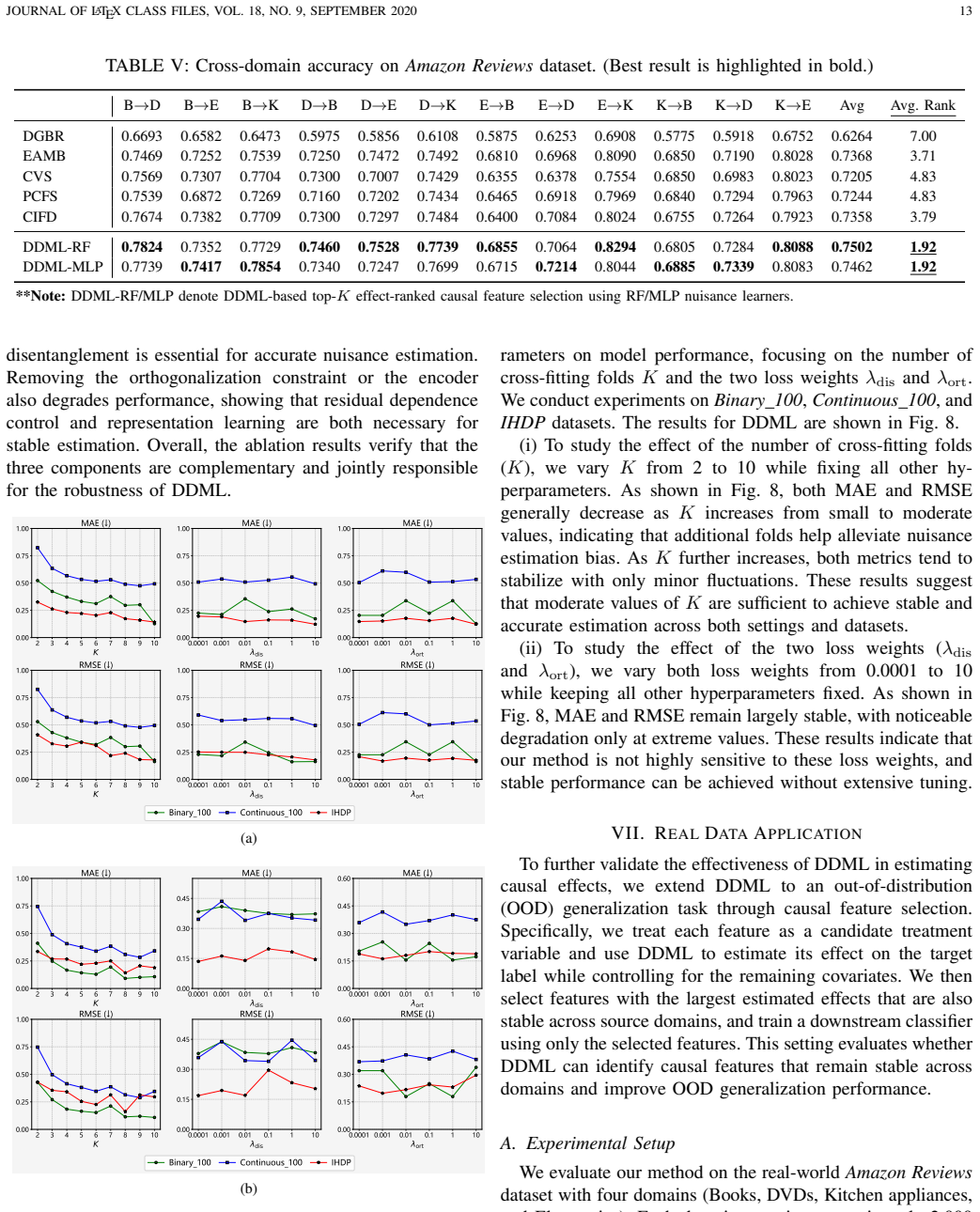
Disentangled Double Machine Learning for Accurate Causal Effect Estimation
Pith reviewed 2026-06-30 11:44 UTC · model grok-4.3
The pith
Disentangled Double Machine Learning improves causal effect estimates by separating covariates into confounders, treatment-specific factors, and outcome-specific factors while orthogonalizing residuals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
