ERA: Entropy-Guided Visual Token Pruning with Rectified Attention for Efficient MLLMs
Pith reviewed 2026-07-01 05:42 UTC · model grok-4.3
The pith
ERA rectifies attention collapse during visual token pruning to preserve MLLM performance under aggressive compression.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
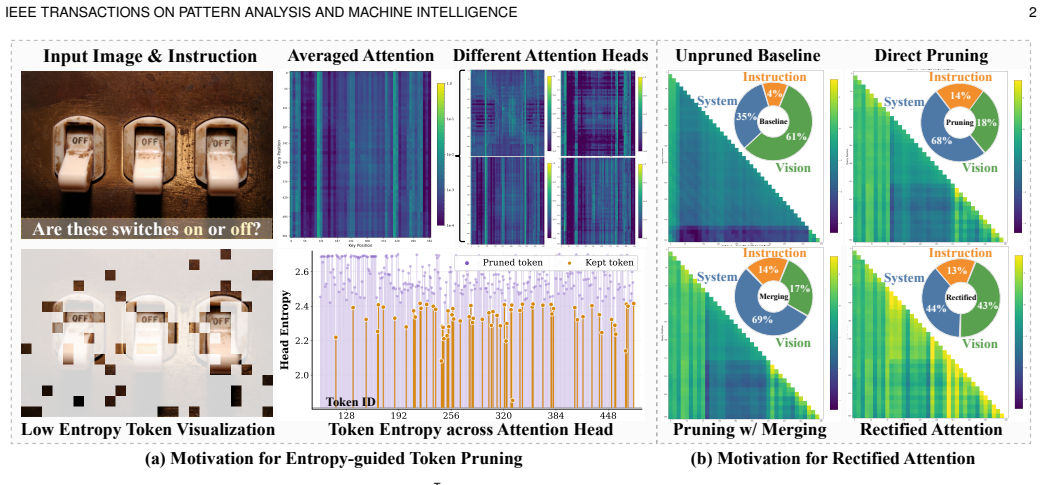
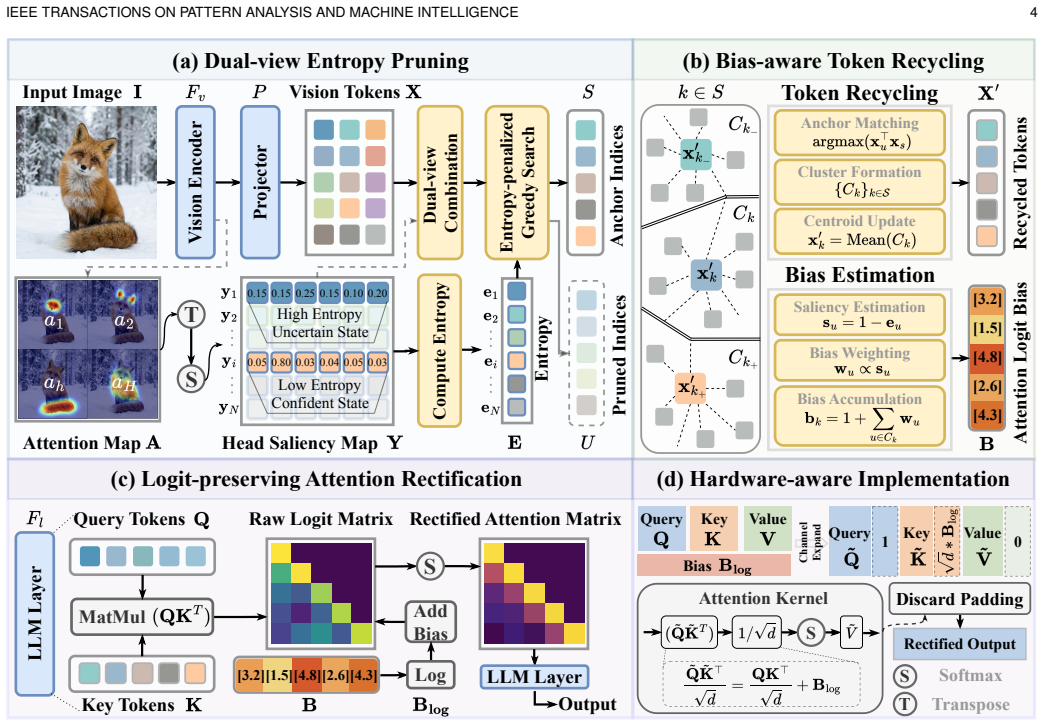
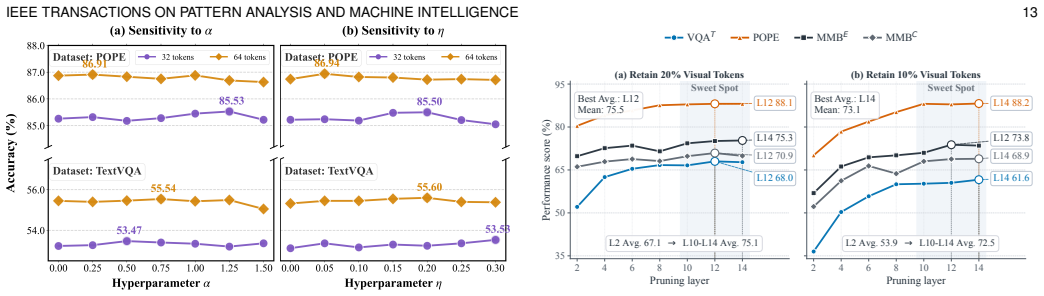
ERA shows that jointly modeling visual diversity and head-wise saliency for anchor selection, recycling pruned tokens to estimate cluster-level logit bias, and injecting the bias into attention logits via rectification prevents the attention distortions that normally accompany token reduction, thereby preserving visual evidence and delivering robust performance across single-image, multi-image, and video settings on a wide range of MLLMs.
