Controllable Texture Tiling with Transformed RoPE-Enhanced Diffusion Models
Pith reviewed 2026-06-26 06:23 UTC · model grok-4.3
The pith
Applying 2D affine transformations to relative positional embeddings in diffusion transformers enables precise texture tiling control without pixel warping.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
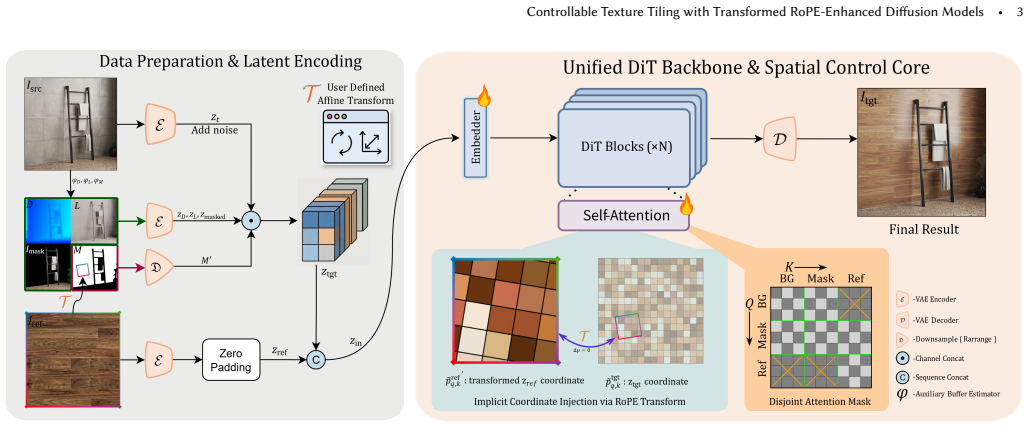
The paper establishes that applying 2D affine transformations directly to the relative positional embeddings between the target latent and the image condition achieves precise control over tiling patterns. This is combined with a Disjoint Attention Mask that shields reference features from semantic leakage, allowing the synthesized texture to retain its structural integrity and blend with the scene's original lighting and geometry without explicit pixel warping or loss of reference information.
What carries the argument
Coordinate-Transformed Rotary Embedding, which applies 2D affine transformations directly to relative positional embeddings between target latent and image condition to control tiling frequency, orientation, and scale.
If this is right
- Precise repetition of the reference pattern occurs according to user-defined frequency, orientation, and scale.
- Full information from the reference condition is utilized without degradation from pixel-level operations.
- The synthesized texture blends seamlessly with the scene's original lighting and geometry.
- Control accuracy and texture fidelity exceed those of state-of-the-art baselines in experiments.
Where Pith is reading between the lines
- The separation of spatial manipulation via embeddings could extend to other parametric editing tasks such as object scaling or pattern placement in generative models.
- Avoiding explicit warping operations may lower memory costs when handling high-resolution references in diffusion pipelines.
- The approach suggests positional embedding transforms as a route for geometric control in latent spaces that could be tested on non-affine transformations.
Load-bearing premise
Applying 2D affine transformations directly to relative positional embeddings between the target latent and image condition achieves precise tiling control without explicit pixel warping or degradation of reference information.
What would settle it
A generated output where the repeated texture pattern deviates measurably from the user-specified frequency, orientation, or scale, or where the reference texture's structural details appear altered compared to the input condition.
Figures







read the original abstract
Realistic integration of user-specified textures into scene images is a fundamental task in computer graphics and image editing. While existing material transfer and reference-guided inpainting methods can edit surface appearances, they often fail to address the specific requirements of texture tiling. This task necessitates precisely repeating a reference pattern according to user-defined parameters such as frequency, orientation, and scale. Furthermore, current generative approaches often struggle to maintain the structural fidelity of the reference texture, limited by either destructive pixel-level resampling or the lack of fine-grained spatial information in semantic image encoders, and they frequently fail to preserve the coherent lighting and geometry of the original scene. In this paper, we propose a novel framework for controllable and high-fidelity texture tiling based on Diffusion Transformers. Our approach introduces two key technical innovations to decouple spatial manipulation from content generation. First, we propose a Coordinate-Transformed Rotary Embedding mechanism. By applying 2D affine transformations directly to the relative positional embeddings between the target latent and the image condition, we achieve precise control over tiling patterns without explicit pixel warping, thereby utilizing the full information of the reference condition without degradation. Second, a Disjoint Attention Mask is employed to shield reference features from semantic leakage. This preserves structural integrity while seamlessly blending the synthesized texture with the scene's original lighting and geometry. Extensive experiments demonstrate that our method outperforms state-of-the-art baselines in both control accuracy and texture fidelity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce a framework for controllable texture tiling using Diffusion Transformers. It proposes two innovations: (1) Coordinate-Transformed Rotary Embedding, which applies 2D affine transformations directly to relative positional embeddings between the target latent and image condition to achieve precise control over frequency, orientation, and scale without explicit pixel warping or degradation of reference information; (2) a Disjoint Attention Mask to prevent semantic leakage from the reference while preserving structural integrity and blending with scene lighting/geometry. Extensive experiments are said to show outperformance over SOTA baselines in control accuracy and texture fidelity.