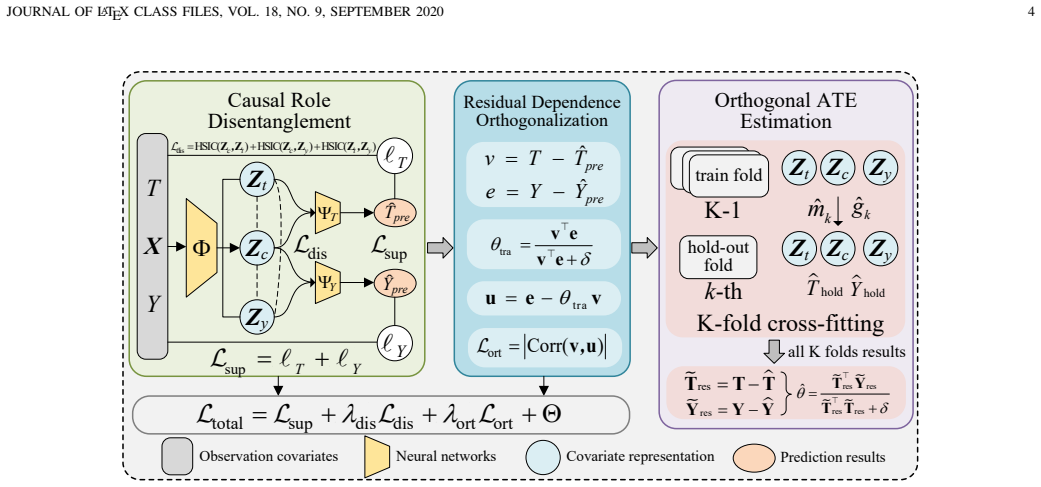
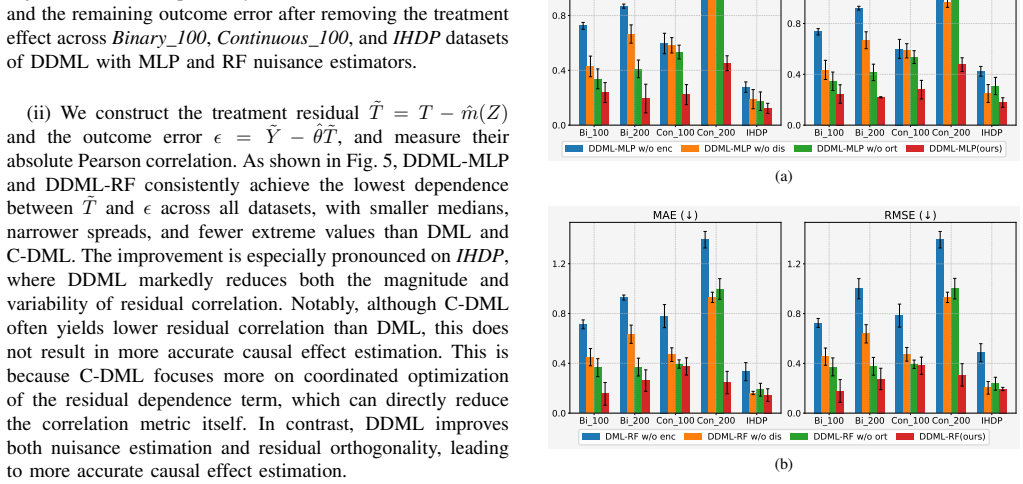
DDML integrates causal role disentanglement, which decomposes covariates into confounders, treatment-specific factors, and outcome-specific factors, with residual dependence orthogonalization that mitigates dependence between treatment residuals and outcome errors caused by nuisance estimation mistakes, producing more accurate causal effect estimates than standard DML.
