Preserving Speech-to-Text LLM Capabilities in Speech-to-Speech Generation
Pith reviewed 2026-07-01 00:58 UTC · model grok-4.3
The pith
PRIME-Speech keeps the original speech-to-text behavior of a frozen LLM backbone intact while adding direct speech-to-speech output through a separately trained causal post-decoder.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
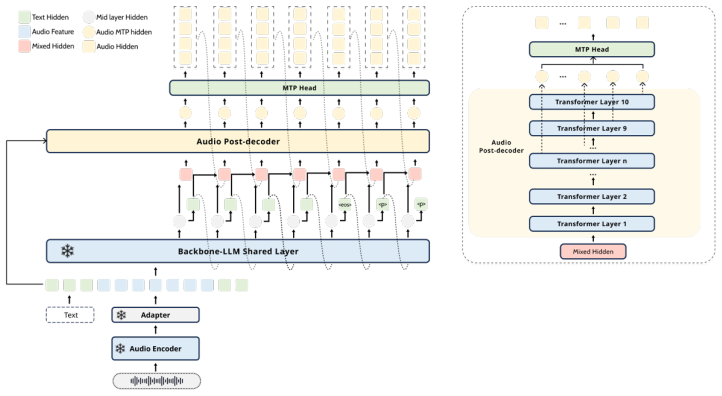
PRIME-Speech trains only speech-generation modules on top of a frozen S2T LLM backbone by synchronizing a causal audio post-decoder to its intermediate hidden states, allowing codec tokens to be produced from the evolving reasoning trajectory rather than from finished text; mixed hidden-state, text, and audio-history conditioning together with turn-level audio KV-cache packing and position reset enable stable multi-turn interaction without extra S2S training data, and multi-token prediction lowers the effective prediction rate.
What carries the argument
Causal audio post-decoder synchronized to intermediate hidden states of the frozen backbone, which generates codec tokens directly from the model's evolving reasoning trajectory using mixed conditioning.
If this is right
- Speech translation and spoken QA become possible as direct S2S tasks without an intermediate text stage.
- Multi-turn spoken dialogue maintains the same turn consistency as the original text-based LLM.
- First-audio latency drops because multi-token prediction generates several codec tokens per step without changing the reasoning path.
- Existing S2T training data suffices for the new S2S capability; no separate multi-turn S2S corpus is required.
Where Pith is reading between the lines
- The same hidden-state synchronization idea might transfer to adding image or video output to text LLMs.
- If the KV-cache packing generalizes, it could reduce the data cost of building multi-turn spoken agents.
- Real-time spoken interfaces become more feasible once the codec rate is lowered by multi-token prediction.
Load-bearing premise
Synchronizing the post-decoder only to intermediate hidden states plus mixed conditioning is enough to produce accurate speech output without degrading the backbone's original S2T capabilities.
What would settle it
Run the original frozen S2T model and the PRIME-Speech version on the same speech-translation or spoken-QA test set and measure whether S2T accuracy or understanding scores drop after the speech-generation modules are added.
Figures
read the original abstract
Strong speech-to-text (S2T) LLMs already provide robust speech perception and text reasoning, but adding speech-to-speech (S2S) output is challenging: fine-tuning the backbone can degrade the original S2T performance, while attaching a downstream talker reintroduces a serial text-to-speech bottleneck. We present PRIME-Speech, a frozen-backbone S2S conversion framework that trains only speech-generation modules. PRIME-Speech synchronizes a causal audio post-decoder with intermediate hidden states of the frozen backbone, so codec tokens are generated from the model's evolving reasoning trajectory rather than from completed text chunks. The post-decoder uses mixed hidden-state, text, and audio-history conditioning, and a training-time packing strategy with turn-level audio KV-cache and position reset stabilizes multi-turn spoken interaction without additional multi-turn S2S training data. Multi-token prediction further reduces the effective codec prediction rate and improves first-audio latency without modifying the reasoning path. Across speech translation, spoken QA, speech understanding, and multi-turn dialogue, PRIME-Speech preserves the S2T behavior of the frozen backbone while producing accurate, low-WER spoken responses.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PRIME-Speech, a frozen-backbone framework for converting S2T LLMs to S2S generation. Only a causal audio post-decoder is trained; it is synchronized to intermediate hidden states of the frozen backbone so that codec tokens are produced from the evolving reasoning trajectory. Mixed hidden-state/text/audio-history conditioning is used, together with a training-time turn-level audio KV-cache packing strategy (with position reset) claimed to stabilize multi-turn dialogue without extra multi-turn S2S data, and multi-token prediction to reduce latency. The central claim is that S2T behavior is preserved across speech translation, spoken QA, speech understanding, and multi-turn dialogue while producing accurate low-WER spoken output.
