TacCoRL: Integrating Tactile Feedback into VLA via Simulation
Pith reviewed 2026-06-27 09:50 UTC · model grok-4.3
The pith
TacCoRL injects tactile feedback into vision-language-action policies through mixed sim-real warm-starting and simulation-based reinforcement learning for direct real-robot transfer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
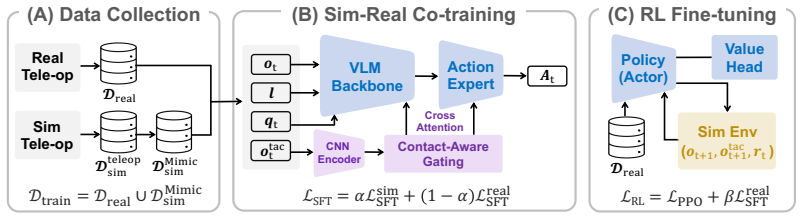
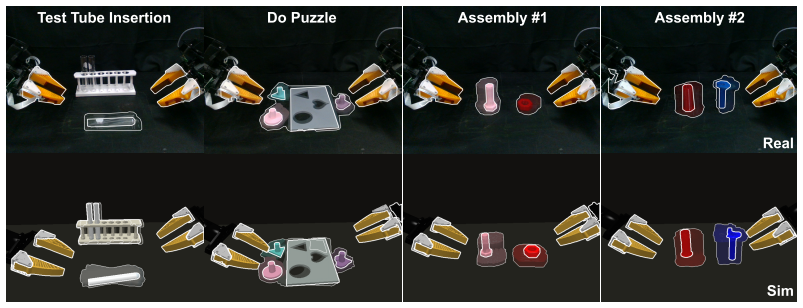
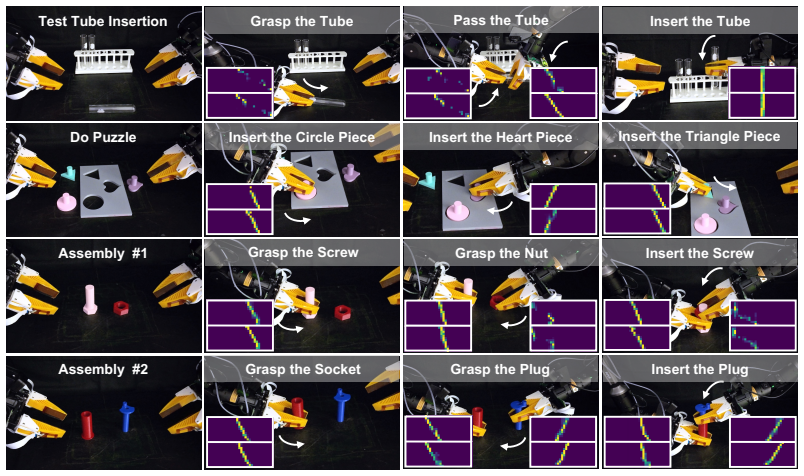
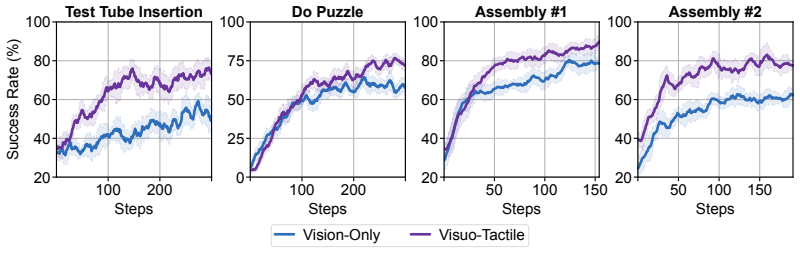
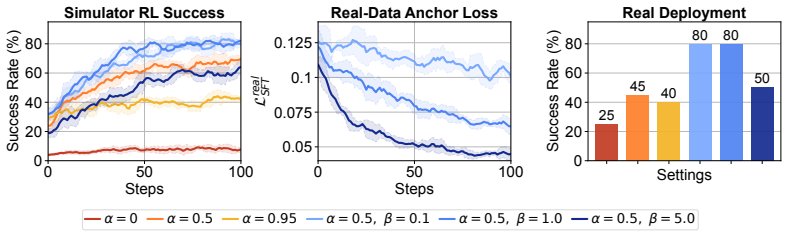
TacCoRL uses a real-aligned simulator as a closed-loop environment where mixed simulated and real trajectories first warm-start tactile-conditioned actions in a pretrained VLA policy; reinforcement learning then optimizes the policy on simulated contact rollouts with verifiable task rewards while a supervised objective on real trajectories anchors the refined policy to deployment distributions. The resulting visuo-tactile policy transfers directly to the real robot and reaches an average 72.5 percent success rate across four bimanual contact-rich tasks compared with a 50 percent baseline.