What carries the argument
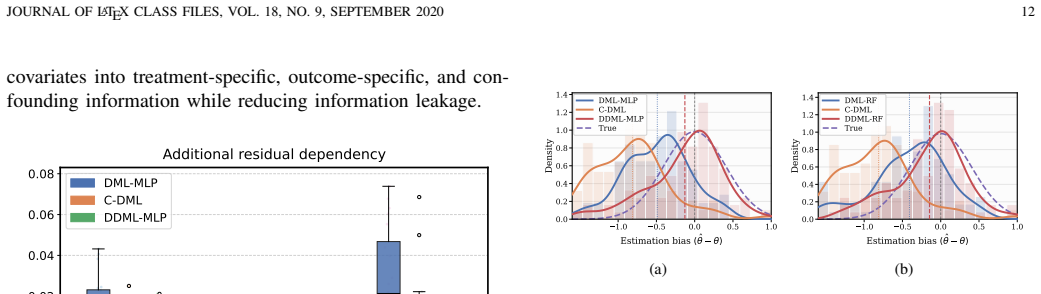
Causal role disentanglement strategy that partitions covariates into three latent groups to enable separate nuisance function estimation for treatment and outcome.
If this is right
- Nuisance functions for treatment and outcome can be estimated using only the relevant covariate subset rather than all covariates.
- Residual dependence introduced by finite-sample nuisance errors is reduced, tightening the final causal effect calculation.
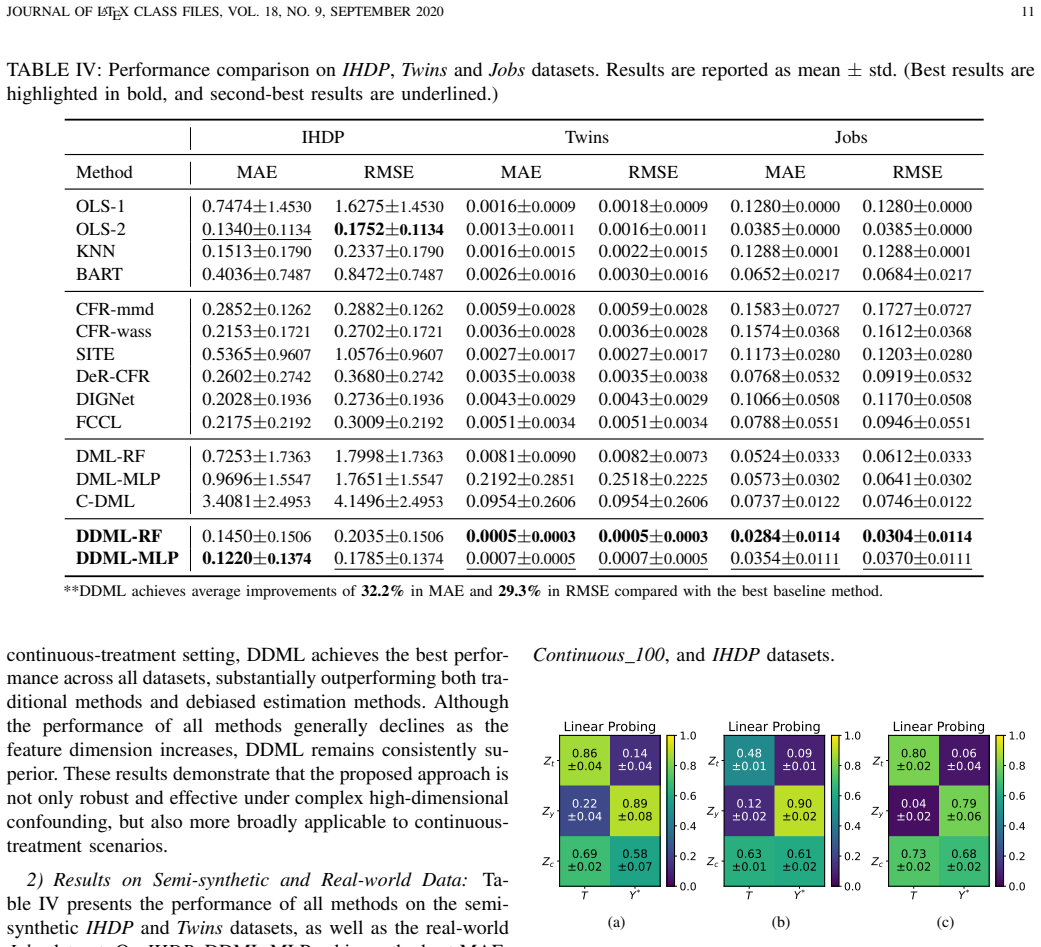
- Performance gains appear on synthetic data with known ground truth, semi-synthetic benchmarks, and real observational datasets.
