SpatialSV: Internalizing Interpretable 3D Spatial Awareness in MLLMs via Task-Oriented Visual Supervision
Pith reviewed 2026-06-26 17:57 UTC · model grok-4.3
The pith
SpatialSV internalizes 3D spatial awareness in MLLMs by compelling active lifting of 2D features into explicit depth maps, poses, and point clouds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
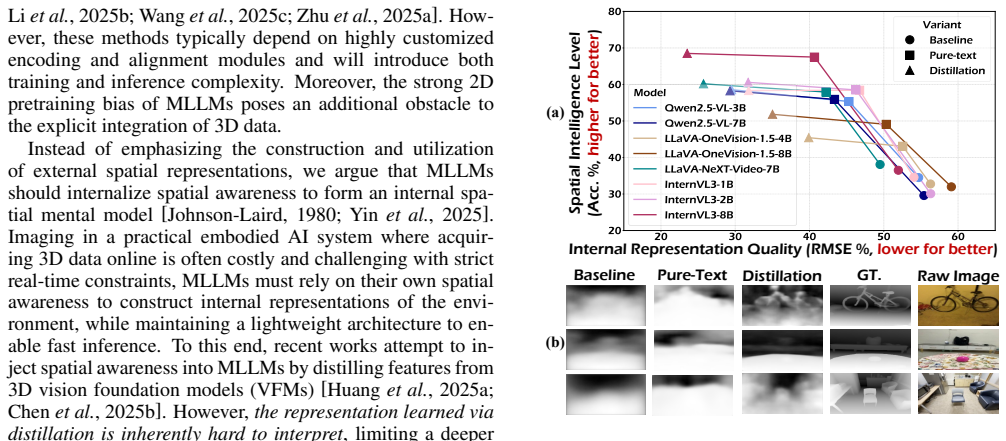
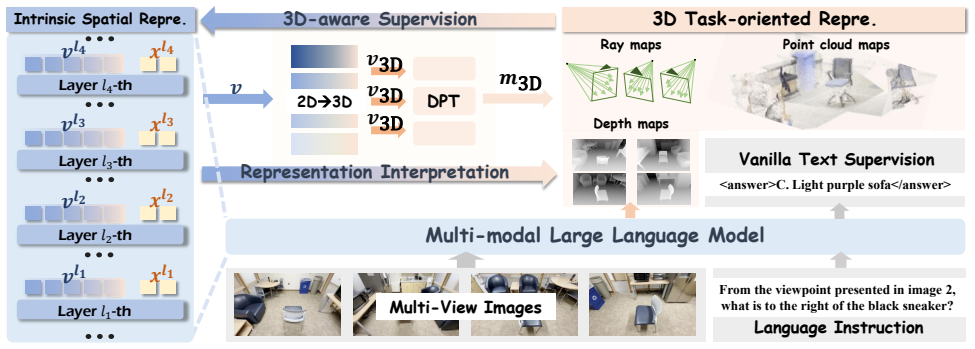
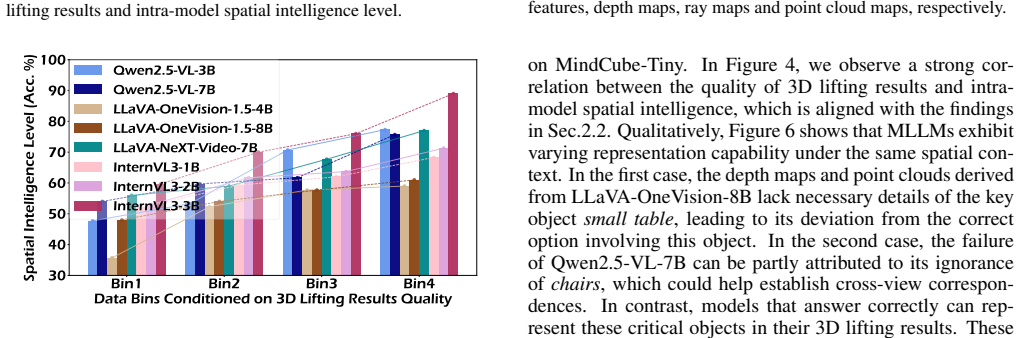
SpatialSV employs task-oriented visual supervision that compels the model to actively lift its 2D visual features into explicit 3D representations, including depth maps, camera poses, and point clouds. This process internalizes robust 3D spatial awareness within MLLMs while providing inherent interpretability, as the resulting 3D reconstructions serve as an intuitive proxy for visualizing and diagnosing the quality of the model's intrinsic spatial knowledge. Experiments show effectiveness across models and benchmarks, with strong generalization in semi-supervised settings.