What carries the argument
The three-component ERA framework of Dual-view Entropy Pruning to select anchors, Bias-aware Token Recycling to estimate logit bias from clusters, and Logit-preserving Attention Rectification to inject the bias and correct pruning-induced collapse.
If this is right
- Maintains performance across single-image, multi-image, and video inputs without retraining.
- Applies training-free to many existing MLLM architectures.
- Delivers practical inference acceleration while keeping visual evidence intact.
- Positions logit-preserving token pruning as a unifying framework combining theory, design, and deployment.
Where Pith is reading between the lines
- The bias estimation step could be adapted for dynamic, input-dependent pruning schedules during runtime.
- Similar rectification of attention logits might transfer to efficiency techniques in pure language models or other modalities.
- The method could reduce memory footprint enough to fit larger MLLMs on edge devices for real-time video processing.
Load-bearing premise
The estimated cluster-level logit bias, when injected through attention rectification, fully compensates for the distortions from pruning without introducing new errors or requiring model-specific tuning.
What would settle it
Applying ERA at high compression ratios and measuring that the resulting attention distributions still deviate substantially from the unpruned baseline or that task accuracy falls below the unpruned model on standard multimodal benchmarks.
Figures


read the original abstract
Multimodal Large Language Models (MLLMs) incur prohibitive inference costs due to long visual token sequences. Training-free visual token reduction provides an efficient solution. However, existing methods distort attention distributions, giving rise to a phenomenon we term Attention Logit Collapse. To address this issue, we propose ERA, an Entropy-guided visual token pruning framework with Rectified Attention for efficient MLLMs. Specifically, ERA comprises three crucial components: Dual-view Entropy Pruning (DEP), Bias-aware Token Recycling (BTR), and Logit-preserving Attention Rectification (LAR). First, DEP identifies representative anchor tokens by jointly modeling visual diversity and head-wise saliency. BTR then recycles pruned tokens into their corresponding anchors while estimating a cluster-level logit bias. Building upon this, LAR injects the estimated bias into attention logits, effectively rectifying the collapse induced by token reduction. Together, these components preserve visual evidence even under aggressive compression, enabling robust performance across single-image, multi-image, and video settings on a wide range of MLLMs. Beyond delivering practical acceleration, ERA establishes logit-preserving visual token pruning as a principled framework for efficient MLLMs, unifying theoretical foundation, algorithmic design, and practical deployment. The code is at https://github.com/924973292/ERA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that visual token pruning in MLLMs induces a phenomenon termed Attention Logit Collapse that distorts attention distributions, and proposes the ERA framework with three components—Dual-view Entropy Pruning (DEP) to select anchor tokens via joint visual diversity and head-wise saliency, Bias-aware Token Recycling (BTR) to recycle pruned tokens while estimating a cluster-level logit bias, and Logit-preserving Attention Rectification (LAR) to inject that bias into attention logits—to restore the original distribution. The method is presented as training-free and model-agnostic, preserving performance under aggressive compression across single-image, multi-image, and video tasks on diverse MLLMs, with code released.
