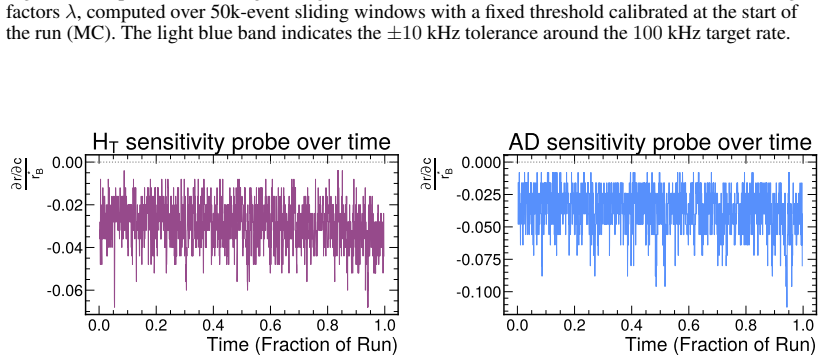
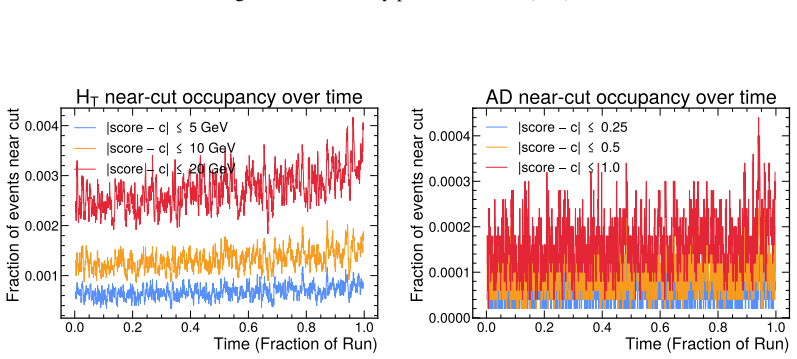
Learning to Trigger: Reinforcement Learning at the Large Hadron Collider
Pith reviewed 2026-06-30 10:18 UTC · model grok-4.3
The pith
A reinforcement learning agent adjusts LHC trigger thresholds in real time and transfers from simulation to real collision data without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
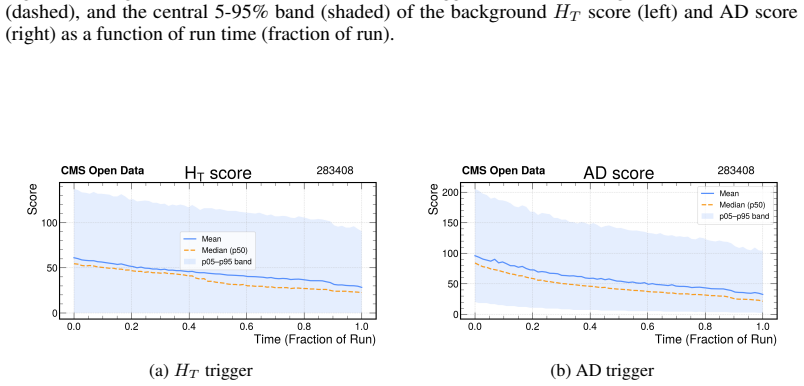
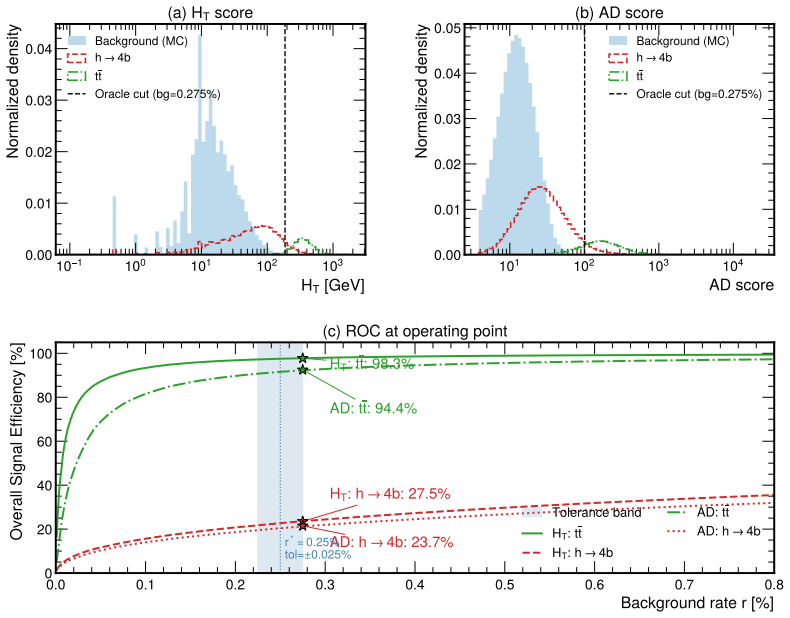
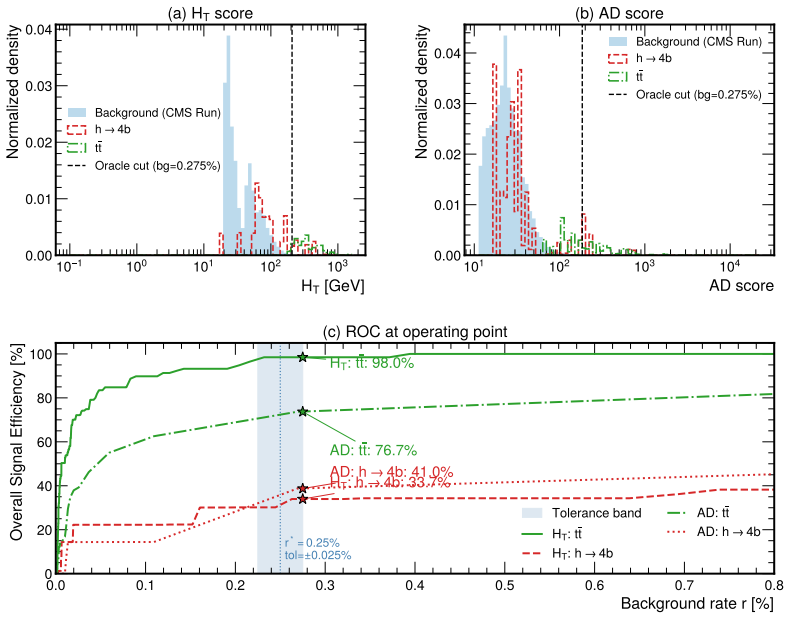
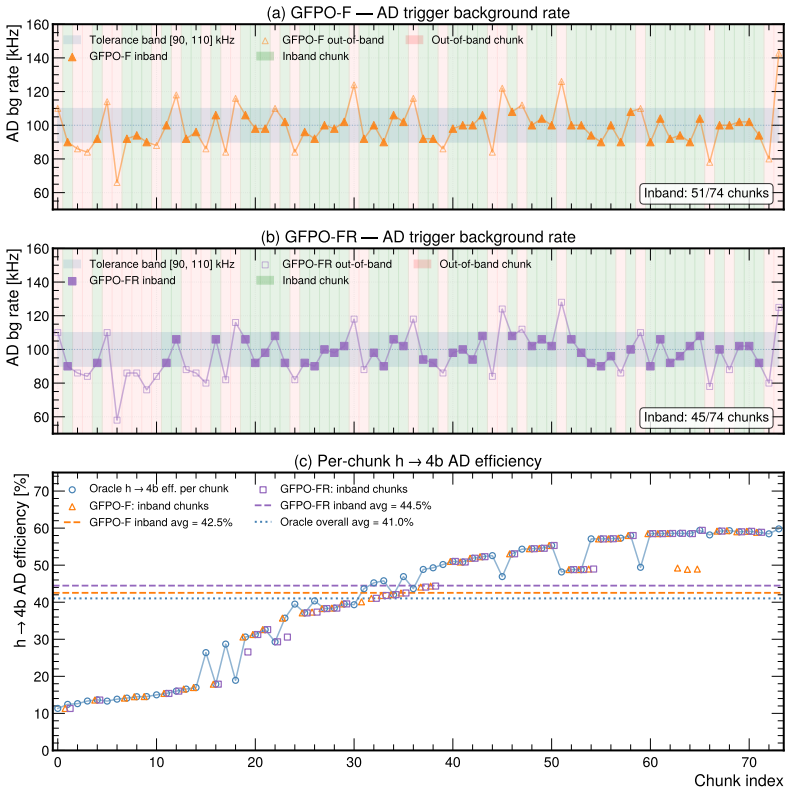
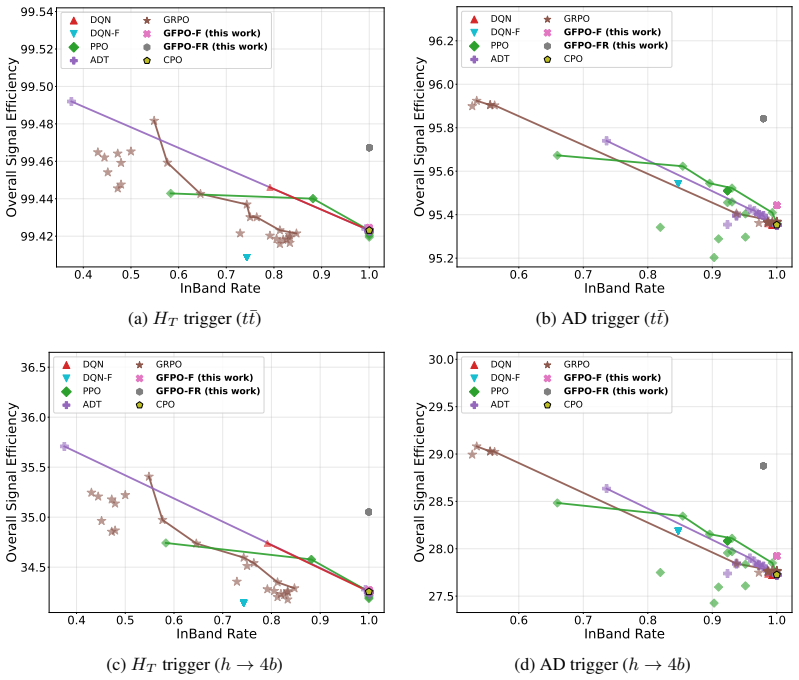
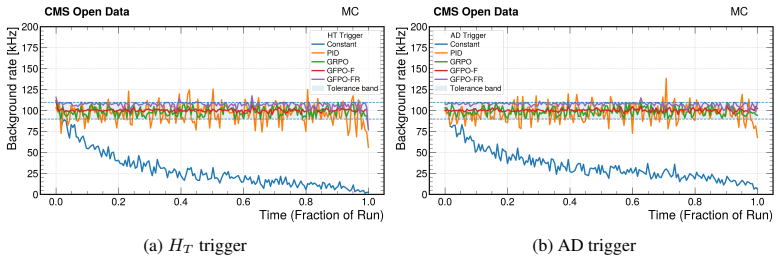