- The method outperforms thirteen existing algorithms in both MAE and RMSE under the same evaluation protocols.
Where Pith is reading between the lines
- The approach may extend to other nuisance-based estimators beyond DML if the same three-group decomposition can be learned.
- In domains where covariate roles are known a priori, the disentanglement step could be replaced by direct feature selection without learning.
- If the decomposition is performed with an auxiliary model, its own estimation error becomes a new source of bias that would need separate analysis.
Load-bearing premise
Covariates can be decomposed into three cleanly separable latent groups consisting of confounders, treatment-specific factors, and outcome-specific factors.
What would settle it
A dataset or simulation in which the three latent covariate groups cannot be recovered separately, where DDML then shows no improvement or higher error than standard DML on the same causal effect task.
Figures




read the original abstract
Confounding bias is a key challenge in causal effect estimation from observational data. Double Machine Learning (DML) addresses this issue by estimating treatment and outcome nuisance functions, constructing treatment and outcome residuals, and estimating causal effects from the residuals. However, DML often produces biased and unstable estimates in highdimensional or finite-sample scenarios. One reason is that DML estimates nuisance functions using all covariates without disentangling distinct latent factors, resulting in unreliable nuisance function estimation. Another is that imprecise nuisance estimation further introduces residual dependence between the treatment residual and the remaining outcome error, undermining the accuracy of causal effect estimates. To address these issues, in this paper, we propose Disentangled Double Machine Learning (DDML), a novel algorithm that integrates two key strategies. First, a causal role disentanglement strategy decomposes covariates into confounders, treatment-specific factors, and outcomespecific factors for enabling reliable nuisance function estimation. And second, a residual dependence orthogonalization strategy mitigates residual dependence caused by nuisance estimation errors for enhancing the precision of causal effect estimates. Experimental results on synthetic, semi-synthetic, and real-world datasets demonstrate that DDML significantly outperforms 13 state-of-the-art baseline algorithms in both MAE and RMSE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Disentangled Double Machine Learning (DDML) as an extension of Double Machine Learning (DML) for causal effect estimation from observational data. It introduces a causal role disentanglement strategy that decomposes covariates into confounders (Z), treatment-specific factors (X_t), and outcome-specific factors (X_y) to improve nuisance function estimation, combined with a residual dependence orthogonalization strategy to mitigate bias from estimation errors in the residuals. The central empirical claim is that DDML significantly outperforms 13 state-of-the-art baselines in MAE and RMSE across synthetic, semi-synthetic, and real-world datasets.
Significance. If the three-way latent decomposition is recoverable from data and the orthogonalization step demonstrably reduces residual dependence without introducing new biases, DDML could offer a practical improvement for high-dimensional or small-sample causal inference. The experimental breadth across dataset types is a positive feature, but the absence of any identifiability result or robustness checks means the significance remains conditional on untested assumptions about the data-generating process.
major comments (3)
- [Method section] The method section (presumably §3) defines the decomposition X = (Z, X_t, X_y) and claims it enables reliable nuisance estimation, but supplies no identifiability theorem, uniqueness result, or sensitivity analysis showing that the learned factors correspond to their causal roles rather than optimization artifacts. This assumption is load-bearing for both the algorithmic contribution and the claim of superiority over standard DML.
- [Experiments section] §4 (experiments) reports superior MAE/RMSE on synthetic and semi-synthetic data, yet these datasets are generated exactly under the three-group structure assumed by DDML. No experiments test performance when the decomposition is only approximately satisfied or when mild violations of the latent-group assumption occur, undermining the generalization claim.
