Citation Discipline in Spec-Driven Development: A Cross-Model Empirical Study of Output Determinism and Automated Hallucination Detection in LLM-Generated Code
Pith reviewed 2026-07-01 06:37 UTC · model grok-4.3
The pith
Requiring per-line citations in spec-driven LLM code generation trades higher output determinism for the ability to automatically detect hallucinations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
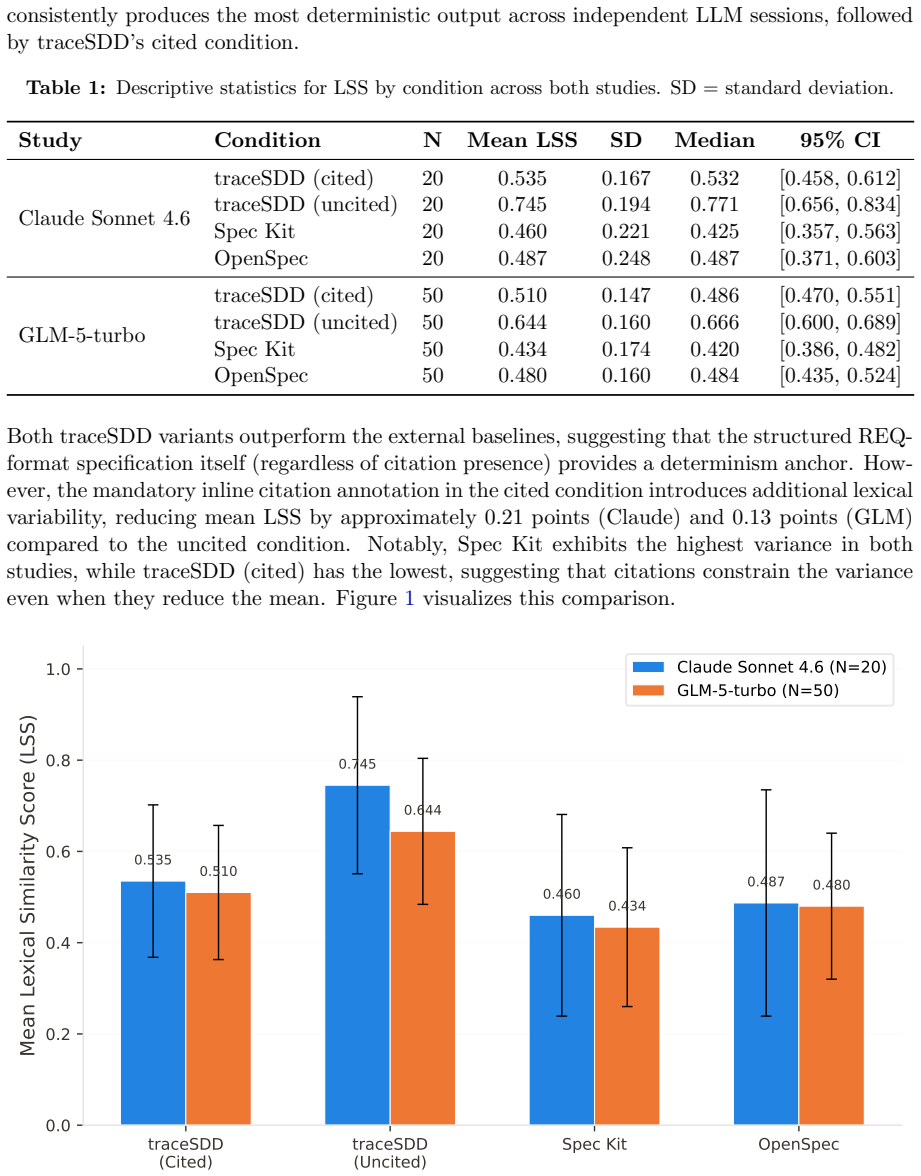
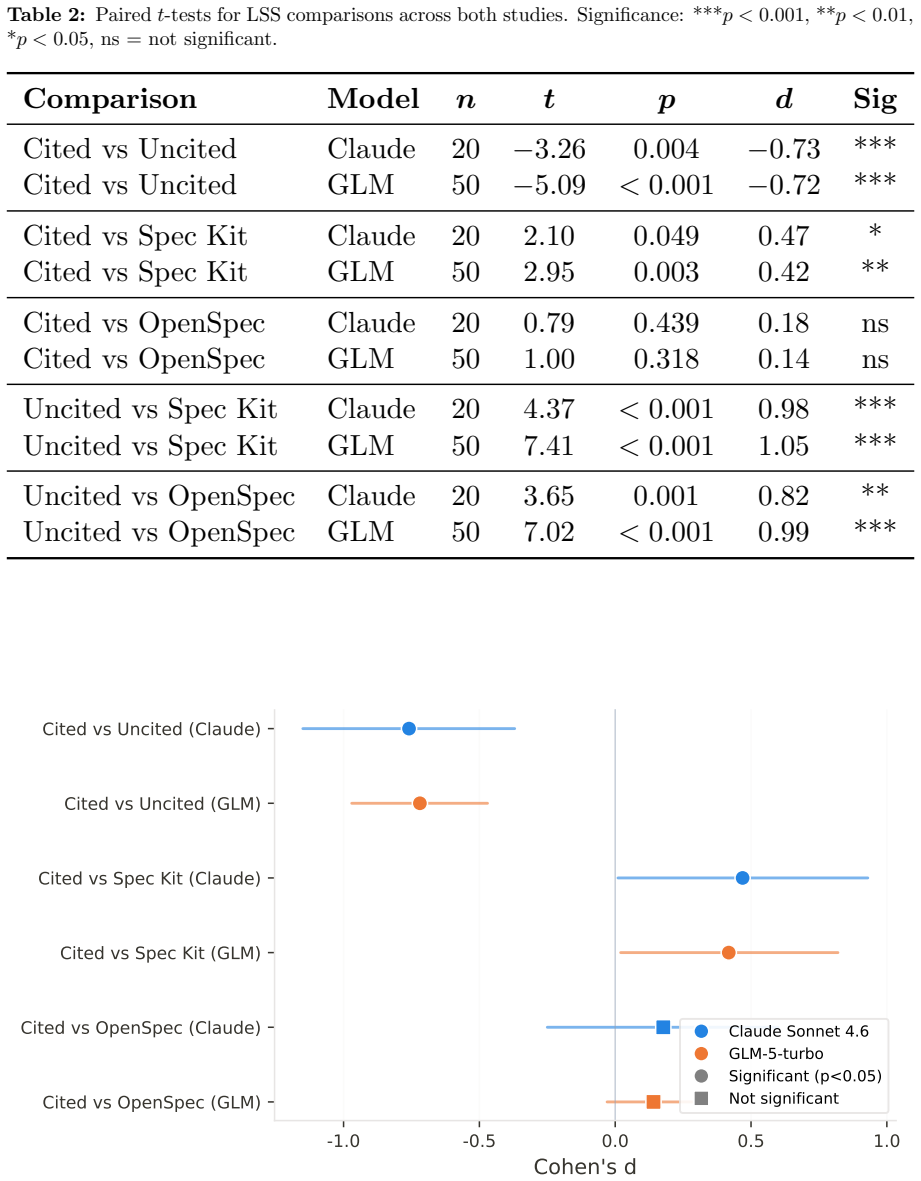
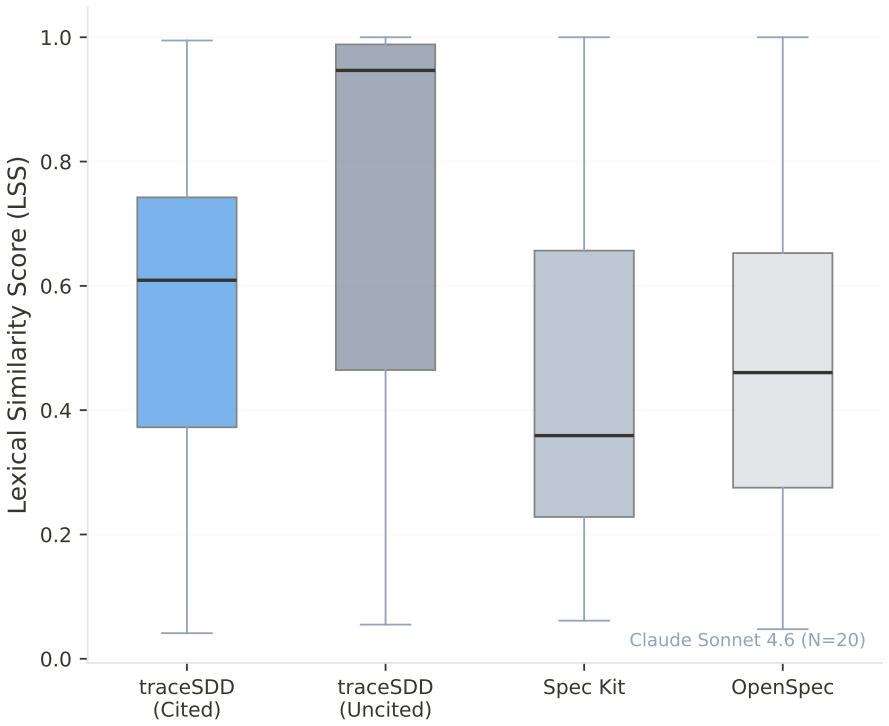
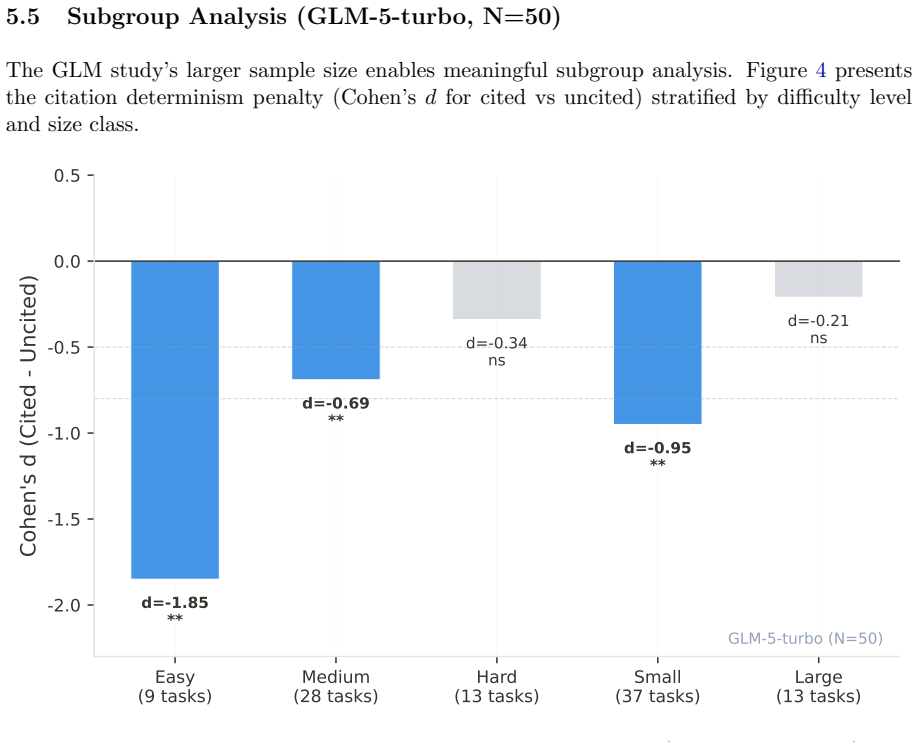
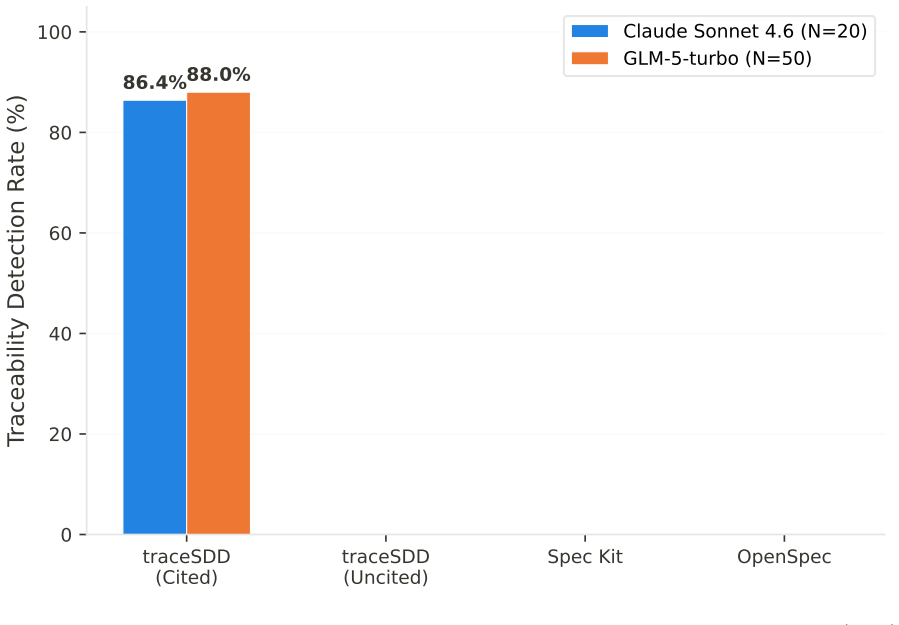
The uncited condition produces significantly higher determinism than the cited condition (Claude: d=-0.76, p=0.003; GLM: d=-0.72, p<0.001), while only the cited condition enables automated hallucination detection (TDR: Claude 86.4 percent, GLM 88.0 percent, versus 0 percent for all alternatives, FPR=0 percent across both studies). traceSDD outperforms Spec Kit on determinism but shows no reliable difference from OpenSpec.
