Interpreting Neural Combinatorial Optimization via Evolving Programmatic Bottlenecks
Pith reviewed 2026-06-26 17:47 UTC · model grok-4.3
The pith
Evolving Programmatic Bottlenecks distills black-box neural combinatorial optimization models into human-readable program portfolios whose performance largely matches the originals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
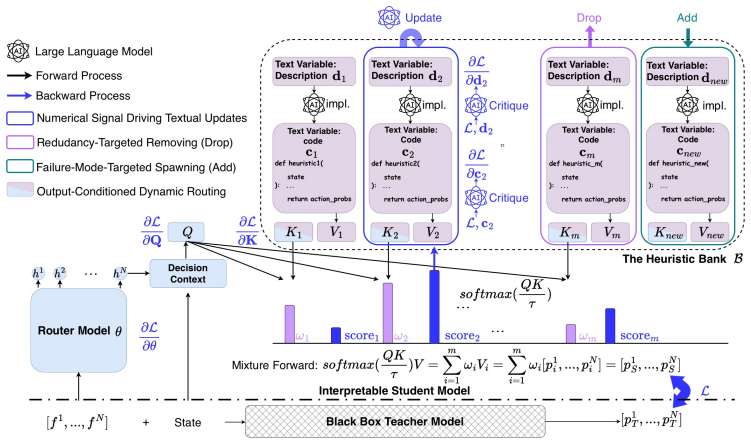
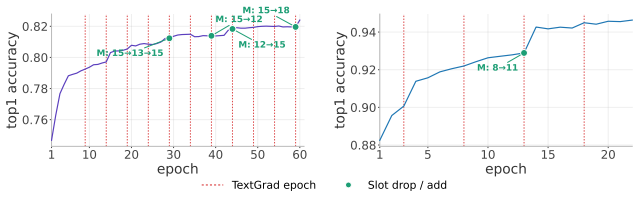
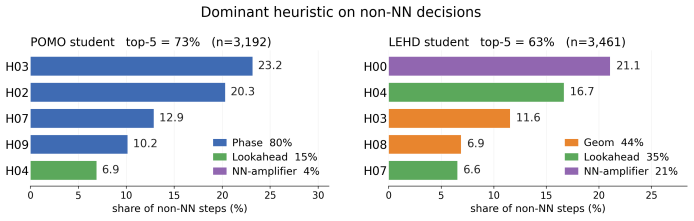
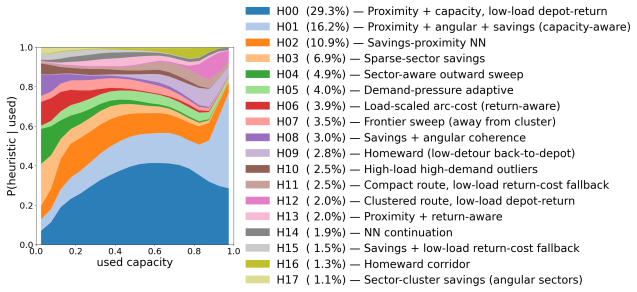
EPB distills black-box NCO models into human-readable program portfolios that largely match original performance. It works by having an LLM evolve a program bank where each program's per-step action distribution serves as the bottleneck. The framework runs in two blocks: one that updates a student router with numerical gradients while revising programs via textual gradients, and another that expands or prunes the bank based on faults. Experiments show the approach applies broadly and that NCO behavior shifts across stages and can be approximated as a composition of classic heuristic variants.
What carries the argument
Evolving Programmatic Bottlenecks (EPB), an iterative LLM-driven process that maintains a bank of programs and treats their per-step action distributions as the dynamic bottleneck for state-dependent NCO decisions.
If this is right
- Distilled program portfolios can be deployed in place of the original neural model while preserving most performance.
- NCO policies can be decomposed into stage-dependent combinations of classic heuristic variants.
- The same distillation process applies to other sequential decision-making models beyond combinatorial optimization.
- Interpretability no longer requires a fixed upfront concept vocabulary for dynamic, state-dependent policies.
Where Pith is reading between the lines
- The evolved programs might be mined for entirely new heuristic building blocks not present in the classic literature.
- Hybrid systems could route easy instances to the readable programs and hard instances to the neural model.
- The textual gradient step in Block I could be extended to other LLM-based program synthesis tasks outside NCO.
Load-bearing premise
That the per-step action distributions from the LLM-evolved programs form a sufficient and faithful representation of the neural model's dynamic decisions even without any pre-defined concept vocabulary.
What would settle it
A direct performance comparison on held-out problem instances where the distilled program portfolios show large gaps versus the original neural model, or fail to reproduce the observed stage-wise shifts in decision patterns.
