Vesta: A Generalist Embodied Reasoning Model
Pith reviewed 2026-06-26 16:53 UTC · model grok-4.3
The pith
A single generalist model for embodied reasoning outperforms both individual specialists and their ensembles by over 20 percent on average.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
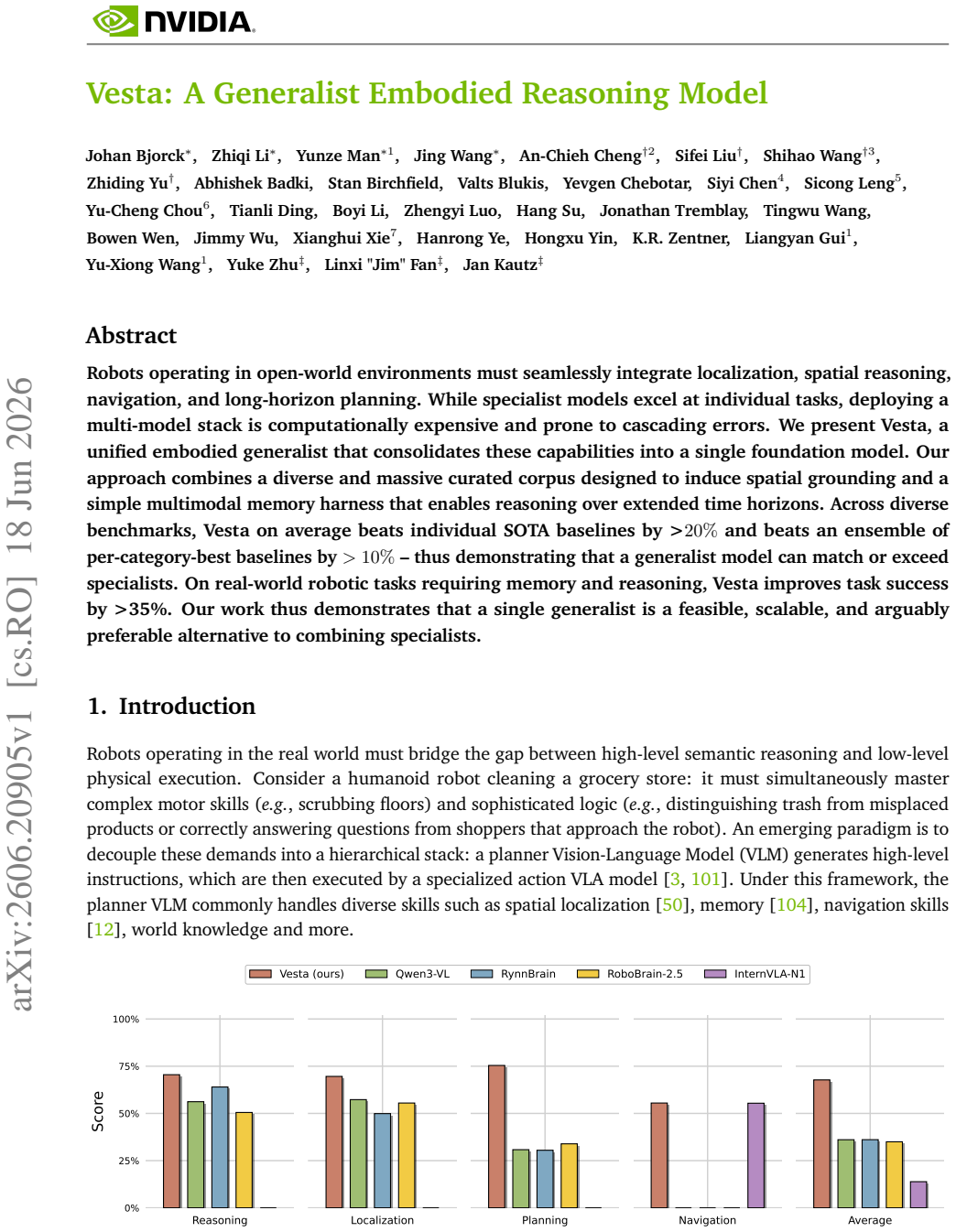
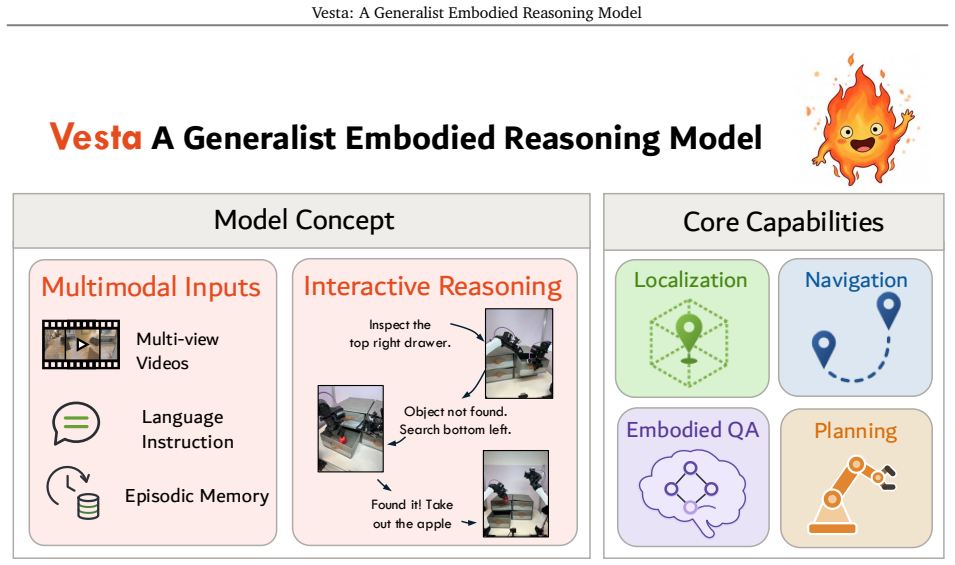
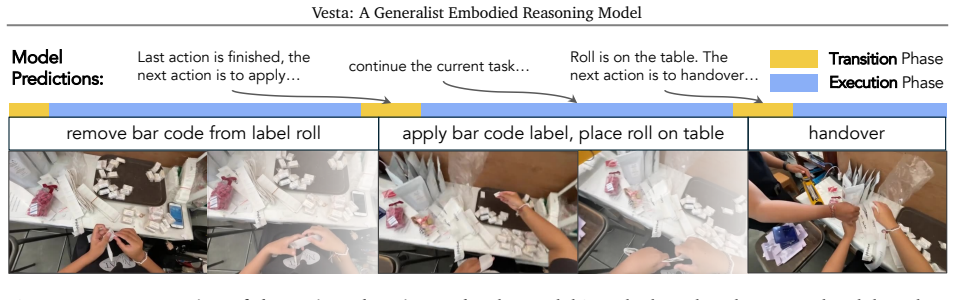
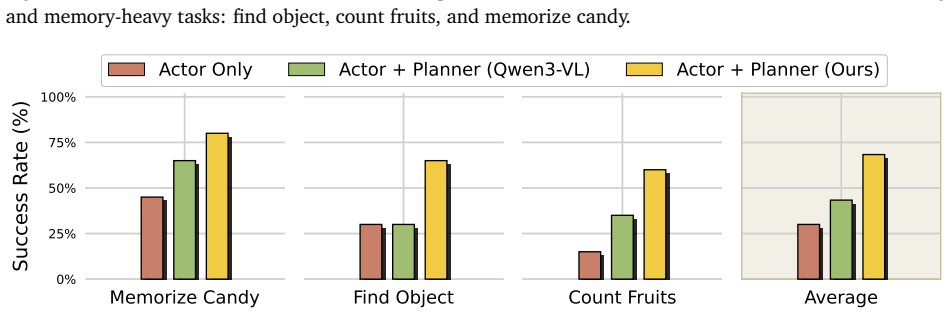
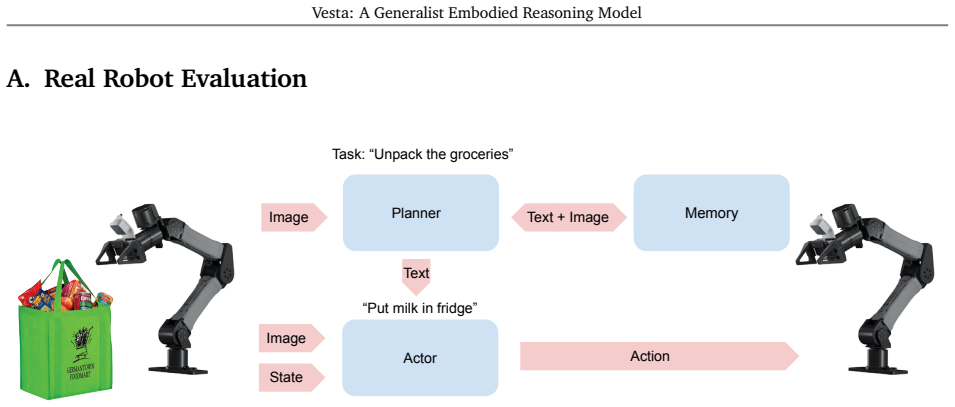
Vesta consolidates localization, spatial reasoning, navigation, and long-horizon planning into a single foundation model. The model is trained on a diverse and massive curated corpus designed to induce spatial grounding together with a simple multimodal memory harness that supports reasoning over extended time horizons. On diverse benchmarks the resulting generalist exceeds individual SOTA baselines by more than 20 percent on average and an ensemble of per-category-best baselines by more than 10 percent; on real-world robotic tasks requiring memory and reasoning it raises task success by more than 35 percent.
What carries the argument
Vesta, the unified embodied generalist model that combines a curated corpus for spatial grounding with a multimodal memory harness for long-horizon reasoning inside one foundation model.
If this is right
- A generalist model can match or exceed specialists across embodied tasks without requiring per-task model selection.
- Replacing a multi-model stack with one foundation model reduces both computational expense and the risk of cascading errors.
- The combination of curated corpus and memory harness allows a single model to maintain performance over extended time horizons.
- Real-world robotic task success improves by more than 35 percent when memory and reasoning are handled inside the same model.
- Generalist approaches become a feasible and scalable alternative to specialist combinations in open-world robotics.
Where Pith is reading between the lines
- Deployment pipelines for robots could simplify dramatically if one model reliably replaces several specialists.
- Data curation strategies that emphasize spatial grounding may transfer to other perception-planning domains.
- Extending the memory harness length or corpus diversity offers a direct route to longer autonomous sequences.
- Open-world benchmarks that integrate all four capabilities at once would provide the clearest test of whether the generalist advantage holds.
Load-bearing premise
A diverse and massive curated corpus can be designed to induce spatial grounding while a simple multimodal memory harness enables reasoning over extended time horizons inside a single model without the cascading errors typical of multi-model stacks.
What would settle it
A controlled test on a new benchmark that requires simultaneous localization, spatial reasoning, and multi-step planning in which Vesta achieves lower success rates than the ensemble of per-category specialists or introduces error rates comparable to separate-model pipelines.