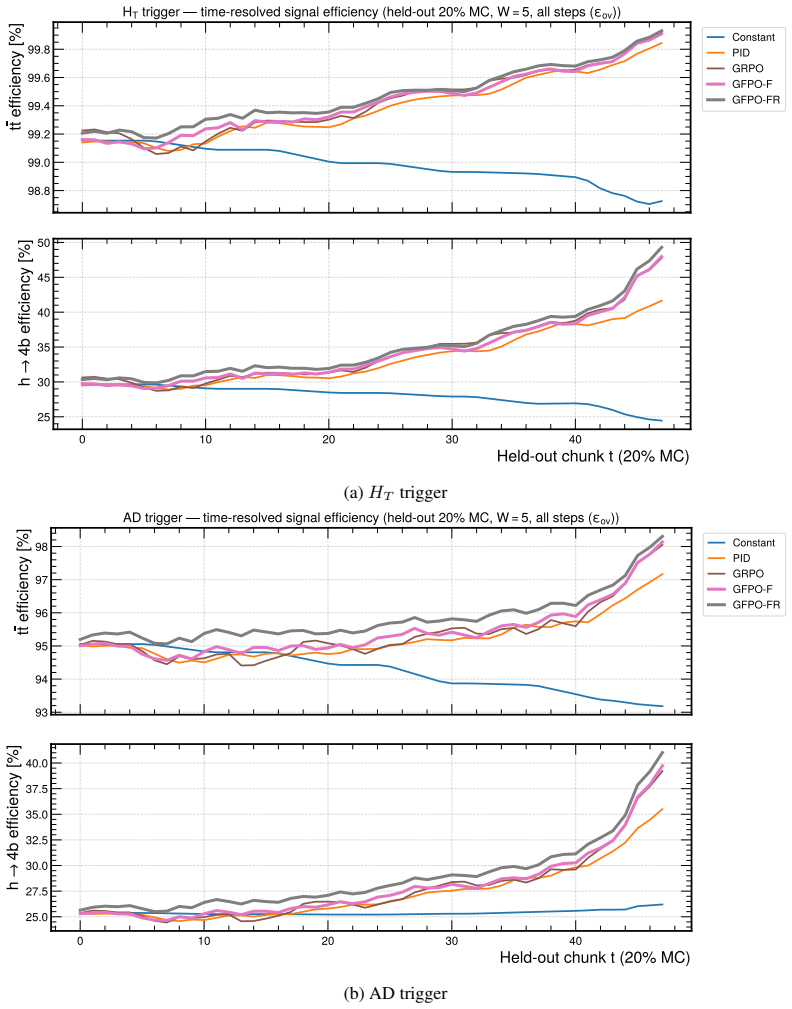
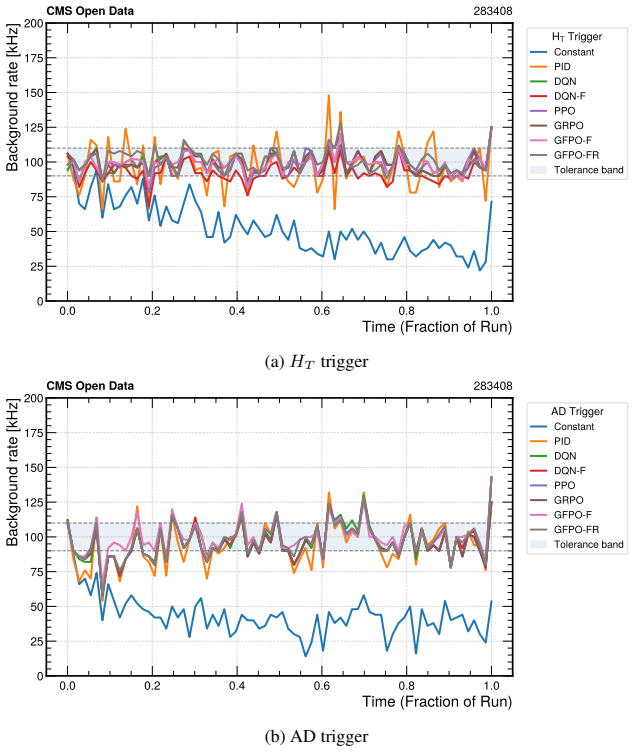
By casting threshold tuning as a streaming control task and adapting Group-Filtered Policy Optimization with two feasibility-enforcing variants, the authors show that the learned agent increases the fraction of time background rates remain inside tolerance by 48 percent (HT) and 28 percent (AD) on Monte Carlo streams and by 56 percent (HT) and 28 percent (AD) on real CMS Run 283408 data, while also raising signal efficiency on the in-tolerance intervals, constituting the first reported demonstration of reinforcement-learning trigger control on actual Large Hadron Collider collision data.