Figures





read the original abstract
Neural Combinatorial Optimization (NCO) achieves strong performance, yet its black-box nature remains a key roadblock to deployment and scientific diagnosis. Standard interpretability tools, such as Concept Bottleneck Models (CBMs), are ill-equipped for NCO, whose decisions are dynamic, state-dependent, and lack proper concept vocabulary definition. To close this gap, we introduce Evolving Programmatic Bottlenecks (EPB), to our knowledge, the first framework for interpreting NCO policies by distilling black-box NCO models into human-readable program portfolios. EPB employs an LLM to autonomously evolve a bank of programs, where each program's per-step action distribution serves as the bottleneck. EPB works through an iterative framework: Block I fixes program bank capacity and introduces a hybrid textual-numerical gradient descent scheme that couples numerical gradients for student router updates and textual gradients for LLM-based program revision; Block II dynamically adapts bank capacity via fault-targeted expansion and redundancy pruning. Extensive experiments demonstrate EPB's effectiveness and broad applicability, where the distilled program portfolios largely match original performance. EPB also reveals that NCO behavior shifts across optimization stages and can be approximated as a composition of classic heuristic variants. Our work advances interpretable NCO and establishes EPB as a promising tool for interpreting sequential decision-making models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Evolving Programmatic Bottlenecks (EPB), a framework for interpreting black-box neural combinatorial optimization (NCO) policies. It distills them into human-readable program portfolios by using an LLM to evolve a bank of programs whose per-step action distributions act as the bottleneck. The method proceeds iteratively via Block I (hybrid textual-numerical gradient descent that couples router updates with LLM-based program revision) and Block II (dynamic capacity adaptation through fault-targeted expansion and redundancy pruning). Experiments are claimed to show that the resulting portfolios largely recover original NCO performance while revealing that NCO decisions shift across optimization stages and can be approximated as compositions of classic heuristic variants.
Significance. If the experimental claims hold, this would represent a meaningful advance in interpretable sequential decision-making for combinatorial optimization. The approach avoids reliance on pre-defined concept vocabularies, which is a noted limitation of standard concept bottleneck models for dynamic NCO settings. The hybrid gradient scheme and capacity-adaptation mechanism are technically interesting contributions that could generalize beyond NCO.
major comments (2)
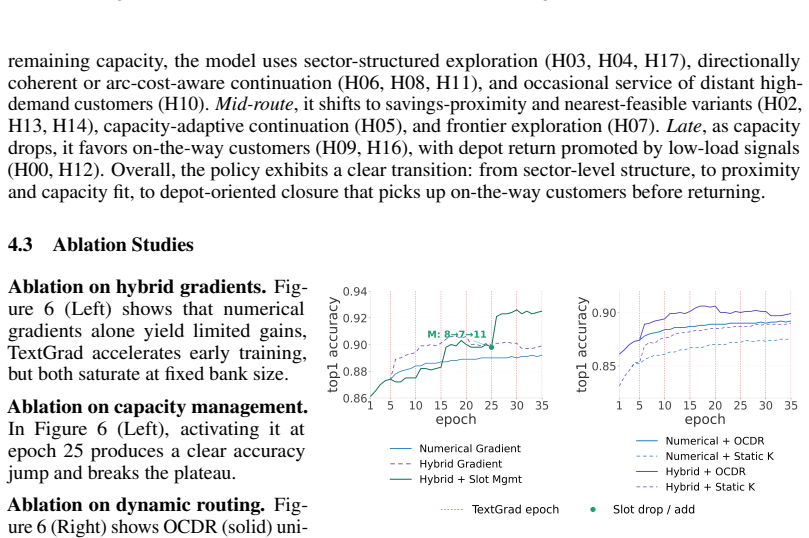
- [Experiments / Results] The central claim that 'the distilled program portfolios largely match original performance' is load-bearing for the contribution. The abstract states this result but provides no quantitative metrics, baselines, or problem instances; the results section must report effect sizes, variance across runs, and comparisons to both the original NCO model and to non-evolved program baselines to substantiate the claim.
- [Method / Interpretation Analysis] The assertion that NCO behavior 'can be approximated as a composition of classic heuristic variants' across stages relies on the faithfulness of the per-step action-distribution bottleneck. Section 4 (or equivalent) should include an explicit faithfulness metric (e.g., KL divergence or action-agreement rate between the original policy and the program portfolio) evaluated at multiple optimization stages; without it the stage-wise composition interpretation remains interpretive rather than quantitatively supported.
minor comments (2)
- [Abstract / Introduction] The abstract uses the phrase 'to our knowledge, the first framework'; this is conventional but should be supported by a brief related-work paragraph that explicitly contrasts EPB with prior program-synthesis or distillation approaches for RL policies.