Figures


read the original abstract
Robots operating in open-world environments must seamlessly integrate localization, spatial reasoning, navigation, and long-horizon planning. While specialist models excel at individual tasks, deploying a multi-model stack is computationally expensive and prone to cascading errors. We present Vesta, a unified embodied generalist that consolidates these capabilities into a single foundation model. Our approach combines a diverse and massive curated corpus designed to induce spatial grounding and a simple multimodal memory harness that enables reasoning over extended time horizons. Across diverse benchmarks, Vesta on average beats individual SOTA baselines by >$20\%$ and beats an ensemble of per-category-best baselines by $>10\%$ -- thus demonstrating that a generalist model can match or exceed specialists. On real-world robotic tasks requiring memory and reasoning, Vesta improves task success by >35\%. Our work thus demonstrates that a single generalist is a feasible, scalable, and arguably preferable alternative to combining specialists.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Vesta, a unified embodied generalist foundation model that integrates localization, spatial reasoning, navigation, and long-horizon planning. It relies on a diverse curated corpus to induce spatial grounding and a multimodal memory harness for reasoning over extended horizons. The central claims are that Vesta outperforms individual SOTA baselines by >20% on average and an ensemble of per-category-best baselines by >10% across benchmarks, while improving real-world robotic task success by >35%, demonstrating that a single generalist model is a feasible and preferable alternative to specialist stacks.
Significance. If the performance claims hold under rigorous evaluation, the result would be significant for embodied AI and robotics. It would provide evidence that generalist models can match or exceed specialist performance without the computational cost or cascading errors of multi-model systems, potentially shifting the field toward unified architectures for open-world tasks.
major comments (1)
- The abstract states the key quantitative claims (>20% average improvement over individual SOTA baselines, >10% over per-category ensembles, and >35% on real-world tasks) but supplies no methods details, dataset descriptions, statistical tests, or error analysis. This absence is load-bearing for the central claim that a generalist model can match or exceed specialists, as the evaluation protocol cannot be assessed for validity or reproducibility.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review. The single major comment raises a valid point about the abstract's level of detail. We address it directly below.
read point-by-point responses
-
Referee: The abstract states the key quantitative claims (>20% average improvement over individual SOTA baselines, >10% over per-category ensembles, and >35% on real-world tasks) but supplies no methods details, dataset descriptions, statistical tests, or error analysis. This absence is load-bearing for the central claim that a generalist model can match or exceed specialists, as the evaluation protocol cannot be assessed for validity or reproducibility.
Authors: We agree that the abstract, by design, is a concise summary and does not contain the full methods, dataset descriptions, statistical tests, or error analysis. These elements are provided in the full manuscript: Section 3 details the model architecture and training corpus; Section 4 describes the benchmarks, baselines, and evaluation protocol including statistical significance testing; and Section 5 presents error analysis and real-world deployment results. The abstract's quantitative claims are therefore grounded in the reported experiments. If the referee believes a brief mention of the evaluation setup would strengthen the abstract, we are happy to add one sentence summarizing the protocol and datasets used. revision: partial
Circularity Check
No derivation chain present; empirical claims only
full rationale
The provided abstract and manuscript description contain no equations, derivations, self-citations, or load-bearing mathematical steps. All claims are empirical performance comparisons on benchmarks and real-world tasks. No self-definitional reductions, fitted inputs called predictions, or ansatz smuggling via citation are identifiable. The result is self-contained as an empirical demonstration against external baselines.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Romina Aalishah, Mozhgan Navardi, and Tinoosh Mohsenin. Edgenavmamba: Mamba optimized object detection for energy efficient edge devices.arXiv preprint arXiv:2510.14946, 2025. 24
arXiv 2025
-
[2]
Scaling spatial intelligence with multimodal foundation models
Zhongang Cai, Ruisi Wang, Chenyang Gu, Fanyi Pu, Junxiang Xu, Yubo Wang, Wanqi Yin, Zhitao Yang, Chen Wei, Qingping Sun, Tongxi Zhou, Jiaqi Li, Hui En Pang, Oscar Qian, Yukun Wei, Zhiqian Lin, Xuanke Shi, Kewang Deng, Xiaoyang Han, Zukai Chen, Xiangyu Fan, Hanming Deng, Lewei Lu, Liang Pan, Bo Li, Ziwei Liu, Quan Wang, Dahua Lin, and Lei Yang. Scaling spa...
