When Context Misleads: Surprisal, Energy and Attention Entropy as Metrics of Coherence Illusions in LLMs
Pith reviewed 2026-06-26 14:39 UTC · model grok-4.3
The pith
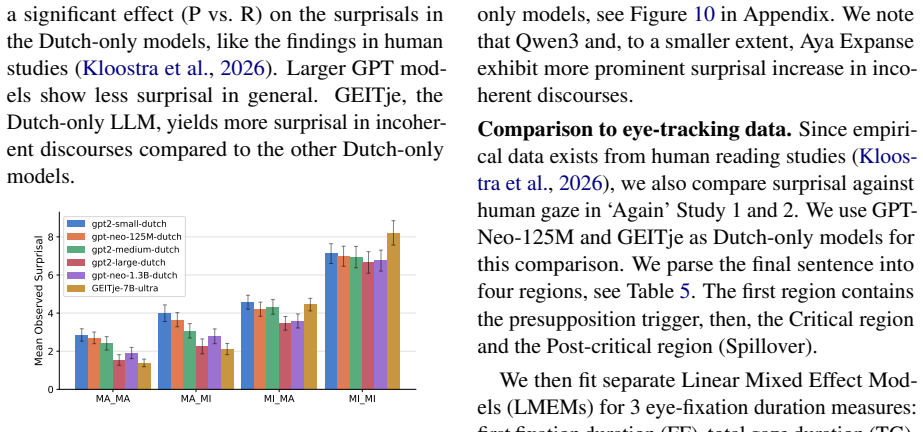
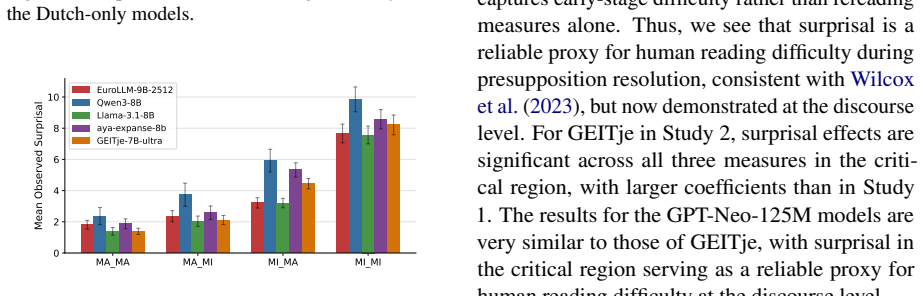
Dutch language models fall for coherence illusions when a distractor in prior context reduces surprisal at incoherent text.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
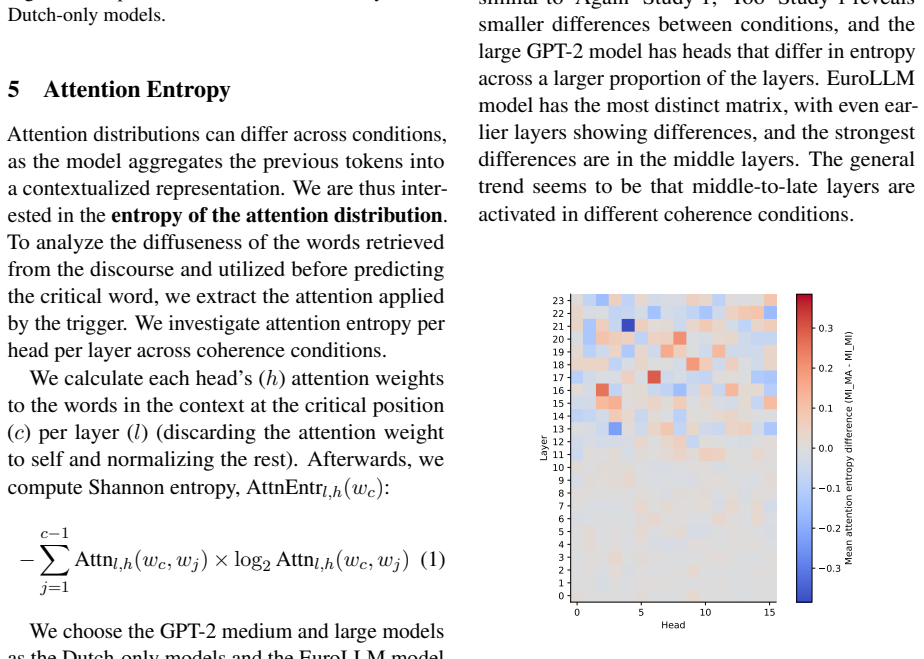
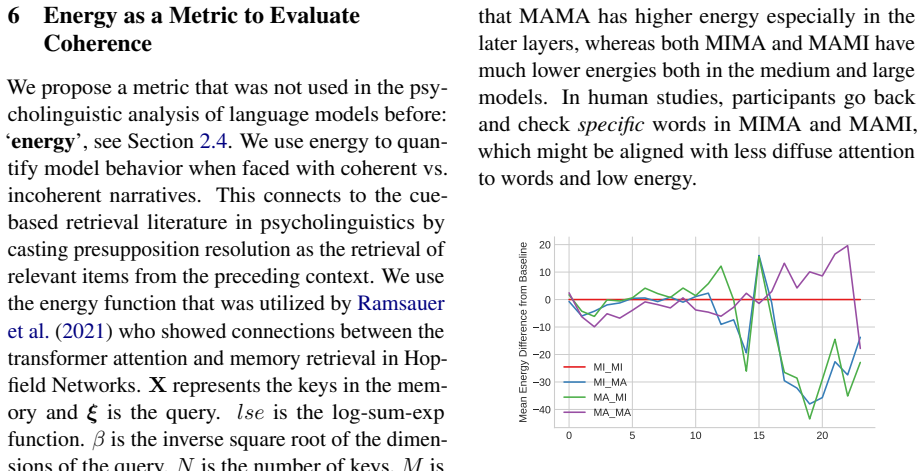
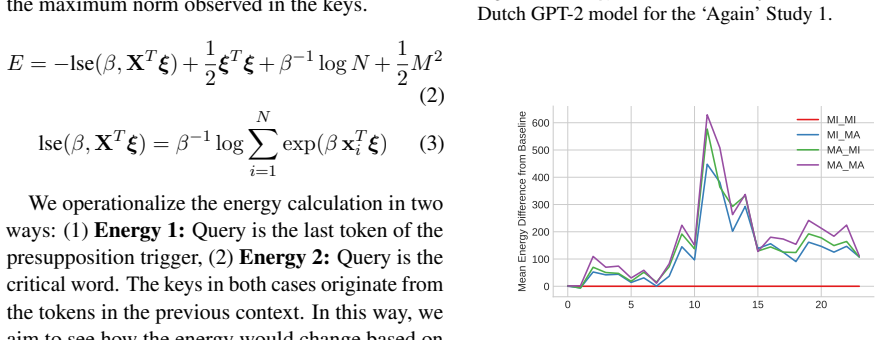
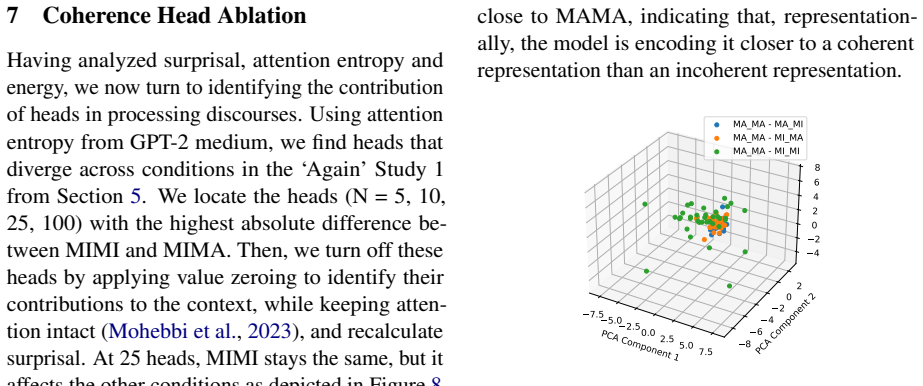
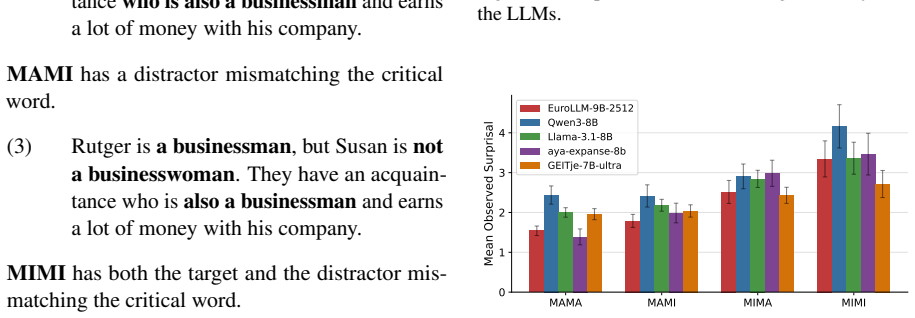
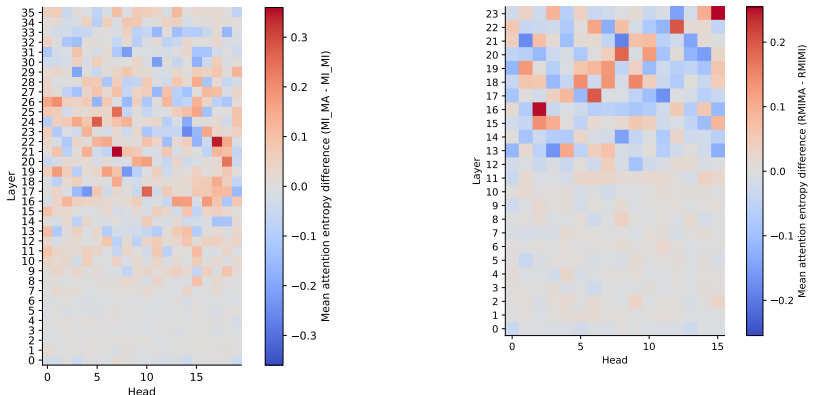
Coherence illusions arise in Dutch LLMs because a distractor in the prior context that matches the critical word reduces the surprisal at that word even when the overall discourse is incoherent. Attention entropy identifies