Automatically Improving Simulation Physics for Articulated Objects
Pith reviewed 2026-05-20 08:56 UTC · model grok-4.3
The pith
A simulator-in-the-loop method infers and corrects physical properties of articulated objects from incomplete 3D assets to improve simulation stability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a multi-modal, simulator-in-the-loop refinement procedure can automatically infer and adjust missing physical parameters of articulated objects so that the resulting assets satisfy measurable interaction-readiness criteria and exhibit more stable, realistic contact behavior during manipulation tasks.
What carries the argument
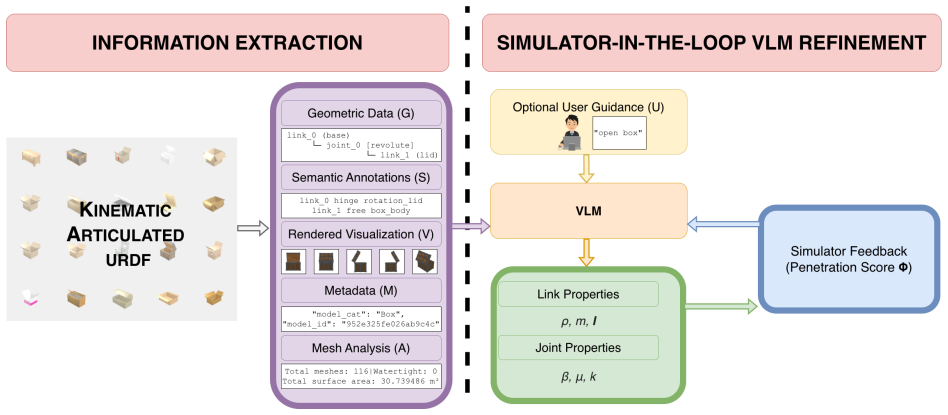
The multi-modal simulator-in-the-loop refinement loop that ingests geometric, visual, and semantic cues and iteratively updates physical parameters until simulator feedback indicates improved consistency.
If this is right
- Higher-quality object assets directly reduce simulation crashes and erratic contact forces during manipulation.
- Policies trained or evaluated on refined objects transfer more reliably to new tasks.
- The same refinement loop can be applied to large existing 3D datasets to produce libraries of interaction-ready articulated objects.
- Evaluation frameworks that measure interaction-readiness components expose failure modes invisible to standard geometric or kinematic checks.
Where Pith is reading between the lines
- The method could be extended to non-articulated rigid bodies or deformable objects by re-using the same cue-and-feedback structure.
- If the refinement generalizes across simulators, it offers a route to standardize physical properties for cross-simulator robot learning benchmarks.
- Repeated application over many objects may reveal statistical patterns in typical missing parameters that could inform future dataset design.
Load-bearing premise
Iterative simulator feedback together with geometric, visual, and semantic information is sufficient to recover accurate physical properties without any ground-truth measurements.
What would settle it
Run the same manipulation policies on both original and refined object sets in an independent simulator or on a real robot and observe whether the refined set still produces measurably fewer instability events or policy failures.
Figures





read the original abstract
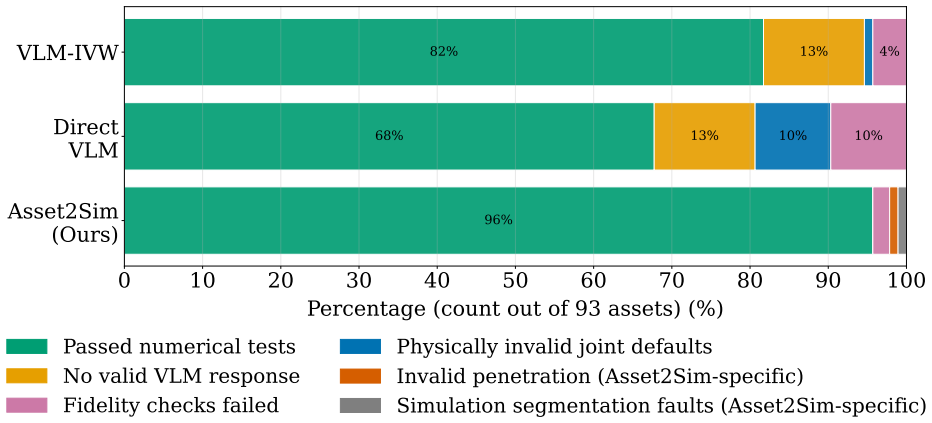
Simulation is a central tool for scalable robot learning, but its effectiveness depends on the quality of object assets. While modern 3D datasets provide rich geometric and kinematic representations, they typically lack the physical properties required for stable and realistic interaction, requiring significant manual effort to construct simulation-ready articulated objects. In this thesis, we introduce interaction-readiness, which characterizes whether an object can be reliably simulated under manipulation. We propose a quantitative evaluation framework that decomposes interaction-readiness into measurable components, enabling systematic analysis of object quality and revealing failure modes not captured by conventional evaluation. We further present a multi-modal, simulator-in-the-loop approach for generating interaction-ready articulated objects from incomplete 3D assets. The method integrates geometric, visual, and semantic information to infer physical properties and refines them through iterative simulator feedback to improve physical consistency. Experiments across diverse articulated objects and manipulation tasks show that object quality directly impacts simulation stability, interaction behavior, and policy performance. Objects refined by our method exhibit more stable and realistic dynamics, enabling more reliable downstream learning and evaluation. Overall, this thesis demonstrates the importance of physical realism for articulated objects in simulation and introduces a practical multi-modal refinement approach, guided by simulator feedback, for constructing such objects at scale.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the concept of interaction-readiness for articulated objects in simulation and presents a multi-modal, simulator-in-the-loop refinement method that combines geometric, visual, and semantic cues to infer and iteratively correct physical properties (such as mass, friction, and joint parameters) from incomplete 3D assets. It also proposes a quantitative evaluation framework decomposing interaction-readiness into measurable components. Experiments on diverse objects and manipulation tasks are claimed to demonstrate that refined objects yield improved simulation stability, interaction behavior, and downstream policy performance compared to unrefined assets.