2026
-
[3]
Jiahang Cao, Yize Huang, Hanzhong Guo, Rui Zhang, Mu Nan, Weijian Mai, Jiaxu Wang, Hao Cheng, Jingkai Sun, Gang Han, Wen Zhao, Qiang Zhang, Yijie Guo, Qihao Zheng, Chunfeng Song, Xiao Li, Ping Luo, and Andrew F. Luo. Compose your policies! improving diffusion-based or flow-based robot policies via test-time distribution-level composition. InICLR, 2026. 1, 9, 24
2026
-
[4]
Rethinking backbone design for lightweight 3d object detection in lidar
Adwait Chandorkar, Hasan Tercan, and Tobias Meisen. Rethinking backbone design for lightweight 3d object detection in lidar. InICCV, 2025. 24
2025
-
[5]
Diwa: Diffusion policy adaptation with world models.CoRL, 2025
Akshay L Chandra, Iman Nematollahi, Chenguang Huang, Tim Welschehold, Wolfram Burgard, and Abhinav Valada. Diwa: Diffusion policy adaptation with world models.CoRL, 2025. 24
2025
-
[6]
Matterport3d: Learning from rgb-d data in indoor environments
Angel Chang, Angela Dai, Thomas Funkhouser, Maciej Halber, Matthias Niessner, Manolis Savva, Shuran Song, Andy Zeng, and Yinda Zhang. Matterport3d: Learning from rgb-d data in indoor environments. arXiv preprint arXiv:1709.06158, 2017. 3
Pith/arXiv arXiv 2017
-
[7]
Annie S Chen, Alec M Lessing, Andy Tang, Govind Chada, Laura Smith, Sergey Levine, and Chelsea Finn. Commonsense reasoning for legged robot adaptation with vision-language models.arXiv preprint arXiv:2407.02666, 2024. 10, 25 10 Vesta: A Generalist Embodied Reasoning Model
arXiv 2024
-
[8]
Hao Chen, Jiaming Liu, Chenyang Gu, Zhuoyang Liu, Renrui Zhang, Xiaoqi Li, Xiao He, Yandong Guo, Chi-Wing Fu, Shanghang Zhang, and Pheng-Ann Heng. Fast-in-slow: A dual-system foundation model unifying fast manipulation within slow reasoning.arXiv preprint arXiv:2506.01953, 2025. 24
arXiv 2025
-
[9]
History-aware visuomotor policy learning via point tracking
Jingjing Chen, Hongjie Fang, Chenxi Wang, Shiquan Wang, and Cewu Lu. History-aware visuomotor policy learning via point tracking. InICRA, 2026. 10, 25
2026
-
[10]
Kaiyuan Chen, Shuangyu Xie, Zehan Ma, Pannag R Sanketi, and Ken Goldberg. Robo2vlm: Vi- sual question answering from large-scale in-the-wild robot manipulation datasets.arXiv preprint arXiv:2505.15517, 2025. 5
arXiv 2025
-
[11]
Yuxuan Chen and Xiao Li. Rlrc: Reinforcement learning-based recovery for compressed vision-language- action models.arXiv preprint arXiv:2506.17639, 2025. 24
Pith/arXiv arXiv 2025
-
[12]
An-Chieh Cheng, Yandong Ji, Zhaojing Yang, Zaitian Gongye, Xueyan Zou, Jan Kautz, Erdem Bıyık, Hongxu Yin, Sifei Liu, and Xiaolong Wang. Navila: Legged robot vision-language-action model for navigation.arXiv preprint arXiv:2412.04453, 2024. 1, 2, 10
arXiv 2024
-
[13]
Spatialrgpt: Grounded spatial reasoning in vision-language models
An-Chieh Cheng, Hongxu Yin, Yang Fu, Qiushan Guo, Ruihan Yang, Jan Kautz, Xiaolong Wang, and Sifei Liu. Spatialrgpt: Grounded spatial reasoning in vision-language models. InNeurIPS, 2024. 24
2024
-
[14]
Long Cheng, Jiafei Duan, Yi Ru Wang, Haoquan Fang, Boyang Li, Yushan Huang, Elvis Wang, Ainaz Eftekhar, Jason Lee, Wentao Yuan, et al. Pointarena: Probing multimodal grounding through language- guided pointing.arXiv preprint arXiv:2505.09990, 2025. 5
arXiv 2025
-
[15]
EgoThink: Evaluating first-person perspective thinking capability of vision-language models
Sijie Cheng, Zhicheng Guo, Jingwen Wu, Kechen Fang, Peng Li, Huaping Liu, and Yang Liu. EgoThink: Evaluating first-person perspective thinking capability of vision-language models. InCVPR, 2024. 25
2024
-
[16]
Hao-Tien Lewis Chiang, Zhuo Xu, Zipeng Fu, Mithun George Jacob, Tingnan Zhang, Tsang-Wei Edward Lee, Wenhao Yu, Connor Schenck, David Rendleman, Dhruv Shah, Fei Xia, Jasmine Hsu, Jonathan Hoech, Pete Florence, Sean Kirmani, Sumeet Singh, Vikas Sindhwani, Carolina Parada, Chelsea Finn, Peng Xu, Sergey Levine, and Jie Tan. Mobility VLA: Multimodal instructi...