Significance. If the central claims hold, ERA would supply a practical training-free route to lower inference cost in MLLMs while maintaining accuracy, addressing a key deployment bottleneck. The release of code is a clear strength that enables direct verification and extension.
major comments (1)
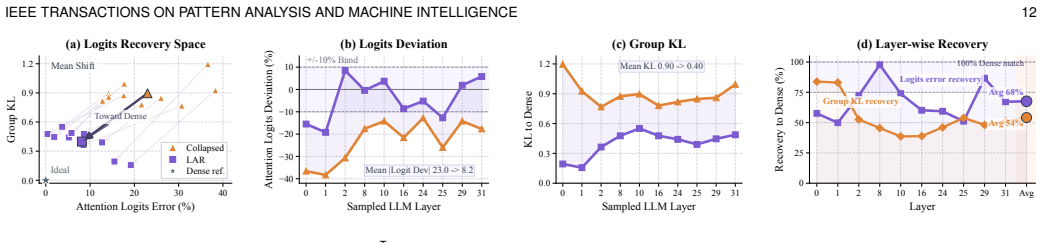
- [Abstract / BTR and LAR] Abstract / BTR+LAR description: the central claim requires that a single scalar per-cluster logit bias estimated from recycled tokens, when added to attention logits, fully restores the pre-pruning distribution. This rests on the unstated assumption that the induced logit shift is constant across heads and query positions within each cluster and exactly recoverable from the recycled tokens; the manuscript must supply either a derivation showing the shift is uniform or an empirical check (e.g., per-head variance of the bias term or residual KL divergence after rectification) because violation would mean LAR introduces a new systematic error rather than canceling the pruning-induced distortion.
minor comments (1)
- [Abstract] The newly coined term 'Attention Logit Collapse' would benefit from a brief comparison to prior observations of attention distortion under token reduction to clarify novelty.
Simulated Author's Rebuttal
We thank the referee for the constructive comment regarding the assumptions in BTR and LAR. We respond point-by-point below.
read point-by-point responses
-
Referee: [Abstract / BTR and LAR] Abstract / BTR+LAR description: the central claim requires that a single scalar per-cluster logit bias estimated from recycled tokens, when added to attention logits, fully restores the pre-pruning distribution. This rests on the unstated assumption that the induced logit shift is constant across heads and query positions within each cluster and exactly recoverable from the recycled tokens; the manuscript must supply either a derivation showing the shift is uniform or an empirical check (e.g., per-head variance of the bias term or residual KL divergence after rectification) because violation would mean LAR introduces a new systematic error rather than canceling the pruning-induced distortion.
Authors: We acknowledge that the original manuscript does not include a formal derivation of uniformity for the per-cluster logit bias nor the suggested empirical checks on per-head variance or residual KL divergence. This is a substantive point. In the revised manuscript we will add an empirical analysis section (new subsection in Section 4 or dedicated appendix) that reports (i) the variance of the estimated bias term across heads and query positions within clusters and (ii) the residual KL divergence between pre-pruning and post-LAR attention distributions, evaluated on representative layers, models, and tasks. These results will either corroborate the single-scalar approximation or highlight its limitations, allowing readers to assess whether LAR fully cancels the distortion or introduces residual error. revision: yes
Circularity Check
No significant circularity detected
full rationale
The ERA paper proposes an algorithmic framework (DEP + BTR + LAR) for training-free visual token pruning. The cluster-level logit bias estimated in BTR and injected by LAR is an explicit, hand-designed correction step within the method itself, not a parameter fitted to the final performance metric and then relabeled as a prediction. No equations or claims in the abstract reduce the performance preservation result to the inputs by construction. No self-citation load-bearing uniqueness theorems or ansatzes are invoked. The central claims rest on empirical behavior across MLLMs rather than a closed mathematical derivation that collapses to its own definitions. This is the normal case of a self-contained engineering contribution.
Axiom & Free-Parameter Ledger
free parameters (1)
- cluster-level logit bias
invented entities (1)
-
Attention Logit Collapse
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Improved baselines with visual instruction tuning,
H. Liu, C. Li, Y. Li, and Y. J. Lee, “Improved baselines with visual instruction tuning,” inCVPR, 2024, pp. 26 296–26 306