What carries the argument
Task-oriented visual supervision that forces active 2D-to-3D lifting of visual features into explicit representations such as depth maps and point clouds.
If this is right
- Enhances spatial intelligence in MLLMs without external tools at inference time.
- Offers inherent interpretability through generated 3D reconstructions.
- Demonstrates effectiveness on multiple models and benchmarks.
- Generalizes well to semi-supervised learning with unlabeled data.
Where Pith is reading between the lines
- The explicit 3D outputs could allow users to verify if the model correctly understands scene geometry before relying on it for planning.
- Applying the same lifting approach to video sequences might add temporal consistency to the spatial representations.
- This method might reduce the need for separate 3D reconstruction modules in vision-language systems by baking the capability into the core model.
Load-bearing premise
The 2D-to-3D lifting process produces reconstructions that serve as an intuitive and faithful proxy for diagnosing the quality of the model's intrinsic spatial knowledge.
What would settle it
If the quality of the generated 3D reconstructions shows no correlation with the model's accuracy on spatial reasoning benchmarks, or if adding the supervision fails to improve performance on unseen 3D tasks.
Figures





read the original abstract
Unlocking the spatial intelligence of multimodal large language model (MLLMs) is crucial for understanding and interacting with the 3D world. Prevailing approaches typically inject spatial priors via external tools, which impose significant inference overhead, or rely on latent feature distillation, which remains uninterpretable and lacks fine-grained geometric constraints. To address these issues, we propose SpatialSV, a framework designed to internalize robust 3D spatial awareness within MLLMs while simultaneously offering inherent interpretability. Deviating from passive feature imitation, SpatialSV employs task-oriented visual supervision, compelling the model to actively lift its 2D visual features into explicit 3D representations, including depth maps, camera poses, and point clouds. Crucially, this 2D-to-3D lifting process provides a transparent window into the model's representations: the resulting 3D reconstructions serve as an intuitive proxy for visualizing and diagnosing the quality of the model's intrinsic spatial knowledge. Extensive experiments across multiple models and benchmarks demonstrate the effectiveness of SpatialSV in enhancing and interpreting MLLMs' spatial intelligence. Furthermore, the framework exhibits strong generalization in semi-supervised settings, validating its potential to leverage unlabeled visual data for scalable, interpretable spatial representation learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SpatialSV, a framework to internalize 3D spatial awareness in MLLMs via task-oriented visual supervision that actively lifts 2D visual features into explicit 3D representations (depth maps, camera poses, point clouds). This is positioned as providing inherent interpretability through the reconstructions as a diagnostic proxy, avoiding external tools at inference and latent-only distillation. The manuscript claims extensive experiments across models and benchmarks demonstrate effectiveness, with strong generalization in semi-supervised settings.
Significance. If the empirical claims hold, the work could meaningfully advance MLLM spatial capabilities by combining explicit geometric supervision with interpretability, potentially reducing inference costs compared to tool-augmented approaches while enabling diagnosis of internal representations. The semi-supervised generalization aspect is a notable strength for scalable learning from unlabeled data.
minor comments (1)
- Abstract: while the high-level claims are clear, including one or two key quantitative metrics (e.g., accuracy gains on a primary benchmark) would strengthen the summary of experimental results without lengthening the abstract excessively.
Simulated Author's Rebuttal
We thank the referee for the positive summary of our work and the recommendation of minor revision. The provided summary accurately captures the core contributions of SpatialSV.
