JSCGC: Joint Source-Channel-Generation Coding for Wireless Generative Communications
Pith reviewed 2026-06-27 06:03 UTC · model grok-4.3
The pith
JSCGC replaces the decoder with a generative model that uses the received signal as a conditioning input to sample from a learned distribution instead of minimizing distortion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
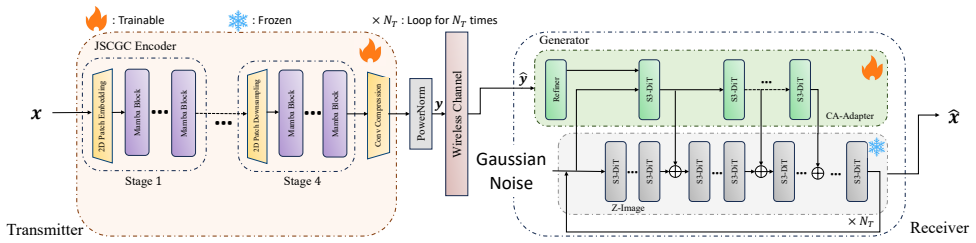
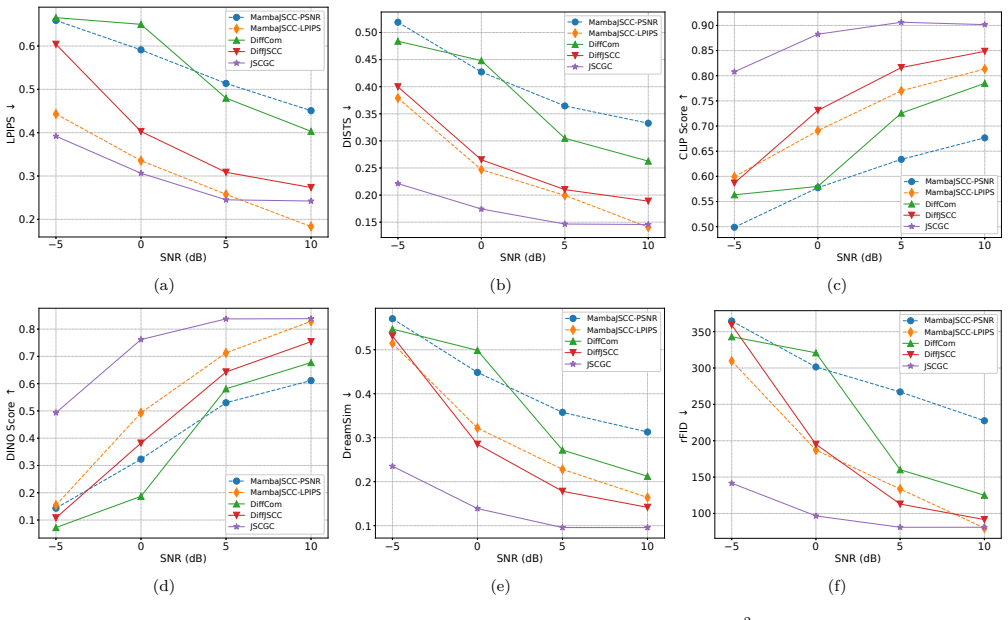
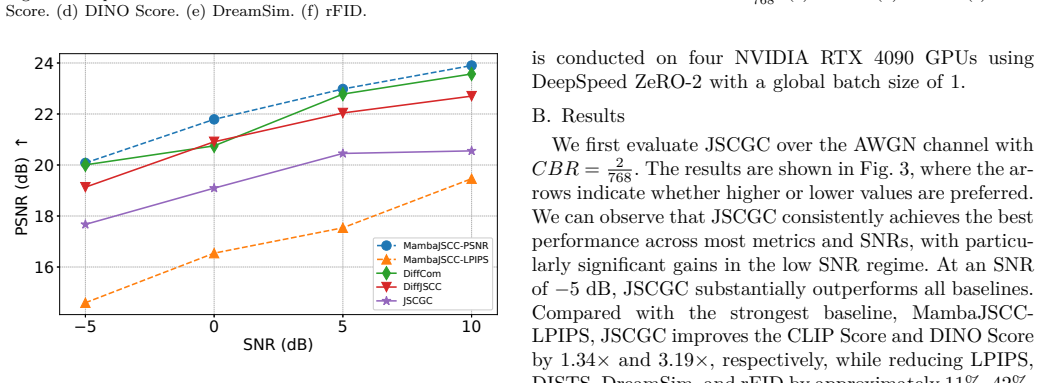
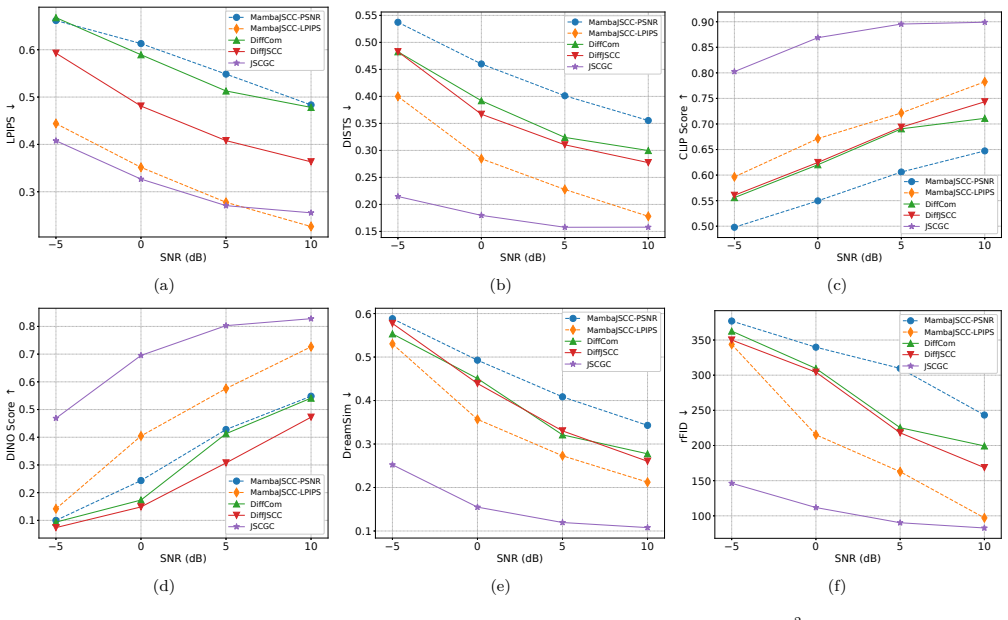
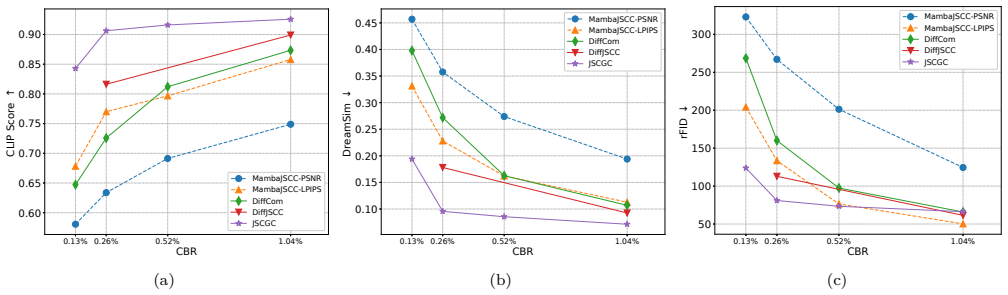
By replacing the conventional decoder with a generative model and treating the received signal as a condition that controls sampling from the learned conditional distribution, the communication task is reformulated from deterministic reconstruction for distortion minimization to controlled generation for mutual information maximization under perceptual constraints. A unified joint training framework and stochastic sampling procedure are developed, with theoretical analysis of learning and inference stages. Experiments on latent-space image transmission show consistent gains in feature-based, semantic-level, and distributional quality metrics across channel conditions, along with an error pat
What carries the argument
The generative model at the receiver that treats the received signal as a conditioning input to control sampling from the learned conditional distribution.