2024
-
[2]
InternVL: Scaling up vision foundation models and aligning for generic visual-linguistic tasks,
Z. Chen, J. Wu, W. Wang, W. Su, G. Chen, S. Xing, M. Zhong, Q. Zhang, X. Zhu, L. Lu, B. Li, P . Luo, T. Lu, Y. Qiao, and J. Dai, “InternVL: Scaling up vision foundation models and aligning for generic visual-linguistic tasks,” inCVPR, 2024, pp. 24 185–24 198
2024
-
[3]
An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models,
L. Chen, H. Zhao, T. Liu, S. Bai, J. Lin, C. Zhou, and B. Chang, “An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models,” inECCV, 2024, pp. 19–35
2024
-
[4]
A survey of token compression for efficient multimodal large language models,
K. Shao, K. Tao, K. Zhang, S. Feng, M. Cai, Y. Shang, H. You, C. Qin, Y. Sui, and H. Wang, “A survey of token compression for efficient multimodal large language models,”TMLR, 2026
2026
-
[5]
DivPrune: Diversity-based visual token pruning for large multimodal mod- els,
S. R. Alvar, G. Singh, M. Akbari, and Y. Zhang, “DivPrune: Diversity-based visual token pruning for large multimodal mod- els,” inCVPR, 2025, pp. 9392–9401
2025
-
[6]
Beyond attention or similarity: Maximizing conditional diversity for token pruning in MLLMs,
Q. Zhang, M. Liu, L. Li, M. Lu, Y. Zhang, J. Pan, Q. She, and S. Zhang, “Beyond attention or similarity: Maximizing conditional diversity for token pruning in MLLMs,” inNeurIPS, vol. 38, 2025, pp. 25 438–25 468
2025
-
[7]
VisionZip: Longer is better but not necessary in vision language models,
S. Yang, Y. Chen, Z. Tian, C. Wang, J. Li, B. Yu, and J. Jia, “VisionZip: Longer is better but not necessary in vision language models,” inCVPR, 2025, pp. 19 792–19 802
2025
-
[8]
Prompt-cam: Making vision transformers interpretable for fine-grained analysis,
A. Chowdhury, D. Paul, Z. Mai, J. Gu, Z. Zhang, K. S. Mehrab, E. G. Campolongo, D. Rubenstein, C. V . Stewart, A. Karpatne, T. Berger-Wolf, Y. Su, and W.-L. Chao, “Prompt-cam: Making vision transformers interpretable for fine-grained analysis,” in CVPR, 2025, pp. 4375–4385
2025
-
[9]
FlashAttention: Fast and memory-efficient exact attention with IO-awareness,
T. Dao, D. Y. Fu, S. Ermon, A. Rudra, and C. R ´e, “FlashAttention: Fast and memory-efficient exact attention with IO-awareness,” in NeurIPS, vol. 35, 2022, pp. 16 344–16 359
2022
-
[10]
Efficient memory management for large language model serving with pagedattention,
W. Kwon, Z. Li, S. Zhuang, Y. Sheng, L. Zheng, C. H. Yu, J. Gon- zalez, H. Zhang, and I. Stoica, “Efficient memory management for large language model serving with pagedattention,” inSOSP, 2023, pp. 611–626
2023
-
[11]
Multimodal machine learning: A survey and taxonomy,
T. Baltrusaitis, C. Ahuja, and L.-P . Morency, “Multimodal machine learning: A survey and taxonomy,”TP AMI, vol. 41, no. 2, pp. 423– 443, 2019
2019
-
[12]
Multimodal learning with transformers: A survey,
P . Xu, X. Zhu, and D. A. Clifton, “Multimodal learning with transformers: A survey,”TP AMI, vol. 45, no. 10, pp. 12 113–12 132, 2023
2023
-
[13]
Vision-language models for vision tasks: A survey,
J. Zhang, J. Huang, S. Jin, and S. Lu, “Vision-language models for vision tasks: A survey,”TP AMI, vol. 46, no. 8, pp. 5625–5644, 2024
2024
-
[14]
MiniGPT-4: Enhancing vision-language understanding with advanced large language models,
D. Zhu, J. Chen, X. Shen, X. Li, and M. Elhoseiny, “MiniGPT-4: Enhancing vision-language understanding with advanced large language models,” inICLR, 2024
2024
-
[15]
LongVILA: Scaling long-context visual language models for long videos,
Y. Chen, F. Xue, D. Li, Q. Hu, L. Zhu, X. Li, Y. Fang, H. Tang, S. Yang, Z. Liu, Y. He, H. Yin, P . Molchanov, J. Kautz, L. Fan, Y. Zhu, Y. Lu, and S. Han, “LongVILA: Scaling long-context visual language models for long videos,” inICLR, 2025
2025
-
[16]
LLaVA-OneVision: Easy visual task transfer,
B. Li, Y. Zhang, D. Guo, R. Zhang, F. Li, H. Zhang, K. Zhang, P . Zhang, Y. Li, Z. Liu, and C. Li, “LLaVA-OneVision: Easy visual task transfer,”TMLR, 2025
2025
-
[17]
LLaVA- NeXT: Improved reasoning, OCR, and world knowledge,