- [Method section] The residual dependence orthogonalization step is presented as mitigating dependence between treatment residual and outcome error, but no derivation or bound is given quantifying how much this step reduces the bias term relative to standard DML (e.g., no comparison of the resulting asymptotic variance or finite-sample error bounds).
minor comments (2)
- [Abstract] The abstract states that DML 'often produces biased and unstable estimates' without citing specific references or conditions under which this occurs; a brief literature pointer would clarify the baseline.
- [Method section] Notation for the three latent groups (Z, X_t, X_y) is introduced without an explicit diagram or table summarizing which covariates are used for each nuisance function, making the algorithmic description harder to follow on first reading.
Simulated Author's Rebuttal
We appreciate the referee's detailed review and constructive suggestions. We address each of the major comments below and outline the revisions we plan to make.
read point-by-point responses
-
Referee: [Method section] The method section (presumably §3) defines the decomposition X = (Z, X_t, X_y) and claims it enables reliable nuisance estimation, but supplies no identifiability theorem, uniqueness result, or sensitivity analysis showing that the learned factors correspond to their causal roles rather than optimization artifacts. This assumption is load-bearing for both the algorithmic contribution and the claim of superiority over standard DML.
Authors: We acknowledge that providing an identifiability theorem or uniqueness result would strengthen the theoretical foundation of the proposed decomposition. The current work motivates the decomposition from the causal roles in the data-generating process and demonstrates its utility through empirical results. We will add a sensitivity analysis section in the revised manuscript to assess the robustness of the learned factors to optimization variations and data perturbations. revision: yes
-
Referee: [Experiments section] §4 (experiments) reports superior MAE/RMSE on synthetic and semi-synthetic data, yet these datasets are generated exactly under the three-group structure assumed by DDML. No experiments test performance when the decomposition is only approximately satisfied or when mild violations of the latent-group assumption occur, undermining the generalization claim.
Authors: The referee correctly notes that the synthetic and semi-synthetic datasets are constructed according to the three-group structure. This design allows us to validate the method under its modeling assumptions, which is a common practice. To better support the generalization claim, we will conduct additional experiments involving approximate satisfaction of the decomposition and mild violations in the revised version of the paper. revision: yes
-
Referee: [Method section] The residual dependence orthogonalization step is presented as mitigating dependence between treatment residual and outcome error, but no derivation or bound is given quantifying how much this step reduces the bias term relative to standard DML (e.g., no comparison of the resulting asymptotic variance or finite-sample error bounds).
Authors: We agree that a formal derivation or bound on the bias reduction would be valuable. The orthogonalization strategy is introduced to explicitly minimize residual dependence, with its benefits shown through improved empirical performance compared to baselines. A complete asymptotic analysis is left for future work; however, we will include a discussion of the expected impact on bias and variance in the method section of the revision. revision: partial
Circularity Check
No circularity detected; DDML is an algorithmic proposal validated empirically
full rationale