Circularity Check
No significant circularity
full rationale
The provided abstract and description outline a training framework that uses task-oriented visual supervision to force explicit 2D-to-3D lifting (depth maps, poses, point clouds) inside MLLMs. No equations, parameter-fitting steps, self-citations, or uniqueness theorems are referenced. The central claim is an empirical training procedure whose outputs are evaluated on external benchmarks; nothing reduces the claimed internalization or interpretability result to a quantity defined by the method itself. This is the common case of a self-contained empirical proposal with no load-bearing derivation chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
[Baiet al., 2025 ] Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shi- jie Wang, Jun Tang, et al. Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923,
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
[Chenet al., 2025b ] Zhangquan Chen, Manyuan Zhang, Xinlei Yu, Xufang Luo, Mingze Sun, Zihao Pan, Yan Feng, Peng Pei, Xunliang Cai, and Ruqi Huang. Think with 3d: Geometric imagination grounded spatial reasoning from limited views.arXiv preprint arXiv:2510.18632,
-
[3]
Spatialrgpt: Grounded spatial rea- soning in vision-language models.Advances in Neural In- formation Processing Systems, 37:135062–135093,
[Chenget al., 2024 ] An-Chieh Cheng, Hongxu Yin, Yang Fu, Qiushan Guo, Ruihan Yang, Jan Kautz, Xiaolong Wang, and Sifei Liu. Spatialrgpt: Grounded spatial rea- soning in vision-language models.Advances in Neural In- formation Processing Systems, 37:135062–135093,
2024
-
[4]
Probing the 3d aware- ness of visual foundation models
[El Bananiet al., 2024 ] Mohamed El Banani, Amit Raj, Kevis-Kokitsi Maninis, Abhishek Kar, Yuanzhen Li, Michael Rubinstein, Deqing Sun, Leonidas Guibas, Justin Johnson, and Varun Jampani. Probing the 3d aware- ness of visual foundation models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21795–21806,
2024
-
[5]
arXiv preprint arXiv:2509.06266 (2025) 2
[Gholamiet al., 2025 ] Mohsen Gholami, Ahmad Rezaei, Zhou Weimin, Sitong Mao, Shunbo Zhou, Yong Zhang, and Mohammad Akbari. Spatial reasoning with vision- language models in ego-centric multi-view scenes.arXiv preprint arXiv:2509.06266,
-
[6]
arXiv preprint arXiv:2505.22657 (2025)
[Huet al., 2025 ] Wenbo Hu, Yining Hong, Yanjun Wang, Leison Gao, Zibu Wei, Xingcheng Yao, Nanyun Peng, Yonatan Bitton, Idan Szpektor, and Kai-Wei Chang. 3dllm-mem: Long-term spatial-temporal memory for embodied 3d large language model.arXiv preprint arXiv:2505.22657,
-
[7]
arXiv preprint arXiv:2506.01946 (2025)
[Huanget al., 2025a ] Xiaohu Huang, Jingjing Wu, Qunyi Xie, and Kai Han. Mllms need 3d-aware representa- tion supervision for scene understanding.arXiv preprint arXiv:2506.01946,
-
[8]
Mental mod- els in cognitive science.Cognitive science, 4(1):71–115,
[Johnson-Laird, 1980] Philip N Johnson-Laird. Mental mod- els in cognitive science.Cognitive science, 4(1):71–115,
1980
-
[9]
[Johnson-Laird, 1983] Philip Nicholas Johnson-Laird.Men- tal models: Towards a cognitive science of language, in- ference, and consciousness. Number
1983
-
[10]
LLaVA-OneVision: Easy Visual Task Transfer
[Liet al., 2024a ] Bo Li, Yuanhan Zhang, Dong Guo, Ren- rui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Topviewrs: Vision-language models as top-view spatial reasoners
[Liet al., 2024b ] Chengzu Li, Caiqi Zhang, Han Zhou, Nigel Collier, Anna Korhonen, and Ivan Vuli´c. Topviewrs: Vision-language models as top-view spatial reasoners. arXiv preprint arXiv:2406.02537,
-
[12]
arXiv preprint arXiv:2505.21500 (2025), ��������������������������������4
[Liet al., 2025a ] Dingming Li, Hongxing Li, Zixuan Wang, Yuchen Yan, Hang Zhang, Siqi Chen, Guiyang Hou, Shengpei Jiang, Wenqi Zhang, Yongliang Shen, et al. Viewspatial-bench: Evaluating multi-perspective spatial localization in vision-language models.arXiv preprint arXiv:2505.21500,