Significance. If the results hold, the work would represent a meaningful advance in computer graphics for reference-guided texture synthesis and scene editing. By decoupling spatial manipulation from content generation via transformed RoPE and attention masking, it could enable higher-fidelity tiling that avoids the structural degradation common in pixel-warping or semantic-encoder approaches. The approach may influence positional embedding designs in diffusion models for other spatially controllable generation tasks.
major comments (2)
- [Abstract] Abstract (central claim on Coordinate-Transformed Rotary Embedding): The assumption that 2D affine transforms applied to relative positional embeddings will induce exact corresponding spatial repetition in the decoded output on a fixed-resolution latent grid is load-bearing for the 'precise control' claim. Because RoPE encodes relative angles/distances rather than absolute pixel coordinates, non-isometric affines (non-uniform scale, shear) risk embedding-space changes that do not map isometrically to image-space tiling periods, potentially causing under-control or distortion that pixel-warping baselines avoid by construction. No derivation or isometric mapping argument is visible to address this.
- [Abstract] Abstract (performance claims): The statement that 'extensive experiments demonstrate that our method outperforms state-of-the-art baselines in both control accuracy and texture fidelity' is central, yet the abstract provides no quantitative metrics, ablation results, controls for tiling parameters, or error analysis. This leaves the superiority claim without visible grounding and prevents assessment of whether the method actually mitigates the geometric mismatch risk.
minor comments (1)
- [Abstract] The abstract is clear but would benefit from one or two concrete quantitative results (e.g., tiling frequency error or FID scores) to support the 'outperforms' claim.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed comments, which help clarify key aspects of our work. Below we provide point-by-point responses to the major comments. We propose targeted revisions to address the concerns while preserving the manuscript's contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract (central claim on Coordinate-Transformed Rotary Embedding): The assumption that 2D affine transforms applied to relative positional embeddings will induce exact corresponding spatial repetition in the decoded output on a fixed-resolution latent grid is load-bearing for the 'precise control' claim. Because RoPE encodes relative angles/distances rather than absolute pixel coordinates, non-isometric affines (non-uniform scale, shear) risk embedding-space changes that do not map isometrically to image-space tiling periods, potentially causing under-control or distortion that pixel-warping baselines avoid by construction. No derivation or isometric mapping argument is visible to address this.
Authors: We appreciate the referee's identification of this theoretical gap. Our Coordinate-Transformed RoPE applies the 2D affine transformation to the coordinate grid prior to rotary embedding computation, modulating the relative phase shifts to control frequency, orientation, and scale directly in the latent space. While the full paper provides extensive empirical evidence across diverse affine parameters demonstrating precise tiling without distortion, we agree that an explicit derivation would strengthen the central claim. In the revision, we will add a dedicated subsection deriving the mapping from transformed relative embeddings to output periodicity, including analysis of non-isometric cases and their effect on the decoded image grid. revision: yes
-
Referee: [Abstract] Abstract (performance claims): The statement that 'extensive experiments demonstrate that our method outperforms state-of-the-art baselines in both control accuracy and texture fidelity' is central, yet the abstract provides no quantitative metrics, ablation results, controls for tiling parameters, or error analysis. This leaves the superiority claim without visible grounding and prevents assessment of whether the method actually mitigates the geometric mismatch risk.