What carries the argument
Group-Filtered Policy Optimization (GFPO) agent adapted for streaming control that ingests recent rate and feature summaries to update trigger thresholds while enforcing background-rate feasibility.
If this is right
- Signal efficiency rises by up to 2 percent on the intervals where background rate stays inside tolerance.
- The same policy transfers directly to real data without any fine-tuning step.
- The approach works for both a pileup-sensitive total-energy trigger and an anomaly-detection trigger.
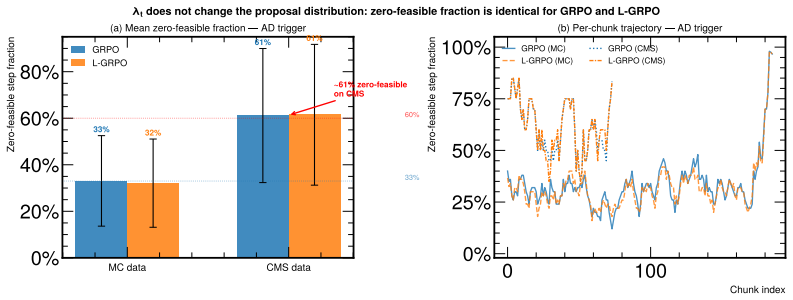
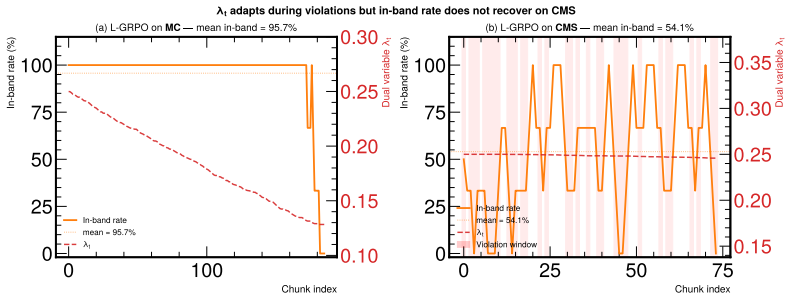
- Feasibility constraints introduced in the GFPO-F and GFPO-FR variants keep the background rate inside the allowed band during training.
Where Pith is reading between the lines
- Continuous online adaptation could reduce the frequency of manual retuning campaigns during long LHC running periods.
- Extending the same streaming formulation to additional trigger types could produce coordinated optimization across an entire trigger menu.
- If the observed sim-to-real transfer holds across multiple runs and years, the method may tolerate the gradual changes in detector response and beam conditions that occur in practice.
- Analogous streaming reinforcement-learning controllers could be examined in other high-rate scientific instruments that must filter data under strict bandwidth and latency limits.
Load-bearing premise
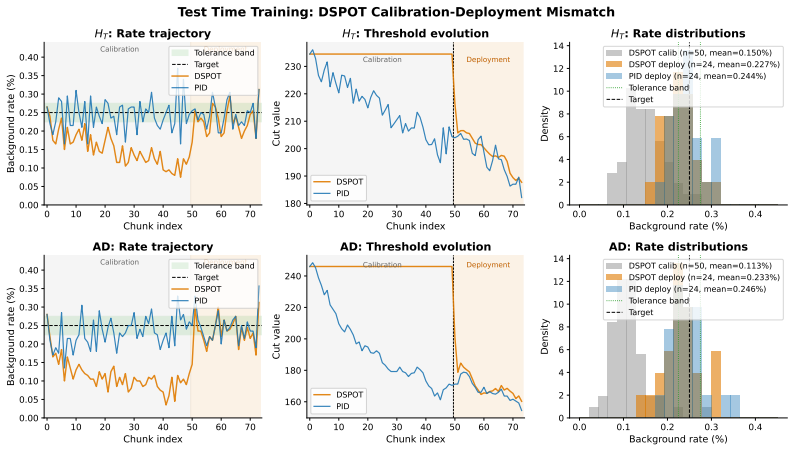
Monte Carlo streams used for training accurately capture the statistical properties and drift patterns of the real collision data the agent will meet at runtime.
What would settle it
Applying the trained agent to a new real collision run and measuring that the in-tolerance time fraction falls to or below the level achieved by the static baselines.
Figures


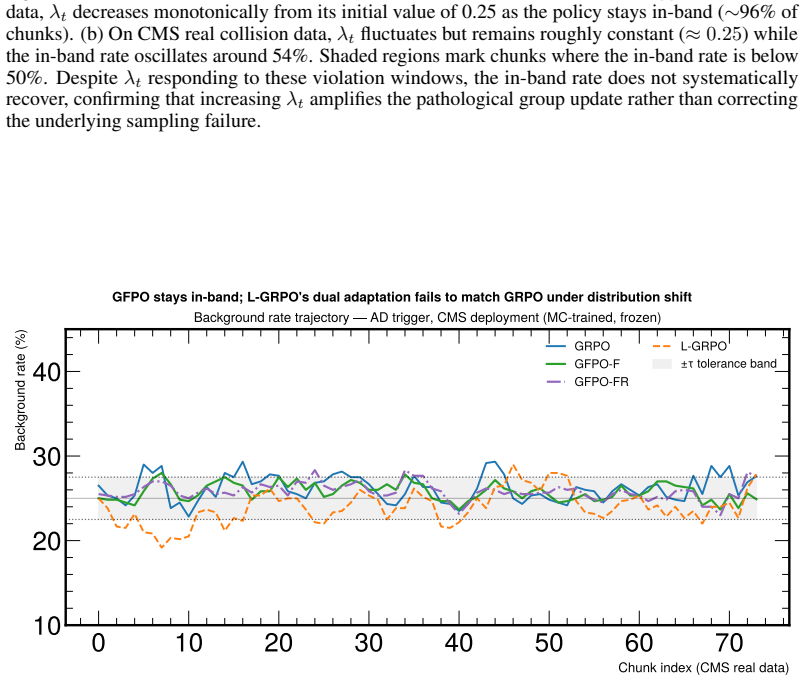
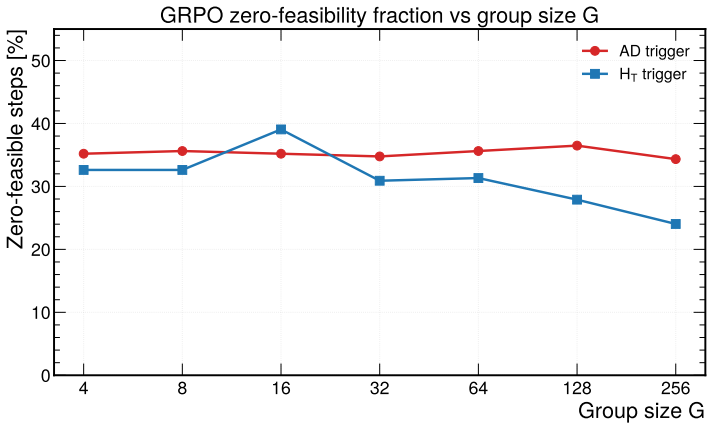
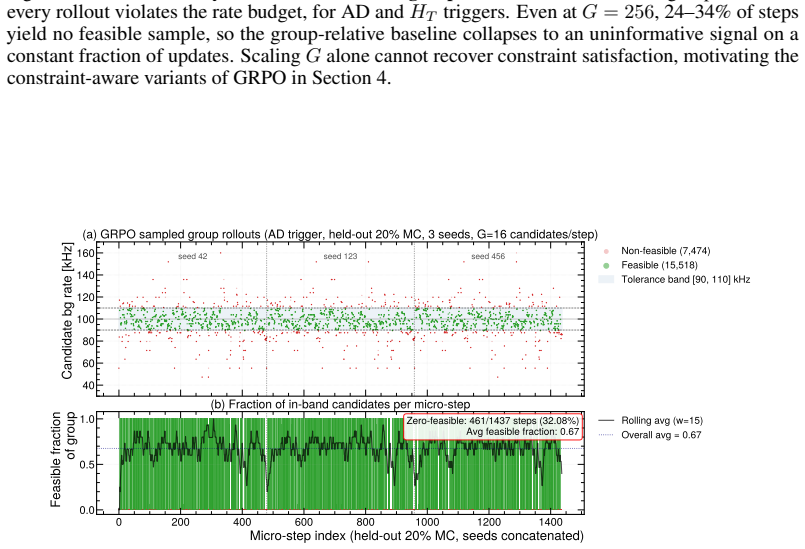
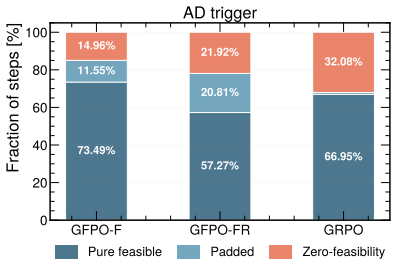
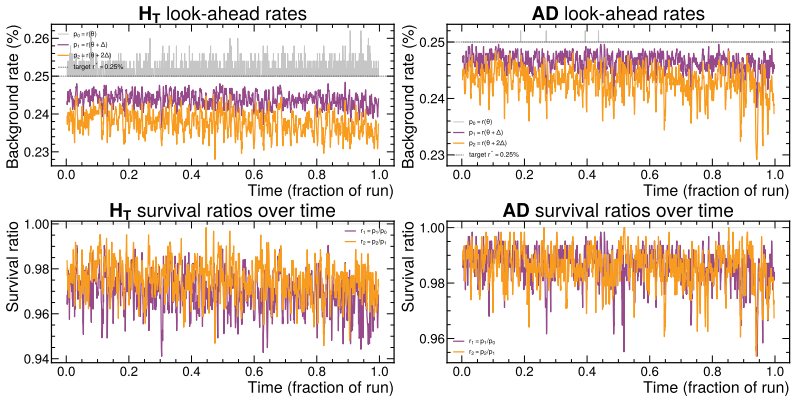
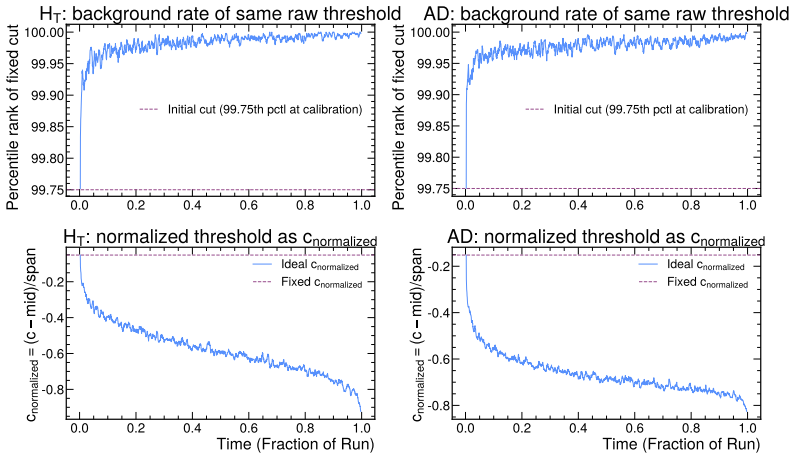
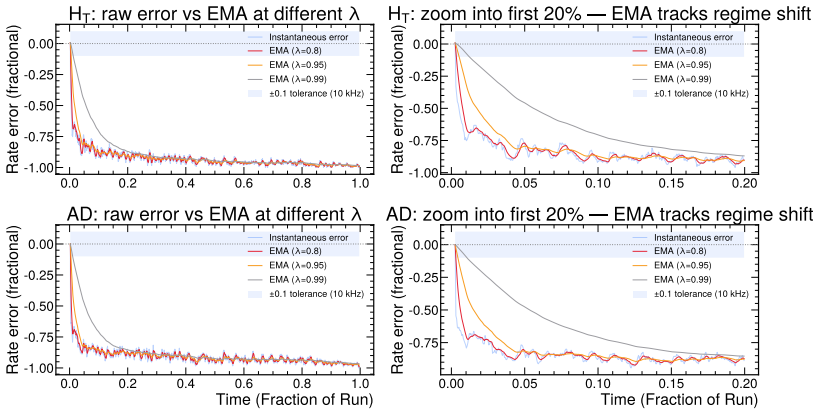
read the original abstract