If this is right
- JSCGC produces outputs with improved feature-based, semantic-level, and distributional quality compared to separation-based or JSCC systems.
- Errors appear as semantic inconsistency rather than generic distortion when channel conditions vary.
- The joint training and stochastic sampling framework supports both learning and inference stages with theoretical backing.
- The paradigm applies to latent-space image transmission under diverse wireless channel conditions.
Where Pith is reading between the lines
- Similar conditioning mechanisms could be tested on video or audio streams by swapping the generative backbone.
- Communication system design might shift error evaluation from pixel distortion to semantic consistency measures.
- Receiver-side generation could reduce the need for high-rate feedback links if the conditioning remains robust.
Load-bearing premise
The received signal can serve as an effective conditioning input that allows the generative model to sample outputs aligned with the source under perceptual constraints.
What would settle it
A test in which quality metrics for JSCGC outputs remain no better than those of standard JSCC across multiple channel SNRs, or in which generated images show no measurable semantic alignment with the transmitted source despite using the received signal as condition.
Figures


read the original abstract
Conventional communication systems, including both separation-based coding and learning-based joint source-channel coding (JSCC), are typically designed under Shannon's rate-distortion theory. However, relying on generic distortion metrics fails to capture complex human visual perception, often resulting in blurred or unrealistic reconstructions. In this paper, we propose Joint Source-Channel-Generation Coding (JSCGC), a generative communication paradigm that replaces the conventional decoder with a generative model at the receiver. The received signal is treated as a condition that controls the sampling process into the learned conditional distribution, reformulating communication from deterministic reconstruction for distortion minimization to controlled generation for mutual information maximization under perceptual constraints. Based on this formulation, we develop a unified joint training and efficient stochastic sampling framework, and provide theoretical analysis of its effectiveness in both learning and inference stages. Extensive experiments on latent-space image transmission demonstrate that the JSCGC consistently improves feature-based, semantic-level, and distributional quality across diverse channel conditions, while exhibiting a distinct error behavior characterized by semantic inconsistency rather than distortion.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Joint Source-Channel-Generation Coding (JSCGC), replacing the conventional decoder with a generative model at the receiver. The received signal is treated as a conditioning input to sample from a learned conditional distribution, reformulating communication from deterministic reconstruction under distortion minimization to controlled generation for mutual information maximization under perceptual constraints. It develops a unified joint training and stochastic sampling framework, provides theoretical analysis, and reports experiments on latent-space image transmission showing consistent improvements in feature-based, semantic-level, and distributional quality with a distinct error pattern of semantic inconsistency rather than distortion.
Significance. If the central modeling assumption holds, the work could meaningfully advance wireless generative communications by shifting focus from rate-distortion to perceptual and semantic objectives, with the reported cross-condition improvements and distinct error behavior offering a potentially useful empirical distinction from prior JSCC approaches. The unified framework and theoretical analysis are presented as supporting the claims, though their strength hinges on verification of the MI-maximization property.
major comments (2)
- [theoretical analysis] Abstract and theoretical analysis section: the reformulation claims that treating y as conditioning input achieves mutual information maximization I(X;X̂) under perceptual constraints via standard conditional generative training, but no derivation is supplied showing that ELBO or adversarial objectives attain this objective rather than high-quality yet semantically decoupled samples.
- [formulation] Formulation of the generative communication paradigm: the assumption that the channel-corrupted y functions as a sufficient statistic for controlling sampling from p(x|y) to maximize the stated MI objective is load-bearing for both the theoretical claims and the reported quality gains; if y correlates primarily with low-level channel statistics, the shift from distortion minimization does not follow.
minor comments (2)
- [experiments] Experiments section: include error bars, multiple random seeds, or statistical tests for the quality metric improvements to allow assessment of consistency across channel conditions.
- [framework] Notation and framework description: clarify the precise form of the perceptual constraint and how it is enforced during the joint training and sampling stages.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments, which highlight important aspects of the theoretical formulation. We address each major comment below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [theoretical analysis] Abstract and theoretical analysis section: the reformulation claims that treating y as conditioning input achieves mutual information maximization I(X;X̂) under perceptual constraints via standard conditional generative training, but no derivation is supplied showing that ELBO or adversarial objectives attain this objective rather than high-quality yet semantically decoupled samples.