What carries the argument
The sim-real co-training plus simulation-based RL loop that learns contact-modulated action responses in near-failure states using a real-aligned simulator for rollouts.
If this is right
- The policy deploys directly on real hardware without needing privileged simulation state or further real-world reinforcement learning.
- Tactile-conditioned actions improve handling of near-failure contact states that are rare in demonstrations.
- Average success across the four tested bimanual contact-rich tasks reaches 72.5 percent versus 50 percent for the baseline.
- The supervised objective on real trajectories keeps the policy aligned with actual visual, tactile, and action distributions.
Where Pith is reading between the lines
- If simulators can be made accurate enough for contact, similar co-training loops could reduce reliance on large-scale real tactile datasets for other robot skills.
- The approach suggests that verifiable task rewards in simulation can substitute for risky real-world exploration when visual-tactile priors are already present.
- Extending the same warm-start plus RL structure to additional sensor modalities might improve robustness in tasks where one modality alone is insufficient.
Load-bearing premise
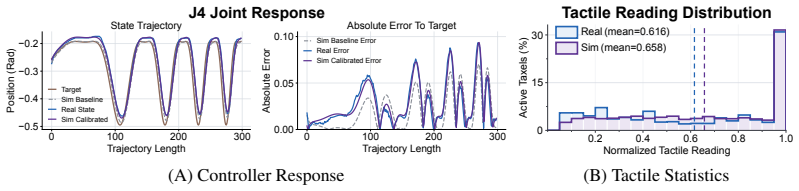
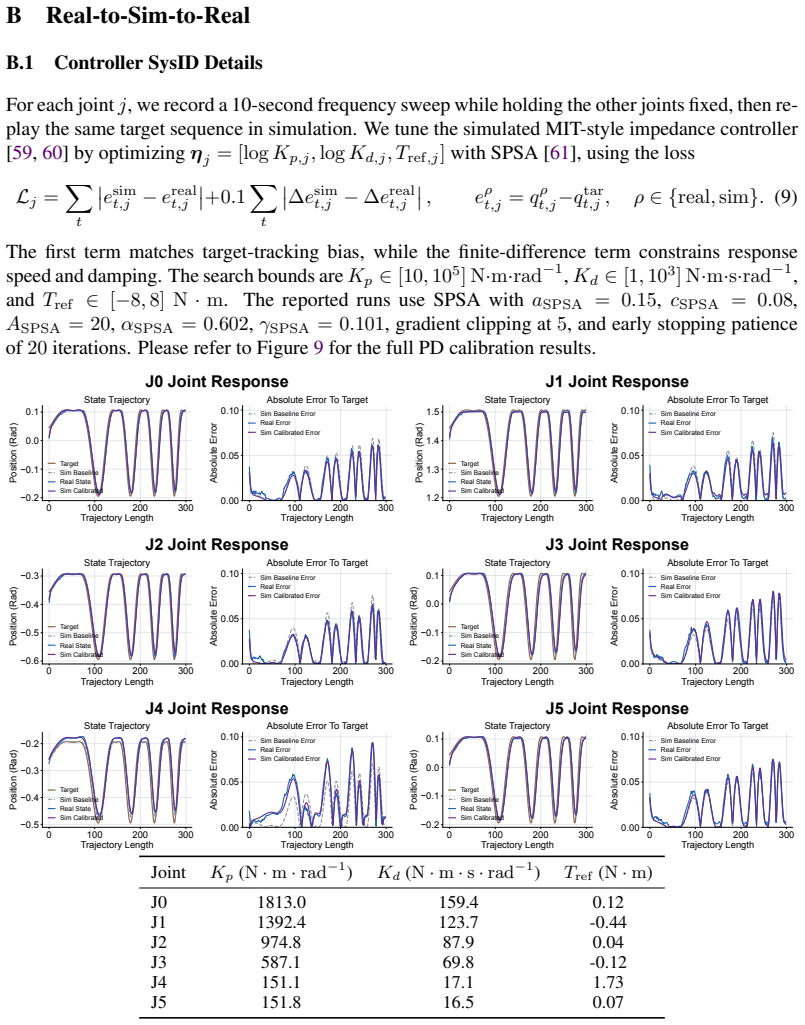
A real-aligned simulator exists that accurately reproduces contact dynamics sufficiently for RL rollouts to produce policies that transfer zero-shot to hardware.
