Absorbing Complexity: An Interaction-Native Knowledge Harness for Financial LLM Agents
Pith reviewed 2026-06-28 14:54 UTC · model grok-4.3
The pith
Financial LLM agents perform better when the system absorbs user and market complexity into structured knowledge rather than requiring repeated user restatements.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
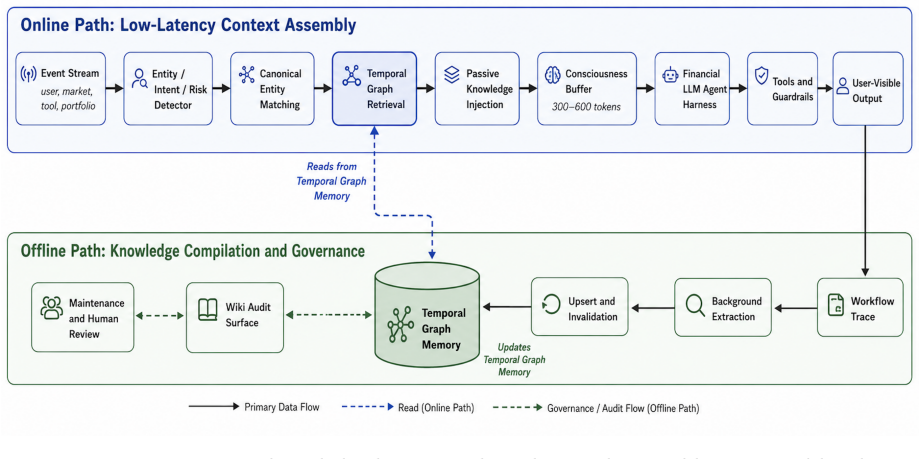
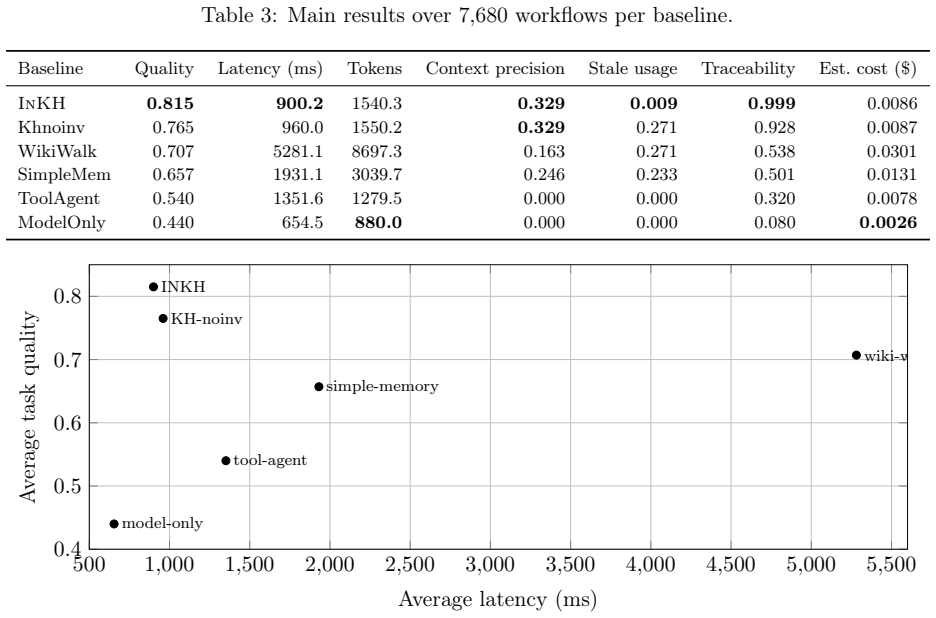
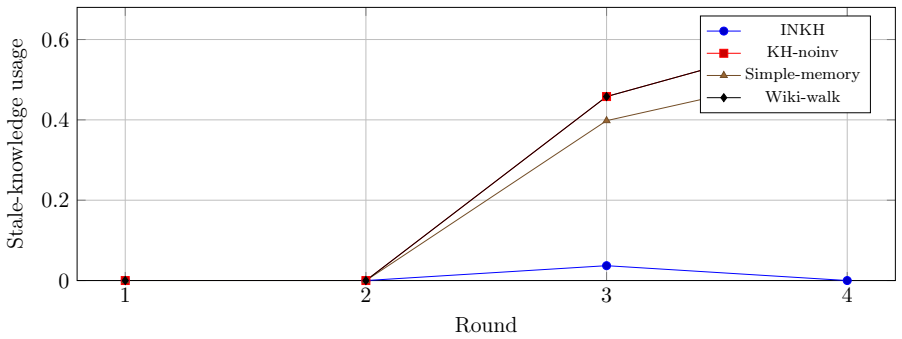
The interaction-native knowledge harness converts user, market, portfolio, and tool events into structured operational knowledge. It assembles a bounded working context buffer via passive knowledge injection before the main model step, uses temporal graph memory for low-latency retrieval, supplies a wiki audit surface for human-readable governance, and applies background extraction with maturity, decay, and write-time invalidation. On the controlled synthetic benchmark, InKH achieves mean task quality of 0.815 at 900 ms latency, reduces latency by 82.95 percent and token cost by 82.29 percent versus agent-driven wiki-walk memory, cuts stale-knowledge usage by 96.58 percent, and raises qualit
What carries the argument
The interaction-native knowledge harness (InKH), an architecture that turns events into structured operational knowledge through passive injection into a bounded context buffer, temporal graph memory, wiki audit surface, and background extraction with maturity, decay, and write-time invalidation.