H. Liu, C. Li, Y. Li, B. Li, Y. Zhang, S. Shen, and Y. J. Lee, “LLaVA- NeXT: Improved reasoning, OCR, and world knowledge,” LLaVA Blog, 2024, accessed: May 17, 2026
2024
-
[18]
X. Dong, P . Zhang, Y. Zang, Y. Cao, B. Wang, L. Ouyang, X. Wei, S. Zhang, H. Duan, M. Cao, W. Zhang, Y. Li, H. Yan, Y. Gao, X. Zhang, W. Li, J. Li, K. Chen, C. He, X. Zhang, Y. Qiao, D. Lin, and J. Wang, “InternLM-XComposer2: Mastering free-form text- image composition and comprehension in vision-language large models,”arXiv preprint arXiv:2401.16420, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
S. Bai, K. Chen, X. Liu, J. Wang, W. Ge, S. Song, K. Dang, P . Wang, S. Wang, J. Tang, H. Zhong, Y. Zhu, M. Yang, Z. Li, J. Wan, P . Wang, W. Ding, Z. Fu, Y. Xu, J. Ye, X. Zhang, T. Xie, Z. Cheng, H. Zhang, Z. Yang, H. Xu, and J. Lin, “Qwen2.5-VL Technical Report,”arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Unveiling encoder-free vision-language models,
H. Diao, Y. Cui, X. Li, Y. Wang, H. Lu, and X. Wang, “Unveiling encoder-free vision-language models,” inNeurIPS, vol. 37, 2024, pp. 52 545–52 567
2024
-
[21]
EVEv2: Improved baselines for encoder-free vision- language models,
H. Diao, X. Li, Y. Cui, Y. Wang, H. Deng, T. Pan, W. Wang, H. Lu, and X. Wang, “EVEv2: Improved baselines for encoder-free vision- language models,” inICCV, 2025, pp. 21 014–21 025
2025
-
[22]
From pixels to words–towards native vision-language primitives at scale,
H. Diao, M. Li, S. Wu, L. Dai, X. Wang, H. Deng, L. Lu, D. Lin, and Z. Liu, “From pixels to words–towards native vision-language primitives at scale,” inICLR, 2026
2026
-
[23]
From Pixels to Words -- Towards Native One-Vision Models at Scale
H. Diao, J. Wang, P . Wu, Y. Dong, Y. Niu, Y. Zhu, Z. Cai, W. Fan, L. Dai, S. Wuet al., “From pixels to words–towards native one- vision models at scale,”arXiv preprint arXiv:2605.28820, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
SenseNova-U1: Unifying Multimodal Understanding and Generation with NEO-unify Architecture
H. Diao, P . Wu, H. Deng, J. Wang, S. Bai, S. Wu, W. Fan, W. Ye, W. Tong, X. Fanet al., “Sensenova-u1: Unifying multimodal un- derstanding and generation with neo-unify architecture,”arXiv preprint arXiv:2605.12500, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
A survey on vision transformer,
K. Han, Y. Wang, H. Chen, X. Chen, J. Guo, Z. Liu, Y. Tang, A. Xiao, C. Xu, Y. Xu, Z. Yang, Y. Zhang, and D. Tao, “A survey on vision transformer,”TP AMI, vol. 45, no. 1, pp. 87–110, 2023
2023
-
[26]
A survey on efficient vision transformers: Algorithms, techniques, and performance benchmarking,
L. Papa, P . Russo, I. Amerini, and L. Zhou, “A survey on efficient vision transformers: Algorithms, techniques, and performance benchmarking,”TP AMI, vol. 46, no. 12, pp. 7682–7700, 2024
2024
-
[27]
Spar- seVLM: Visual token sparsification for efficient vision-language model inference,
Y. Zhang, C. Fan, J. Ma, W. Zheng, T. Huang, K. Cheng, D. A. Gudovskiy, T. Okuno, Y. Nakata, K. Keutzer, and S. Zhang, “Spar- seVLM: Visual token sparsification for efficient vision-language model inference,” inICML, 2025, pp. 74 840–74 857
2025
-
[28]
Boosting multimodal large lan- guage models with visual tokens withdrawal for rapid inference,
Z. Lin, M. Lin, L. Lin, and R. Ji, “Boosting multimodal large lan- guage models with visual tokens withdrawal for rapid inference,” inAAAI, vol. 39, no. 5, 2025, pp. 5334–5342
2025
-
[29]
Fit and prune: Fast and training-free visual token pruning for multi-modal large language models,
W. Ye, Q. Wu, W. Lin, and Y. Zhou, “Fit and prune: Fast and training-free visual token pruning for multi-modal large language models,” inAAAI, vol. 39, no. 21, 2025, pp. 22 128–22 136
2025
-
[30]
Stop looking for “important tokens
Z. Wen, Y. Gao, S. Wang, J. Zhang, Q. Zhang, W. Li, C. He, and L. Zhang, “Stop looking for “important tokens” in multimodal language models: Duplication matters more,” inEMNLP, 2025, pp. 9961–9980
2025
-
[31]
Determinantal point processes for machine learning,
A. Kulesza and B. Taskar, “Determinantal point processes for machine learning,”Foundations and Trends in Machine Learning, vol. 5, no. 2–3, pp. 123–286, 2012