What would settle it
Train the policy in the described simulator loop and measure whether its success rate on the four real bimanual tasks matches the reported 72.5 percent without any privileged simulation state or online real-world updates.
Figures





read the original abstract
Vision-language-action (VLA) models provide strong visual, language, and action priors for robot manipulation, but visual observations alone often miss the local contact state required for contact-rich tasks. We present TacCoRL, a scalable framework that injects Tactile feedback into VLA policies and improves them through sim-real Co-training and simulation-based reinforcement learning (RL), without requiring large-scale tactile pretraining or extensive real-world contact exploration. The key idea is not only adding touch as an input, but learning how contact readings should modulate action responses in near-failure states that are rare in demonstrations and risky to collect on hardware. We use a real-aligned simulator as a closed-loop training environment for contact interaction. Mixed simulated and real trajectories first warm-start tactile-conditioned actions in the pretrained policy. Reinforcement learning with verifiable task rewards then optimizes the policy using simulated contact rollouts. It reinforces tactile-conditioned actions that lead to task completion, while a supervised objective on real trajectories keeps the refined policy anchored to deployment visual, tactile, and action distributions. The resulting policy transfers directly to the real robot without privileged simulation state or online real-world RL. Across four bimanual contact-rich tasks, the final visuo-tactile policy achieves an average success rate of 72.5%, compared to baseline of 50.0%. Result videos and more details are available at https://tac-corl.github.io/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TacCoRL, a framework for injecting tactile feedback into pretrained vision-language-action (VLA) policies. It uses mixed simulated and real trajectories to warm-start tactile-conditioned actions, followed by simulation-based RL with verifiable rewards to optimize contact responses in near-failure states, while a supervised objective on real data anchors the policy. The resulting policy is claimed to transfer zero-shot to hardware; across four bimanual contact-rich tasks the visuo-tactile policy reaches 72.5% average success versus a 50% baseline.
Significance. If the empirical claims are substantiated, the work would provide a concrete route to augment VLA models with tactile modulation for contact-rich manipulation without large-scale tactile pretraining or online real-world RL, addressing a recognized limitation of vision-only policies in tasks sensitive to local contact state.
major comments (2)
- [Abstract] Abstract: the central zero-shot transfer claim rests on the existence of a 'real-aligned simulator' that produces contact rollouts whose learned tactile-to-action mappings transfer directly; however, no quantitative validation of simulator fidelity (real-vs-sim tactile signal correlation, force-torque error metrics, or domain-randomization ablation) is supplied, leaving the 22.5-point success-rate lift vulnerable to sim-specific artifacts.
- [Abstract] Abstract: the reported success rates are given without any description of experimental protocol, task definitions, baseline implementations, trial counts, variance, or statistical tests, so the reliability of the improvement and the cross-task claim cannot be assessed from the provided text.
minor comments (1)
- The abstract refers to 'four bimanual contact-rich tasks' and 'verifiable task rewards' without naming the tasks or reward formulations.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting areas where the abstract could better substantiate our claims. We address each comment below and will revise the manuscript to improve transparency on simulator validation and experimental details.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central zero-shot transfer claim rests on the existence of a 'real-aligned simulator' that produces contact rollouts whose learned tactile-to-action mappings transfer directly; however, no quantitative validation of simulator fidelity (real-vs-sim tactile signal correlation, force-torque error metrics, or domain-randomization ablation) is supplied, leaving the 22.5-point success-rate lift vulnerable to sim-specific artifacts.