Significance. If the empirical claims hold, the approach would be a practical contribution to multimodal LLM deployment: it avoids both full backbone fine-tuning (which risks S2T degradation) and serial TTS bottlenecks. The engineering choices—hidden-state synchronization, mixed conditioning, and the KV-cache packing heuristic—are concrete and could be adopted by other groups working on speech-native models.
major comments (3)
- [Abstract and §4] Abstract and §4 (Experiments): the central preservation claim is stated without any before/after S2T metrics on the backbone (e.g., WER or accuracy on the same speech-translation or QA test sets). Direct comparison is required to substantiate that post-decoder training induces no distribution shift in the consumed hidden states.
- [§3.2] §3.2 (KV-cache packing): the turn-level audio KV-cache packing with position reset is presented as sufficient for stable multi-turn behavior from limited or single-turn data, yet no ablation removing the packing, no description of the multi-turn training distribution, and no inference-time KV-cache comparison on longer dialogues are reported. This is load-bearing for the multi-turn claim.
- [§4] §4 (Ablations): no ablation is shown that isolates the contribution of mixed hidden-state/text/audio-history conditioning versus hidden-state-only conditioning, nor any measurement of first-audio latency or WER when multi-token prediction is disabled. These controls are needed to support the latency and accuracy assertions.
minor comments (2)
- [§3.1] Notation for the post-decoder input (hidden states vs. text tokens vs. audio history) should be defined once in §3.1 with consistent symbols across equations and figures.
- [Figure 2] Figure 2 (architecture diagram) would benefit from explicit arrows showing the position-reset operation during packing.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger empirical validation of our preservation and ablation claims. We will revise the manuscript to incorporate the requested metrics and ablations.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the central preservation claim is stated without any before/after S2T metrics on the backbone (e.g., WER or accuracy on the same speech-translation or QA test sets). Direct comparison is required to substantiate that post-decoder training induces no distribution shift in the consumed hidden states.
Authors: We agree that direct before/after S2T metrics on the frozen backbone are required to substantiate the preservation claim. In the revised manuscript we will add a table in §4 reporting WER and accuracy on the identical speech-translation and spoken-QA test sets for the original S2T LLM versus the model after post-decoder training, confirming no measurable distribution shift in the consumed hidden states. revision: yes
-
Referee: [§3.2] §3.2 (KV-cache packing): the turn-level audio KV-cache packing with position reset is presented as sufficient for stable multi-turn behavior from limited or single-turn data, yet no ablation removing the packing, no description of the multi-turn training distribution, and no inference-time KV-cache comparison on longer dialogues are reported. This is load-bearing for the multi-turn claim.
Authors: We acknowledge the absence of these controls. The revision will add (i) an ablation removing the turn-level KV-cache packing, (ii) an explicit description of the training distribution (single-turn data with the packing heuristic applied at training time), and (iii) inference-time KV-cache size and stability comparisons on longer multi-turn dialogues. These results will be reported in §3.2 and §4. revision: yes
-
Referee: [§4] §4 (Ablations): no ablation is shown that isolates the contribution of mixed hidden-state/text/audio-history conditioning versus hidden-state-only conditioning, nor any measurement of first-audio latency or WER when multi-token prediction is disabled. These controls are needed to support the latency and accuracy assertions.