What carries the argument
traceSDD framework, which enforces mandatory per-line requirement citations using hierarchical REQ-XXX.Y.Z identifiers, compared against artifact-level traceability (Spec Kit) and post-hoc external trace maps (OpenSpec).
If this is right
- Citation annotations can be used to enable automated verification of whether generated code actually satisfies stated requirements.
- Developers face a direct choice between more consistent but unverifiable outputs and traceable outputs that support detection of invented requirements.
- The determinism-verifiability trade-off generalizes across different LLM architectures.
- traceSDD's per-line citation style yields higher determinism than artifact-level traceability in direct comparisons.
Where Pith is reading between the lines
- Teams working on safety-critical code may need to accept lower output consistency to gain automated checks.
- Hybrid approaches could combine citations with additional prompting to recover some determinism without losing detection capability.
- The results suggest examining whether similar citation requirements affect determinism in non-code generation tasks such as test case creation.
Load-bearing premise
That the measured differences in determinism and hallucination detection are caused only by the presence or absence of citations rather than other differences in how the three frameworks were implemented or how hallucinations were defined.
What would settle it
Re-running the full set of experiments with a new SDD framework that achieves high true detection rates without any per-line citations, or with the same frameworks but altered definitions of what counts as a hallucination.
Figures
read the original abstract
Spec-Driven Development (SDD) frameworks guide Large Language Model (LLM)-powered code generation through formal specifications, yet they differ fundamentally in how they enforce traceability between requirements and generated code. This paper presents two controlled empirical studies comparing three SDD frameworks: $traceSDD$, which enforces mandatory per-line requirement citations using hierarchical REQ-XXX.Y.Z identifiers; $Spec Kit$, which uses artifact-level traceability through user stories and acceptance criteria; and $OpenSpec$, which relies on post-hoc external trace maps. We measure two primary outcomes across two frontier LLMs -- Claude Sonnet 4.6 (N=20, 4 conditions, 240 implementations) and GLM-5-turbo (N=50, 4 conditions, 600 implementations): $output$ $determinism$ (lexical similarity across independent LLM sessions) and $automated$ $hallucination$ $detection$ $rate$ (TDR). Our pre-registered analysis reveals a consistent, cross-model replicated trade-off: the uncited condition produces significantly higher determinism than the cited condition (Claude: $d=-0.76$, $p=0.003$; GLM: $d=-0.72$, $p<0.001$), while only the cited condition enables automated hallucination detection (TDR: Claude 86.4%, GLM 88.0%, vs 0% for all alternatives, FPR=0% across both studies). traceSDD (cited) significantly outperforms $Spec Kit$ on determinism (Claude: $d=0.47$, $p=0.049$; GLM: $d=0.42$, $p=0.003$) but not OpenSpec (Claude: $d=0.18$, $p=0.44$; GLM: $d=0.14$, $p=0.32$). These findings establish that citation annotations trade determinism for verifiability, and that this trade-off generalizes across model architectures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports two pre-registered controlled studies (Claude Sonnet 4.6: N=20, 240 implementations; GLM-5-turbo: N=50, 600 implementations) comparing three SDD frameworks that differ in traceability: traceSDD (mandatory per-line REQ-XXX.Y.Z citations), Spec Kit (artifact-level user stories), and OpenSpec (post-hoc trace maps). It claims a replicated trade-off in which the uncited condition yields higher output determinism (Claude d=-0.76 p=0.003; GLM d=-0.72 p<0.001) while only the cited condition supports automated hallucination detection (TDR 86.4%/88.0% vs 0%, FPR=0%), with traceSDD also outperforming Spec Kit on determinism in both models.