-
[13]
Spatial forcing: Implicit spatial representation alignment for vision-language-action model,
[Liet al., 2025b ] Fuhao Li, Wenxuan Song, Han Zhao, Jingbo Wang, Pengxiang Ding, Donglin Wang, Long Zeng, and Haoang Li. Spatial forcing: Implicit spatial rep- resentation alignment for vision-language-action model. arXiv preprint arXiv:2510.12276,
-
[14]
[Liet al., 2025c ] Hongxing Li, Dingming Li, Zixuan Wang, Yuchen Yan, Hang Wu, Wenqi Zhang, Yongliang Shen, Weiming Lu, Jun Xiao, and Yueting Zhuang. Spatiallad- der: Progressive training for spatial reasoning in vision- language models.arXiv preprint arXiv:2510.08531,
-
[15]
[Liet al., 2025d ] Pengteng Li, Pinhao Song, Wuyang Li, Weiyu Guo, Huizai Yao, Yijie Xu, Dugang Liu, and Hui Xiong. See&trek: Training-free spatial prompting for multimodal large language model.arXiv preprint arXiv:2509.16087,
-
[16]
Depth Anything 3: Recovering the Visual Space from Any Views
[Linet al., 2025 ] Haotong Lin, Sili Chen, Junhao Liew, Donny Y Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647,
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Mmbench: Is your multi-modal model an all-around player? InEuropean conference on computer vision, pages 216–233
[Liuet al., 2024 ] Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. Mmbench: Is your multi-modal model an all-around player? InEuropean conference on computer vision, pages 216–233. Springer,
2024
-
[18]
Ssr: Enhancing depth perception in vision- language models via rationale-guided spatial reasoning
[Liuet al., 2025a ] Yang Liu, Ming Ma, Xiaomin Yu, Pengx- iang Ding, Han Zhao, Mingyang Sun, Siteng Huang, and Donglin Wang. Ssr: Enhancing depth perception in vision- language models via rationale-guided spatial reasoning. arXiv preprint arXiv:2505.12448,
-
[19]
Abstract 3D Perception for Spatial Intelligence in Vision-Language Models
[Liuet al., 2025b ] Yifan Liu, Fangneng Zhan, Kaichen Zhou, Yilun Du, Paul Pu Liang, and Hanspeter Pfister. Abstract 3d perception for spatial intelligence in vision- language models.arXiv preprint arXiv:2511.10946,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
3dsrbench: A comprehensive 3d spatial reason- ing benchmark
[Maet al., 2025 ] Wufei Ma, Haoyu Chen, Guofeng Zhang, Yu-Cheng Chou, Jieneng Chen, Celso de Melo, and Alan Yuille. 3dsrbench: A comprehensive 3d spatial reason- ing benchmark. InProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision, pages 6924–6934,
2025
-
[21]
arXiv preprint arXiv:2501.01428 (2025)
[Qiet al., 2025 ] Zhangyang Qi, Zhixiong Zhang, Ye Fang, Jiaqi Wang, and Hengshuang Zhao. Gpt4scene: Under- stand 3d scenes from videos with vision-language models. arXiv preprint arXiv:2501.01428,
-
[22]
Vision transformers for dense prediction
[Ranftlet al., 2021 ] Ren´e Ranftl, Alexey Bochkovskiy, and Vladlen Koltun. Vision transformers for dense prediction. InProceedings of the IEEE/CVF international conference on computer vision, pages 12179–12188,
2021
-
[23]
Ro- bospatial: Teaching spatial understanding to 2d and 3d vision-language models for robotics
[Songet al., 2025 ] Chan Hee Song, Valts Blukis, Jonathan Tremblay, Stephen Tyree, Yu Su, and Stan Birchfield. Ro- bospatial: Teaching spatial understanding to 2d and 3d vision-language models for robotics. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 15768–15780,
2025
-
[24]
Letp: Coupling attention localization and cognitive reasoning for ego-centric multi-task driving scene perception
[Tanget al., 2026 ] Jiayu Tang, Yuchen Zhou, Chen Xiong, and Chao Gou. Letp: Coupling attention localization and cognitive reasoning for ego-centric multi-task driving scene perception. InICASSP 2026-2026 IEEE Interna- tional Conference on Acoustics, Speech and Signal Pro- cessing (ICASSP), pages 19797–19801. IEEE,
2026
-
[25]
arXiv preprint arXiv:2504.01901 (2025)