If this is right
- Task quality reaches 0.815 while holding latency to 900 ms across the tested episodes.
- Stale-knowledge usage drops 96.58 percent versus agent-driven wiki-walk memory, lowering the chance of decisions based on outdated information.
- Traceability rises by 0.461, supporting stronger human-readable governance through the wiki audit surface.
- Token cost and latency each fall more than 82 percent versus the wiki-walk baseline while quality and traceability improve.
- Financial AI adoption improves when complexity is absorbed by the system instead of transferred to the user.
Where Pith is reading between the lines
- The same passive-injection and decay mechanisms could reduce context-restatement burden in other persistent-context domains such as medical decision support.
- The wiki audit surface might allow regulators to inspect agent reasoning without requiring full model retraining.
- Write-time invalidation combined with temporal graphs could be tested for preventing error propagation in multi-agent financial systems that share memory.
- If the bounded context buffer scales, it might limit token usage growth even as the number of monitored portfolios increases.
Load-bearing premise
The controlled synthetic benchmark with 24 seeds, 4 rounds, and 80 episodes per round accurately captures the latency, error, and auditability issues that arise in real financial workflows involving live market data and human oversight.
What would settle it
Running the InKH agents on live market data feeds with actual human traders and observing no reduction in decision errors or no gain in auditability compared with the wiki-walk baseline would challenge the central claim.
Figures
read the original abstract
Financial AI agents often fail for a simple reason: they make users carry the complexity. A user must repeatedly restate goals, risk preferences, portfolio context, past judgments, and shifting market assumptions, while the agent answers, retrieves, acts, and forgets. In finance, this is not just inconvenient. In tasks such as market analysis, copy-trading review, and trade preparation, forgotten context and stale memory can create latency, repeated errors, weak auditability, and unsafe decisions. We propose the interaction-native knowledge harness (InKH), an architecture for financial LLM agents that absorbs complexity into the system. InKH converts user, market, portfolio, and tool events into structured operational knowledge. It uses passive knowledge injection to assemble a bounded working context buffer before the main model step, temporal graph memory for low-latency retrieval, a wiki audit surface for human-readable governance, and background extraction with maturity, decay, and write-time invalidation. We evaluate InKH on a reproducible controlled synthetic benchmark with 24 random seeds, 4 rounds, 80 episodes per round, and 6 baselines, producing 46,080 baseline-conditioned evaluations. InKH achieves mean task quality of 0.815 at 900 ms latency. Compared with agent-driven wiki-walk memory, it reduces latency by 82.95 percent, token cost by 82.29 percent, and stale-knowledge usage by 96.58 percent, while improving quality by 0.108 and traceability by 0.461. Compared with a temporal-graph system without invalidation, it improves quality by 0.050 and reduces stale-memory usage by 96.58 percent with comparable serving cost. The results support a design thesis for financial AI: adoption happens when complexity is absorbed by the system rather than transferred to the user. The benchmark validates architecture-level behavior, not live trading performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the interaction-native knowledge harness (InKH) architecture for financial LLM agents that absorbs complexity into the system via passive knowledge injection to assemble a bounded working context buffer, temporal graph memory for low-latency retrieval, a wiki audit surface for governance, and background extraction with maturity, decay, and write-time invalidation. It evaluates the approach on a reproducible controlled synthetic benchmark using 24 random seeds, 4 rounds, and 80 episodes per round against 6 baselines, yielding 46,080 evaluations. InKH is reported to achieve mean task quality of 0.815 at 900 ms latency, with an 82.95% latency reduction, 82.29% token cost reduction, 96.58% reduction in stale-knowledge usage, +0.108 quality improvement, and +0.461 traceability improvement versus agent-driven wiki-walk memory (and smaller but positive gains versus a temporal-graph system without invalidation). The results are scoped to architecture-level behavior on the synthetic benchmark and not claimed to generalize to live trading.
