Ask, Don't Judge: Binary Questions for Interpretable LLM Evaluation and Self-Improvement
Pith reviewed 2026-06-26 04:34 UTC · model grok-4.3
The pith
Decomposing LLM evaluation into generated binary questions produces interpretable scores that match human judgments and enable iterative prompt improvement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
BINEVAL decomposes any task's evaluation criteria into a set of atomic binary questions via meta-prompt, obtains independent LLM verdicts on each question for a given output, and aggregates those verdicts into calibrated multi-dimensional scores together with the raw question-level answers; this yields evaluation that is more inspectable, better calibrated to human distributions, and directly usable as feedback for prompt optimization without training.
What carries the argument
The meta-prompt that turns task criteria into a covering set of atomic binary questions whose independent answers are aggregated into scores.
If this is right
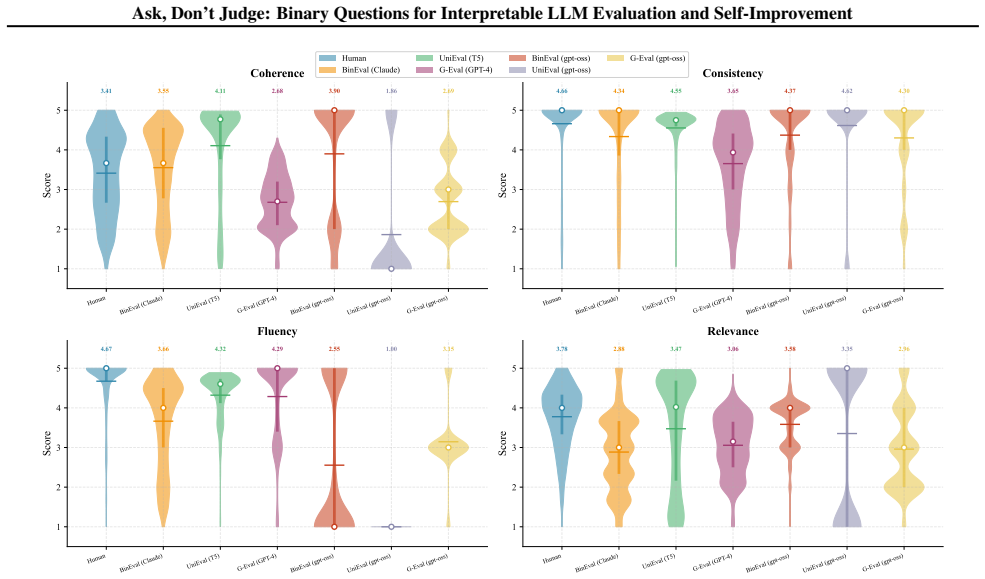
- BINEVAL matches or outperforms UniEval and G-Eval across SummEval, Topical-Chat, and QAGS while better matching human score distributions.
- The question-level answers avoid ceiling effects and discriminate more clearly between borderline and clearly flawed outputs.
- The same question feedback supports iterative prompt optimization on summarization and instruction-following tasks under both self-update and cross-model settings.
- The framework is task-agnostic and training-free.
Where Pith is reading between the lines
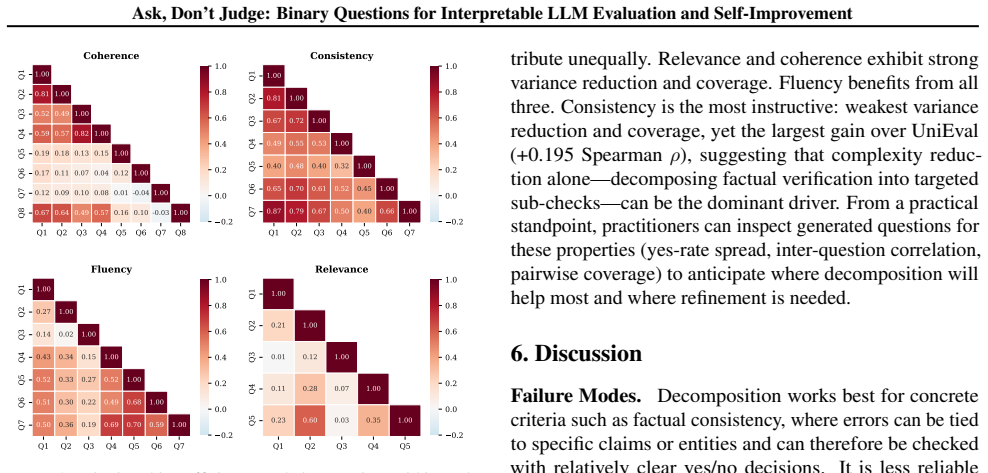
- Binary-question feedback could be applied to domains such as code generation where holistic scores currently obscure which specific properties fail.