2012
-
[32]
BLIP-2: Bootstrapping language-image pre-training with frozen image encoders and large language models,
J. Li, D. Li, S. Savarese, and S. Hoi, “BLIP-2: Bootstrapping language-image pre-training with frozen image encoders and large language models,” inICML, 2023, pp. 19 730–19 742
2023
-
[33]
LLaVA-PruMerge: Adaptive token reduction for efficient large multimodal models,
Y. Shang, M. Cai, B. Xu, Y. J. Lee, and Y. Yan, “LLaVA-PruMerge: Adaptive token reduction for efficient large multimodal models,” inICCV, 2025, pp. 22 857–22 867
2025
-
[34]
FlowCut: Rethinking redundancy via information flow for efficient vision- language models,
J. Tong, W. Jin, P . Qin, A. Li, Y. Zou, Y. Li, Y. Li, and R. Li, “FlowCut: Rethinking redundancy via information flow for efficient vision- language models,” inNeurIPS, vol. 38, 2025, pp. 94 946–94 973
2025
-
[35]
Sur les fonctions convexes et les in´egalit´es entre les valeurs moyennes,
J. L. W. V . Jensen, “Sur les fonctions convexes et les in´egalit´es entre les valeurs moyennes,”Acta mathematica, vol. 30, no. 1, pp. 175– 193, 1906
1906
-
[36]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agar- wal, G. Sastry, A. Askell, P . Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning transferable visual models from natural language supervision,” inICML, 2021, pp. 8748–8763
2021
-
[37]
Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality,
W.-L. Chiang, Z. Li, Z. Lin, Y. Sheng, Z. Wu, H. Zhang, L. Zheng, S. Zhuang, Y. Zhuang, J. E. Gonzalez, I. Stoica, and E. P . Xing, “Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality,” March 2023, accessed: May 17, 2026
2023
-
[38]
An image is worth 16x16 words: Transformers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: Transformers for image recognition at scale,” inICLR, 2021
2021
-
[39]
Root mean square layer normaliza- tion,
B. Zhang and R. Sennrich, “Root mean square layer normaliza- tion,” inNeurIPS, vol. 32, 2019, pp. 12 360–12 371
2019
-
[40]
GLU Variants Improve Transformer
N. Shazeer, “GLU variants improve transformer,”arXiv preprint arXiv:2002.05202, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[41]
Swin Transformer: Hierarchical vision transformer using shifted windows,
Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, S. Lin, and B. Guo, “Swin Transformer: Hierarchical vision transformer using shifted windows,” inICCV, 2021, pp. 10 012–10 022
2021
-
[42]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
J. Zhu, W. Wang, Z. Chen, Z. Liuet al., “InternVL3: Exploring ad- vanced training and test-time recipes for open-source multimodal models,”arXiv preprint arXiv:2504.10479, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
MileBench: Benchmarking MLLMs in long context,
D. Song, S. Chen, G. H. Chen, F. Yu, X. Wan, and B. Wang, “MileBench: Benchmarking MLLMs in long context,” inCOLM, 2024
2024
-
[44]
LLaVA- Video: Video instruction tuning with synthetic data,
Y. Zhang, J. Wu, W. Li, B. Li, Z. Ma, Z. Liu, and C. Li, “LLaVA- Video: Video instruction tuning with synthetic data,”TMLR, 2025
2025
-
[45]
Less is more: A simple yet effective token reduction method for efficient multi-modal LLMs,
D. Song, W. Wang, S. Chen, X. Wang, M. X. Guan, and B. Wang, “Less is more: A simple yet effective token reduction method for efficient multi-modal LLMs,” inCOLING, 2025, pp. 7614–7623
2025
-
[46]
Agilepruner: An empirical study of attention and diversity for adaptive visual token pruning in large vision-language models,
C. Baek, J. Song, S. Kim, and K. Kong, “Agilepruner: An empirical study of attention and diversity for adaptive visual token pruning in large vision-language models,”ICLR, 2026. IEEE TRANSACTIONS ON PATTERN ANAL YSIS AND MACHINE INTELLIGENCE 16
2026
-
[47]
Zoo-prune: Training-free token pruning via zeroth-order gradient estimation in vision-language models,
Y. Kim, Y. Zhang, H. Liu, A. Jung, S. Lee, and S. Hong, “Zoo-prune: Training-free token pruning via zeroth-order gradient estimation in vision-language models,” inCVPR, 2026
2026
-
[48]
Conical visual concentration for efficient large vision-language models,