Significance. If the design isolates citation discipline, the work supplies cross-model replicated evidence with effect sizes, p-values, and pre-registration on a determinism-verifiability trade-off relevant to AI-assisted software engineering. Strengths include explicit reporting of sample sizes, statistical tests, and replication across frontier LLMs.
major comments (2)
- [Abstract and §4 (Experimental Design)] Abstract and §4 (Experimental Design): The central claim attributes the determinism difference (d=-0.76/-0.72) and TDR gap specifically to citation discipline. However, the three frameworks also differ in traceability granularity, spec structure, and enforcement mechanism; the uncited condition is not presented as a pure ablation holding all other variables fixed, so the reported effects cannot be isolated to citation alone.
- [§5.3 (Hallucination Detection Results)] §5.3 (Hallucination Detection Results): TDR reaches 86.4%/88.0% only for the cited condition and 0% for alternatives. Because the automated detector presupposes per-line REQ-XXX.Y.Z identifiers (absent by design in Spec Kit and OpenSpec), the 0% TDR is a definitional outcome rather than an independent empirical test of detection capability across frameworks.
minor comments (1)
- [Abstract] Abstract: The inline LaTeX markup '$output$ $determinism$' and '$automated$ $hallucination$ $detection$ $rate$' should be cleaned to plain text for readability.
Simulated Author's Rebuttal
We thank the referee for these precise observations on attribution and experimental interpretation. Both comments identify areas where our framing overstates the isolation of citation discipline; we agree and will revise accordingly.
read point-by-point responses
-
Referee: [Abstract and §4 (Experimental Design)] Abstract and §4 (Experimental Design): The central claim attributes the determinism difference (d=-0.76/-0.72) and TDR gap specifically to citation discipline. However, the three frameworks also differ in traceability granularity, spec structure, and enforcement mechanism; the uncited condition is not presented as a pure ablation holding all other variables fixed, so the reported effects cannot be isolated to citation alone.
Authors: We accept the critique. The study compares three complete, representative SDD frameworks rather than a controlled ablation that varies only the presence of per-line citations. While citation is the most salient difference and the only one that enables the detector, other design choices (granularity, enforcement) may contribute to the determinism results. We will revise the abstract, §4, and the discussion to state that the observed trade-off applies to these frameworks as implemented, with citation discipline as the necessary condition for automated detection, and we will add an explicit limitations paragraph addressing potential confounds from non-citation factors. revision: partial
-
Referee: [§5.3 (Hallucination Detection Results)] §5.3 (Hallucination Detection Results): TDR reaches 86.4%/88.0% only for the cited condition and 0% for alternatives. Because the automated detector presupposes per-line REQ-XXX.Y.Z identifiers (absent by design in Spec Kit and OpenSpec), the 0% TDR is a definitional outcome rather than an independent empirical test of detection capability across frameworks.
Authors: We agree. The detector is intentionally citation-dependent; therefore the 0 % TDR in the non-cited arms is a direct consequence of the missing identifiers rather than an independent test of detection performance. We will rewrite §5.3 to present the result as evidence that per-line citations are required for this particular automated verification method, and we will remove language that could be read as comparing detection capability across frameworks independent of the citation mechanism. revision: yes
Circularity Check
No significant circularity in empirical measurements
full rationale
The paper reports direct experimental outcomes from two pre-registered studies (N=20 and N=50 LLM sessions) comparing determinism (effect sizes d=-0.76/-0.72) and TDR rates across SDD frameworks. No equations, fitted parameters presented as predictions, self-citations, or uniqueness theorems appear in the abstract or described methods. The TDR comparison, while dependent on framework features like per-line identifiers, is an explicit measurement of an automated detector rather than a derivation that reduces results to inputs by construction. The central claims rest on independent LLM runs and statistical tests, making the work self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard assumptions underlying effect size (Cohen's d) and p-value calculations, including sample independence and appropriate distributional properties for the chosen tests.