Authors: We agree these ablations are necessary. The revised §4 will include (i) a direct comparison of mixed conditioning versus hidden-state-only conditioning on WER and latency, and (ii) first-audio latency and WER measurements with multi-token prediction disabled. Both will be added as new rows in the existing ablation table. revision: yes
Circularity Check
No circularity; empirical architecture with frozen backbone
full rationale
The paper presents PRIME-Speech as an engineering solution that freezes the S2T backbone and trains only post-decoder modules to generate codec tokens from intermediate hidden states. No equations, parameter fits, or predictions are described that reduce the claimed preservation of S2T behavior to a self-referential definition or fitted input. The turn-level KV-cache packing is presented as a training heuristic without any derivation that loops back to the target metrics. The central claim rests on the direct consequence of not updating backbone weights, which is independent of the reported results and does not rely on self-citation chains or ansatzes smuggled from prior work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Recent advances in speech language models: A survey,
W. Cui, D. Yu, X. Jiao, Z. Meng, G. Zhang, Q. Wang, S. Y . Guo, and I. King, “Recent advances in speech language models: A survey,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025, pp. 13 943– 13 970
2025
-
[2]
On The Landscape of Spoken Language Models: A Comprehensive Survey
S. Arora, K.-W. Chang, C.-M. Chien, Y . Peng, H. Wu, Y . Adi, E. Dupoux, H.-Y . Lee, K. Livescu, and S. Watanabe, “On the landscape of spoken language models: A comprehensive survey,”arXiv preprint arXiv:2504.08528, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Whislu: End-to-end spoken language under- standing with whisper,
M. Wang, Y . Li, J. Guo, X. Qiao, Z. Li, H. Shang, D. Wei, S. Tao, M. Zhang, and H. Yang, “Whislu: End-to-end spoken language under- standing with whisper,” inProc. Interspeech, vol. 2023, 2023, pp. 770– 774
2023
-
[4]
Adapting large language model with speech for fully formatted end- to-end speech recognition,
S. Ling, Y . Hu, S. Qian, G. Ye, Y . Qian, Y . Gong, E. Lin, and M. Zeng, “Adapting large language model with speech for fully formatted end- to-end speech recognition,” inICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 11 046–11 050
2024
-
[5]
Speechgpt: Empowering large language models with intrinsic cross- modal conversational abilities,
D. Zhang, S. Li, X. Zhang, J. Zhan, P. Wang, Y . Zhou, and X. Qiu, “Speechgpt: Empowering large language models with intrinsic cross- modal conversational abilities,” inFindings of the Association for Computational Linguistics: EMNLP 2023, 2023, pp. 15 757–15 773
2023
-
[6]
Y . Chu, J. Xu, Q. Yang, H. Wei, X. Wei, Z. Guo, Y . Leng, Y . Lv, J. He, J. Linet al., “Qwen2-audio technical report,”arXiv preprint arXiv:2407.10759, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
Microsoft, A. Abouelenin, A. Ashfaq, A. Atkinson, H. Awadalla, N. Bach, J. Bao, A. Benhaim, M. Cai, V . Chaudhary, C. Chenet al., “Phi- 4-mini technical report: Compact yet powerful multimodal language models via mixture-of-loras,”arXiv preprint arXiv:2503.01743, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Understanding the modality gap: An empirical study on the speech-text alignment mechanism of large speech language models,
B. Xiang, S. Zhao, T. Guo, and W. Zou, “Understanding the modality gap: An empirical study on the speech-text alignment mechanism of large speech language models,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025, pp. 5187– 5202
2025
-
[9]
Alignformer: Modality matching can achieve better zero-shot instruction-following speech-llm,
R. Fan, B. Ren, Y . Hu, R. Zhao, S. Liu, and J. Li, “Alignformer: Modality matching can achieve better zero-shot instruction-following speech-llm,” IEEE Journal of Selected Topics in Signal Processing, 2025
2025
-
[10]
Closing the gap between text and speech understanding in llms,