Significance. If the empirical results hold under the stated synthetic conditions, the work supplies a concrete, reproducible comparison that supports the thesis that financial LLM agent performance and auditability improve when complexity is absorbed by the system rather than transferred to the user. The explicit benchmark parameters (seeds, rounds, episodes) and the six-baseline design enable direct architecture-level validation; the paper's clear scoping statement that results do not claim live-trading performance is a positive feature that keeps the claims proportionate.
minor comments (2)
- [Abstract] Abstract and Evaluation section: the derivation of the total 46,080 evaluations (24 seeds × 4 rounds × 80 episodes × 6 baselines) is arithmetically correct but not shown explicitly; adding a short sentence or footnote would improve immediate verifiability.
- [Evaluation] The manuscript states the benchmark is reproducible yet provides no table or pseudocode summarizing the exact episode generation rules, baseline implementations, or quality/traceability metric definitions; a compact methods table would strengthen the reproducibility claim without altering the central results.
Simulated Author's Rebuttal
We thank the referee for the positive and accurate summary of the InKH architecture, its evaluation on the synthetic benchmark, and the recommendation for minor revision. The assessment correctly notes the reproducibility parameters, the six-baseline design, and the explicit scoping that results apply to architecture-level behavior rather than live trading.
Circularity Check
No significant circularity
full rationale
The paper contains no derivation chain, equations, fitted parameters, or self-citations that reduce claims to internal definitions. All central results are direct empirical measurements (task quality, latency, stale-knowledge usage, etc.) on an explicitly described synthetic benchmark with 24 seeds, 4 rounds, 80 episodes/round, and 6 baselines. These are compared to external baselines rather than being forced by any internal construction or prior author work invoked as uniqueness. The architecture is described at the system level without any predictive modeling that could collapse into its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Synthetic episodes with random seeds sufficiently represent real financial task dynamics including context drift and audit needs.
invented entities (1)
-
Interaction-native knowledge harness (InKH)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Official blog post, 2026
Thinking Machines Lab.Interaction Models: A Scalable Approach to Human-AI Collaboration. Official blog post, 2026. Available at:https://thinkingmachines.ai/blog/interaction-models/
2026
-
[2]
GitHub Gist, 2026
Andrej Karpathy.LLM Wiki. GitHub Gist, 2026. Available at: https://gist.github.com/karpathy/ 442a6bf555914893e9891c11519de94f
2026
-
[3]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.NeurIPS, 2020
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.NeurIPS, 2020
2020
-
[4]
Improving Language Models by Retrieving from Trillions of Tokens.ICML, 2022
Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Rutherford, Katie Millican, George van den Driessche, Jean-Baptiste Lespiau, Bogdan Damoc, Aurelia Guy, et al. Improving Language Models by Retrieving from Trillions of Tokens.ICML, 2022
2022
-
[5]
ReAct: Synergizing Reasoning and Acting in Language Models.ICLR, 2023
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing Reasoning and Acting in Language Models.ICLR, 2023
2023
-
[6]
Toolformer: Language Models Can Teach Themselves to Use Tools.NeurIPS, 2023
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language Models Can Teach Themselves to Use Tools.NeurIPS, 2023. 14
2023
-
[7]
O’Brien, Carrie J
Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. Generative Agents: Interactive Simulacra of Human Behavior.UIST, 2023
2023
-
[8]
Reflexion: Language Agents with Verbal Reinforcement Learning.NeurIPS, 2023
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language Agents with Verbal Reinforcement Learning.NeurIPS, 2023
2023
-
[9]
Self-Refine: Iterative Refinement with Self-Feedback.NeurIPS, 2023
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al. Self-Refine: Iterative Refinement with Self-Feedback.NeurIPS, 2023
2023
-
[10]
Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection.ICLR, 2024
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection.ICLR, 2024
2024
-
[11]
MemGPT: Towards LLMs as Operating Systems
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. MemGPT: Towards LLMs as Operating Systems. arXiv:2310.08560, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
