/3611643.3616367
-
[34]
Renxi Wang, Haonan Li, Xudong Han, Yixuan Zhang, and Timothy Baldwin. Learning from failure: Integrating negative examples when fine-tuning large language models as agents,
-
[35]
doi:10.48550/arXiv.2402.11651
-
[36]
Advancements and challenges of large language model-based code generation and completion
Zheer Wang. Advancements and challenges of large language model-based code generation and completion. InProceedings of the 1st International Conference on Modern Logistics and Supply Chain Management, pages 208–213, 2024. doi:10.5220/0013271800004558
-
[37]
Zi Wang, Xiaoyu Zhu, Hongqiang Wang, Yichun Yu, and Yuqing Lan. KerSpecGen: Co-piloting formal kernel specification synthesis with refined knowledge graphs and large lan- guage models.PLOS ONE, 20(12):e0338821, 2025. doi:10.1371/journal.pone.0338821
-
[38]
Hironori Washizaki, Yann-Gaël Guéhéneuc, and Foutse Khomh. ProMeTA: A taxonomy for program metamodels in program reverse engineering.Empirical Software Engineering, 23:2323–2358, 2018. doi:10.1007/s10664-017-9592-3
-
[39]
Prompt engineering with ai coding agents
Nick Wienholt. Prompt engineering with ai coding agents. GitHub Copilot and AI Coding Tools in Practice, 2025. doi:10.1007/979-8-8688-1784-7_4
-
[40]
Danning Xie, Byungwoo Yoo, Nan Jiang, Mijung Kim, Lin Tan, Xiangyu Zhang, and Judy S. Lee. How effective are large language models in generating software specifications? In 2025 IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER), 2025. doi:10.1109/SANER64311.2025.00014
-
[41]
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. SWE-agent: Agent-computer interfaces enable automated software engineering. InAdvances in Neural Information Processing Systems 37, pages 50528–50652, 2024. doi:10.52202/079017-1601
-
[42]
YuBo Zhang, KaiChun Yao, LiBo Zhang, and Chen Zhao. RepoCBench: A benchmark for c-oriented repository-level code generation with large language models and agents, 2025. doi:10.2139/ssrn.5886003
-
[43]
A Survey of Large Language Models
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, Yifan Du, Chen Yang, Yushuo Chen, Zhipeng Chen, Jinhao Jiang, Ruiyang Ren, Yifan Li, Xinyu Tang, Zikang Liu, Peiyu Liu, Jian-Yun Nie, and Ji-Rong Wen. A survey of large language models, 2023. doi: 10.48550/arXiv.2303.18223
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.18223 2023
-
[44]
A survey of large language models for code: Evolution, benchmarking, and future trends, 2023
Zibin Zheng, Kaiwen Ning, Yanlin Wang, Jingwen Zhang, Dewu Zheng, Mingxi Ye, and Jiachi Chen. A survey of large language models for code: Evolution, benchmarking, and future trends, 2023. doi:10.48550/arXiv.2311.10372
-
[45]
T. Zhu, L. C. Cordeiro, and Y. Sun. ReqInOne: A large language model-based agent for software requirements specification generation. InProceedings of the IEEE International Conference on Requirements Engineering, pages 449–457, 2025. doi:10.1109/RE63999. 2025.00054. 17
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.