heads that differ under coherent versus incoherent conditions, and ablating them shows transfer effects across experiments, suggesting a shared mechanism. Energy from the associative-memory literature serves as a metric that quantifies discourse coherence across the tested settings.
What carries the argument
Surprisal at the critical word, together with attention entropy over heads and the energy metric, which together detect when prior context lowers surprise for an otherwise incoherent continuation.
If this is right
- Surprisal values align with human acceptability judgments and eye-tracking measures on the same materials.
- Specific attention heads show distinct entropy patterns under coherent versus incoherent conditions.
- Ablating the identified heads produces measurable transfer effects between different illusion experiments.
- The energy metric tracks discourse coherence in a way that operates across both monolingual and multilingual models.
Where Pith is reading between the lines
- If the same heads and energy patterns appear in non-Dutch models, the illusion mechanism may be architecture-level rather than language-specific.
- Energy could be added as an auxiliary training signal to penalize low-coherence states during pretraining.
- Long-context applications such as summarization may inherit the same distractor sensitivity observed here.
Load-bearing premise
The chosen texts built around 'again' and 'too' plus the ten specific Dutch models are representative enough to support broader claims about coherence illusions in language models.
What would settle it
A new set of illusion texts or models in which surprisal at the critical word does not drop when a matching distractor is present would falsify the claim that these illusions occur in Dutch LLMs.