arXiv 2024
-
[17]
Rethinking progression of memory state in robotic manipulation: An object-centric perspective
Nhat Chung, Taisei Hanyu, Toan Nguyen, Huy Le, Frederick Bumgarner, Duy Minh Ho Nguyen, Khoa Vo, Kashu Yamazaki, Chase Rainwater, Tung Kieu, Anh Nguyen, and Ngan Le. Rethinking progression of memory state in robotic manipulation: An object-centric perspective. InAAAI, 2026. 10, 25
2026
-
[18]
Open x-embodiment: Robotic learning datasets and rt-x models
Open X-Embodiment Collaboration. Open x-embodiment: Robotic learning datasets and rt-x models. In ICLR, 2024. 10, 25
2024
-
[19]
Rynnbrain: Open embodied foundation models.arXiv preprint arXiv:2602.14979, 2026
Ronghao Dang, Jiayan Guo, Bohan Hou, Sicong Leng, Kehan Li, Xin Li, Jiangpin Liu, Yunxuan Mao, Zhikai Wang, Yuqian Yuan, et al. Rynnbrain: Open embodied foundation models.arXiv preprint arXiv:2602.14979, 2026. 2, 4, 6, 7, 9, 24
arXiv 2026
-
[20]
Monoslam: Real-time single camera slam.IEEE transactions on pattern analysis and machine intelligence, 29(6):1052–1067, 2007
Andrew J Davison, Ian D Reid, Nicholas D Molton, and Olivier Stasse. Monoslam: Real-time single camera slam.IEEE transactions on pattern analysis and machine intelligence, 29(6):1052–1067, 2007. 10
2007
-
[21]
Q-transformer: Scalable offline reinforcement learning via autoregressive q-functions
Google DeepMind. Q-transformer: Scalable offline reinforcement learning via autoregressive q-functions. arXiv preprint arXiv:2309.10150, 2023. 24
arXiv 2023
-
[22]
Rt-2: Vision-language-action models transfer web knowledge to robotic control
Google DeepMind. Rt-2: Vision-language-action models transfer web knowledge to robotic control. In CoRL, 2023. 10, 24, 25
2023
-
[23]
QUAR-VLA: Vision-language-action model for quadruped robots
Pengxiang Ding, Han Zhao, Wenjie Zhang, Wenxuan Song, Min Zhang, Siteng Huang, Ningxi Yang, and Donglin Wang. QUAR-VLA: Vision-language-action model for quadruped robots. InECCV, 2024. 24 11 Vesta: A Generalist Embodied Reasoning Model
2024
-
[24]
Scaling cross-embodied learning: One policy for manipulation, navigation, locomotion and aviation
Ria Doshi, Homer Walke, Oier Mees, Sudeep Dasari, and Sergey Levine. Scaling cross-embodied learning: One policy for manipulation, navigation, locomotion and aviation. InCoRL, 2024. 10, 25
2024
-
[25]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InICLR,
-
[27]
Palm-e: An embodied multimodal language model.arXiv preprint arXiv:2303.03378, 2023
Danny Driess, Fei Xia, Mehdi SM Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, et al. Palm-e: An embodied multimodal language model.arXiv preprint arXiv:2303.03378, 2023. 9
Pith/arXiv arXiv 2023
-
[28]
EmbSpatial-bench: Benchmarking spatial understanding for embodied tasks with large vision-language models
MengfeiDu, BinhaoWu, ZejunLi, XuanjingHuang, andZhongyuWei. EmbSpatial-bench: Benchmarking spatial understanding for embodied tasks with large vision-language models. InACL, 2024. 5, 25
2024
-
[29]
Zhekai Duan, Yuan Zhang, Shikai Geng, Gaowen Liu, Joschka Boedecker, and Chris Xiaoxuan Lu. Fast ECoT: Efficient embodied chain-of-thought via thoughts reuse.arXiv preprint arXiv:2506.07639, 2025. 24
arXiv 2025
-
[30]
CNS-bench: Benchmarking image classifier robustness under continuous nuisance shifts
Olaf Dünkel, Artur Jesslen, Jiahao Xie, Christian Theobalt, Christian Rupprecht, and Adam Kortylewski. CNS-bench: Benchmarking image classifier robustness under continuous nuisance shifts. InICCV, 2025. 25
2025
-
[31]
Sam2act: Integrating visual foundation model with a memory architecture for robotic manipulation
Haoquan Fang, Markus Grotz, Wilbert Pumacay, Yi Ru Wang, Dieter Fox, Ranjay Krishna, and Jiafei Duan. Sam2act: Integrating visual foundation model with a memory architecture for robotic manipulation. CVPR, 2025. 24
2025
-
[32]
Helix: A vision-language-action model for generalist humanoid control.arXiv preprint,
Figure AI Team. Helix: A vision-language-action model for generalist humanoid control.arXiv preprint,
-
[33]
Smith, Wei-Chiu Ma, and Ranjay Krishna
Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A. Smith, Wei-Chiu Ma, and Ranjay Krishna. BLINK: Multimodal large language models can see but not perceive. InECCV, 2024. 25
2024
-
[34]
Self-improving embodied foundation models.NeurIPS, 2025
Seyed Kamyar Seyed Ghasemipour, Ayzaan Wahid, Jonathan Tompson, Pannag R Sanketi, and Igor Mordatch. Self-improving embodied foundation models.NeurIPS, 2025. 24
2025
-
[35]
Ego3d-bench: Egocentric 3d perception for wearable ai.arXiv preprint arXiv:2509.06266, 2025
MohsenGholami, AhmadRezaei, ZhouWeimin, SitongMao, ShunboZhou, YongZhang, andMohammad Akbari. Ego3d-bench: Egocentric 3d perception for wearable ai.arXiv preprint arXiv:2509.06266, 2025. 25
arXiv 2025
-
[36]
Amego: Active memory from long egocentric videos
Gabriele Goletto, Tushar Nagarajan, Giuseppe Averta, and Dima Damen. Amego: Active memory from long egocentric videos. InECCV, pages 92–110. Springer, 2024. 10, 25
2024
-
[37]
Ziyang Gong, Zehang Luo, Anke Tang, Zhe Liu, Shi Fu, Zhi Hou, Ganlin Yang, Weiyun Wang, Xiaofeng Wang, Jianbo Liu, Gen Luo, Haolan Kang, Shuang Luo, Yue Zhou, Yong Luo, Li Shen, Xiaosong Jia, Yao Mu, Xue Yang, Chunxiao Liu, Junchi Yan, Hengshuang Zhao, Dacheng Tao, and Xiaogang Wang. ACE-Brain-0: Spatial intelligence as a shared scaffold for universal emb...