S. Cuervo, S. Seto, M. de Seyssel, R. H. Bai, Z. Gu, T. Likhomanenko, N. Jaitly, and Z. Aldeneh, “Closing the gap between text and speech understanding in llms,”arXiv preprint arXiv:2510.13632, 2025
-
[11]
Speech discrete tokens or continuous features? a comparative analysis for spoken language understanding in speechllms,
D. Wang, J. Li, M. Cui, D. Yang, X. Chen, and H. Meng, “Speech discrete tokens or continuous features? a comparative analysis for spoken language understanding in speechllms,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025, pp. 24 924–24 935
2025
-
[12]
Closing the Modality Reasoning Gap for Speech Large Language Models
C. Wang, H. Lu, X. Zhang, S. Liu, Y . Lu, J. Li, and Z. Wu, “Closing the modality reasoning gap for speech large language models,”arXiv preprint arXiv:2601.05543, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
E2 tts: Embarrassingly easy fully non-autoregressive zero-shot tts,
S. E. Eskimez, X. Wang, M. Thakker, C. Li, C.-H. Tsai, Z. Xiao, H. Yang, Z. Zhu, M. Tang, X. Tanet al., “E2 tts: Embarrassingly easy fully non-autoregressive zero-shot tts,” in2024 IEEE Spoken Language Technology Workshop (SLT). IEEE, 2024, pp. 682–689
2024
-
[14]
Neural codec language models are zero-shot text to speech synthesizers,
S. Chen, C. Wang, Y . Wu, Z. Zhang, L. Zhou, S. Liu, Z. Chen, Y . Liu, H. Wang, J. Liet al., “Neural codec language models are zero-shot text to speech synthesizers,”IEEE Transactions on Audio, Speech and Language Processing, vol. 33, pp. 705–718, 2025
2025
-
[15]
CosyVoice 2: Scalable Streaming Speech Synthesis with Large Language Models
Z. Du, Y . Wang, Q. Chen, X. Shi, X. Lv, T. Zhao, Z. Gao, Y . Yang, C. Gao, H. Wanget al., “Cosyvoice 2: Scalable streaming speech synthesis with large language models,”arXiv preprint arXiv:2412.10117, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
CosyVoice 3: Towards In-the-wild Speech Generation via Scaling-up and Post-training
Z. Du, C. Gao, Y . Wang, F. Yu, T. Zhao, H. Wang, X. Lv, H. Wang, C. Ni, X. Shiet al., “Cosyvoice 3: Towards in-the-wild speech generation via scaling-up and post-training,”arXiv preprint arXiv:2505.17589, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Pseudo-autoregressive neural codec language models for efficient zero-shot text-to-speech synthesis,
Y . Yang, S. Liu, J. Li, Y . Hu, H. Wu, H. Wang, J. Yu, L. Meng, H. Sun, Y . Liuet al., “Pseudo-autoregressive neural codec language models for efficient zero-shot text-to-speech synthesis,” inProceedings of the 33rd ACM International Conference on Multimedia, 2025, pp. 9316–9325
2025
-
[18]
Indextts2: A breakthrough in emotionally expressive and duration- controlled auto-regressive zero-shot text-to-speech,
S. Zhou, Y . Zhou, Y . He, X. Zhou, J. Wang, W. Deng, and J. Shu, “Indextts2: A breakthrough in emotionally expressive and duration- controlled auto-regressive zero-shot text-to-speech,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 41, 2026, pp. 35 139–35 148
2026
-
[19]
Fish audio s2 technical report,
S. Liao, Y . Wang, S. Liu, Y . Cheng, R. Zhang, T. Li, S. Li, Y . Zheng, X. Liu, Q. Wanget al., “Fish audio s2 technical report,”arXiv preprint arXiv:2603.08823, 2026
-
[20]
Zipvoice-dialog: Non-autoregressive spoken dialogue generation with flow matching,
H. Zhu, W. Kang, L. Guo, Z. Yao, F. Kuang, W. Zhuang, Z. Li, Z. Han, D. Zhang, X. Zhanget al., “Zipvoice-dialog: Non-autoregressive spoken dialogue generation with flow matching,” inFindings of the Association for Computational Linguistics: ACL 2026, 2026, pp. 38 717–38 729
2026
-
[21]
Moshi: a speech-text foundation model for real-time dialogue
A. D ´efossez, L. Mazar ´e, M. Orsini, A. Royer, P. P ´erez, H. J ´egou, E. Grave, and N. Zeghidour, “Moshi: a speech-text foundation model for real-time dialogue,”arXiv preprint arXiv:2410.00037, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Freeze-omni: A smart and low latency speech-to-speech dialogue model with frozen llm,