Authors: The abstract is a high-level summary; the full manuscript (Sections 4–5) contains the requested quantitative grounding, including control accuracy metrics (e.g., tiling frequency/orientation error), texture fidelity scores (LPIPS, PSNR), ablation studies on the RoPE transformation and attention mask, and comparisons against pixel-warping and semantic-encoder baselines. To better ground the abstract claim and allow readers to assess mitigation of geometric mismatch, we will revise the abstract to concisely reference key quantitative improvements (e.g., “outperforms baselines by 15–25% in control accuracy”) while remaining within length constraints. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The abstract and description introduce Coordinate-Transformed Rotary Embedding and Disjoint Attention Mask as novel mechanisms for decoupling spatial control from content generation. No equations, parameter-fitting steps, or self-citations are shown that would reduce any claimed prediction or uniqueness result to the inputs by construction. The central claims rest on the proposed architectural changes rather than self-referential definitions or renamed empirical patterns. The derivation is self-contained against external benchmarks with no load-bearing reductions exhibited.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Perla Mayo and Carolin M. Pirkl and Alin M. Achim and Bjoern H. Menze and Mohammad Golbabaee , title =. 2026 , url =. doi:10.1109/ACCESS.2026.3674726 , timestamp =
-
[2]
In: IEEE/CVF International Conference on Computer Vision
Lvmin Zhang and Anyi Rao and Maneesh Agrawala , title =. 2023 , url =. doi:10.1109/ICCV51070.2023.00355 , timestamp =
-
[3]
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
Hu Ye and Jun Zhang and Sibo Liu and Xiao Han and Wei Yang , title =. CoRR , volume =. 2023 , url =. doi:10.48550/ARXIV.2308.06721 , eprinttype =. 2308.06721 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2308.06721 2023
-
[4]
2024 , howpublished=
Black Forest Labs , title=. 2024 , howpublished=
2024
-
[5]
FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space
Black Forest Labs and Stephen Batifol and Andreas Blattmann and Frederic Boesel and Saksham Consul and Cyril Diagne and Tim Dockhorn and Jack English and Zion English and Patrick Esser and Sumith Kulal and Kyle Lacey and Yam Levi and Cheng Li and Dominik Lorenz and Jonas M. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2506.15742 , eprinttype =. 2506....
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.15742 2025
-
[6]
Ta Ying Cheng and Prafull Sharma and Andrew Markham and Niki Trigoni and Varun Jampani , editor =. ZeST: Zero-Shot Material Transfer from a Single Image , booktitle =. 2024 , url =. doi:10.1007/978-3-031-73232-4\_21 , timestamp =
-
[7]
Kamil Garifullin and Maxim Nikolaev and Andrey Kuznetsov and Aibek Alanov , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2502.06606 , eprinttype =. 2502.06606 , timestamp =
-
[8]
Lopes, I. and Deschaintre, V. and Hold‐Geoffroy, Y. and de Charette, R. , year =. MatSwap: Light‐aware material transfers in images , volume =. Computer Graphics Forum , publisher =. doi:10.1111/cgf.70168 , number =
-
[9]
In: IEEE/CVF International Conference on Computer Vision
Peebles, William and Xie, Saining , year =. Scalable Diffusion Models with Transformers , url =. doi:10.1109/iccv51070.2023.00387 , booktitle =
-
[10]
RoFormer: Enhanced transformer with Rotary Position Embedding , journal =
Su, Jianlin and Ahmed, Murtadha and Lu, Yu and Pan, Shengfeng and Bo, Wen and Liu, Yunfeng , year =. RoFormer: Enhanced transformer with Rotary Position Embedding , volume =. doi:10.1016/j.neucom.2023.127063 , journal =
-
[11]
arXiv preprint arXiv:2601.02760 , year=
AnyDepth: Depth Estimation Made Easy , author=. arXiv preprint arXiv:2601.02760 , year=
-
[12]
Zheng Zeng and Valentin Deschaintre and Iliyan Georgiev and Yannick Hold. RGB. 2024 , url =. doi:10.1145/3641519.3657445 , timestamp =
-
[13]
MM-ViT: Multi-Modal Video Transformer for Compressed Video Action Recognition
Suvorov, Roman and Logacheva, Elizaveta and Mashikhin, Anton and Remizova, Anastasia and Ashukha, Arsenii and Silvestrov, Aleksei and Kong, Naejin and Goka, Harshith and Park, Kiwoong and Lempitsky, Victor , year =. Resolution-robust Large Mask Inpainting with Fourier Convolutions , url =. doi:10.1109/wacv51458.2022.00323 , booktitle =
-
[14]
Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bjorn , year =. High-Resolution Image Synthesis with Latent Diffusion Models , url =. doi:10.1109/cvpr52688.2022.01042 , booktitle =
-
[15]