High-throughput scientific facilities such as the Large Hadron Collider depend on real-time event filtering (\textit{triggering}) under tight constraints on bandwidth, latency, and storage. In practice, trigger menus are largely static and hand-tuned and can become suboptimal as detector conditions, pileup, and background composition drift over time. We cast online threshold tuning as a sequential decision-making problem: a reinforcement learning agent ingests streaming summaries of recent rates and signal-sensitive features and updates trigger thresholds to maximize signal efficiency while tracking a target background rate within a tolerance band. We adapt Group-Filtered Policy Optimization (GFPO) to streaming control and introduce two variants (GFPO-F, GFPO-FR) that enforce background rate feasibility during training. On a benchmark that emulates realistic collider operation, we study two representative triggers: a total transverse energy ($H_{T}$) trigger sensitive to pileup variation, and an anomaly-detection (AD) trigger based on reconstruction loss for rare or non-standard signatures. On Monte Carlo streams, our agent increases the fraction of in-tolerance time intervals by 48\% ($H_T$) and 28\% (AD), with a cumulative gain of up to 2\% in signal efficiency on those in-tolerance intervals. Transferring from simulation to \emph{real} collision data (CMS Run 283408), the same agent, without fine-tuning, achieves a 56\% ($H_T$) and 28\% (AD) in-tolerance improvement over baselines, with further signal-efficiency gain on both triggers. To our knowledge, this is the \emph{first} demonstration of RL-based trigger control on real Large Hadron Collider collision data. Code is available at https://github.com/Zixind/GFPO_LHC (see repo for details).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper casts LHC trigger threshold tuning as a streaming RL control problem and adapts Group-Filtered Policy Optimization (GFPO) with feasibility constraints (GFPO-F, GFPO-FR). On Monte Carlo streams the agent raises the fraction of in-tolerance intervals by 48% (HT) and 28% (AD) while adding up to 2% signal efficiency. The same policy, without fine-tuning, is reported to deliver 56% (HT) and 28% (AD) in-tolerance gains on real CMS Run 283408 collision data, presented as the first RL-based trigger demonstration on actual LHC data. Code is released.
Significance. If the sim-to-real transfer result is robust, the work would show that RL can maintain trigger performance under realistic drift without manual retuning, a practical advance for high-throughput scientific facilities. The open-source release and the explicit zero-shot transfer experiment are concrete strengths that aid reproducibility and allow independent verification.