Authors: We acknowledge that an explicit derivation linking the conditional generative training objectives to the mutual information maximization claim is not present in the current manuscript. In the revised version, we will expand the theoretical analysis section with a step-by-step derivation showing how maximization of the ELBO (or the corresponding adversarial objective) under the joint training framework corresponds to maximizing I(X; ilde{X}) while respecting the perceptual constraints encoded in the generative model. This will clarify why the resulting samples remain semantically coupled to the source rather than decoupled. revision: yes
-
Referee: [formulation] Formulation of the generative communication paradigm: the assumption that the channel-corrupted y functions as a sufficient statistic for controlling sampling from p(x|y) to maximize the stated MI objective is load-bearing for both the theoretical claims and the reported quality gains; if y correlates primarily with low-level channel statistics, the shift from distortion minimization does not follow.
Authors: By the Markov chain structure of the communication system (source X to transmitted signal to channel output y), y is the sufficient statistic for any inference about X at the receiver. The joint training procedure optimizes the generative model to extract and leverage the information in y that is relevant to the perceptual distribution p(x|y), which is what enables the reported gains in semantic and distributional metrics. We will add a short clarifying paragraph in the formulation section that explicitly invokes the data-processing inequality and the role of joint optimization to address the concern about possible low-level correlations. revision: partial
Circularity Check
No circularity: reformulation presented as modeling choice, not reduction to inputs
full rationale
The paper proposes JSCGC by explicitly treating the received signal as a conditioning input for generative sampling, thereby reformulating the objective from distortion minimization to mutual information maximization under perceptual constraints. This is introduced as a new paradigm and modeling decision in the abstract, with no equations, self-citations, or prior results shown that reduce the claim to fitted parameters or self-referential definitions. No load-bearing steps match the enumerated circularity patterns; the derivation chain remains self-contained against external benchmarks and does not exhibit self-definition or renamed predictions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Generative models can learn conditional distributions allowing the received signal to control sampling for mutual information maximization under perceptual constraints.
Reference graph
Works this paper leans on
-
[1]
Joint source-channel-generation coding: From distortion-oriented reconstruction to semantic-consistent gen- eration,
T. Wu, Z. Chen, G. Lu, L. Song, F. Yang, M. Tao, and W. Zhang, “Joint source-channel-generation coding: From distortion-oriented reconstruction to semantic-consistent gen- eration,” Proc. 2026 IEEE International Symposium on Infor- mation Theory Workshops, pp. 1–5, 2026
2026
-
[2]
Coding Theorems for a Discrete Source With a Fidelity Criterion, Institute of Radio Engineers, International Convention Record, vol. 7, 1959
C. E. Shannon, “Coding Theorems for a Discrete Source With a Fidelity Criterion, Institute of Radio Engineers, International Convention Record, vol. 7, 1959. ” in Claude E. Shannon: Collected Papers. IEEE, 1993, pp. 325–350
1959
-
[3]
Deep Joint Source-Channel Coding for Wireless Image Transmission,
E. Bourtsoulatze, D. Burth Kurka, and D. Gündüz, “Deep Joint Source-Channel Coding for Wireless Image Transmission,” IEEE Transactions on Cognitive Communications and Network- ing, vol. 5, no. 3, pp. 567–579, 2019
2019
-
[4]
Nonlinear Transform Source-Channel Coding for Semantic Communications,