The paper introduces DDML via two strategies (causal role disentanglement of covariates into confounders/treatment-specific/outcome-specific factors, plus residual orthogonalization) and reports empirical gains over baselines on synthetic/semi-synthetic/real datasets. No equations, fitted parameters renamed as predictions, self-citations, or uniqueness theorems appear in the provided text that would reduce any claimed result to its inputs by construction. The central claims rest on external experimental benchmarks rather than a closed derivation chain, satisfying the criteria for a self-contained non-circular contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Causal machine learning for predicting treatment outcomes,
S. Feuerriegel, D. Frauen, V . Melnychuk, J. Schweisthal, K. Hess, A. Curth, S. Bauer, N. Kilbertus, I. S. Kohane, and M. van der Schaar, “Causal machine learning for predicting treatment outcomes,”Nat. Med., vol. 30, no. 4, pp. 958–968, 2024
2024
-
[2]
A causal adjustment module for debiasing scene graph generation,
L. Liu, S. Sun, S. Zhi, F. Shi, Z. Liu, J. Heikkil ¨a, and Y . Liu, “A causal adjustment module for debiasing scene graph generation,” IEEE Trans. Pattern Anal. Mach. Intell. , vol. 47, no. 5, pp. 4024–4043, 2025. JOURNAL OF LATEX CLASS FILES, VOL. 18, NO. 9, SEPTEMBER 2020 15
2025
-
[3]
Causal inference via style bias deconfounding for domain generalization,
J. Li, D. Lin, H. Chen, H. Liu, L. Wan, and W. Feng, “Causal inference via style bias deconfounding for domain generalization,” IEEE Trans. Pattern Anal. Mach. Intell. , vol. 48, no. 5, pp. 5357–5370, 2026
2026
-
[4]
Data-driven causal effect estimation based on graphical causal modelling: A survey,
D. Cheng, J. Li, L. Liu, J. Liu, and T. D. Le, “Data-driven causal effect estimation based on graphical causal modelling: A survey,” ACM Comput. Surv., vol. 56, no. 5, pp. 1–37, 2024
2024
-
[5]
Propen- sity score analysis with survey weighted data,
G. Ridgeway, S. A. Kovalchik, B. A. Griffin, and M. U. Kabeto, “Propen- sity score analysis with survey weighted data,” J. Causal Inference , vol. 3, no. 2, pp. 237–249, 2015
2015
-
[6]
Matching on generalized propensity scores with continuous exposures,
X. Wu, F. Mealli, M.-A. Kioumourtzoglou, F. Dominici, and D. Braun, “Matching on generalized propensity scores with continuous exposures,” J. Amer. Stat. Assoc. , vol. 119, no. 545, pp. 757–772, 2024
2024
-
[7]
Estimating individual treatment effect: generalization bounds and algorithms,
U. Shalit, F. D. Johansson, and D. Sontag, “Estimating individual treatment effect: generalization bounds and algorithms,” in Proc. 34th Int. Conf. Mach. Learn. , 2017, pp. 3076–3085
2017
-
[8]
Representation learning for treatment effect estimation from observational data,
L. Yao, S. Li, Y . Li, M. Huai, J. Gao, and A. Zhang, “Representation learning for treatment effect estimation from observational data,” in Proc. 32nd Int. Conf. Neural Inf. Process. Syst. , 2018, pp. 2638–2648
2018
-
[9]
Estimating the effects of continuous-valued interventions using generative adversarial networks,
I. Bica, J. Jordon, and M. van der Schaar, “Estimating the effects of continuous-valued interventions using generative adversarial networks,” in Proc. 34th Int. Conf. Neural Inf. Process. Syst. , 2020, pp. 16 434– 16 445
2020
-
[10]
Double/debiased machine learning for treatment and structural parameters,
V . Chernozhukov, D. Chetverikov, M. Demirer, E. Duflo, C. Hansen, W. Newey, and J. Robins, “Double/debiased machine learning for treatment and structural parameters,” Econ. J., vol. 21, no. 1, pp. C1– C68, 2018
2018
-
[11]
Coordinated double machine learning,
N. Fingerhut, M. Sesia, and Y . Romano, “Coordinated double machine learning,” in Proc. 39th Int. Conf. Mach. Learn. , 2022, pp. 6499–6513
2022
-
[12]
A survey on causal inference,