- The decomposition might reduce certain forms of position or length bias that affect scalar LLM judges.
- Aggregated binary answers could serve as a lightweight reward signal for reinforcement learning from human feedback loops.
Load-bearing premise
A meta-prompt can reliably produce a set of atomic, unbiased binary questions whose coverage of the intended criteria is complete enough that independent answers aggregate into calibrated scores.
What would settle it
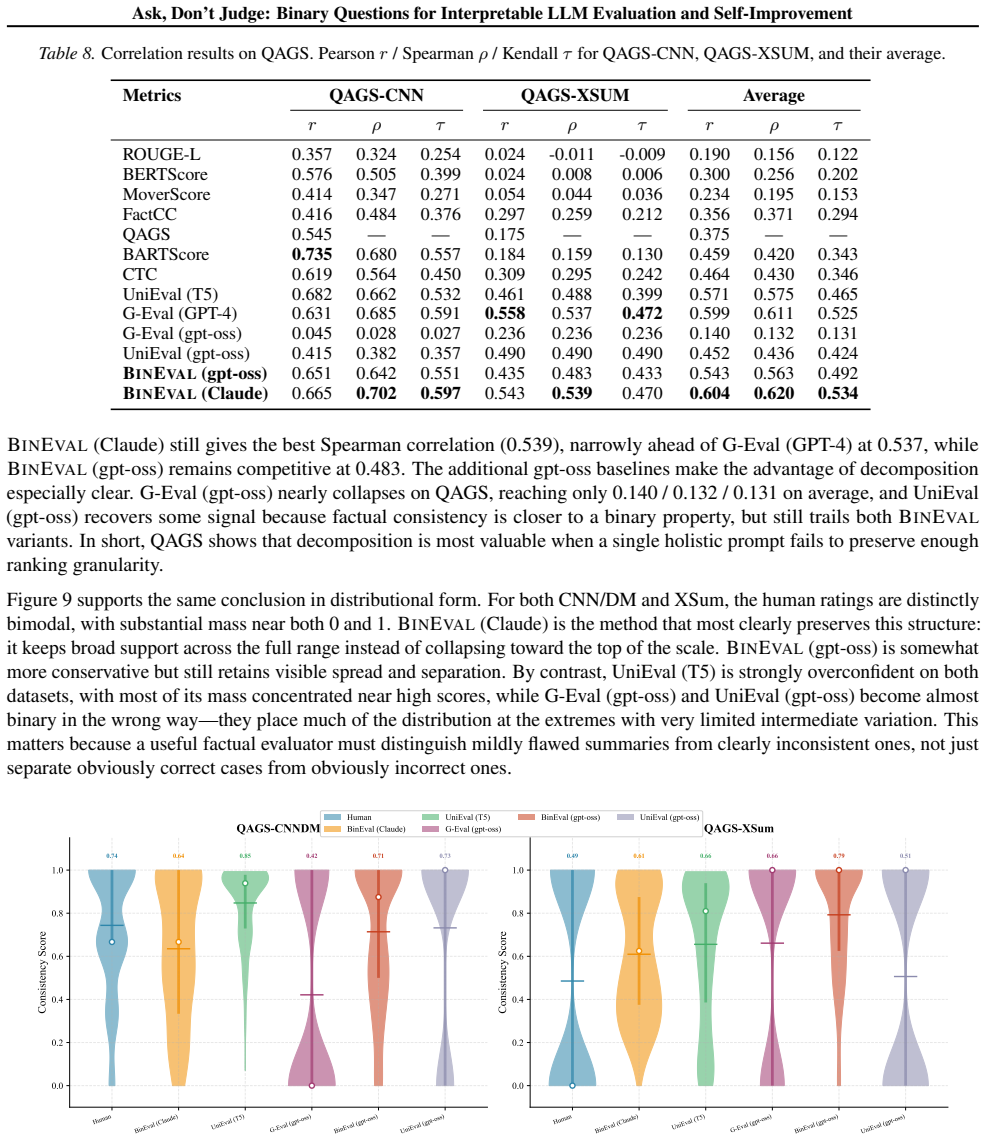
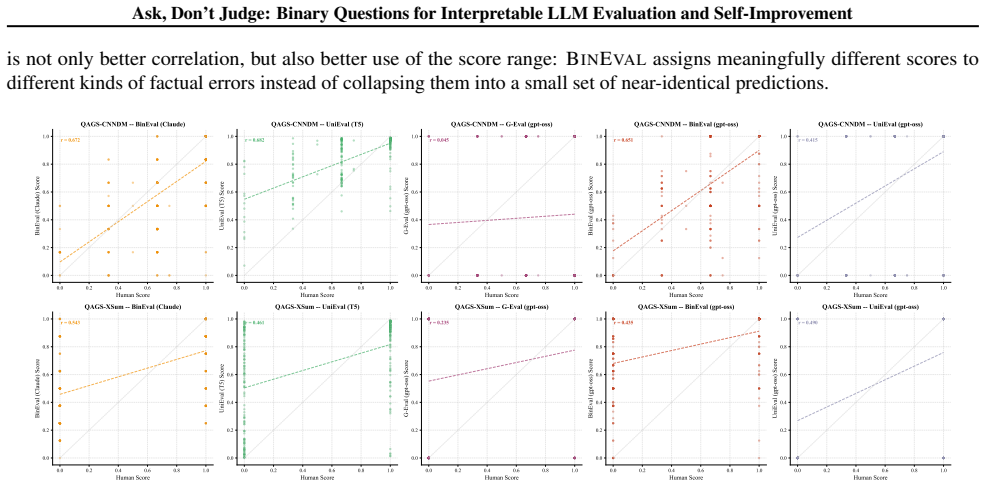
Running the framework on the QAGS factual-consistency benchmark and finding that the aggregated scores have lower rank correlation with human ratings than a holistic LLM judge such as G-Eval.
Figures
read the original abstract
Evaluating LLM outputs remains a major bottleneck in NLP: human evaluation is expensive and slow, lexical metrics correlate poorly with human judgments on open-ended generation, and holistic LLM judges often produce opaque scores that are hard to debug. We propose BINEVAL, a framework that decomposes evaluation criteria into atomic binary questions and aggregates the resulting verdicts into interpretable, multi-dimensional scores. Given a task prompt, a meta-prompt generates fine-grained evaluation questions, and an LLM answers them independently for each output, yielding transparent question-level feedback together with calibrated overall scores. This decomposition makes evaluation easier to inspect, easier to diagnose, and directly usable for prompt improvement. Across SummEval, Topical-Chat, and QAGS, BINEVAL matches or outperforms strong baselines including UniEval and G-Eval, with especially strong results on factual consistency benchmarks such as QAGS. Beyond competitive correlation with human judgments, BINEVAL better matches human score distributions and avoids the ceiling effects common in prior LLM judges, leading to better discrimination between borderline and clearly flawed outputs. We further show that the same question-level feedback supports iterative prompt optimization, improving evaluator prompts on summarization and generation prompts on IFBench under both self-update and cross-model update settings. Overall, BINEVAL provides a task-agnostic, training-free, and interpretable evaluation framework that combines strong empirical performance with practical diagnostic and optimization value.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BINEVAL, a framework that decomposes LLM evaluation criteria into atomic binary questions generated via a meta-prompt. An LLM answers these questions independently for each output, and verdicts are aggregated into interpretable multi-dimensional scores. Experiments on SummEval, Topical-Chat, and QAGS report that BINEVAL matches or outperforms baselines including UniEval and G-Eval (especially on factual consistency), better matches human score distributions, avoids ceiling effects, and that the question-level feedback enables iterative prompt optimization under self-update and cross-model settings.