- [Method] Notation for the 'student router' and 'program bank capacity' is introduced without a compact mathematical definition; adding a short table or boxed notation summary in the method section would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments. We agree that the central claims require stronger quantitative backing to be fully convincing. We address each major comment below and will revise the manuscript to incorporate the requested metrics and analyses.
read point-by-point responses
-
Referee: The central claim that 'the distilled program portfolios largely match original performance' is load-bearing for the contribution. The abstract states this result but provides no quantitative metrics, baselines, or problem instances; the results section must report effect sizes, variance across runs, and comparisons to both the original NCO model and to non-evolved program baselines to substantiate the claim.
Authors: We agree that explicit quantitative support is essential. The manuscript reports performance on standard NCO benchmarks (TSP, CVRP, etc.) but does not sufficiently highlight effect sizes, run-to-run variance, or direct comparisons against non-evolved program baselines. In the revision we will add a new results table (and corresponding text in Section 5) that reports mean optimality gaps with standard deviations over 5–10 independent runs, side-by-side with the original NCO policy and with static (non-evolved) program portfolios. This will make the “largely match” claim quantitatively precise. revision: yes
-
Referee: The assertion that NCO behavior 'can be approximated as a composition of classic heuristic variants' across stages relies on the faithfulness of the per-step action-distribution bottleneck. Section 4 (or equivalent) should include an explicit faithfulness metric (e.g., KL divergence or action-agreement rate between the original policy and the program portfolio) evaluated at multiple optimization stages; without it the stage-wise composition interpretation remains interpretive rather than quantitatively supported.
Authors: We concur that an explicit faithfulness metric is needed to ground the stage-wise interpretation. The current manuscript provides only qualitative stage-dependent observations. We will revise Section 4 to include quantitative faithfulness measurements—specifically mean KL divergence and per-step action-agreement rate—computed between the original NCO policy and the evolved program portfolio at early, middle, and late optimization stages across multiple instances. These metrics will be reported alongside the existing qualitative analysis. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The supplied abstract and description present EPB as an empirical distillation procedure: LLM evolves program bank, per-step action distributions act as bottleneck, hybrid gradients and capacity adaptation are applied iteratively, and experiments measure performance recovery plus stage-wise heuristic composition. No equations, fitted parameters renamed as predictions, self-definitional relations, or load-bearing self-citations appear. Central claims rest on external experimental outcomes rather than reducing to inputs by construction. This matches the default expectation of a non-circular empirical method.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Attention, learn to solve routing problems! In International Conference on Learning Representations, 2019
Wouter Kool, Herke Van Hoof, and Max Welling. Attention, learn to solve routing problems! In International Conference on Learning Representations, 2019
2019
-
[2]
Pomo: Policy optimization with multiple optima for reinforcement learning
Yeong-Dae Kwon, Jinho Choo, Byoungjip Kim, Iljoo Yoon, Youngjune Gwon, and Seungjai Min. Pomo: Policy optimization with multiple optima for reinforcement learning. InAdvances in Neural Information Processing Systems, 2020
2020
-
[3]
Neural combinatorial optimization with heavy decoder: Toward large scale generalization.Advances in Neural Information Processing Systems, 36:8845–8864, 2023
Fu Luo, Xi Lin, Fei Liu, Qingfu Zhang, and Zhenkun Wang. Neural combinatorial optimization with heavy decoder: Toward large scale generalization.Advances in Neural Information Processing Systems, 36:8845–8864, 2023
2023
-
[4]
Visualizing and understanding convolutional networks
Matthew D Zeiler and Rob Fergus. Visualizing and understanding convolutional networks. InEuropean conference on computer vision, pages 818–833. Springer, 2014
2014
-
[5]
Concept bottleneck models