L. Yao, Z. Chu, S. Li, Y . Li, J. Gao, and A. Zhang, “A survey on causal inference,” ACM Trans. Knowl. Discov. Data , vol. 15, no. 5, pp. 1–46, 2021
2021
-
[13]
Matching via dimensionality reduction for estimation of treatment effects in digital marketing cam- paigns,
S. Li, N. Vlassis, J. Kawale, and Y . Fu, “Matching via dimensionality reduction for estimation of treatment effects in digital marketing cam- paigns,” in Proc. 25th Int. Joint Conf. Artif. Intell., 2016, pp. 3768–3774
2016
-
[14]
Debiased inverse propensity score weight- ing for estimation of average treatment effects with high-dimensional confounders,
Y . Wang and R. D. Shah, “Debiased inverse propensity score weight- ing for estimation of average treatment effects with high-dimensional confounders,” Ann. Stat., vol. 52, no. 5, pp. 1978–2003, 2024
1978
-
[15]
Robust inference using inverse probability weight- ing,
X. Ma and J. Wang, “Robust inference using inverse probability weight- ing,” J. Amer. Stat. Assoc. , vol. 115, no. 532, pp. 1851–1860, 2020
2020
-
[16]
Doubly robust estimation of causal effects,
M. J. Funk, D. Westreich, C. Wiesen, T. St ¨urmer, M. A. Brookhart, and M. Davidian, “Doubly robust estimation of causal effects,” Am. J. Epidemiol., vol. 173, no. 7, pp. 761–767, 2011
2011
-
[17]
Doubly robust estimation of optimal dynamic treatment regimes with multicategory treatments and survival outcomes,
Z. Zhang, D. Yi, and Y . Fan, “Doubly robust estimation of optimal dynamic treatment regimes with multicategory treatments and survival outcomes,” Stat. Med., vol. 41, no. 24, pp. 4903–4923, 2022
2022
-
[18]
Bayesian ensemble learn- ing,
H. Chipman, E. George, and R. McCulloch, “Bayesian ensemble learn- ing,” in Proc. 20th Int. Conf. Neural Inf. Process. Syst. , 2006, pp. 265– 272
2006
-
[19]
Bart: Bayesian additive regression trees,
H. A. Chipman, E. I. George, and R. E. McCulloch, “Bart: Bayesian additive regression trees,” Ann. Appl. Stat. , pp. 266–298, 2010
2010
-
[20]
Learning representations for counterfactual inference,
F. Johansson, U. Shalit, and D. Sontag, “Learning representations for counterfactual inference,” in Proc. 33rd Int. Conf. Mach. Learn. , 2016, pp. 3020–3029
2016
-
[21]
Proximity matters: Local proximity enhanced balancing for treatment effect esti- mation,
H. Wang, Z. Chen, Z. Liu, X. Chen, H. Li, and Z. Lin, “Proximity matters: Local proximity enhanced balancing for treatment effect esti- mation,” in Proc. 31st ACM SIGKDD Conf. Knowl. Discov. Data Min. , 2025, pp. 2927–2937
2025
-
[22]
Causal effect inference with deep latent-variable models,
C. Louizos, U. Shalit, J. M. Mooij, D. Sontag, R. Zemel, and M. Welling, “Causal effect inference with deep latent-variable models,” in Proc. 31st Int. Conf. Neural Inf. Process. Syst. , 2017, pp. 6449–6459
2017
-
[23]
GANITE: Estimation of individualized treatment effects using generative adversarial nets,
J. Yoon, J. Jordon, and M. van der Schaar, “GANITE: Estimation of individualized treatment effects using generative adversarial nets,” in Proc. 6th Int. Conf. Learn. Represent. , 2018. [Online]. Available: https://openreview.net/pdf?id=ByKWUeW A-
2018
-
[24]
Adversarial balancing-based representation learning for causal effect inference with observational data,
X. Du, L. Sun, W. Duivesteijn, A. Nikolaev, and M. Pechenizkiy, “Adversarial balancing-based representation learning for causal effect inference with observational data,” Data Min. Knowl. Discov. , vol. 35, no. 4, pp. 1713–1738, 2021
2021
-
[25]
Glcn: Treatment effect estimation via global-local networks with adversarial debiasing,
S. Qiang, “Glcn: Treatment effect estimation via global-local networks with adversarial debiasing,” in Proc. 34th ACM Int. Conf. Inf. Knowl. Manag., 2025, pp. 5136–5140
2025
-
[26]
Treatment effect estimation with data-driven variable decomposition,