In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Yang, Binxin and Gu, Shuyang and Zhang, Bo and Zhang, Ting and Chen, Xuejin and Sun, Xiaoyan and Chen, Dong and Wen, Fang , year =. Paint by Example: Exemplar-based Image Editing with Diffusion Models , url =. doi:10.1109/cvpr52729.2023.01763 , booktitle =
-
[16]
arXiv preprint arXiv:2403.05139 , year=
Improving Diffusion Models for Authentic Virtual Try-on in the Wild , author=. arXiv preprint arXiv:2403.05139 , year=
-
[17]
2025 , eprint=
CatVTON: Concatenation Is All You Need for Virtual Try-On with Diffusion Models , author=. 2025 , eprint=
2025
-
[18]
Titov, Vadim and Khalmatova, Madina and Ivanova, Alexandra and Vetrov, Dmitry and Alanov, Aibek , title =. Computer Vision – ECCV 2024: 18th European Conference, Milan, Italy, September 29–October 4, 2024, Proceedings, Part LXXI , pages =. 2024 , isbn =. doi:10.1007/978-3-031-73209-6_14 , abstract =
-
[19]
Generative adversarial networks.Commun
Goodfellow, Ian and Pouget-Abadie, Jean and Mirza, Mehdi and Xu, Bing and Warde-Farley, David and Ozair, Sherjil and Courville, Aaron and Bengio, Yoshua , year =. Generative adversarial networks , volume =. Communications of the ACM , publisher =. doi:10.1145/3422622 , number =
-
[20]
Edward J Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen , booktitle=. Lo. 2022 , url=
2022
-
[21]
Materialistic: Selecting Similar Materials in Images , year =
Sharma, Prafull and Philip, Julien and Gharbi, Michaël and Freeman, Bill and Durand, Fredo and Deschaintre, Valentin , year =. Materialistic: Selecting Similar Materials in Images , volume =. ACM Transactions on Graphics , publisher =. doi:10.1145/3592390 , number =
-
[22]
arXiv preprint arXiv:2312.11805 , year=
Gemini: A Family of Highly Capable Multimodal Models , author=. arXiv preprint arXiv:2312.11805 , year=
-
[23]
2026 , howpublished=
Nano Banana Pro (Gemini 3 Pro Image) , author=. 2026 , howpublished=
2026
-
[24]
In: IEEE/CVF International Conference on Computer Vision
Kirillov, Alexander and Mintun, Eric and Ravi, Nikhila and Mao, Hanzi and Rolland, Chloe and Gustafson, Laura and Xiao, Tete and Whitehead, Spencer and Berg, Alexander C. and Lo, Wan-Yen and Dollár, Piotr and Girshick, Ross , year =. Segment Anything , url =. doi:10.1109/iccv51070.2023.00371 , booktitle =
-
[25]
2018 , url =
Blender - a 3D modelling and rendering package , author =. 2018 , url =
2018
-
[26]
In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Brooks, Tim and Holynski, Aleksander and Efros, Alexei A. , year =. InstructPix2Pix: Learning to Follow Image Editing Instructions , url =. doi:10.1109/cvpr52729.2023.01764 , booktitle =
-
[27]
Advances in Neural Information Processing Systems , publisher =
MagicBrush: A Manually Annotated Dataset for Instruction-Guided Image Editing , author=. Advances in Neural Information Processing Systems , publisher =
-
[28]
Chung, Jiwoo and Hyun, Sangeek and Heo, Jae-Pil , year =. Style Injection in Diffusion: A Training-Free Approach for Adapting Large-Scale Diffusion Models for Style Transfer , url =. doi:10.1109/cvpr52733.2024.00840 , booktitle =
-
[29]
Deng, Yingying and He, Xiangyu and Tang, Fan and Dong, Weiming , year =. Z*: Zero-shot Style Transfer via Attention Reweighting , url =. doi:10.1109/cvpr52733.2024.00662 , booktitle =
-
[30]
NTIRE 2025 challenge on HR depth from images of specular and transparent surfaces,
Fahim, Masud An-Nur Islam and Saqib, Nazmus and Boutellier, Jani , year =. STAM: Zero-Shot Style Transfer Using Diffusion Model via Attention Modulation , url =. doi:10.1109/cvprw67362.2025.00629 , booktitle =
-
[31]
2025 , eprint=
Eye-for-an-eye: Appearance Transfer with Semantic Correspondence in Diffusion Models , author=. 2025 , eprint=
2025
-
[32]
Madar, Or and Fried, Ohad , year =. Tiled Diffusion , url =. doi:10.1109/cvpr52734.2025.00730 , booktitle =
-
[33]
Sharma, Prafull and Jampani, Varun and Li, Yuanzhen and Jia, Xuhui and Lagun, Dmitry and Durand, Fredo and Freeman, Bill and Matthews, Mark , booktitle =. 2024 , volume =. doi:10.1109/CVPR52733.2024.02278 , url =
-
[34]
Eurographics Symposium on Rendering , editor =
Jimenez-Navarro, Santiago and Guerrero-Viu, Julia and Masia, Belen , year =. Eurographics Symposium on Rendering , editor =
-
[35]
ACM Transactions on Graphics , volume=
IntrinsicEdit: Precise generative image manipulation in intrinsic space , author=. ACM Transactions on Graphics , volume=
-
[36]
Yeh, Yu-Ying and Huang, Jia-Bin and Kim, Changil and Xiao, Lei and Nguyen-Phuoc, Thu and Khan, Numair and Zhang, Cheng and Chandraker, Manmohan and Marshall, Carl S and Dong, Zhao and Li, Zhengqin , booktitle =. 2024 , volume =. doi:10.1109/CVPR52733.2024.00412 , url =
-
[37]
2025 , eprint=
NaTex: Seamless Texture Generation as Latent Color Diffusion , author=. 2025 , eprint=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.