L. Xing, Q. Huang, X. Dong, J. Lu, P . Zhang, Y. Zang, Y. Cao, C. He, J. Wang, F. Wu, and D. Lin, “Conical visual concentration for efficient large vision-language models,” inCVPR, 2025, pp. 14 593–14 603
2025
-
[49]
Beyond text-visual attention: Exploiting visual cues for effective token pruning in VLMs,
Q. Zhang, A. Cheng, M. Lu, R. Zhang, Z. Zhuo, J. Cao, S. Guo, Q. She, and S. Zhang, “Beyond text-visual attention: Exploiting visual cues for effective token pruning in VLMs,” inICCV, 2025, pp. 20 857–20 867
2025
-
[50]
Mak- ing the v in vqa matter: Elevating the role of image understanding in visual question answering,
Y. Goyal, T. Khot, D. Summers-Stay, D. Batra, and D. Parikh, “Mak- ing the v in vqa matter: Elevating the role of image understanding in visual question answering,” inCVPR, 2017, pp. 6904–6913
2017
-
[51]
GQA: A new dataset for real- world visual reasoning and compositional question answering,
D. A. Hudson and C. D. Manning, “GQA: A new dataset for real- world visual reasoning and compositional question answering,” inCVPR, 2019, pp. 6700–6709
2019
-
[52]
Learn to explain: Multimodal reasoning via thought chains for science question answering,
P . Lu, S. Mishra, T. Xia, L. Qiu, K.-W. Chang, S.-C. Zhu, O. Tafjord, P . Clark, and A. Kalyan, “Learn to explain: Multimodal reasoning via thought chains for science question answering,” inNeurIPS, vol. 35, 2022, pp. 2507–2521
2022
-
[53]
Towards VQA models that can read,
A. Singh, V . Natarajan, M. Shah, Y. Jiang, X. Chen, D. Batra, D. Parikh, and M. Rohrbach, “Towards VQA models that can read,” inCVPR, 2019, pp. 8317–8326
2019
-
[54]
ChartQA: A benchmark for question answering about charts with visual and logical reasoning,
A. Masry, D. X. Long, J. Q. Tan, S. Joty, and E. Hoque, “ChartQA: A benchmark for question answering about charts with visual and logical reasoning,” inFindings of ACL, 2022, pp. 2263–2279
2022
-
[55]
A diagram is worth a dozen images,
A. Kembhavi, M. Salvato, E. Kolve, M. Seo, H. Hajishirzi, and A. Farhadi, “A diagram is worth a dozen images,” inECCV, 2016, pp. 235–251
2016
-
[56]
MME: A com- prehensive evaluation benchmark for multimodal large language models,
C. Fu, P . Chen, Y. Shen, Y. Qin, M. Zhang, X. Lin, J. Yang, X. Zheng, K. Li, X. Sun, Y. Wu, R. Ji, C. Shan, and R. He, “MME: A com- prehensive evaluation benchmark for multimodal large language models,” inNeurIPS Datasets and Benchmarks Track, 2025
2025
-
[57]
MMBench: Is your multi-modal model an all-around player?
Y. Liu, H. Duan, Y. Zhang, B. Li, S. Zhang, W. Zhao, Y. Yuan, J. Wang, C. He, Z. Liuet al., “MMBench: Is your multi-modal model an all-around player?” inECCV, 2024, pp. 216–233
2024
-
[58]
MM-vet: Evaluating large multimodal models for integrated capabilities,
W. Yu, Z. Yang, L. Li, J. Wang, K. Lin, Z. Liu, X. Wang, and L. Wang, “MM-vet: Evaluating large multimodal models for integrated capabilities,” inICML, 2024, pp. 57 730–57 754
2024
-
[59]
Evaluating object hallucination in large vision-language models,
Y. Li, Y. Du, K. Zhou, J. Wang, X. Zhao, and J.-R. Wen, “Evaluating object hallucination in large vision-language models,” inEMNLP, 2023, pp. 292–305
2023
-
[60]
Microsoft COCO: Common objects in context,
T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P . Perona, D. Ramanan, P . Doll´ar, and C. L. Zitnick, “Microsoft COCO: Common objects in context,” inECCV, 2014, pp. 740–755
2014
-
[61]
HallusionBench: An advanced diagnostic suite for entangled language halluci- nation and visual illusion in large vision-language models,
T. Guan, F. Liu, X. Wu, R. Xian, Z. Li, X. Liu, X. Wang, L. Chen, F. Huang, Y. Yacoob, D. Manocha, and T. Zhou, “HallusionBench: An advanced diagnostic suite for entangled language halluci- nation and visual illusion in large vision-language models,” in CVPR, 2024, pp. 14 375–14 385
2024
-
[62]
Video-MME: The first-ever comprehensive evaluation benchmark of multi-modal LLMs in video analysis,
C. Fu, Y. Dai, Y. Luo, L. Li, S. Ren, R. Zhang, Z. Wang, C. Zhou, Y. Shen, M. Zhang, P . Chen, Y. Li, S. Lin, S. Zhao, K. Li, T. Xu, X. Zheng, E. Chen, C. Shan, R. He, and X. Sun, “Video-MME: The first-ever comprehensive evaluation benchmark of multi-modal LLMs in video analysis,” inCVPR, 2025, pp. 24 108–24 118