K. Kuang, P. Cui, B. Li, M. Jiang, S. Yang, and F. Wang, “Treatment effect estimation with data-driven variable decomposition,” in Proc. 31st AAAI Conf. Artif. Intell. , 2017, pp. 140–146
2017
-
[27]
Learning disentangled representations for counterfactual regression,
N. Hassanpour and R. Greiner, “Learning disentangled representations for counterfactual regression,” in Proc. 7th Int. Conf. Learn. Represent., 2019. [Online]. Available: https://openreview.net/forum?id= HkxBJT4YvB
2019
-
[28]
Learning decomposed representations for treatment effect estimation,
A. Wu, J. Yuan, K. Kuang, B. Li, R. Wu, Q. Zhu, Y . Zhuang, and F. Wu, “Learning decomposed representations for treatment effect estimation,” IEEE Trans. Knowl. Data Eng. , vol. 35, no. 5, pp. 4989–5001, 2023
2023
-
[29]
Dignet: Learning decomposed patterns in representation balancing for treatment effect estimation,
Y . Huang, W. Siyi, C. H. Leung, Q. Wu, D. Wang, and Z. Huang, “Dignet: Learning decomposed patterns in representation balancing for treatment effect estimation,” Trans. Mach. Learn. Res. , 2024. [Online]. Available: https://openreview.net/pdf?id=Z20FInfWlm
2024
-
[30]
Counter- factual contrastive learning with normalizing flows for robust treatment effect estimation,
J. Zhang, E. Eldele, F. Cao, Y . Wang, X. Li, and J. Liang, “Counter- factual contrastive learning with normalizing flows for robust treatment effect estimation,” in Proc. 42nd Int. Conf. Mach. Learn. , 2025, pp. 74 819–74 839
2025
-
[31]
Estimating identifiable causal effects through double machine learning,
Y . Jung, J. Tian, and E. Bareinboim, “Estimating identifiable causal effects through double machine learning,” in Proc. 35th AAAI Conf. Artif. Intell., 2021, pp. 12 113–12 122
2021
-
[32]
Automatic debiased machine learning of causal and structural effects,
V . Chernozhukov, W. K. Newey, and R. Singh, “Automatic debiased machine learning of causal and structural effects,”Econometrica, vol. 90, no. 3, pp. 967–1027, 2022
2022
-
[33]
Visual domain adaptation with manifold embedded distribution alignment,
J. Wang, W. Feng, Y . Chen, H. Yu, M. Huang, and P. S. Yu, “Visual domain adaptation with manifold embedded distribution alignment,” in Proc. 26th ACM Int. Conf. Multimedia , 2018, pp. 402–410
2018
-
[34]
Causal feature selection in the presence of sample selection bias,
S. Yang, X. Guo, K. Yu, X. Huang, T. Jiang, J. He, and L. Gu, “Causal feature selection in the presence of sample selection bias,” ACM Trans. Intell. Syst. Technol., vol. 14, no. 5, pp. 1–18, 2023
2023
-
[35]
Stable prediction across unknown environments,
K. Kuang, P. Cui, S. Athey, R. Xiong, and B. Li, “Stable prediction across unknown environments,” in Proc. 24th Int. Conf. Knowl. Discov. Data Min., 2018, pp. 1617–1626
2018
-
[36]
Error-aware markov blanket learning for causal feature selection,
X. Guo, K. Yu, F. Cao, P.-P. Li, and H. Wang, “Error-aware markov blanket learning for causal feature selection,” Inf. Sci. , vol. 589, pp. 849–877, 2022
2022
-
[37]
Stable prediction with leveraging seed variable,
K. Kuang, H. Wang, Y . Liu, R. Xiong, R. Wu, W. Lu, Y . T. Zhuang, F. Wu, P. Cui, and B. Li, “Stable prediction with leveraging seed variable,”IEEE Trans. Knowl. Data Eng., vol. 35, no. 6, pp. 6392–6404, 2023
2023
-
[38]
Discovering causally invariant features for out-of-distribution generalization,
Y . Wang, K. Yu, G. Xiang, F. Cao, and J. Liang, “Discovering causally invariant features for out-of-distribution generalization,” Pattern Recog- nit., vol. 150, p. 110338, 2024
2024
-
[39]
Statistical comparisons of classifiers over multiple data sets,
J. Dem ˇsar, “Statistical comparisons of classifiers over multiple data sets,” J. Mach. Learn. Res. , vol. 7, no. Jan, pp. 1–30, 2006
2006
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.