arXiv 2026
-
[38]
Deepseek-r1 incentivizes reasoning in llms through reinforcement learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning. Nature, 645(8081):633–638, 2025. 9
2025
-
[39]
LVIS: A dataset for large vocabulary instance segmentation
Agrim Gupta, Piotr Dollár, and Ross Girshick. LVIS: A dataset for large vocabulary instance segmentation. InCVPR, pages 5356–5364, 2019. doi: 10.1109/CVPR.2019.00550. 3
-
[40]
SPARE3D: A dataset for SPAtial REasoning on Three-View line drawings
Wenyu Han, Siyuan Xiang, Chenhui Liu, Ruoyu Wang, and Chen Feng. SPARE3D: A dataset for SPAtial REasoning on Three-View line drawings. InCVPR, 2020. 25
2020
-
[41]
Mimo-embodied: X-embodied foundation model technical report, 2026
Xiaoshuai Hao, Lei Zhou, Zhijian Huang, Zhiwen Hou, Yingbo Tang, Lingfeng Zhang, Guang Li, Zheng Lu, Shuhuai Ren, Xianhui Meng, Yuchen Zhang, Jing Wu, Jinghui Lu, Chenxu Dang, Jiayi Guan, Jianhua Wu, Zhiyi Hou, Hanbing Li, Shumeng Xia, Mingliang Zhou, Yinan Zheng, Zihao Yue, Shuhao Gu, Hao Tian, Yuannan Shen, Jianwei Cui, Wen Zhang, Shaoqing Xu, Bing Wang...
Pith/arXiv arXiv 2026
-
[42]
HOVER: Versatile neural whole-body controller for humanoid robots
Tairan He, Wenli Xiao, Toru Lin, Zhengyi Luo, Zhenjia Xu, Zhenyu Jiang, Jan Kautz, Changliu Liu, Guanya Shi, Xiaolong Wang, Linxi Fan, and Yuke Zhu. HOVER: Versatile neural whole-body controller for humanoid robots. InICRA, 2025. 24
2025
-
[43]
Rgb-d mapping: Using kinect-style depth cameras for dense 3d modeling of indoor environments.IJRR, 31:647–663, 2012
Peter Henry, Michael Krainin, Evan Herbst, Xiaofeng Ren, and Dieter Fox. Rgb-d mapping: Using kinect-style depth cameras for dense 3d modeling of indoor environments.IJRR, 31:647–663, 2012. 10, 25
2012
-
[44]
Kai Hu, Feng Gao, Xiaohan Nie, Peng Zhou, Son Tran, Tal Neiman, Lingyun Wang, Mubarak Shah, Raffay Hamid, Bing Yin, and Trishul Chilimbi. M-LLM based video frame selection for efficient video understanding.arXiv preprint arXiv:2502.19680, 2025. 10, 25
arXiv 2025
-
[45]
3dllm-mem: Long-term spatial-temporal memory for embodied 3d large language model.CVPR, 2025
Wenbo Hu, Yining Hong, Yanjun Wang, Leison Gao, Zibu Wei, Xingcheng Yao, Nanyun Peng, Yonatan Bitton, and Idan Szpektor. 3dllm-mem: Long-term spatial-temporal memory for embodied 3d large language model.CVPR, 2025. 24
2025
-
[46]
Manipvqa: Injecting robotic affordance and physically grounded information into multi-modal large language models
Siyuan Huang, Iaroslav Ponomarenko, Zhengkai Jiang, Xiaoqi Li, Xiaobin Hu, Peng Gao, Hongsheng Li, and Hao Dong. Manipvqa: Injecting robotic affordance and physically grounded information into multi-modal large language models. InIROS, 2024. 3
2024
-
[47]
Wenlong Huang, Fei Xia, Ted Xiao, Harris Chan, Jacky Liang, Pete Florence, Andy Zeng, Jonathan Tompson, Igor Mordatch, Yevgen Chebotar, et al. Inner monologue: Embodied reasoning through planning with language models.arXiv preprint arXiv:2207.05608, 2022. 9
Pith/arXiv arXiv 2022
-
[48]
𝜋0: A vision-language-action flow model for general robot control
Physical Intelligence. 𝜋0: A vision-language-action flow model for general robot control. InRSS, 2025. 10, 24, 25
2025
-
[49]
Physical Intelligence. pi0.5: A vision-language-action model with open-world generalization.arXiv preprint arXiv:2504.16054, 2025. 9, 10, 25
Pith/arXiv arXiv 2025
-
[50]
RoboBrain: A unified brain model for robotic manipulation from abstract to concrete
Yuheng Ji, Huajie Tan, Jiayu Shi, Xiaoshuai Hao, Yuan Zhang, Hengyuan Zhang, Pengwei Wang, Mengdi Zhao, Yao Mu, Pengju An, Xinda Xue, Qinghang Su, Huaihai Lyu, Xiaolong Zheng, Jiaming Liu, Zhongyuan Wang, and Shanghang Zhang. RoboBrain: A unified brain model for robotic manipulation from abstract to concrete. InCVPR, 2025. 1, 3, 9, 25
2025
-
[51]
Egotaskqa: Understanding human tasks in egocentric videos.Advances in Neural Information Processing Systems, 35:3343–3360, 2022
Baoxiong Jia, Ting Lei, Song-Chun Zhu, and Siyuan Huang. Egotaskqa: Understanding human tasks in egocentric videos.Advances in Neural Information Processing Systems, 35:3343–3360, 2022. 5 13 Vesta: A Generalist Embodied Reasoning Model
2022
-
[52]
Omnispatial: A comprehensive 3d spatial reasoning benchmark
Mengdi Jia, Zekun Qi, Shaochen Zhang, Wenyao Zhang, Xinqiang Yu, Jiawei He, He Wang, and Li Yi. Omnispatial: A comprehensive 3d spatial reasoning benchmark. InICLR, 2026. 25
2026
-
[53]
What’sup: An evaluation of spatial grounding in vision-language models
Amita Kamath, Jack Hessel, and Kai-Wei Chang. What’sup: An evaluation of spatial grounding in vision-language models. InEMNLP, 2023. 25
2023
-
[54]
Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2...