[Wanget al., 2025a ] Haochen Wang, Yucheng Zhao, Tian- cai Wang, Haoqiang Fan, Xiangyu Zhang, and Zhaoxi- ang Zhang. Ross3d: Reconstructive visual instruction tun- ing with 3d-awareness.arXiv preprint arXiv:2504.01901,
-
[26]
Pointllm: Empowering large language models to understand point clouds
[Xuet al., 2024 ] Runsen Xu, Xiaolong Wang, Tai Wang, Yilun Chen, Jiangmiao Pang, and Dahua Lin. Pointllm: Empowering large language models to understand point clouds. InEuropean Conference on Computer Vision, pages 131–147. Springer,
2024
-
[27]
[Yanget al., 2025b ] Yuncong Yang, Jiageng Liu, Zheyuan Zhang, Siyuan Zhou, Reuben Tan, Jianwei Yang, Yilun Du, and Chuang Gan. Mindjourney: Test-time scaling with world models for spatial reasoning.arXiv preprint arXiv:2507.12508,
-
[28]
Spatial mental modeling from limited views
[Yinet al., 2025 ] Baiqiao Yin, Qineng Wang, Pingyue Zhang, Jianshu Zhang, Kangrui Wang, Zihan Wang, Jieyu Zhang, Keshigeyan Chandrasegaran, Han Liu, Ranjay Kr- ishna, et al. Spatial mental modeling from limited views. InStructural Priors for Vision Workshop at ICCV’25,
2025
-
[29]
LLaVA-Video: Video Instruction Tuning With Synthetic Data
[Zhanget al., 2024 ] Yuanhan Zhang, Jinming Wu, Wei Li, Bo Li, Zejun Ma, Ziwei Liu, and Chunyuan Li. Video instruction tuning with synthetic data.arXiv preprint arXiv:2410.02713,
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
[Zhanget al., 2025 ] Haoyu Zhang, Meng Liu, Zaijing Li, Haokun Wen, Weili Guan, Yaowei Wang, and Liqiang Nie. Spatial understanding from videos: Structured prompts meet simulation data.arXiv preprint arXiv:2506.03642,
-
[31]
Video-3d llm: Learning position-aware video rep- resentation for 3d scene understanding
[Zhenget al., 2025 ] Duo Zheng, Shijia Huang, and Liwei Wang. Video-3d llm: Learning position-aware video rep- resentation for 3d scene understanding. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 8995–9006,
2025
-
[32]
Learning from easy to hard pairs: Multi- step reasoning network for human-object interaction de- tection
[Zhouet al., 2023 ] Yuchen Zhou, Guang Tan, Mengtang Li, and Chao Gou. Learning from easy to hard pairs: Multi- step reasoning network for human-object interaction de- tection. InProceedings of the 31st ACM International Conference on Multimedia, pages 4368–4377,
2023
-
[33]
Where, what, why: Towards ex- plainable driver attention prediction
[Zhouet al., 2025 ] Yuchen Zhou, Jiayu Tang, Xiaoyan Xiao, Yueyao Lin, Linkai Liu, Zipeng Guo, Hao Fei, Xiaobo Xia, and Chao Gou. Where, what, why: Towards ex- plainable driver attention prediction. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2675–2685,
2025
-
[34]
Logic unseen: Revealing the logical blindspots of vision-language models
[Zhouet al., 2026 ] Yuchen Zhou, Jiayu Tang, Shuo Yang, Xiaoyan Xiao, Yuqin Dai, Wenhao Yang, Chao Gou, Xi- aobo Xia, and Tat-Seng Chua. Logic unseen: Revealing the logical blindspots of vision-language models. InPro- ceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 29062–29070,
2026
-
[35]
[Zhuet al., 2025b ] Fangrui Zhu, Hanhui Wang, Yiming Xie, Jing Gu, Tianye Ding, Jianwei Yang, and Huaizu Jiang. Struct2d: A perception-guided framework for spatial reasoning in large multimodal models.arXiv preprint arXiv:2506.04220,
-
[36]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
[Zhuet al., 2025c ] Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring ad- vanced training and test-time recipes for open-source mul- timodal models.arXiv preprint arXiv:2504.10479,
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
[Zhuet al., 2025d ] Nannan Zhu, Yonghao Dong, Teng Wang, Xueqian Li, Shengjun Deng, Yijia Wang, Zheng Hong, Tiantian Geng, Guo Niu, Hanyan Huang, et al. Cvbench: Benchmarking cross-video syner- gies for complex multimodal reasoning.arXiv preprint arXiv:2508.19542, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.