J. Dai, S. Wang, K. Tan, Z. Si, X. Qin, K. Niu, and P. Zhang, “Nonlinear Transform Source-Channel Coding for Semantic Communications,” IEEE Journal on Selected Areas in Com- munications, vol. 40, no. 8, pp. 2300–2316, 2022
2022
-
[5]
MambaJSCC: Adaptive Deep Joint Source-Channel Coding With Generalized State Space Model,
T. Wu, Z. Chen, M. Tao, Y. Sun, X. Xu, W. Zhang, and P. Zhang, “MambaJSCC: Adaptive Deep Joint Source-Channel Coding With Generalized State Space Model,” IEEE Trans- actions on Wireless Communications, vol. 25, pp. 9264–9279, 2026
2026
-
[6]
Wireless Deep Video Semantic Transmission,
S. Wang, J. Dai, Z. Liang, K. Niu, Z. Si, C. Dong, X. Qin, and P. Zhang, “Wireless Deep Video Semantic Transmission,” IEEE Journal on Selected Areas in Communications, vol. 41, no. 1, pp. 214–229, 2023
2023
-
[7]
Problems of monetary management: the uk experience,
C. A. Goodhart, “Problems of monetary management: the uk experience,” in Monetary theory and practice: The UK experience. Springer, 1984, pp. 91–121
1984
-
[8]
The unreasonable effectiveness of deep features as a perceptual metric,
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang, “The unreasonable effectiveness of deep features as a perceptual metric,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 586–595
2018
-
[9]
High-fidelity generative image compression,
F. Mentzer, G. D. Toderici, M. Tschannen, and E. Agustsson, “High-fidelity generative image compression,” in Advances in Neural Information Processing Systems, H. Larochelle, M. Ran- zato, R. Hadsell, M. Balcan, and H. Lin, Eds., vol. 33. Curran Associates, Inc., 2020, pp. 11 913–11 924
2020
-
[10]
Reducing artifact generation when using per- ceptual loss for image deblurring of microscopy data for mi- crostructure analysis,
P. Krawczyk, M. Gaertner, A. Jansche, T. Bernthaler, and G. Schneider, “Reducing artifact generation when using per- ceptual loss for image deblurring of microscopy data for mi- crostructure analysis,” Methods in Microscopy, vol. 1, no. 2, pp. 137–150, 2024
2024
-
[11]
Universal rate- distortion-perception representations for lossy compression,
G. Zhang, J. Qian, J. Chen, and A. Khisti, “Universal rate- distortion-perception representations for lossy compression,” IEEE Transactions on Information Theory, vol. 71, no. 11, pp. 8633–8653, 2025
2025
-
[12]
On the rate-distortion-perception function,
J. Chen, L. Yu, J. Wang, W. Shi, Y. Ge, and W. Tong, “On the rate-distortion-perception function,” IEEE Journal on Selected Areas in Information Theory, vol. 3, no. 4, pp. 664–673, 2022
2022
-
[13]
Task-oriented lossy compression with data, perception, and classification con- straints,
Y. Wang, Y. Wu, S. Ma, and Y.-J. Angela Zhang, “Task-oriented lossy compression with data, perception, and classification con- straints,” IEEE Journal on Selected Areas in Communications, vol. 43, no. 7, pp. 2635–2650, 2025
2025
-
[14]
Per- ceptual learned source-channel coding for high-fidelity image semantic transmission,
J. Wang, S. Wang, J. Dai, Z. Si, D. Zhou, and K. Niu, “Per- ceptual learned source-channel coding for high-fidelity image semantic transmission,” in GLOBECOM 2022 - 2022 IEEE Global Communications Conference, 2022, pp. 3959–3964
2022
-
[15]
CDDM: Channel Denoising Diffusion Models for Wireless Semantic Communications,
T. Wu, Z. Chen, D. He, L. Qian, Y. Xu, M. Tao, and W. Zhang, “CDDM: Channel Denoising Diffusion Models for Wireless Semantic Communications,” IEEE Transactions on Wireless Communications, vol. 23, no. 9, pp. 11 168–11 183, 2024
2024
-
[16]
Icdm: Interference cancellation diffusion models for wireless semantic communications,
T. Wu, Z. Chen, D. He, F. Yang, M. Tao, X. Xu, W. Zhang, and P. Zhang, “Icdm: Interference cancellation diffusion models for wireless semantic communications,” IEEE Journal on Selected Areas in Communications, vol. 44, pp. 2528–2543, 2026
2026
-
[17]
Semantics-guided diffusion for deep joint source-channel coding in wireless image transmission,
M. Zhang, H. Wu, G. Zhu, R. Jin, X. Chen, and D. Gündüz, “Semantics-guided diffusion for deep joint source-channel coding in wireless image transmission,” IEEE Transactions on Wireless Communications, vol. 25, pp. 1547–1564, 2026