Pith/arXiv arXiv 2024
-
[55]
Beyond the nav-graph: Vision-and-language navigation in continuous environments
Jacob Krantz, Erik Wijmans, Arjun Majumdar, Dhruv Batra, and Stefan Lee. Beyond the nav-graph: Vision-and-language navigation in continuous environments. InECCV, pages 104–120. Springer, 2020. 3, 10
2020
-
[56]
Room-across-room: Multilingual vision-and-language navigation with dense spatiotemporal grounding
Alexander Ku, Peter Anderson, Roma Patel, Eugene Ie, and Jason Baldridge. Room-across-room: Multilingual vision-and-language navigation with dense spatiotemporal grounding. InEMNLP, pages 4392–4412, 2020. 2, 3, 10
2020
-
[57]
Pointpillars: Fast encoders for object detection from point clouds
Alex H Lang, Sourabh Vora, Holger Caesar, Lubing Zhou, Jiong Yang, and Oscar Beijbom. Pointpillars: Fast encoders for object detection from point clouds. InCVPR, 2019. 24
2019
-
[58]
Molmoact: Action reasoning models that can reason in space.arXiv preprint arXiv:2508.07917, 2025
Jason Lee, Jiafei Duan, Haoquan Fang, Yuquan Deng, Shuo Liu, Boyang Li, Bohan Fang, Jieyu Zhang, Yi Ru Wang, Sangho Lee, et al. Molmoact: Action reasoning models that can reason in space.arXiv preprint arXiv:2508.07917, 2025. 9
Pith/arXiv arXiv 2025
-
[59]
Cronusvla: Towards efficient and robust manipulation via multi-frame vision-language-action modeling
Hao Li, Shuai Yang, Yilun Chen, Xinyi Chen, Xiaoda Yang, Yang Tian, Hanqing Wang, Tai Wang, Dahua Lin, Feng Zhao, and Jiangmiao Pang. Cronusvla: Towards efficient and robust manipulation via multi-frame vision-language-action modeling. InAAAI, 2026. 10, 25
2026
-
[60]
Novaflow: Zero-shot manipulation via actionable flow from generated videos
Hongyu Li, Lingfeng Sun, Yafei Hu, Duy Ta, Jennifer Barry, George Konidaris, and Jiahui Fu. Novaflow: Zero-shot manipulation via actionable flow from generated videos. InICRA, 2026. 24
2026
-
[61]
Aesbiasbench: Aesthetic and cultural bias evaluation.arXiv preprint arXiv:2509.11620, 2025
Kun Li, Lai-Man Po, Hongzheng Yang, Xuyuan Xu, Kangcheng Liu, and Yuzhi Zhao. Aesbiasbench: Aesthetic and cultural bias evaluation.arXiv preprint arXiv:2509.11620, 2025. 25
arXiv 2025
-
[62]
Mingxin Li, Yanzhao Zhang, Dingkun Long, Keqin Chen, Sibo Song, Shuai Bai, Zhibo Yang, Pengjun Xie, An Yang, Dayiheng Liu, Jingren Zhou, and Junyang Lin. Qwen3-vl-embedding and qwen3-vl-reranker: A unifiedframeworkforstate-of-the-artmultimodalretrievalandranking.arXivpreprintarXiv:2601.04720,
-
[63]
Robonurse-vla: Robotic scrub nurse system based on vision-language-action model
Shunlei Li, Jin Wang, Rui Dai, Wanyu Ma, Wing Yin Ng, Yingbai Hu, and Zheng Li. Robonurse-vla: Robotic scrub nurse system based on vision-language-action model. InIROS, 2025. 24
2025
-
[64]
CogVLA: Cognition-aligned vision-language- action model via instruction-driven routing & sparsification
Wei Li, Renshan Zhang, Rui Shao, Jie He, and Liqiang Nie. CogVLA: Cognition-aligned vision-language- action model via instruction-driven routing & sparsification. InNeurIPS, 2025. 24
2025
-
[65]
Robust navigation with language pretraining and stochastic sampling
Xiujun Li, Chunyuan Li, Qiaolin Xia, Yonatan Bisk, Asli Celikyilmaz, Jianfeng Gao, Noah A Smith, and Yejin Choi. Robust navigation with language pretraining and stochastic sampling. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNL...