X. Wang, Y . Li, C. Fu, Y . Shen, L. Xie, K. Li, X. Sun, and L. Ma, “Freeze-omni: A smart and low latency speech-to-speech dialogue model with frozen llm,”arXiv preprint arXiv:2411.00774, 2024
-
[23]
Mimo-audio: Audio language models are few-shot learners,
D. Zhang, G. Wang, J. Xue, K. Fang, L. Zhao, R. Ma, S. Ren, S. Liu, T. Guo, W. Zhuanget al., “Mimo-audio: Audio language models are few-shot learners,”arXiv preprint arXiv:2512.23808, 2025
-
[24]
D. Ding, Z. Ju, Y . Leng, S. Liu, T. Liu, Z. Shang, K. Shen, W. Song, X. Tan, H. Tanget al., “Kimi-audio technical report,”arXiv preprint arXiv:2504.18425, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Slam-omni: Timbre-controllable voice interaction system with single-stage training,
W. Chen, Z. Ma, R. Yan, Y . Liang, X. Li, R. Xu, Z. Niu, Y . Zhu, Y . Yang, Z. Liuet al., “Slam-omni: Timbre-controllable voice interaction system with single-stage training,” inFindings of the Association for Computational Linguistics: ACL 2025, 2025, pp. 2262–2282
2025
-
[26]
Fun-audio-chat technical report,
Q. Chen, L. Cheng, C. Deng, X. Li, J. Liu, C.-H. Tan, W. Wang, J. Xu, J. Ye, Q. Zhanget al., “Fun-audio-chat technical report,”arXiv preprint arXiv:2512.20156, 2025
-
[27]
C. Yang, C. Yu, H. Chen, J. Zhu, J. Chen, K. Chen, W. Wang, Y . Wang, Y . Jiang, Y . Jianget al., “Moss-audio technical report,”arXiv preprint arXiv:2606.01802, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
GLM-4-Voice: Towards Intelligent and Human-Like End-to-End Spoken Chatbot
A. Zeng, Z. Du, M. Liu, K. Wang, S. Jiang, L. Zhao, Y . Dong, and J. Tang, “GLM-4-V oice: Towards intelligent and human-like end-to-end spoken chatbot,”arXiv preprint arXiv:2412.02612, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Llama-omni2: Llm- based real-time spoken chatbot with autoregressive streaming speech synthesis,
Q. Fang, Y . Zhou, S. Guo, S. Zhang, and Y . Feng, “Llama-omni2: Llm- based real-time spoken chatbot with autoregressive streaming speech synthesis,”arXiv preprint arXiv:2505.02625, 2025
-
[30]
B. Wu, C. Yan, C. Hu, C. Yi, C. Feng, F. Tian, F. Shen, G. Yu, H. Zhang, J. Liet al., “Step-audio 2 technical report,”arXiv preprint arXiv:2507.16632, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
J. Xu, Z. Guo, J. He, H. Hu, T. He, S. Bai, K. Chen, J. Wang, Y . Fan, K. Danget al., “Qwen2. 5-omni technical report,”arXiv preprint arXiv:2503.20215, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
J. Xu, Z. Guo, H. Hu, Y . Chu, X. Wang, J. He, Y . Wang, X. Shi, T. He, X. Zhuet al., “Qwen3-omni technical report,”arXiv preprint arXiv:2509.17765, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Minmo: A multimodal large language model for seamless voice interaction,
Q. Chen, Y . Chen, Y . Chen, M. Chen, Y . Chen, C. Deng, Z. Du, R. Gao, C. Gao, Z. Gaoet al., “Minmo: A multimodal large language model for seamless voice interaction,”arXiv preprint arXiv:2501.06282, 2025
-
[34]
Q. Team, “Qwen3. 5-omni technical report,”arXiv preprint arXiv:2604.15804, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[35]
A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruanet al., “Deepseek-v3 technical report,”arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Better & faster large language models via multi-token prediction,
F. Gloeckle, B. Y . Idrissi, B. Rozi `ere, D. Lopez-Paz, and G. Synnaeve, “Better & faster large language models via multi-token prediction,” in Proceedings of the 41st International Conference on Machine Learning, 2024, pp. 15 706–15 734
2024
-
[37]
Vita-audio: Fast interleaved cross-modal token generation for efficient large speech-language model,
Z. Long, Y . Shen, C. Fu, H. Gao, L. Li, P. Chen, M. Zhang, H. Shao, J. Li, J. Penget al., “Vita-audio: Fast interleaved cross-modal token generation for efficient large speech-language model,”arXiv preprint arXiv:2505.03739, 2025
-
[38]
V ocalnet: Speech llm with multi-token prediction for faster and high- quality generation,