Significance. If the refinements can be shown to produce dynamics that better match real-world behavior rather than merely stabilizing the simulator, the approach would address a significant practical barrier in scalable robot learning by reducing the manual effort needed to create simulation-ready articulated assets from existing 3D datasets.
major comments (2)
- Experiments section: the central claim that refined objects exhibit 'more stable and realistic dynamics' enabling better policy performance rests entirely on metrics collected inside the identical simulator supplying the iterative feedback signal. No real-world measurements, external ground-truth data, or cross-simulator validation are described, leaving open the possibility that parameters are tuned only to eliminate simulator-specific artifacts rather than achieving physical fidelity.
- Method overview (and Abstract): the inference of physical properties from geometric/visual/semantic cues and the precise form of the simulator feedback loop (including any objective function, parameter update rule, or stopping criterion) are not specified with sufficient detail to assess reproducibility or to determine whether the process is parameter-free or relies on hand-tuned thresholds.
minor comments (2)
- The abstract refers to the work as 'this thesis,' which should be revised for consistency with journal article conventions.
- Clarify the exact set of physical parameters being refined and how they are initialized from the input 3D assets.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review of our manuscript. Below we address each of the major comments point by point, indicating where we agree and the revisions we plan to implement.
read point-by-point responses
-
Referee: Experiments section: the central claim that refined objects exhibit 'more stable and realistic dynamics' enabling better policy performance rests entirely on metrics collected inside the identical simulator supplying the iterative feedback signal. No real-world measurements, external ground-truth data, or cross-simulator validation are described, leaving open the possibility that parameters are tuned only to eliminate simulator-specific artifacts rather than achieving physical fidelity.
Authors: We agree with the referee that our evaluation is performed within the same simulator used for the refinement process, which could potentially optimize for simulator-specific behaviors. Our primary contribution is demonstrating that the proposed refinement leads to more stable simulations and better policy performance in manipulation tasks, as measured by our interaction-readiness framework. To address this concern, we will revise the manuscript to tone down claims of 'realistic dynamics' and instead focus on 'improved simulation stability and interaction behavior'. We will also include a new subsection in the discussion that explicitly acknowledges the lack of real-world or cross-simulator validation and outlines plans for such evaluations in future work. revision: yes
-
Referee: Method overview (and Abstract): the inference of physical properties from geometric/visual/semantic cues and the precise form of the simulator feedback loop (including any objective function, parameter update rule, or stopping criterion) are not specified with sufficient detail to assess reproducibility or to determine whether the process is parameter-free or relies on hand-tuned thresholds.