Authors: We agree that quantitative validation of simulator fidelity is essential to support the zero-shot transfer. The manuscript describes the real-aligned simulator construction and its role in co-training/RL, but does not report explicit metrics such as tactile signal correlations or force-torque errors in the abstract (or prominently in results). In revision we will add these metrics, including real-vs-sim correlation coefficients and a domain-randomization ablation, to the methods/results sections to demonstrate that performance gains are not artifacts of simulation-specific contact dynamics. revision: yes
-
Referee: [Abstract] Abstract: the reported success rates are given without any description of experimental protocol, task definitions, baseline implementations, trial counts, variance, or statistical tests, so the reliability of the improvement and the cross-task claim cannot be assessed from the provided text.
Authors: The full manuscript contains task definitions, baseline implementations, trial counts (e.g., 20 trials per task), and variance reporting in the Experiments section. However, the abstract is too concise to include this protocol. We will revise the abstract to briefly note the four tasks, trial counts, and that full protocol/variance/statistical details appear in the main text, allowing readers to assess reliability without expanding the abstract beyond typical length limits. revision: partial
Circularity Check
No significant circularity; empirical results only
full rationale
The paper presents an empirical training pipeline (mixed sim-real warm-start followed by sim RL with task rewards and real supervised anchoring) whose output is measured success rate on hardware. No equations, fitted parameters renamed as predictions, self-definitional quantities, or load-bearing self-citations appear in the abstract or described method. The 72.5% vs 50% result is reported as an experimental outcome rather than a quantity derived by construction from its own inputs. The central premise (simulator fidelity) is an assumption, not a circular derivation step.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A real-aligned simulator exists whose contact dynamics are sufficiently accurate that policies optimized on simulated contact rollouts transfer directly to hardware.
Reference graph
Works this paper leans on
-
[1]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. In Conference on Robot Learning, pages 2165–2183. PMLR, 2023
2023
-
[2]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
Pith/arXiv arXiv 2024
-
[3]
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al.π 0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
Pith/arXiv arXiv 2024
-
[4]
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, et al.π 0.5: A vision-language-action model with open-world generalization. arXiv preprint arXiv:2504.16054, 2025
Pith/arXiv arXiv 2025
-
[5]
W. Yuan, S. Dong, and E. H. Adelson. Gelsight: High-resolution robot tactile sensors for estimating geometry and force.Sensors, 17(12):2762, 2017
2017
-
[6]
Huang, Y
B. Huang, Y . Wang, X. Yang, Y . Luo, and Y . Li. 3D-ViTac: Learning fine-grained manipulation with visuo-tactile sensing. InConference on Robot Learning, 2024
2024
-
[7]
Z. Zhao, S. Haldar, J. Cui, L. Pinto, and R. Bhirangi. Touch begins where vision ends: Gener- alizable policies for contact-rich manipulation.arXiv preprint arXiv:2506.13762, 2025
arXiv 2025
- [8]
-
[9]
F. Yang, C. Ma, J. Zhang, J. Zhu, W. Yuan, and A. Owens. Touch and go: Learning from human-collected vision and touch.arXiv preprint arXiv:2211.12498, 2022
arXiv 2022
-
[10]
Cheng, J