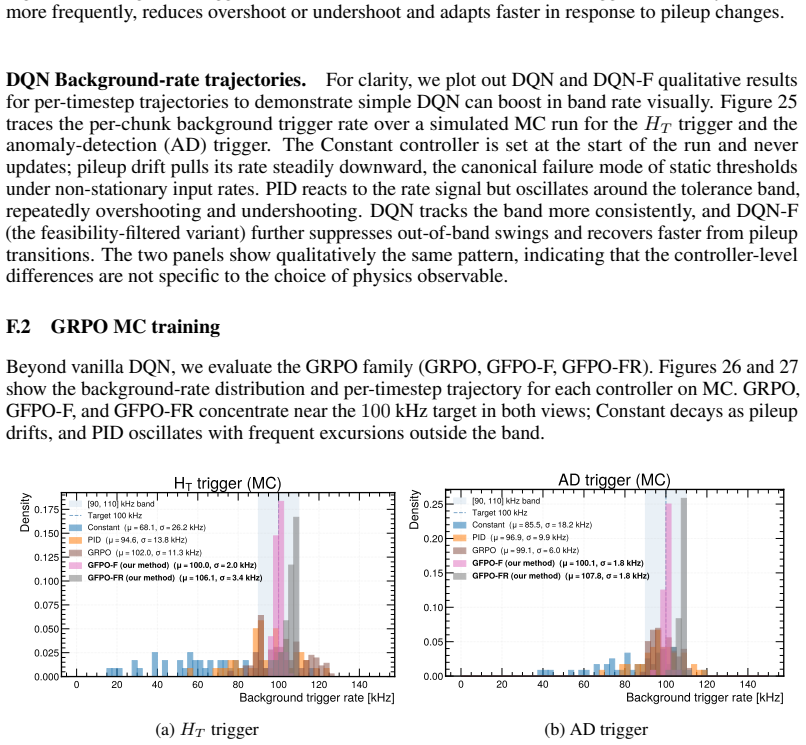
major comments (2)
- [Abstract] Abstract (transfer paragraph): the central claim of 56% (HT) and 28% (AD) in-tolerance improvement on CMS Run 283408 without fine-tuning rests on the unverified assumption that Monte Carlo training streams match the statistical properties of the real data. No distributional alignment metrics (rate histograms, pileup spectra, or feature-space distances) are supplied to support this match.
- [Abstract] Abstract: the reported performance numbers are given without error bars, confidence intervals, or any statistical test against the baselines. This omission directly affects the ability to judge whether the claimed gains are distinguishable from run-to-run variability.
minor comments (1)
- [Abstract] The abstract introduces GFPO-F and GFPO-FR but does not indicate where in the manuscript the precise feasibility constraints or the group-filtering mechanism are defined.
Simulated Author's Rebuttal
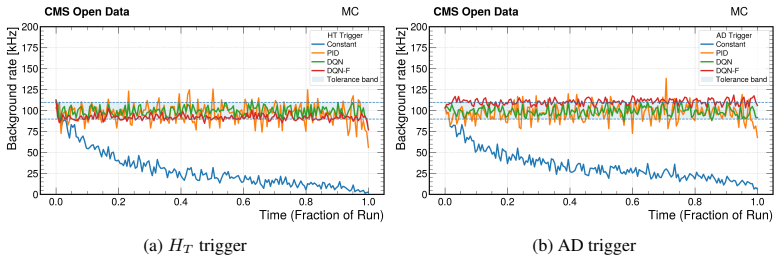
We thank the referee for the detailed review and constructive comments. We address each major point below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract (transfer paragraph): the central claim of 56% (HT) and 28% (AD) in-tolerance improvement on CMS Run 283408 without fine-tuning rests on the unverified assumption that Monte Carlo training streams match the statistical properties of the real data. No distributional alignment metrics (rate histograms, pileup spectra, or feature-space distances) are supplied to support this match.
Authors: We agree that explicit distributional alignment metrics would strengthen the sim-to-real transfer claim. Although the Monte Carlo samples were generated with standard CMS tuning procedures to reproduce observed pileup and rate distributions, the current manuscript does not include side-by-side histograms or distance measures. In the revision we will add rate histograms, pileup spectra, and feature-space distances (e.g., Wasserstein or MMD) between the training streams and Run 283408, together with a short discussion of residual mismatches and their expected impact on policy transfer. revision: yes
-
Referee: [Abstract] Abstract: the reported performance numbers are given without error bars, confidence intervals, or any statistical test against the baselines. This omission directly affects the ability to judge whether the claimed gains are distinguishable from run-to-run variability.
Authors: The referee correctly notes the absence of uncertainty quantification. The reported percentages are point estimates obtained from single long streams. In the revised manuscript we will recompute all in-tolerance and efficiency figures with bootstrap confidence intervals derived from multiple independent rollouts (both in simulation and on the real run) and will include paired statistical tests against the baseline controllers to assess whether the observed gains exceed run-to-run variability. revision: yes
Circularity Check
No circularity: empirical RL results on held-out MC and real data streams
full rationale
The paper reports an RL agent (GFPO variants) trained on Monte Carlo streams and evaluated zero-shot on held-out MC and real CMS Run 283408 data. Performance metrics (in-tolerance fraction, signal efficiency) are direct empirical comparisons against baselines. No equations, fitted parameters, or self-citation chains are shown that reduce the reported gains to inputs defined inside the paper. The derivation chain consists of standard RL adaptation plus experimental benchmarks; results remain falsifiable against external data streams.
Axiom & Free-Parameter Ledger
free parameters (1)
- GFPO learning-rate and feasibility parameters
axioms (1)
- domain assumption Streaming summaries of recent rates and signal-sensitive features contain sufficient information to decide threshold updates that track a target background rate.
Reference graph
Works this paper leans on
-
[1]
Summary of the trigger systems of the large hadron collider experiments alice, atlas, cms and lhcb.Journal of Physics G: Nuclear and Particle Physics, 52(3):030501, 2025
Johannes Albrecht, Leon Bozianu, Lukas Calefice, Sofia Cella, CE Cocha Toapaxi, Caterina Doglioni, VV Gligorov, James Andrew Gooding, Kaare Endrup Iversen, Patin Inkaew, et al. Summary of the trigger systems of the large hadron collider experiments alice, atlas, cms and lhcb.Journal of Physics G: Nuclear and Particle Physics, 52(3):030501, 2025
2025
-
[2]
Chinmaya Mahesh, Kristin Dona, David W Miller, and Yuxin Chen. Towards an inter- pretable data-driven trigger system for high-throughput physics facilities.arXiv preprint arXiv:2104.06622, 2021
-
[3]
The cms high level trigger.The European Physical Journal C-Particles and Fields, 46(3):605–667, 2006
CMS collaboration. The cms high level trigger.The European Physical Journal C-Particles and Fields, 46(3):605–667, 2006
2006
-
[4]
Performance of the atlas level-1 topological trigger in run 2.The European Physical Journal C, 82(1):7, 2022
Georges Aad, Brad Abbott, Dale Charles Abbott, A Abed Abud, Kira Abeling, Deshan Kavishka Abhayasinghe, Syed Haider Abidi, OS AbouZeid, NL Abraham, Halina Abramowicz, et al. Performance of the atlas level-1 topological trigger in run 2.The European Physical Journal C, 82(1):7, 2022
2022
-
[5]
Miller, Jennifer Ngadiuba, and Nhan Tran
Shaghayegh Emami, Cecilia Tosciri, Giovanna Salvi, Zixin Ding, Yuxin Chen, Abhijith Gan- drakota, Christian Herwig, David W. Miller, Jennifer Ngadiuba, and Nhan Tran. Towards a self-driving trigger at the LHC: Adaptive response in real time.Machine Learning: Science and Technology, 2026. doi: 10.1088/2632-2153/ae631f. URL https://iopscience.iop.org/ artic...