Y . Wang, H. Liu, Z. Cheng, R. Wu, Q. Gu, Y . Wang, and Y . Wang, “V ocalnet: Speech llm with multi-token prediction for faster and high- quality generation,”CoRR, 2025
2025
-
[39]
Similarity of neural network representations revisited,
S. Kornblith, M. Norouzi, H. Lee, and G. Hinton, “Similarity of neural network representations revisited,” inInternational conference on machine learning. PMlR, 2019, pp. 3519–3529
2019
-
[40]
Libriheavy: a 50,000 hours asr corpus with punctuation casing and context,
W. Kang, X. Yang, Z. Yao, F. Kuang, Y . Yang, L. Guo, L. Lin, and D. Povey, “Libriheavy: a 50,000 hours asr corpus with punctuation casing and context,” 2023
2023
-
[41]
Covost 2 and massively multilingual speech translation,
C. Wang, A. Wu, J. Gu, and J. Pino, “Covost 2 and massively multilingual speech translation,” inProceedings of Interspeech 2021, 2021, pp. 2247–2251
2021
-
[42]
Mini-omni: Language models can hear, talk while thinking in streaming,
Z. Xie and C. Wu, “Mini-omni: Language models can hear, talk while thinking in streaming,”arXiv preprint arXiv:2408.16725, 2024
-
[43]
Towards efficient speech-text jointly decoding within one speech language model,
H. Wu, Y . Hu, R. Fan, X. Wang, K. Kumatani, B. Ren, J. Yu, H. Lu, L. Wang, Y . Qianet al., “Towards efficient speech-text jointly decoding within one speech language model,”arXiv preprint arXiv:2506.04518, 2025
-
[44]
Cvss corpus and massively multilingual speech-to-speech translation,
Y . Jia, M. T. Ramanovich, Q. Wang, and H. Zen, “Cvss corpus and massively multilingual speech-to-speech translation,” inProceedings of the Thirteenth Language Resources and Evaluation Conference, 2022, pp. 6691–6703
2022
-
[45]
Slm-s2st: A multimodal language model for direct speech-to-speech translation,
Y . Hu, H. Wu, R. Fan, X. Wang, H. Lu, Y . Qian, and J. Li, “Slm-s2st: A multimodal language model for direct speech-to-speech translation,” arXiv preprint arXiv:2506.04392, 2025
-
[46]
TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension
M. Joshi, E. Choi, D. Weld, and L. Zettlemoyer, “triviaqa: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension,” arXiv e-prints, p. arXiv:1705.03551, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[47]
Hello gpt-4o,
OpenAI, “Hello gpt-4o,” 2024. [Online]. Available: https://openai.com/index/hello-gpt-4o/
2024
-
[48]
Fleurs: Few-shot learning evaluation of universal representations of speech,
A. Conneau, M. Ma, S. Khanuja, Y . Zhang, V . Axelrod, S. Dalmia, J. Riesa, C. Rivera, and A. Bapna, “Fleurs: Few-shot learning evaluation of universal representations of speech,” in2022 IEEE Spoken Language Technology Workshop (SLT). IEEE, 2023, pp. 798–805
2023
-
[49]
Ultraeval-audio: A unified framework for comprehensive evaluation of audio foundation models,
Q. Shi, J. Zhou, B. Lin, J. Cui, G. Zeng, Y . Zhou, Z. Wang, X. Liu, Z. Luo, Y . Wanget al., “Ultraeval-audio: A unified framework for comprehensive evaluation of audio foundation models,”arXiv preprint arXiv:2601.01373, 2026
-
[50]
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
A. Srivastava, A. Rastogi, A. Rao, A. A. M. Shoeb, A. Abid, A. Fisch, A. R. Brown, A. Santoro, A. Gupta, A. Garriga-Alonsoet al., “Beyond the imitation game: Quantifying and extrapolating the capabilities of language models,”arXiv preprint arXiv:2206.04615, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[51]
V ocalbench: Benchmarking the vocal conversational abilities for speech interaction models,
H. Liu, Y . Wang, Z. Cheng, R. Wu, Q. Gu, Y . Wang, and Y . Wang, “V ocalbench: Benchmarking the vocal conversational abilities for speech interaction models,”arXiv preprint arXiv:2505.15727, 2025
-
[52]
Robust speech recognition via large-scale weak supervi- sion,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervi- sion,” inInternational conference on machine learning. PMLR, 2023, pp. 28 492–28 518. VI. GENERATIVEAI USEDISCLOSURE We used generative AI tools only for language polishing, including grammar correction and spelling checks, an...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.