N. Cheng, J. Xu, C. Guan, J. Gao, W. Wang, Y . Li, F. Meng, J. Zhou, B. Fang, and W. Han. Touch100k: A large-scale touch-language-vision dataset for touch-centric multimodal repre- sentation.Information Fusion, 124:103305, 2025
2025
-
[11]
Higuera, A
C. Higuera, A. Sharma, C. K. Bodduluri, T. Fan, P. Lancaster, M. Kalakrishnan, M. Kaess, B. Boots, M. Lambeta, T. Wu, et al. Sparsh: Self-supervised touch representations for vision- based tactile sensing. 2024. InURL https://openreview. net/forum, 2024
2024
-
[12]
P. Hao, C. Zhang, D. Li, X. Cao, X. Hao, S. Cui, and S. Wang. Tla: Tactile-language-action model for contact-rich manipulation.arXiv preprint arXiv:2503.08548, 2025
arXiv 2025
-
[13]
Zhang, P
C. Zhang, P. Hao, X. Cao, X. Hao, S. Cui, and S. Wang. Vtla: Vision-tactile-language- action model with preference learning for insertion manipulation.Biomimetic Intelligence and Robotics, page 100333, 2026
2026
- [14]
- [15]
-
[16]
J. Bi, K. Y . Ma, C. Hao, M. Z. Shou, and H. Soh. Vla-touch: Enhancing vision-language-action models with dual-level tactile feedback.arXiv preprint arXiv:2507.17294, 2025. 9
arXiv 2025
- [17]
-
[18]
Z. Zhang, J. Ma, X. Yang, X. Wen, Y . Zhang, B. Li, Y . Qin, J. Liu, C. Zhao, L. Kang, et al. Touchguide: Inference-time steering of visuomotor policies via touch guidance.arXiv preprint arXiv:2601.20239, 2026
Pith/arXiv arXiv 2026
-
[19]
J. Xu, S. Kim, T. Chen, A. R. Garcia, P. Agrawal, W. Matusik, and S. Sueda. Efficient tactile simulation with differentiability for robotic manipulation. InConference on Robot Learning, pages 1488–1498. PMLR, 2023
2023
-
[20]
Akinola, J
I. Akinola, J. Xu, J. Carius, D. Fox, and Y . Narang. Tacsl: A library for visuotactile sensor simulation and learning.IEEE Transactions on Robotics, 2025
2025
-
[21]
Y . Li, W. Du, C. Yu, P. Li, Z. Zhao, T. Liu, C. Jiang, Y . Zhu, and S. Huang. Taccel: Scaling up vision-based tactile robotics via high-performance gpu simulation.Advances in Neural Information Processing Systems, 38:94577–94604, 2026
2026
-
[22]
S. Sha, Y . Wang, B. Huang, A. Loquercio, and Y . Li. Efficient and reliable teleoperation through real-to-sim-to-real shared autonomy.arXiv preprint arXiv:2603.17016, 2026
arXiv 2026
-
[23]
A. Maddukuri, Z. Jiang, L. Y . Chen, S. Nasiriany, Y . Xie, Y . Fang, W. Huang, Z. Wang, Z. Xu, N. Chernyadev, et al. Sim-and-real co-training: A simple recipe for vision-based robotic ma- nipulation.arXiv preprint arXiv:2503.24361, 2025
arXiv 2025
-
[24]
Y . Lei, M. Liu, A. Maddukuri, Z. Jiang, and Y . Zhu. A mechanistic analysis of sim-and-real co-training in generative robot policies.arXiv preprint arXiv:2604.13645, 2026
Pith/arXiv arXiv 2026
-
[25]
S. Tan, K. Dou, Y . Zhao, and P. Kr ¨ahenb¨uhl. Interactive post-training for vision-language- action models.arXiv preprint arXiv:2505.17016, 2025
Pith/arXiv arXiv 2025
-
[27]
H. Li, Y . Zuo, J. Yu, Y . Zhang, Z. Yang, K. Zhang, X. Zhu, Y . Zhang, T. Chen, G. Cui, et al. Simplevla-rl: Scaling vla training via reinforcement learning.arXiv preprint arXiv:2509.09674, 2025
Pith/arXiv arXiv 2025
-
[28]
L. Shi, S. Chen, F. Gao, Y . Chen, K. Chen, T. Zhang, H. Zang, W. Zhang, C. Yu, and Y . Wang. Beyond imitation: Reinforcement learning-based sim-real co-training for vla models.arXiv preprint arXiv:2602.12628, 2026
Pith/arXiv arXiv 2026
-
[29]
X. Zhang, C. Jia, S. Li, D. He, X. Xiong, Z. Sun, H. He, Y . Wu, B. Yu, L. Sun, et al. How rl unlocks the aha moment in geometric interleaved reasoning.arXiv preprint arXiv:2603.01070, 2026
Pith/arXiv arXiv 2026
-
[30]
Alspach, K