Significance. If the empirical results hold, BINEVAL offers a training-free, task-agnostic, and interpretable alternative to holistic LLM judges, with added practical value for diagnosis and prompt self-improvement. The use of public benchmarks and the optimization experiments are clear strengths.
major comments (2)
- Abstract: The claim that the meta-prompt generates 'fine-grained evaluation questions' that are atomic, unbiased, and collectively cover the target criteria (leading to calibrated scores and better discrimination) is load-bearing for all superiority claims over G-Eval and UniEval. The manuscript provides no human audit, inter-rater agreement, coverage analysis, or ablation on question quality; if the generated questions systematically under-cover error modes or embed meta-prompt priors, the subsequent independent answers and aggregation cannot deliver the reported calibration or performance gains.
- Experiments section: The statements of 'competitive or superior correlations' and 'especially strong results on QAGS' require reported statistical tests, variance across runs, and ablations on the aggregation function to be load-bearing; without them the central empirical claims cannot be verified and post-hoc data handling cannot be ruled out.
minor comments (2)
- Abstract: The aggregation procedure that converts independent binary verdicts into overall scores is described only at high level; a concise formal definition or pseudocode would improve reproducibility.
- The paper would benefit from an explicit limitations paragraph addressing potential biases inherited from the meta-prompt LLM.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and will incorporate revisions to strengthen the empirical grounding and transparency of the claims.
read point-by-point responses
-
Referee: Abstract: The claim that the meta-prompt generates 'fine-grained evaluation questions' that are atomic, unbiased, and collectively cover the target criteria is load-bearing. The manuscript provides no human audit, inter-rater agreement, coverage analysis, or ablation on question quality.
Authors: We agree this validation is important and currently missing. The manuscript relies on downstream task performance as indirect support. In revision we will add a dedicated analysis subsection with: (i) human evaluation of 200 sampled questions for atomicity and coverage of the original criteria, (ii) inter-annotator agreement (Cohen's kappa), and (iii) qualitative review for meta-prompt bias or under-covered error modes. This directly addresses the concern. revision: yes
-
Referee: Experiments section: Statements of competitive or superior correlations and especially strong results on QAGS require reported statistical tests, variance across runs, and ablations on the aggregation function.
Authors: We accept the point. The current version reports mean correlations without significance testing or variance. We will revise the experimental results to include: (i) paired statistical significance tests (Wilcoxon signed-rank) against baselines, (ii) standard deviation across five independent runs with different random seeds, and (iii) an ablation comparing mean, majority-vote, and weighted aggregation functions. These additions will be placed in the main results tables and appendix. revision: yes
Circularity Check
No circularity: empirical results validated against external human judgments on public benchmarks
full rationale
The paper presents an empirical framework (BINEVAL) whose central claims rest on measured correlations with human annotations on established external benchmarks (SummEval, Topical-Chat, QAGS). No equations, derivations, fitted parameters, or predictions are defined in terms of the method's own outputs. The meta-prompt step for question generation is an unverified modeling assumption rather than a self-referential loop; performance is assessed by direct comparison to independent human scores, satisfying the criterion for non-circularity. No self-citation chains or renamings of known results are load-bearing for the reported superiority.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can generate appropriate atomic binary evaluation questions via a meta-prompt and can answer those questions independently and accurately enough to support calibrated aggregate scores.
Reference graph
Works this paper leans on
-
[1]
Generalizing Verifiable Instruction Following
GitHub repository. Lin, C.-Y . ROUGE: A package for automatic evaluation of summaries. InText Summarization Branches Out, pp. 74–81, 2004. Liu, Y ., Iter, D., Xu, Y ., Wang, S., Xu, R., and Zhu, C. G-Eval: NLG evaluation using GPT-4 with better hu- man alignment. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 202...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/d18-1206 2004
-
[2]
because,
Implicit transitions are acceptable.Require logical connections but do not demand explicit cue words (“because,” “therefore”). Implicit continuity suffices if the narrative flows
-
[3]
Add a central-claim relevance criterion.Each sentence should advance the article’s main claim; sentences that do not contribute are non-contributory regardless of grammatical correctness
-
[4]
logical connections between sentences (explicit cues like ‘because, ’ ‘therefore, ’ or implicit continuity)
Do not penalize omission of background details.Missing context should not lower coherence as long as the core fact and conflict remain clear. These lessons produced targeted edits to the evaluation rubric: Table 5.Coherence prompt: key changes from iteration 0 to iteration 1. Iteration 0 (Baseline) Iteration 1 (Updated) “...logical connections between sen...