-
[6]
An automated bandwidth division for the lhcb upgrade trigger.Computing and Software for Big Science, 9(1):7, 2025
Timothy Evans, Conor Fitzpatrick, and Joshua Horswill. An automated bandwidth division for the lhcb upgrade trigger.Computing and Software for Big Science, 9(1):7, 2025
2025
-
[7]
Description and performance of track and primary-vertex reconstruc- tion with the cms tracker.Journal of Instrumentation, 9(10):P10009–P10009, 2014
CMS collaboration et al. Description and performance of track and primary-vertex reconstruc- tion with the cms tracker.Journal of Instrumentation, 9(10):P10009–P10009, 2014
2014
-
[8]
Sutton and Andrew G
Richard S. Sutton and Andrew G. Barto.Reinforcement Learning: An Introduction. MIT Press, Cambridge, MA, 1998
1998
-
[9]
Deep recurrent q-learning for partially observable mdps
Matthew J Hausknecht and Peter Stone. Deep recurrent q-learning for partially observable mdps. InAAAI fall symposia, volume 45, page 141, 2015
2015
-
[10]
Dream to control: Learning behaviors by latent imagination
Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Mohammad Norouzi. Dream to control: Learning behaviors by latent imagination. InInternational Conference on Learning Representa- tions, 2020. URLhttps://openreview.net/forum?id=S1lOTC4tDS
2020
-
[11]
Thickbrick: optimal event selection and categorization in high energy physics
Konstantin T Matchev and Prasanth Shyamsundar. Thickbrick: optimal event selection and categorization in high energy physics. part i. signal discovery.Journal of High Energy Physics, 2021(3):291, 2021
2021
-
[12]
Sequential anomaly detection using inverse reinforcement learning
Min-hwan Oh and Garud Iyengar. Sequential anomaly detection using inverse reinforcement learning. InProceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & data mining, pages 1480–1490, 2019
2019
-
[13]
Adt: Time series anomaly detection for cyber-physical systems via deep reinforcement learning.Computers & Security, 141:103825, 2024
Xue Yang, Enda Howley, and Michael Schukat. Adt: Time series anomaly detection for cyber-physical systems via deep reinforcement learning.Computers & Security, 141:103825, 2024
2024
-
[14]
Variational autoencoders for new physics mining at the large hadron collider.Journal of High Energy Physics, 2019(5):1–29, 2019
Olmo Cerri, Thong Q Nguyen, Maurizio Pierini, Maria Spiropulu, and Jean-Roch Vlimant. Variational autoencoders for new physics mining at the large hadron collider.Journal of High Energy Physics, 2019(5):1–29, 2019
2019
-
[15]
The atlas run-3 trigger menu
Sofia Cella. The atlas run-3 trigger menu. Technical report, ATL-COM-DAQ-2024-077, 2024
2024
-
[16]
About CMS Open Data, 2024
CMS Collaboration. About CMS Open Data, 2024. URL https://opendata.cern.ch/ docs/about-cms. Accessed: March 9, 2025. 13
2024
-
[17]
Sample more to think less: Group filtered policy optimization for concise reasoning
Vaishnavi Shrivastava, Ahmed Hassan Awadallah, Vidhisha Balachandran, Shivam Garg, Harki- rat Behl, and Dimitris Papailiopoulos. Sample more to think less: Group filtered policy optimization for concise reasoning. InThe Fourteenth International Conference on Learning Representations, 2026. URLhttps://openreview.net/forum?id=UKOqoULbZS
2026
-
[18]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Alphaflow: autonomous discovery and optimization of multi-step chemistry using a self-driven fluidic lab guided by reinforcement learning.Nature Communications, 14(1):1403, 2023
Amanda A V olk, Robert W Epps, Daniel T Yonemoto, Benjamin S Masters, Felix N Castellano, Kristofer G Reyes, and Milad Abolhasani. Alphaflow: autonomous discovery and optimization of multi-step chemistry using a self-driven fluidic lab guided by reinforcement learning.Nature Communications, 14(1):1403, 2023
2023
-
[20]
Reinforcement learning-trained optimisers and bayesian optimisation for online particle accelerator tuning
Jan Kaiser, Chenran Xu, Annika Eichler, Andrea Santamaria Garcia, Oliver Stein, Erik Brün- dermann, Willi Kuropka, Hannes Dinter, Frank Mayet, Thomas Vinatier, et al. Reinforcement learning-trained optimisers and bayesian optimisation for online particle accelerator tuning. Scientific reports, 14(1):15733, 2024
2024
-
[21]
Magnetic control of tokamak plasmas through deep reinforcement learning.Nature, 602(7897): 414–419, 2022
Jonas Degrave, Federico Felici, Jonas Buchli, Michael Neunert, Brendan Tracey, Francesco Carpanese, Timo Ewalds, Roland Hafner, Abbas Abdolmaleki, Diego de Las Casas, et al. Magnetic control of tokamak plasmas through deep reinforcement learning.Nature, 602(7897): 414–419, 2022
2022
-
[22]
Meta-aad: Active anomaly detection with deep reinforcement learning
Daochen Zha, Kwei-Herng Lai, Mingyang Wan, and Xia Hu. Meta-aad: Active anomaly detection with deep reinforcement learning. In2020 IEEE International Conference on Data Mining (ICDM), pages 771–780. IEEE, 2020
2020
-
[23]
Anomaly detection in streams with extreme value theory
Alban Siffer, Pierre-Alain Fouque, Alexandre Termier, and Christine Largouet. Anomaly detection in streams with extreme value theory. InProceedings of the 23rd ACM SIGKDD international conference on knowledge discovery and data mining, pages 1067–1075, 2017
2017
-
[24]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Does reinforcement learning really incentivize reasoning capacity in LLMs beyond the base model? InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Yang Yue, Shiji Song, and Gao Huang. Does reinforcement learning really incentivize reasoning capacity in LLMs beyond the base model? InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URLhttps://openreview.net/forum?id=4OsgYD7em5
2026
-
[26]
Ekaterina Govorkova, Ema Puljak, Thea Aarrestad, Thomas James, Vladimir Loncar, Maurizio Pierini, Adrian Alan Pol, Nicolo Ghielmetti, Maksymilian Graczyk, Sioni Summers, et al. Autoencoders on field-programmable gate arrays for real-time, unsupervised new physics detection at 40 mhz at the large hadron collider.Nature Machine Intelligence, 4(2):154–161, 2022
2022
-
[27]
A primer on reinforcement learning in medicine for clinicians.NPJ digital medicine, 7(1):337, 2024
Pushkala Jayaraman, Jacob Desman, Moein Sabounchi, Girish N Nadkarni, and Ankit Sakhuja. A primer on reinforcement learning in medicine for clinicians.NPJ digital medicine, 7(1):337, 2024
2024
-
[28]
Smooth imitation learning for online sequence prediction
Hoang Le, Andrew Kang, Yisong Yue, and Peter Carr. Smooth imitation learning for online sequence prediction. InInternational Conference on Machine Learning, pages 680–688. PMLR, 2016
2016
-
[29]
Human-level control through deep reinforcement learning.nature, 518(7540):529–533, 2015
V olodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A Rusu, Joel Veness, Marc G Bellemare, Alex Graves, Martin Riedmiller, Andreas K Fidjeland, Georg Ostrovski, et al. Human-level control through deep reinforcement learning.nature, 518(7540):529–533, 2015
2015
-
[30]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[31]
Constrained policy optimization