Suchow, and Khaldoun Khashanah
Yangyang Yu, Haohang Li, Zhi Chen, Yuechen Jiang, Yang Li, Denghui Zhang, Rong Liu, Jordan W. Suchow, and Khaldoun Khashanah. FinMem: A Performance-Enhanced LLM Trading Agent with Layered Memory and Character Design. arXiv:2311.13743, 2023
-
[13]
Evaluating Very Long-Term Conversational Memory of LLM Agents.ACL, 2024
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. Evaluating Very Long-Term Conversational Memory of LLM Agents.ACL, 2024
2024
-
[14]
ExpeL: LLM Agents Are Experiential Learners.AAAI, 2024
Andrew Zhao, Daniel Huang, Quentin Xu, Matthieu Lin, Yong-Jin Liu, and Gao Huang. ExpeL: LLM Agents Are Experiential Learners.AAAI, 2024
2024
-
[15]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. Voyager: An Open-Ended Embodied Agent with Large Language Models. arXiv:2305.16291, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory
Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai-Wei Chang, and Dong Yu. LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory. arXiv:2410.10813, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building Production- Ready AI Agents with Scalable Long-Term Memory. arXiv:2504.19413, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
A-MEM: Agentic Memory for LLM Agents
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-MEM: Agentic Memory for LLM Agents. arXiv:2502.12110, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Zep: A Temporal Knowledge Graph Architecture for Agent Memory
Preston Rasmussen, Pavlo Paliychuk, Travis Beauvais, Jack Ryan, and Daniel Chalef. Zep: A Temporal Knowledge Graph Architecture for Agent Memory. arXiv:2501.13956, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
arXiv preprint arXiv:2602.05665 , year=
Chang Yang, Chuang Zhou, Yilin Xiao, Su Dong, Luyao Zhuang, Yujing Zhang, Zhu Wang, Zijin Hong, Zheng Yuan, Zhishang Xiang, et al. Graph-based Agent Memory: Taxonomy, Techniques, and Applications. arXiv:2602.05665, 2026
-
[21]
FinanceBench: A New Benchmark for Financial Question Answering
Pranab Islam, Anand Kannappan, Douwe Kiela, Rebecca Qian, Nino Scherrer, and Bertie Vidgen. FinanceBench: A New Benchmark for Financial Question Answering. arXiv:2311.11944, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Antoine Bigeard, Langston Nashold, Rayan Krishnan, and Shirley Wu. Finance Agent Benchmark: Benchmarking LLMs on Real-world Financial Research Tasks. arXiv:2508.00828, 2025
-
[23]
FinAgentBench: A Benchmark Dataset for Agentic Retrieval in Financial Question Answering
Chanyeol Choi, Jihoon Kwon, Alejandro Lopez-Lira, Chaewoon Kim, Minjae Kim, Juneha Hwang, Jaeseon Ha, Hojun Choi, Suyeol Yun, Yongjin Kim, and Yongjae Lee. FinAgentBench: A Benchmark Dataset for Agentic Retrieval in Financial Question Answering. arXiv:2508.14052, 2025
-
[24]
BizFinBench: A Business-Driven Real-World Financial Benchmark for Evaluating LLMs
Guilong Lu, Xuntao Guo, Rongjunchen Zhang, Wenqiao Zhu, and Ji Liu. BizFinBench: A Business-Driven Real-World Financial Benchmark for Evaluating LLMs. arXiv:2505.19457, 2025
-
[25]
Ailiya Borjigin, Igor Stadnyk, Ben Bilski, Serhii Hovorov, and Sofiia Pidturkina. Execution Is the New Attack Surface: Survivability-Aware Agentic Crypto Trading with OpenClaw-Style Local Executors. arXiv:2603.10092, 2026. 15
-
[26]
Safe and Compliant Cross-Market Trade Execution via Constrained RL and Zero-Knowledge Audits
Ailiya Borjigin and Cong He. Safe and Compliant Cross-Market Trade Execution via Constrained RL and Zero-Knowledge Audits. arXiv:2510.04952, 2025
-
[27]
Louis.FRED API Documentation
Federal Reserve Bank of St. Louis.FRED API Documentation. Official documentation, accessed 2026. Available at:https://fred.stlouisfed.org/docs/api/fred/
2026
-
[28]
Securities and Exchange Commission.EDGAR Application Programming Interfaces
U.S. Securities and Exchange Commission.EDGAR Application Programming Interfaces. Of- ficial documentation, accessed 2026. Available at: https://www.sec.gov/search-filings/ edgar-application-programming-interfaces
2026
-
[29]
Official developer documentation, accessed 2026
Binance.Binance Spot API Documentation. Official developer documentation, accessed 2026. Available at: https://developers.binance.com/docs/binance-spot-api-docs/rest-api
2026
-
[30]
Required
Zep.Graphiti: Build Real-Time Knowledge Graphs for AI Agents. Official open-source repository, accessed 2026. Available at:https://github.com/getzep/graphiti. A Practical Engineering Appendix A.1 Implementation defaults Table 8 separatesrequired architectural commitmentsfromsuggested defaults. The latter are implementation recommendations rather than clai...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.