Reference graph
Works this paper leans on
-
[1]
Survey of hallucination in natural language generation.ACM Computing Surveys, 55(12):1–38, 2023
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezhong Tan, et al. Survey of hallucination in natural language generation.ACM Computing Surveys, 55(12):1–38, 2023
2023
-
[2]
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, et al. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions.arXiv preprint arXiv:2311.05232, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Beyond Pass@k: Establishing stronger baselines for evaluating code gen- eration
Caleb Watson. Beyond Pass@k: Establishing stronger baselines for evaluating code gen- eration. InarXiv preprint arXiv:2407.14578, 2024. Introduces pass@1 and other stronger metrics for code generation evaluation beyond pass@k
-
[4]
Orlena C. Z. Gotel and Anthony C. W. Finkelstein. An analysis of the requirements trace- ability problem. InProceedings of the First International Conference on Requirements Engineering (ICRE), pages 94–101. IEEE, 1994
1994
-
[5]
Lockerbie, and J
Jane Cleland-Huang, Brian Berenbach, Shaoying Zhu, J. Lockerbie, and J. Aranda. Paving the way for requirements traceability: Moving from theory to practice. InProceedings of the 15th IEEE International Requirements Engineering Conference (RE), pages 281–282. IEEE, 2007
2007
-
[6]
Does requirements traceability improve the quality of software? A systematic literature review.Journal of Systems and Software, 192:111441, 2022
Soheil Jalali and Claes Wohlin. Does requirements traceability improve the quality of software? A systematic literature review.Journal of Systems and Software, 192:111441, 2022
2022
-
[7]
IEEE recommended practice for software requirements specifications
IEEE. IEEE recommended practice for software requirements specifications. Technical Report IEEE Std 830-1998, IEEE, 1998
1998
-
[8]
Gustavo Pinto, Igor Steinmacher, and Marco A. Gerosa. More common than you think: An in-depth study of casual contributors. InProceedings of the IEEE/ACM International Conference on Software Engineering: Companion Proceedings (ICSE-Companion), pages 202–204. ACM, 2018. Referenced in the context of requirements traceability tool surveys
2018
-
[9]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[10]
OpenAI. GPT-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Sparks of Artificial General Intelligence: Early experiments with GPT-4
S´ ebastien Bubeck, Varun Chandrasekaran, Ronen Eldan, et al. Sparks of artificial general intelligence: Early experiments with GPT-4.arXiv preprint arXiv:2303.12712, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
StarCoder: may the source be with you!
Raymond Li, Loubna Ben Allal, Niklas Muennighoff, et al. StarCoder: May the source be with you!arXiv preprint arXiv:2305.06161, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
DeepSeek-Coder: When the Large Language Model Meets Programming -- The Rise of Code Intelligence
Daya Guo, Qihao Zhu, et al. DeepSeek-Coder: When the large language model meets programming. InarXiv preprint arXiv:2401.14196, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
The Claude 3 model family.Anthropic Technical Report, 2024
Anthropic. The Claude 3 model family.Anthropic Technical Report, 2024
2024
-
[15]
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools
A. Wang et al. GLM-4: An open large language model.arXiv preprint arXiv:2406.12793, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Yuntao Bai, Andy Jones, Kamal Ndousse, et al. Training a helpful and harmless assistant with reinforcement learning from human feedback.arXiv preprint arXiv:2204.05862, 2022. 16
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[17]
Large language models are zero-shot fuzzers: Fuzzing deep-learning libraries via large language models
Xiaogang Hou, Yiran Liu, Xiangyu Zhang, et al. Large language models are zero-shot fuzzers: Fuzzing deep-learning libraries via large language models. InProceedings of the 32nd ACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA), pages 499–511, 2023
2023
-
[18]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, et al. Self-consistency improves chain of thought reasoning in language models.arXiv preprint arXiv:2203.11171, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[19]
Scaling laws for neural language models.arXiv preprint arXiv:2010.07448, 2020
Jared Kaplan, Sam McCandlish, Tom Henighan, et al. Scaling laws for neural language models.arXiv preprint arXiv:2010.07448, 2020
-
[20]
ReAct: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, et al. ReAct: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[21]
Reflexion: Language Agents with Verbal Reinforcement Learning
Noah Shinn, Federico Cassano, Ashwin Gopinath, et al. Reflexion: Language agents with verbal reinforcement learning.arXiv preprint arXiv:2303.11366, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Lawrence Erlbaum Associates, 2nd edition, 1988
Jacob Cohen.Statistical Power Analysis for the Behavioral Sciences. Lawrence Erlbaum Associates, 2nd edition, 1988
1988
-
[23]
Dominance statistics: Ordinal analyses to answer ordinal questions.Psycho- logical Bulletin, 114(3):494–509, 1993
Norman Cliff. Dominance statistics: Ordinal analyses to answer ordinal questions.Psycho- logical Bulletin, 114(3):494–509, 1993. 17
1993
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.