Joshua Achiam, David Held, Aviv Tamar, and Pieter Abbeel. Constrained policy optimization. InInternational conference on machine learning, pages 22–31. Pmlr, 2017. 14
2017
-
[32]
Performance of the atlas trigger system in 2015.The European Physical Journal C, 77(5):1–53, 2017
Morad Aaboud, Georges Aad, Brad Abbott, Jalal Abdallah, Baptiste Abeloos, Rosemarie Aben, OS AbouZeid, NL Abraham, Halina Abramowicz, Henso Abreu, et al. Performance of the atlas trigger system in 2015.The European Physical Journal C, 77(5):1–53, 2017
2015
-
[33]
Operation of the atlas trigger system in run 2.Journal of Instrumenta- tion, 15(10):P10004–P10004, 2020
Atlas Collaboration et al. Operation of the atlas trigger system in run 2.Journal of Instrumenta- tion, 15(10):P10004–P10004, 2020
2020
-
[34]
Technical Design Report for the Phase-II Upgrade of the ATLAS Tile Calorimeter
ATLAS Collaboration. Technical Design Report for the Phase-II Upgrade of the ATLAS Tile Calorimeter. Technical report, CERN, Geneva, 2017. URL https://cds.cern.ch/record/ 2285583
2017
-
[35]
Safe reinforcement learning via shielding
Mohammed Alshiekh, Roderick Bloem, Rüdiger Ehlers, Bettina Könighofer, Scott Niekum, and Ufuk Topcu. Safe reinforcement learning via shielding. InProceedings of the AAAI conference on artificial intelligence, 2018
2018
-
[36]
A dynamic safety shield for safe and efficient reinforcement learning of navigation tasks
Murad Dawood, Ahmed Shokry, and Maren Bennewitz. A dynamic safety shield for safe and efficient reinforcement learning of navigation tasks. In7th Annual Learning for Dynamics & Control Conference, pages 686–697. PMLR, 2025
2025
-
[37]
Marcin Andrychowicz, Anton Raichuk, Piotr Sta´nczyk, Manu Orsini, Sertan Girgin, Raphael Marinier, Léonard Hussenot, Matthieu Geist, Olivier Pietquin, Marcin Michalski, et al. What matters in on-policy reinforcement learning? a large-scale empirical study.arXiv preprint arXiv:2006.05990, 2020
-
[38]
Turn-ppo: Turn-level advantage estimation with ppo for improved multi-turn rl in agentic llms
Junbo Li, Peng Zhou, Rui Meng, Meet P Vadera, Lihong Li, and Yang Li. Turn-ppo: Turn-level advantage estimation with ppo for improved multi-turn rl in agentic llms. InFindings of the Association for Computational Linguistics: EACL 2026, pages 6227–6243, 2026
2026
-
[39]
Actor-critic algorithms.Advances in neural information processing systems, 12, 1999
Vijay Konda and John Tsitsiklis. Actor-critic algorithms.Advances in neural information processing systems, 12, 1999
1999
-
[40]
High- dimensional continuous control using generalized advantage estimation
John Schulman, Philipp Moritz, Sergey Levine, Michael Jordan, and Pieter Abbeel. High- dimensional continuous control using generalized advantage estimation. InProceedings of the International Conference on Learning Representations (ICLR), 2016
2016
-
[41]
Time limits in reinforcement learning
Fabio Pardo, Arash Tavakoli, Vitaly Levdik, and Petar Kormushev. Time limits in reinforcement learning. InInternational Conference on Machine Learning, pages 4045–4054. PMLR, 2018
2018
-
[42]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
The dependence of effective planning horizon on model accuracy
Nan Jiang, Alex Kulesza, Satinder Singh, and Richard Lewis. The dependence of effective planning horizon on model accuracy. InProceedings of the 2015 international conference on autonomous agents and multiagent systems, pages 1181–1189, 2015
2015
-
[44]
Routledge, 2021
Eitan Altman.Constrained Markov decision processes. Routledge, 2021
2021
-
[45]
Mankowitz, and Shie Mannor
Chen Tessler, Daniel J. Mankowitz, and Shie Mannor. Reward constrained policy optimization. InInternational Conference on Learning Representations, 2019. URL https://openreview. net/forum?id=SkfrvsA9FX
2019
-
[46]
Responsive safety in reinforcement learning by pid lagrangian methods
Adam Stooke, Joshua Achiam, and Pieter Abbeel. Responsive safety in reinforcement learning by pid lagrangian methods. InInternational conference on machine learning, pages 9133–9143. PMLR, 2020
2020
-
[47]
Trust region policy optimization
John Schulman, Sergey Levine, Pieter Abbeel, Michael Jordan, and Philipp Moritz. Trust region policy optimization. InInternational conference on machine learning, pages 1889–1897. PMLR, 2015
2015
-
[48]
Lhc data storage: Preparing for the challenges of run-3
Maria Arsuaga-Rios, Vladimír Bahyl, Manuel Batalha, Cédric Caffy, Eric Cano, Niccolo Capitoni, Cristian Contescu, Michael Davis, David Fernandez Alvarez, Jaroslav Guenther, et al. Lhc data storage: Preparing for the challenges of run-3. InEPJ Web of Conferences, volume 251, page 02023. EDP Sciences, 2021. 15
2021
-
[49]
Unsw-nb15: a comprehensive data set for network intrusion detection systems (unsw-nb15 network data set)
Nour Moustafa and Jill Slay. Unsw-nb15: a comprehensive data set for network intrusion detection systems (unsw-nb15 network data set). In2015 Military Communications and Information Systems Conference (MilCIS), pages 1–6. IEEE, 2015
2015
-
[50]
Evaluating real-time anomaly detection algorithms–the numenta anomaly benchmark
Alexander Lavin and Subutai Ahmad. Evaluating real-time anomaly detection algorithms–the numenta anomaly benchmark. In2015 IEEE 14th international conference on machine learning and applications (ICMLA), pages 38–44. IEEE, 2015
2015
-
[51]
The atlas trigger system for lhc run 3 and trigger performance in 2022.Journal of Instrumentation, 19(06): P06029, 2024
Georges Aad, Erlend Aakvaag, B Abbott, Kira Abeling, Nils Julius Abicht, SH Abidi, Asmaa Aboulhorma, Halina Abramowicz, Henso Abreu, Yiming Abulaiti, et al. The atlas trigger system for lhc run 3 and trigger performance in 2022.Journal of Instrumentation, 19(06): P06029, 2024
2022
-
[52]
A comparison of cpu and gpu implementations for the lhcb experiment run 3 trigger.Computing and Software for Big Science, 6(1):1, 2022
Roel Aaij, Marta Adinolfi, Salvatore Aiola, S Akar, Johannes Albrecht, M Alexander, S Amato, Yasmine Amhis, F Archilli, M Bala, et al. A comparison of cpu and gpu implementations for the lhcb experiment run 3 trigger.Computing and Software for Big Science, 6(1):1, 2022
2022
-
[53]
Laura Boggia, Carlos Cocha, Fotis Giasemis, Joachim Hansen, Patin Inkaew, Kaare Endrup Iversen, Pratik Jawahar, Henrique Pineiro Monteagudo, Micol Olocco, Sten Astrand, et al. Review of machine learning for real-time analysis at the large hadron collider experiments alice, atlas, cms and lhcb.arXiv preprint arXiv:2506.14578, 2025
-
[54]
Top-down design of protein architectures with reinforcement learning.Science, 380(6642):266–273, 2023
Isaac D Lutz, Shunzhi Wang, Christoffer Norn, Alexis Courbet, Andrew J Borst, Yan Ting Zhao, Annie Dosey, Longxing Cao, Jinwei Xu, Elizabeth M Leaf, et al. Top-down design of protein architectures with reinforcement learning.Science, 380(6642):266–273, 2023
2023
-
[55]
Rajat Khanda, Mohammad Baqar, Sambuddha Chakrabarti, and Satyasaran Changdar. Ex- tending group relative policy optimization to continuous control: A theoretical framework for robotic reinforcement learning.arXiv preprint arXiv:2507.19555, 2025