Authors: We appreciate this feedback on the clarity of our method description. While the full manuscript provides additional details beyond the abstract, we recognize that the overview may not be sufficient for reproducibility. In the revised manuscript, we will enhance the method section by providing a more precise specification of how geometric, visual, and semantic cues are combined to infer initial physical properties. We will also detail the simulator feedback loop, including the objective function that minimizes instability metrics, the parameter update rule based on iterative search, and the stopping criterion when changes in key metrics fall below a threshold. We will explicitly state the hand-tuned parameters and their values to allow readers to reproduce the process. revision: yes
- Conducting real-world measurements or cross-simulator validation to directly verify physical fidelity, as this is beyond the scope of the current simulation-focused study and would require substantial new resources.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper defines interaction-readiness as a decomposable property and presents a multi-modal simulator-in-the-loop refinement procedure that incorporates geometric, visual, semantic cues plus iterative feedback to infer and adjust physical parameters. Experiments then measure downstream effects on stability, interaction behavior, and policy performance inside simulation. No equations, fitted parameters, or self-citations appear in the provided text that reduce any claimed prediction or result to the refinement inputs by construction; the evaluation framework supplies independent measurable components against which improvements are reported. The derivation therefore remains self-contained.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
multi-modal, simulator-in-the-loop approach ... integrates geometric, visual, and semantic information to infer physical properties and refines them through iterative simulator feedback
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
interaction-readiness ... physical robustness, semantic accuracy, behavioral fidelity
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
91 HaoranGeng, HelinXu, ChengyangZhao, ChaoXu, LiYi, SiyuanHuang, andHeWang. Gapartnet: Cross-category domain-generalizable object perception and manipulation via generalizable and actionable parts.arXiv preprint arXiv:2211.05272,
-
[3]
URL https: //arxiv.org/abs/2506.04941. Abhishek Joshi, Beining Han, Jack Nugent, Max Gonzalez Saez-Diez, Yiming Zuo, Jonathan Liu, Hongyu Wen, Stamatis Alexandropoulos, Karhan Kayan, Anna Calveri, Tao Sun, Gaowen Liu, Yi Shao, Alexander Raistrick, and Jia Deng. Procedural generation of articulated simulation- ready assets,
-
[4]
Procedural genera- tion of articulated simulation-ready assets, 2025
URL https://arxiv.org/abs/2505.10755. Rishabh Kabra, Loic Matthey, Alexander Lerchner, and Niloy J Mitra. Leveraging vlm-based pipelines to annotate 3d objects.arXiv preprint arXiv:2311.17851,
-
[5]
Long Le, Jason Xie, William Liang, Hung-Ju Wang, Yue Yang, Yecheng Jason Ma, Kyle Vedder, Arjun Krishna, Dinesh Jayaraman, and Eric Eaton. Articulate-anything: Automatic modeling of articulated objects via a vision-language foundation model.arXiv preprint arXiv:2410.13882,
-
[6]
Long Le, Ryan Lucas, Chen Wang, Chuhao Chen, Dinesh Jayaraman, Eric Eaton, and Lingjie Liu. Pixie: Fast and generalizable supervised learning of 3d physics from pixels.arXiv preprint arXiv:2508.17437,
-
[7]
Zhe Li, Xiang Bai, Jieyu Zhang, Zhuangzhe Wu, Che Xu, Ying Li, Chengkai Hou, and Shanghang Zhang. Urdf-anything: Constructing articulated objects with 3d multimodal language model. arXiv preprint arXiv:2511.00940,
-
[8]
LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning.arXiv preprint arXiv:2306.03310,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Isaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
Mayank Mittal, Pascal Roth, James Tigue, Antoine Richard, Octi Zhang, Peter Du, Antonio Serrano-Muñoz, Xinjie Yao, René Zurbrügg, Nikita Rudin, Lukasz Wawrzyniak, Milad Rakhsha, Alain Denzler, Eric Heiden, Ales Borovicka, Ossama Ahmed, Iretiayo Akinola, Abrar Anwar, Mark T. Carlson, Ji Yuan Feng, Animesh Garg, Renato Gasoto, Lionel Gulich, Yijie Guo, M. G...
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Isaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
doi: 10.48550/arXiv.2511.04831. URL 93 https://arxiv.org/abs/2511.04831. Kaichun Mo, Shilin Zhu, Angel X. Chang, Li Yi, Subarna Tripathi, Leonidas J. Guibas, and Hao Su. PartNet: A large-scale benchmark for fine-grained and hierarchical part-level 3D object understanding. InThe IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2511.04831
-
[11]
DreamFusion: Text-to-3D using 2D Diffusion
Accessed: 2026-04-27. Ben Poole, Ajay Jain, Jonathan T Barron, and Ben Mildenhall. Dreamfusion: Text-to-3d using 2d diffusion.arXiv preprint arXiv:2209.14988,
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
arXiv preprint arXiv:2502.02590 (2025)
Xiaowen Qiu, Jincheng Yang, Yian Wang, Zhehuan Chen, Yufei Wang, Tsun-Hsuan Wang, Zhou Xian, and Chuang Gan. Articulate anymesh: Open-vocabulary 3d articulated objects modeling. arXiv preprint arXiv:2502.02590,
-
[13]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Mu- joco: A physics engine for model-based control
doi: 10.1109/IROS.2012.6386109. Trimesh Authors. Trimesh,
-
[15]
Maggie Wang, Stephen Tian, Aiden Swann, Ola Shorinwa, Jiajun Wu, and Mac Schwager
URL https://github.com/mikedh/trimesh. Maggie Wang, Stephen Tian, Aiden Swann, Ola Shorinwa, Jiajun Wu, and Mac Schwager. Phys2real: Fusing vlm priors with interactive online adaptation for uncertainty-aware sim-to- real manipulation.arXiv preprint arXiv:2510.11689,
-
[16]
RoboLab: A High-Fidelity Simulation Benchmark for Analysis of Task Generalist Policies
URL https://arxiv.org/abs/2604.09860. Yu Yang, Zhilu Zhang, Xiang Zhang, Yihan Zeng, Hui Li, and Wangmeng Zuo. Physworld: From real videos to world models of deformable objects via physics-aware demonstration synthesis. arXiv preprint arXiv:2510.21447,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.