Pang Wei Koh, Thao Nguyen, Yew Siang Tang, Stephen Mussmann, Emma Pierson, Been Kim, and Percy Liang. Concept bottleneck models. InInternational conference on machine learning, pages 5338–5348. PMLR, 2020
2020
-
[6]
Learning to intervene on concept bottlenecks.arXiv preprint arXiv:2308.13453, 2023
David Steinmann, Wolfgang Stammer, Felix Friedrich, and Kristian Kersting. Learning to intervene on concept bottlenecks.arXiv preprint arXiv:2308.13453, 2023
-
[7]
Discover and cure: Concept-aware mitigation of spurious correlation
Shirley Wu, Mert Yuksekgonul, Linjun Zhang, and James Zou. Discover and cure: Concept-aware mitigation of spurious correlation. InInternational Conference on Machine Learning, pages 37765–37786. PMLR, 2023
2023
-
[8]
TextGrad: Automatic "Differentiation" via Text
Mert Yuksekgonul, Federico Bianchi, Joseph Boen, Sheng Liu, Zhi Huang, Carlos Guestrin, and James Zou. Textgrad: Automatic" differentiation" via text.arXiv preprint arXiv:2406.07496, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Difusco: Graph-based diffusion solvers for combinatorial optimization
Zhiqing Sun and Yiming Yang. Difusco: Graph-based diffusion solvers for combinatorial optimization. Advances in neural information processing systems, 36:3706–3731, 2023
2023
-
[10]
Neural Combinatorial Optimization with Reinforcement Learning
Irwan Bello, Hieu Pham, Quoc V Le, Mohammad Norouzi, and Samy Bengio. Neural combinatorial optimization with reinforcement learning.arXiv preprint arXiv:1611.09940, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[11]
Reinforcement learning for solving the vehicle routing problem.Advances in neural information processing systems, 31, 2018
Mohammadreza Nazari, Afshin Oroojlooy, Lawrence Snyder, and Martin Takác. Reinforcement learning for solving the vehicle routing problem.Advances in neural information processing systems, 31, 2018
2018
-
[12]
Pointer networks
Oriol Vinyals, Meire Fortunato, and Navdeep Jaitly. Pointer networks. InAdvances in Neural Information Processing Systems, 2015
2015
-
[13]
Simulation-guided beam search for neural combinatorial optimization.Advances in Neural Information Processing Systems, 35:8760–8772, 2022
Jinho Choo, Yeong-Dae Kwon, Jihoon Kim, Jeongwoo Jae, André Hottung, Kevin Tierney, and Youngjune Gwon. Simulation-guided beam search for neural combinatorial optimization.Advances in Neural Information Processing Systems, 35:8760–8772, 2022
2022
-
[14]
Efficient active search for combinatorial optimization problems
André Hottung, Yeong-Dae Kwon, and Kevin Tierney. Efficient active search for combinatorial optimization problems. InInternational Conference on Learning Representations, 2022
2022
-
[15]
Learning to iteratively solve routing problems with dual-aspect collaborative transformer
Yining Ma, Jingwen Li, Zhiguang Cao, Wen Song, Le Zhang, Zhenghua Chen, and Jing Tang. Learning to iteratively solve routing problems with dual-aspect collaborative transformer. InAdvances in Neural Information Processing Systems, volume 34, pages 11096–11107, 2021
2021
-
[16]
Learning improvement heuristics for solving routing problems.IEEE Transactions on Neural Networks and Learning Systems, 2021
Yaoxin Wu, Wen Song, Zhiguang Cao, Jie Zhang, and Andrew Lim. Learning improvement heuristics for solving routing problems.IEEE Transactions on Neural Networks and Learning Systems, 2021
2021
-
[17]
Cai, James Wexler, Fernanda Viegas, and Rory Sayres
Been Kim, Martin Wattenberg, Justin Gilmer, Carrie J. Cai, James Wexler, Fernanda Viegas, and Rory Sayres. Interpretability beyond feature attribution: Quantitative testing with concept activation vectors (tcav). InInternational Conference on Machine Learning, 2018
2018
-
[18]
Zou, and Been Kim
Amirata Ghorbani, James Wexler, James Y . Zou, and Been Kim. Towards automatic concept-based explanations. InAdvances in Neural Information Processing Systems, 2019. 11
2019
-
[19]
arXiv preprint arXiv:2205.15480 (2022) 1, 3, 4
Mert Yuksekgonul, Maggie Wang, and James Zou. Post-hoc concept bottleneck models.arXiv preprint arXiv:2205.15480, 2022
-
[20]
Vlg-cbm: Training concept bottleneck models with vision-language guidance
Divyansh Srivastava, Ge Yan, and Tsui-Wei Weng. Vlg-cbm: Training concept bottleneck models with vision-language guidance. InAdvances in Neural Information Processing Systems, 2024
2024
-
[21]
Interpretable generative models through post-hoc concept bottlenecks
Akshay Kulkarni, Ge Yan, Chung-En Sun, Tuomas Oikarinen, and Tsui-Wei Weng. Interpretable generative models through post-hoc concept bottlenecks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8162–8171, 2025
2025
-
[22]
Concept bottleneck large language models