2025
-
[63]
LongVideoBench: A benchmark for long-context interleaved video-language understanding,
H. Wu, D. Li, B. Chen, and J. Li, “LongVideoBench: A benchmark for long-context interleaved video-language understanding,” in NeurIPS, vol. 37, 2024, pp. 28 828–28 857
2024
-
[64]
MVBench: A comprehensive multi- modal video understanding benchmark,
K. Li, Y. Wang, Y. He, Y. Li, Y. Wang, Y. Liu, Z. Wang, J. Xu, G. Chen, P . Luo, L. Wang, and Y. Qiao, “MVBench: A comprehensive multi- modal video understanding benchmark,” inCVPR, 2024, pp. 22 195–22 206
2024
-
[65]
VLMEvalKit: An open-source ToolKit for evaluating large multi-modality models,
H. Duan, J. Yang, Y. Qiao, X. Fang, L. Chen, Y. Liu, X. Dong, Y. Zang, P . Zhang, J. Wang, D. Lin, and K. Chen, “VLMEvalKit: An open-source ToolKit for evaluating large multi-modality models,” inACM MM, 2024, pp. 11 198–11 201
2024
-
[66]
LMMs-Eval: Reality check on the evaluation of large multimodal models,
K. Zhang, B. Li, P . Zhang, F. Pu, J. A. Cahyono, K. Hu, S. Liu, Y. Zhang, J. Yang, C. Li, and Z. Liu, “LMMs-Eval: Reality check on the evaluation of large multimodal models,” inFindings of NAACL, 2025, pp. 881–916
2025
-
[67]
PyTorch: An imperative style, high-performance deep learning library,
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, A. Desmaison, A. Kopf, E. Yang, Z. DeVito, M. Raison, A. Tejani, S. Chilamkurthy, B. Steiner, L. Fang, J. Bai, and S. Chintala, “PyTorch: An imperative style, high-performance deep learning library,” inNeurIPS, vol. 32, 2019, pp. 8024–8035
2019
-
[68]
H2O: Heavy- hitter oracle for efficient generative inference of large language models,
Z. Zhang, Y. Sheng, T. Zhou, T. Chen, L. Zheng, R. Cai, Z. Song, Y. Tian, C. R ´e, C. Barrett, Z. Wang, and B. Chen, “H2O: Heavy- hitter oracle for efficient generative inference of large language models,” inNeurIPS, vol. 36, 2023, pp. 34 661–34 710
2023
-
[69]
SnapKV: LLM knows what you are looking for before generation,
Y. Li, Y. Huang, B. Yang, B. Venkitesh, A. Locatelli, H. Ye, T. Cai, P . Lewis, and D. Chen, “SnapKV: LLM knows what you are looking for before generation,” inNeurIPS, vol. 37, 2024, pp. 22 947–22 970
2024
-
[70]
PyramidKV: Dynamic KV cache compression based on pyramidal information funneling,
Z. Cai, Y. Zhang, B. Gao, Y. Liu, Y. Li, T. Liu, K. Lu, W. Xiong, Y. Dong, J. Hu, and W. Xiao, “PyramidKV: Dynamic KV cache compression based on pyramidal information funneling,” in COLM, 2025
2025
-
[71]
LOOK-M: Look-once optimization in KV cache for effi- cient multimodal long-context inference,
Z. Wan, Z. Wu, C. Liu, J. Huang, Z. Zhu, P . Jin, L. Wang, and L. Yuan, “LOOK-M: Look-once optimization in KV cache for effi- cient multimodal long-context inference,” inFindings of EMNLP, 2024, pp. 4065–4078
2024
-
[72]
MEDA: Dynamic KV cache allocation for efficient multimodal long-context inference,
Z. Wan, H. Shen, X. Wang, C. Liu, Z. Mai, and M. Zhang, “MEDA: Dynamic KV cache allocation for efficient multimodal long-context inference,” inNAACL, 2025, pp. 2485–2497
2025
-
[73]
PruneVid: Visual token pruning for efficient video large language models,
X. Huang, H. Zhou, and K. Han, “PruneVid: Visual token pruning for efficient video large language models,” inFindings of ACL, 2025, pp. 19 959–19 973
2025
-
[74]
FastVID: Dynamic density pruning for fast video large language models,
L. Shen, G. Gong, T. He, Y. Zhang, P . Liu, S. Zhao, and G. Ding, “FastVID: Dynamic density pruning for fast video large language models,” inNeurIPS, vol. 38, 2025, pp. 123 553–123 581
2025
-
[75]
FlashVID: Efficient video large language models via training-free tree-based spatiotemporal token merging,
Z. Fan, K. Chen, R. Xing, Y. Li, L. Jiang, and Z. Tian, “FlashVID: Efficient video large language models via training-free tree-based spatiotemporal token merging,” inICLR, 2026. Yuhao Wangreceived the B.E. degree in Artifi- cial Intelligence from the School of Future Tech- nology, Dalian University of Technology (DUT), Dalian, China, in 2024. He is pursu...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.