A. Alspach, K. Hashimoto, N. Kuppuswamy, and R. Tedrake. Soft-bubble: A highly com- pliant dense geometry tactile sensor for robot manipulation. In2019 2nd IEEE International Conference on Soft Robotics (RoboSoft), pages 597–604. IEEE, 2019
2019
-
[31]
Z. Zhao, W. Li, Y . Li, T. Liu, B. Li, M. Wang, K. Du, H. Liu, Y . Zhu, Q. Wang, et al. Embed- ding high-resolution touch across robotic hands enables adaptive human-like grasping.Nature Machine Intelligence, 7(6):889–900, 2025
2025
-
[32]
H. Choi, Y . Hou, C. Pan, S. Hong, A. Patel, X. Xu, M. R. Cutkosky, and S. Song. In-the-wild compliant manipulation with umi-ft.arXiv preprint arXiv:2601.09988, 2026. 10
arXiv 2026
-
[33]
Y . Li, Y . Chen, Z. Zhao, P. Li, T. Liu, S. Huang, and Y . Zhu. Simultaneous tactile-visual per- ception for learning multimodal robot manipulation.IEEE Robotics and Automation Letters, 2026
2026
-
[34]
Z. Xu, R. Uppuluri, X. Zhang, C. Fitch, P. G. Crandall, W. Shou, D. Wang, and Y . She. Unit: Data efficient tactile representation with generalization to unseen objects.IEEE Robotics and Automation Letters, 2025
2025
-
[35]
R. Feng, J. Hu, W. Xia, T. Gao, A. Shen, Y . Sun, B. Fang, and D. Hu. Anytouch: Learn- ing unified static-dynamic representation across multiple visuo-tactile sensors.arXiv preprint arXiv:2502.12191, 2025
arXiv 2025
-
[36]
Radford, J
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[37]
F. Yang, C. Feng, Z. Chen, H. Park, D. Wang, Y . Dou, Z. Zeng, X. Chen, R. Gangopadhyay, A. Owens, et al. Binding touch to everything: Learning unified multimodal tactile repre- sentations. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26340–26353, 2024
2024
-
[38]
K. Gubernatorov, M. Sannikov, I. Mikhalchuk, E. Kuznetsov, M. Artemov, O. F. Ouwatobi, M. Fernando, A. Asanov, Z. Guo, and D. Tsetserukou. Hapticvla: Contact-rich manipula- tion via vision-language-action model without inference-time tactile sensing.arXiv preprint arXiv:2603.15257, 2026
arXiv 2026
-
[39]
C. Xu, J. T. Springenberg, M. Equi, A. Amin, A. Esmail, S. Levine, and L. Ke. Rl token: Bootstrapping online rl with vision-language-action models.arXiv preprint arXiv:2604.23073, 2026
Pith/arXiv arXiv 2026
-
[40]
H. Zang, M. Wei, S. Xu, Y . Wu, Z. Guo, Y . Wang, H. Lin, L. Shi, Y . Xie, Z. Xu, et al. Rlinf-vla: A unified and efficient framework for vla+ rl training.arXiv preprint arXiv:2510.06710, 2025
arXiv 2025
-
[41]
P. Intelligence, A. Amin, R. Aniceto, A. Balakrishna, K. Black, K. Conley, G. Connors, J. Darpinian, K. Dhabalia, J. DiCarlo, et al.π ∗ 0.6: a vla that learns from experience.arXiv preprint arXiv:2511.14759, 2025
Pith/arXiv arXiv 2025
-
[42]
Zhang, S
H. Zhang, S. Zhang, J. Jin, Q. Zeng, Y . Qiao, H. Lu, and D. Wang. Balancing signal and variance: Adaptive offline rl post-training for vla flow models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 18755–18763, 2026
2026
-
[43]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[44]
A. Ren, J. Lidard, L. Ankile, A. Simeonov, P. Agrawal, A. Majumdar, B. Burchfiel, H. Dai, and M. Simchowitz. Diffusion policy policy optimization. InInternational Conference on Learning Representations, volume 2025, pages 77288–77329, 2025
2025
-
[45]
H. Jiang and Z. Yang. Adaptive diffusion policy optimization for robotic manipulation.arXiv preprint arXiv:2505.08376, 2025
arXiv 2025
-
[46]
G. Zou, W. Li, H. Wu, Y . Qian, Y . Wang, and H. Wang. D2ppo: Diffusion policy policy opti- mization with dispersive loss. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 18891–18899, 2026
2026
-
[47]
Johannink, S
T. Johannink, S. Bahl, A. Nair, J. Luo, A. Kumar, M. Loskyll, J. A. Ojea, E. Solowjow, and S. Levine. Residual reinforcement learning for robot control. In2019 international conference on robotics and automation (ICRA), pages 6023–6029. IEEE, 2019. 11