2026
-
[18]
Diffcom: Channel received signal is a natural condition to guide diffusion posterior sampling,
S. Wang, J. Dai, K. Tan, X. Qin, K. Niu, and P. Zhang, “Diffcom: Channel received signal is a natural condition to guide diffusion posterior sampling,” IEEE Journal on Selected Areas in Communications, vol. 43, no. 7, pp. 2651–2666, 2025
2025
-
[19]
High perceptual quality wireless image delivery with denoising diffusion models,
S. F. Yilmaz, X. Niu, B. Bai, W. Han, L. Deng, and D. Gündüz, “High perceptual quality wireless image delivery with denoising diffusion models,” in IEEE INFOCOM 2024 - IEEE Conference on Computer Communications Workshops (INFOCOM WK- SHPS), 2024, pp. 1–5
2024
-
[20]
Commin: Semantic image communications as an inverse problem with inn- guided diffusion models,
J. Chen, D. You, D. Gündüz, and P. L. Dragotti, “Commin: Semantic image communications as an inverse problem with inn- guided diffusion models,” in ICASSP 2024 - 2024 IEEE Interna- tional Conference on Acoustics, Speech and Signal Processing (ICASSP), 2024, pp. 6675–6679
2024
-
[21]
Diffusion-aided joint source channel coding for high realism wireless image transmission,
M. Yang, B. Liu, B. Wang, and H.-S. Kim, “Diffusion-aided joint source channel coding for high realism wireless image transmission,” IEEE Transactions on Machine Learning in Communications and Networking, vol. 3, pp. 1227–1243, 2025
2025
-
[22]
Flow Matching for Generative Modeling,
Y. Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le, “Flow Matching for Generative Modeling,” in 11th International Conference on Learning Representations, ICLR 2023, 2023
2023
-
[23]
Z-Image: An Efficient Image Generation Foundation Model with Single-Stream Diffusion Transformer
Z.-I. Team, “Z-Image: An Efficient Image Generation Founda- tion Model with Single-Stream Diffusion Transformer,” arXiv preprint arXiv:2511.22699, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Score-Based Generative Modeling through Stochastic Differential Equations,
Y. Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Er- mon, and B. Poole, “Score-Based Generative Modeling through Stochastic Differential Equations,” in International Conference on Learning Representations, 2021
2021
-
[25]
Image quality assessment: Unifying structure and texture similarity,
K. Ding, K. Ma, S. Wang, and E. P. Simoncelli, “Image quality assessment: Unifying structure and texture similarity,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 5, pp. 2567–2581, 2022
2022
-
[26]
CLIPScore: A reference-free evaluation metric for image cap- tioning,
J. Hessel, A. Holtzman, M. Forbes, R. Le Bras, and Y. Choi, “CLIPScore: A reference-free evaluation metric for image cap- tioning,” in Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2021
2021
-
[27]
DINOv2: Learning Robust Visual Features without Supervision
M. Oquab, T. Darcet, T. Moutakanni, H. Vo, M. Szafraniec, V. Khalidov, P. Fernandez, D. Haziza, F. Massa, A. El-Nouby, M. Assran, N. Ballas, W. Galuba, M. Rabbat, V. Sharma, G. Synnaeve, H. Xu, H. Jegou, J. Mairal, P. Labatut, A. Joulin, and P. Bojanowski, “Dinov2: Learning robust visual features without supervision,” arXiv preprint, vol. abs/2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
Dreamsim: Learning new dimensions of human visual similarity using synthetic data,
S. Fu, N. Tamir, S. Sundaram, L. Chai, R. Zhang, T. Dekel, and P. Isola, “Dreamsim: Learning new dimensions of human visual similarity using synthetic data,” in Advances in Neural Information Processing Systems, vol. 36. Curran Associates, Inc., 2023, pp. 50 742–50 768
2023
-
[29]
Rethinking fid: Towards a better evaluation metric for image generation,
S. Jayasumana, S. Ramalingam, A. Veit, D. Glasner, A. Chakrabarti, and S. Kumar, “Rethinking fid: Towards a better evaluation metric for image generation,” arXiv preprint, vol. abs/2401.09603, 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.