Chung-En Sun, Tuomas Oikarinen, Berk Ustun, and Tsui-Wei Weng. Concept bottleneck large language models. InInternational Conference on Learning Representations, 2025
2025
-
[23]
Probing neural combinatorial optimization models.arXiv preprint arXiv:2510.22131, 2025
Zhiqin Zhang, Yining Ma, Zhiguang Cao, and Hoong Chuin Lau. Probing neural combinatorial optimization models.arXiv preprint arXiv:2510.22131, 2025
-
[24]
Competition-level code generation with alphacode
Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Rémi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, et al. Competition-level code generation with alphacode. Science, 378(6624):1092–1097, 2022
2022
-
[25]
Mathematical discoveries from program search with large language models.Nature, 625(7995):468–475, 2024
Bernardino Romera-Paredes, Mohammadamin Barekatain, Alexander Novikov, Matej Balog, M Pawan Kumar, Emilien Dupont, Francisco JR Ruiz, Jordan S Ellenberg, Pengming Wang, Omar Fawzi, et al. Mathematical discoveries from program search with large language models.Nature, 625(7995):468–475, 2024
2024
-
[26]
Evolution of heuristics: Towards efficient automatic algorithm design using large language model,
Fei Liu, Xialiang Tong, Mingxuan Yuan, Xi Lin, Fu Luo, Zhenkun Wang, Zhichao Lu, and Qingfu Zhang. Evolution of heuristics: Towards efficient automatic algorithm design using large language model.arXiv preprint arXiv:2401.02051, 2024
-
[27]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[28]
Program Synthesis with Large Language Models
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and Charles Sutton. Program synthesis with large language models.arXiv preprint arXiv:2108.07732, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[29]
Reflexion: Language agents with verbal reinforcement learning.Advances in neural information processing systems, 36:8634–8652, 2023
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning.Advances in neural information processing systems, 36:8634–8652, 2023
2023
-
[30]
Tree of thoughts: Deliberate problem solving with large language models.Advances in neural information processing systems, 36:11809–11822, 2023
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models.Advances in neural information processing systems, 36:11809–11822, 2023
2023
-
[31]
Eric J Michaud, Isaac Liao, Vedang Lad, Ziming Liu, Anish Mudide, Chloe Loughridge, Zifan Carl Guo, Tara Rezaei Kheirkhah, Mateja Vukeli´c, and Max Tegmark. Opening the ai black box: program synthesis via mechanistic interpretability.arXiv preprint arXiv:2402.05110, 2024
-
[32]
Dweep Trivedi, Jesse Zhang, Shao-Hua Sun, and Joseph J. Lim. Learning to synthesize programs as interpretable and generalizable policies. InAdvances in Neural Information Processing Systems, 2021
2021
-
[33]
Interpretable and explainable logical policies via neurally guided symbolic abstraction
Quentin Delfosse, Hikaru Shindo, Devendra Dhami, and Kristian Kersting. Interpretable and explainable logical policies via neurally guided symbolic abstraction. InAdvances in Neural Information Processing Systems, 2023
2023
-
[34]
Atticus Geiger, Duligur Ibeling, Amir Zur, Maheep Chaudhary, Sonakshi Chauhan, Jing Huang, Aryaman Arora, Zhengxuan Wu, Noah Goodman, Christopher Potts, and Thomas Icard. Causal abstraction: A theoretical foundation for mechanistic interpretability.arXiv preprint arXiv:2301.04709, 2023
-
[35]
thoughts
Abhinav Verma, Vijay Murali, Rishabh Singh, Pushmeet Kohli, and Swarat Chaudhuri. Programmatically interpretable reinforcement learning. InInternational Conference on Machine Learning, 2018. 12 Interpreting Neural Combinatorial Optimization via Evolving Programmatic Bottlenecks (Appendix) A Related Work 14 B TSP and CVRP 14 C Teacher/Student NCO model Str...
2018
-
[36]
After softmax with the training temperature, your output should look near-one-hot in clear-cut situations –- not a smoothly graded distribution
**Output sharp, decisive scores.** The winning candidate's score should be substantially higher than the runner-up. After softmax with the training temperature, your output should look near-one-hot in clear-cut situations –- not a smoothly graded distribution. A decisive winner gap matters more than carefully shaping the long tail
-
[37]
score = -distance + lookahead_bonus
**Top-1 is what matters; top-2 is a soft backup; the rest is irrelevant.** Don't waste complexity on shaping the bottom of the distribution. A simple "score = -distance + lookahead_bonus" can outperform an 8-signal weighted mixture if the simpler one consistently picks the right top-1. Heuristics are evaluated on: (a) whether their argmax matches the teac...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.