-
[56]
Anomaly transformer: Time series anomaly detection with association discrepancy
Jiehui Xu, Haixu Wu, Jianmin Wang, and Mingsheng Long. Anomaly transformer: Time series anomaly detection with association discrepancy. InInternational Conference on Learning Representations, 2022. URLhttps://openreview.net/forum?id=LzQQ89U1qm_
2022
-
[57]
Lhc machine.Journal of instrumentation, 3(08):S08001– S08001, 2008
Lyndon Evans and Philip Bryant. Lhc machine.Journal of instrumentation, 3(08):S08001– S08001, 2008
2008
-
[58]
Physics guided rnns for modeling dynamical systems: A case study in simulating lake temperature profiles
Xiaowei Jia, Jared Willard, Anuj Karpatne, Jordan Read, Jacob Zwart, Michael Steinbach, and Vipin Kumar. Physics guided rnns for modeling dynamical systems: A case study in simulating lake temperature profiles. InProceedings of the 2019 SIAM international conference on data mining, pages 558–566. SIAM, 2019
2019
-
[59]
Physics- guided neural networks (pgnn): An application in lake temperature modeling
Arka Daw, Anuj Karpatne, William D Watkins, Jordan S Read, and Vipin Kumar. Physics- guided neural networks (pgnn): An application in lake temperature modeling. InKnowledge guided machine learning, pages 353–372. Chapman and Hall/CRC, 2022
2022
-
[60]
Physics-informed recurrent neural network for time dynamics in optical resonances.Nature computational science, 2(3):169–178, 2022
Yingheng Tang, Jichao Fan, Xinwei Li, Jianzhu Ma, Minghao Qi, Cunxi Yu, and Weilu Gao. Physics-informed recurrent neural network for time dynamics in optical resonances.Nature computational science, 2(3):169–178, 2022
2022
-
[61]
Near-optimal reinforcement learning in polynomial time
Michael Kearns and Satinder Singh. Near-optimal reinforcement learning in polynomial time. Machine learning, 49(2):209–232, 2002
2002
-
[62]
An analysis of model-based interval estimation for markov decision processes.Journal of Computer and System Sciences, 74(8):1309–1331, 2008
Alexander L Strehl and Michael L Littman. An analysis of model-based interval estimation for markov decision processes.Journal of Computer and System Sciences, 74(8):1309–1331, 2008
2008
-
[63]
The role of baselines in policy gradient optimization.Advances in Neural Information Processing Systems, 35:17818–17830, 2022
Jincheng Mei, Wesley Chung, Valentin Thomas, Bo Dai, Csaba Szepesvari, and Dale Schuur- mans. The role of baselines in policy gradient optimization.Advances in Neural Information Processing Systems, 35:17818–17830, 2022
2022
-
[64]
Hongyi Zhou, Kai Ye, Erhan Xu, Jin Zhu, Ying Yang, Shijin Gong, and Chengchun Shi. Demystifying group relative policy optimization: Its policy gradient is a u-statistic.arXiv preprint arXiv:2603.01162, 2026. 16
-
[65]
Simulated dataset tttohadronic_tunecp5_13tev-powheg-pythia8 in miniaod- sim format for 2016 collision data
CMS Collaboration. Simulated dataset tttohadronic_tunecp5_13tev-powheg-pythia8 in miniaod- sim format for 2016 collision data. CERN Open Data Portal, 2024. URL https://opendata. cern.ch/record/67840. Data recorded in 2016 and published in 2024
2016
-
[66]
About cms
CERN Open Data Portal. About cms. https://opendata.cern.ch/docs/about-cms,
-
[67]
Accessed: 2026-01-03
2026
-
[68]
Deciphering the nature of the Higgs sector, volume 2
Daniel de Florian, Christophe Grojean, Fabio Maltoni, C Mariotti, A Nikitenko, M Pieri, P Savard, M Schumacher, R Aggleton, M Ahmad, et al.CERN Yellow Reports: Monographs, Vol 2 (2017): Handbook of LHC Higgs cross sections: 4. Deciphering the nature of the Higgs sector, volume 2. Cern, 2017
2017
-
[69]
Morad Aaboud, G Aad, B Abbott, B Abeloos, DK Abhayasinghe, SH Abidi, OS AbouZeid, NL Abraham, H Abramowicz, H Abreu, et al. Search for the higgs boson produced in association with a vector boson and decaying into two spin-zero particles in the h→aa→4b channel in pp collisions at √s= 13 tev with the atlas detector.Journal of High Energy Physics, 2018(10): ...
2018
-
[70]
Trigger throttling system for cms daq
A Racz. Trigger throttling system for cms daq. Technical report, CERN, 2000. URL https: //cds.cern.ch/record/479701
2000
-
[71]
Operation of the upgraded atlas central trigger processor during the lhc run 2.Journal of Instrumentation, 11(02):C02020–C02020, 2016
Henrik Bertelsen, G Carrillo Montoya, P-O Deviveiros, T Eifert, G Galster, J Glatzer, S Haas, A Marzin, MV Silva Oliveira, T Pauly, et al. Operation of the upgraded atlas central trigger processor during the lhc run 2.Journal of Instrumentation, 11(02):C02020–C02020, 2016
2016
-
[72]
Long short-term memory.Supervised sequence labelling with recurrent neural networks, pages 37–45, 2012
Alex Graves. Long short-term memory.Supervised sequence labelling with recurrent neural networks, pages 37–45, 2012
2012
-
[73]
Gate-variants of gated recurrent unit (gru) neural networks
Rahul Dey and Fathi M Salem. Gate-variants of gated recurrent unit (gru) neural networks. In 2017 IEEE 60th international midwest symposium on circuits and systems (MWSCAS), pages 1597–1600. IEEE, 2017
2017
-
[74]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[75]
Time2Vec: Learning a Vector Representation of Time
Seyed Mehran Kazemi, Rishab Goel, Sepehr Eghbali, Janahan Ramanan, Jaspreet Sahota, Sanjay Thakur, Stella Wu, Cathal Smyth, Pascal Poupart, and Marcus Brubaker. Time2vec: Learning a vector representation of time.arXiv preprint arXiv:1907.05321, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[76]
Temporal fusion transformers for interpretable multi-horizon time series forecasting.International journal of forecasting, 37(4): 1748–1764, 2021
Bryan Lim, Sercan Ö Arık, Nicolas Loeff, and Tomas Pfister. Temporal fusion transformers for interpretable multi-horizon time series forecasting.International journal of forecasting, 37(4): 1748–1764, 2021
2021
-
[77]
Dinamo: Dynamic and inter- pretable anomaly monitoring for large-scale particle physics experiments.Machine Learning: Science and Technology, 6(3):035050, 2025
Arsenii Gavrikov, Julián García Pardiñas, and Alberto Garfagnini. Dinamo: Dynamic and inter- pretable anomaly monitoring for large-scale particle physics experiments.Machine Learning: Science and Technology, 6(3):035050, 2025
2025
-
[78]
Abhijith Gandrakota. Real-time anomaly detection at the l1 trigger of cms experiment.arXiv preprint arXiv:2411.19506, 2024
-
[79]
2024 Data Collected with AXOL1TL Anomaly Detection at the CMS Level- 1 Trigger
CMS Collaboration. 2024 Data Collected with AXOL1TL Anomaly Detection at the CMS Level- 1 Trigger. Technical report, CERN, 2024. URLhttps://cds.cern.ch/record/2904695
-
[80]
Testing a neural network for anomaly detection in the cms global trigger test crate during run 3.Journal of Instrumentation, 19(03):C03029, 2024
Noah Zipper and CMS collaboration. Testing a neural network for anomaly detection in the cms global trigger test crate during run 3.Journal of Instrumentation, 19(03):C03029, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.