2019
-
[48]
M. Alakuijala, G. Dulac-Arnold, J. Mairal, J. Ponce, and C. Schmid. Residual reinforcement learning from demonstrations.arXiv preprint arXiv:2106.08050, 2021
arXiv 2021
-
[49]
K. Fang, W. Liang, Y . Li, J. Zhang, P. Zeng, L. Gao, J. Song, and H. T. Shen. Sim-and- human co-training for data-efficient and generalizable robotic manipulation.arXiv preprint arXiv:2601.19406, 2026
arXiv 2026
-
[50]
Barreiros, A
J. Barreiros, A. Beaulieu, A. Bhat, R. Cory, E. Cousineau, H. Dai, C.-H. Fang, K. Hashimoto, M. Z. Irshad, M. Itkina, et al. A careful examination of large behavior models for multitask dexterous manipulation.Science Robotics, 11(113):eaea6201, 2026
2026
-
[51]
X. Li, K. Hsu, J. Gu, O. Mees, K. Pertsch, H. R. Walke, C. Fu, I. Lunawat, I. Sieh, S. Kir- mani, et al. Evaluating real-world robot manipulation policies in simulation. In8th Annual Conference on Robot Learning, 2024
2024
-
[52]
A. Bronars, Y . Park, and P. Agrawal. Tune to learn: How controller gains shape robot policy learning.arXiv preprint arXiv:2604.02523, 2026
Pith/arXiv arXiv 2026
-
[53]
Y . R. Song, J. Li, R. Fu, D. Murphy, K. Zhou, R. Shiv, Y . Li, H. Xiong, C. E. Owens, Y . Du, et al. Opentouch: Bringing full-hand touch to real-world interaction.arXiv preprint arXiv:2512.16842, 2025
arXiv 2025
-
[54]
Mandlekar, S
A. Mandlekar, S. Nasiriany, B. Wen, I. Akinola, Y . Narang, L. Fan, Y . Zhu, and D. Fox. Mimicgen: A data generation system for scalable robot learning using human demonstrations. In7th Annual Conference on Robot Learning, 2023
2023
-
[55]
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
Pith/arXiv arXiv 2017
-
[56]
V . G. Goecks, G. M. Gremillion, V . J. Lawhern, J. Valasek, and N. R. Waytowich. Integrating behavior cloning and reinforcement learning for improved performance in dense and sparse reward environments.arXiv preprint arXiv:1910.04281, 2019
arXiv 1910
-
[57]
Fujimoto and S
S. Fujimoto and S. S. Gu. A minimalist approach to offline reinforcement learning.Advances in neural information processing systems, 34:20132–20145, 2021
2021
-
[58]
B. Huang and Y . Li. Flexitac: A low-cost, open-source, scalable tactile sensing solution for robotic systems.arXiv preprint arXiv:2604.28156, 2026
Pith/arXiv arXiv 2026
-
[59]
N. Hogan. Impedance control: An approach to manipulation. In1984 American control conference, pages 304–313. IEEE, 1984
1984
-
[60]
B. Katz, J. Di Carlo, and S. Kim. Mini cheetah: A platform for pushing the limits of dynamic quadruped control. In2019 international conference on robotics and automation (ICRA), pages 6295–6301. IEEE, 2019
2019
-
[61]
J. C. Spall. Multivariate stochastic approximation using a simultaneous perturbation gradient approximation.IEEE transactions on automatic control, 37(3):332–341, 1992
1992
-
[62]
C. Yu, Y . Wang, Z. Guo, H. Lin, S. Xu, H. Zang, Q. Zhang, Y . Wu, C. Zhu, J. Hu, Z. Huang, M. Wei, Y . Xie, K. Yang, B. Dai, Z. Xu, J. Du, X. Wang, X. Fu, L. Shi, Z. Liu, K. Chen, W. Liu, G. Liu, B. Li, J. Yang, Z. Yang, G. Dai, and Y . Wang. RLinf: Flexible and efficient large-scale reinforcement learning via macro-to-micro flow transformation.arXiv pre...
arXiv 2025
-
[63]
K. Chen, Z. Liu, T. Zhang, Z. Guo, S. Xu, H. Lin, H. Zang, X. Li, Q. Zhang, Z. Yu, G. Fan, T. Huang, Y . Wang, and C. Yu.π RL: Online RL fine-tuning for flow-based vision-language- action models.arXiv preprint arXiv:2510.25889, 2025. 12 Supplementary Materials Contents A Robot Setup 13 B Real-to-Sim-to-Real 14 B.1 Controller SysID Details. . . . . . . . ....
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.