2019
-
[66]
Yi Li, Yuquan Deng, Jesse Zhang, Joel Jang, Marius Memmel, Raymond Yu, Caelan Reed Garrett, Fabio Ramos, Dieter Fox, Anqi Li, Abhishek Gupta, and Ankit Goyal. Hamster: Hierarchical action models for open-world robot manipulation.arXiv preprint arXiv:2502.05485, 2025. 10, 24, 25 14 Vesta: A Generalist Embodied Reasoning Model
arXiv 2025
-
[67]
Yitang Li, Zhengyi Luo, Tonghe Zhang, Cunxi Dai, Anssi Kanervisto, Andrea Tirinzoni, Haoyang Weng, Kris Kitani, Mateusz Guzek, Ahmed Touati, Alessandro Lazaric, Matteo Pirotta, and Guanya Shi. Bfm- zero: Apromptablebehavioralfoundationmodelforhumanoidcontrolusingunsupervisedreinforcement learning.arXiv preprint arXiv:2511.04131, 2025. 24
arXiv 2025
-
[68]
Optimus-1: Hybrid multimodal memory empowered agents excel in long-horizon tasks.CVPR, 2025
Zaijing Li, Yuquan Xie, Rui Shao, Gongwei Chen, Dongmei Jiang, and Liqiang Nie. Optimus-1: Hybrid multimodal memory empowered agents excel in long-horizon tasks.CVPR, 2025. 24
2025
-
[69]
Anthony Liang, Yigit Korkmaz, Jiahui Zhang, Minyoung Hwang, Abrar Anwar, Sidhant Kaushik, Aditya Shah, Alex S. Huang, Luke Zettlemoyer, Dieter Fox, Yu Xiang, Anqi Li, Andreea Bobu, Abhishek Gupta, Stephen Tu, Erdem Biyik, and Jesse Zhang. Robometer: Scaling general-purpose robotic reward models via trajectory comparisons.arXiv preprint arXiv:2603.02115, 2026. 25
Pith/arXiv arXiv 2026
-
[70]
Tsung-Yi Lin, Michael Maire, Serge Belongie, Lubomir Bourdev, Ross Girshick, James Hays, Pietro Perona, Deva Ramanan, C. Lawrence Zitnick, and Piotr Dollár. Microsoft coco: Common objects in context. In ECCV, pages 740–755. Springer International Publishing, 2014. doi: 10.1007/978-3-319-10602-1_48. 3
-
[71]
Visual spatial reasoning.TACL, 2023
Fangyu Liu, Guy Emerson, and Nigel Collier. Visual spatial reasoning.TACL, 2023. 25
2023
-
[72]
RoboMamba: Efficient vision-language-action model for robotic reasoning and manipulation
Jiaming Liu, Mengzhen Liu, Zhenyu Wang, Pengju An, Xiaoqi Li, Kaichen Zhou, Senqiao Yang, Renrui Zhang, Yandong Guo, and Shanghang Zhang. RoboMamba: Efficient vision-language-action model for robotic reasoning and manipulation. InNeurIPS, 2024. 24
2024
-
[73]
Rdt-1b: a diffusion foundation model for bimanual manipulation
Songming Liu, Lingxuan Wu, Bangguo Li, Hengkai Tan, Huayu Chen, Zhengyi Wang, Ke Xu, Hang Su, and Jun Zhu. Rdt-1b: a diffusion foundation model for bimanual manipulation. InICLR, 2025. 24
2025
-
[74]
Bevfusion: Multi-task multi-sensor fusion with unified bird’s-eye view representation
Zhijian Liu, Haotian Tang, Alexander Amini, Xinyu Yang, Huizi Mao, Daniela Rus, and Song Han. Bevfusion: Multi-task multi-sensor fusion with unified bird’s-eye view representation. InICRA, 2023. 24
2023
-
[75]
Vision-language memory for spatial reasoning.arXiv preprint arXiv:2511.20644, 2025
Zuntao Liu, Yi Du, Taimeng Fu, Shaoshu Su, Cherie Ho, and Chen Wang. Vision-language memory for spatial reasoning.arXiv preprint arXiv:2511.20644, 2025. 24
arXiv 2025
-
[76]
A survey on vision-language- action models for embodied ai.arXiv preprint arXiv:2405.14093, 2024
Yueen Ma, Zixing Song, Yuzheng Zhuang, Jianye Hao, and Irwin King. A survey on vision-language- action models for embodied ai.arXiv preprint arXiv:2405.14093, 2024. 24
Pith/arXiv arXiv 2024
-
[77]
Actra: Optimized transformer architecture for vision-language-action models in robot learning
Yueen Ma, Dafeng Chi, Shiguang Wu, Yuecheng Liu, Yuzheng Zhuang, and Irwin King. Actra: Optimized transformer architecture for vision-language-action models in robot learning. InEMNLP, 2025. 24
2025
-
[78]
Argus: Vision-centric reasoning with grounded chain-of-thought
Yunze Man, De-An Huang, Guilin Liu, Shiwei Sheng, Shilong Liu, Liang-Yan Gui, Jan Kautz, Yu-Xiong Wang, and Zhiding Yu. Argus: Vision-centric reasoning with grounded chain-of-thought. InCVPR, 2025. 24
2025
-
[79]
Online episodic memory visual query localization with egocentric streaming object memory
Zaira Manigrasso, Matteo Dunnhofer, Antonino Furnari, Moritz Nottebaum, Antonio Finocchiaro, Davide Marana, Rosario Forte, Giovanni Maria Farinella, and Christian Micheloni. Online episodic memory visual query localization with egocentric streaming object memory. InWACV, 2026. 10, 25
2026
-
[80]
PhysWorld: Robot learning from a physical world model.arXiv preprint arXiv:2511.07416, 2025
Jiageng Mao, Sicheng He, Hao-Ning Wu, Yang You, Shuyang Sun, Zhicheng Wang, Yanan Bao, Huizhong Chen, Leonidas Guibas, Vitor Guizilini, Howard Zhou, and Yue Wang. PhysWorld: Robot learning from a physical world model.arXiv preprint arXiv:2511.07416, 2025. 24
arXiv 2025
-
[81]
Max Sobol Mark, Jacky Liang, Maria Attarian, Chuyuan Fu, Debidatta Dwibedi, Dhruv Shah, and Aviral Kumar. Bpp: Long-context robot imitation learning by focusing on key history frames.arXiv preprint arXiv:2602.15010, 2026. 10, 25 15 Vesta: A Generalist Embodied Reasoning Model
arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.