-
[5]
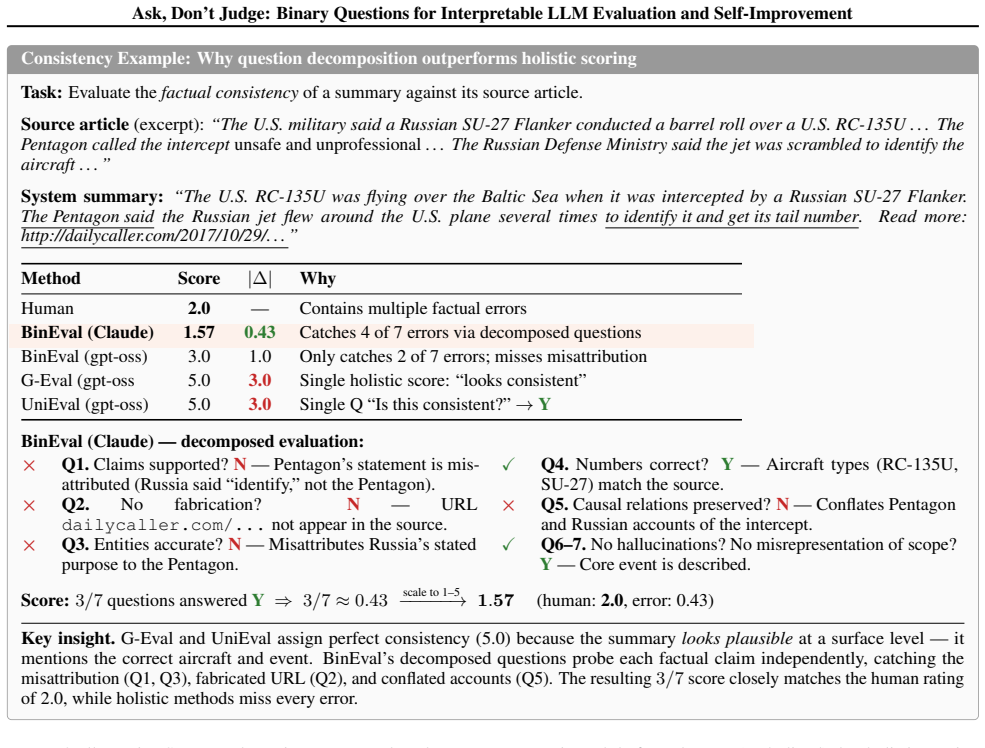
Omission ̸= inconsistency.A summary that omits details from the source is not factually inconsistent; only statements present in the summarythat are unsupported should be penalized
-
[6]
83rd minute
Semantic equivalence via arithmetic.Converting “83rd minute” to “seven minutes remaining” (in a 90-minute match) is a valid transformation, not a hallucination
-
[7]
X restarted his row with Z
Subject–role misattribution.When summaries restructure clauses, verify that entities are attached to the correct verbs (e.g., “X restarted his row with Z” misattributes if the source says “X had a row with Y and drew 0–0 with Z”). The updated prompt grew substantially (from 4 evaluation steps to 6, with detailed guidance on literal interpretation, subject...
-
[8]
Make the rubric stricter about coverage of essential context, not just the headline fact
-
[9]
Require the evaluator to check foreverykey actor,everymotivation, andeverybackground event
-
[10]
The resulting prompt decomposed relevance into exhaustive sub-criteria (actors, motivations, background events, factual propositions, redundancy) with a rigid penalty system
Apply quantitative penalties:−1per missing key actor,−0.5per missing motivation or background event. The resulting prompt decomposed relevance into exhaustive sub-criteria (actors, motivations, background events, factual propositions, redundancy) with a rigid penalty system. The regenerated binary questions reflected this over-specificity: Regenerated que...
-
[11]
Does the summary includeevery key actormentioned in the source?
-
[12]
Does the summary includeevery motivationfor actions stated in the source?
-
[13]
Does the summary includeall background eventsdirectly relevant to the headline?
-
[14]
Does the summary containevery other factual proposition(dates, locations, amounts)?
-
[15]
did the summary capture the gist?
Does the summary avoid irrelevant or redundant information? Why it fails:Human annotators use aholisticjudgment for relevance—“did the summary capture the gist?”—with soft tolerance for missing minor details. The updated questions demandexhaustivecoverage, causing the model to rate almost all summaries as deficient. The resulting scores are systematically...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.