Figures




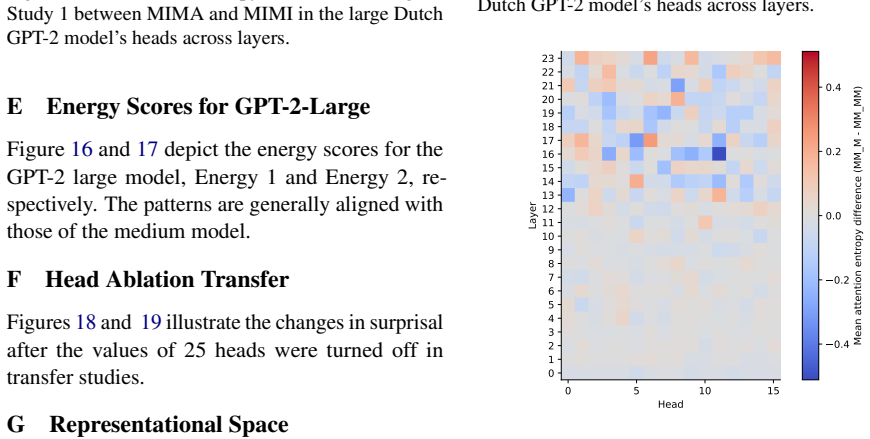
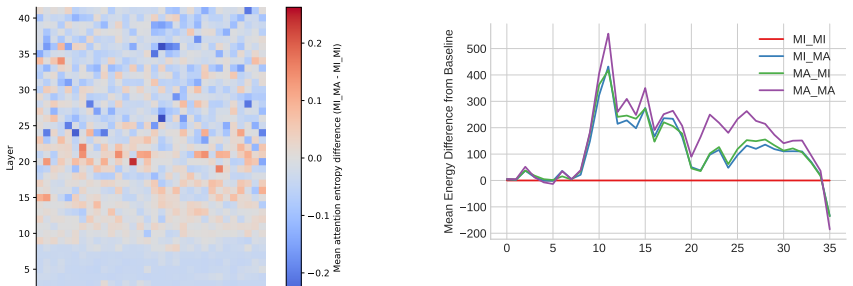
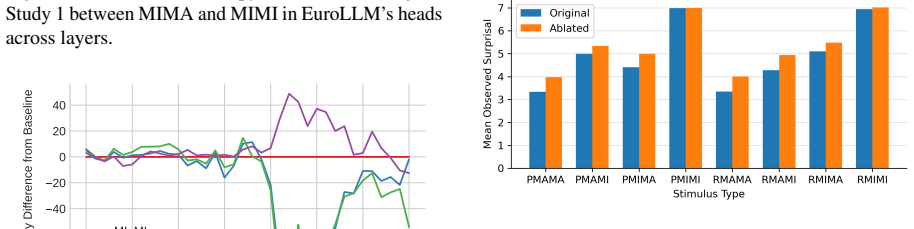
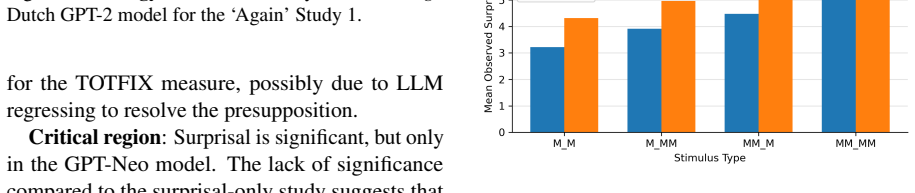
read the original abstract
Psycholinguistics studies show that human readers fall for coherence illusions: an incoherent discourse can seem coherent simply because a distractor matches what comes next. We investigate whether Dutch language models (6 monolingual and 4 multilingual) show the same behavior on texts that link back to earlier context with words such as 'again' and 'too'. First, we find that surprisal at the critical word tracks human acceptability judgments and eye-tracking data. Models are more surprised by incoherent continuations, but a matching distractor in the prior context reduces this surprisal. Second, attention entropy at the critical position identifies heads that behave differently under coherence vs. incoherence. We find that ablating these heads shows transfer effects across experiments, suggesting a shared mechanism. Third, we introduce energy from the associative-memory literature as a metric to quantify discourse coherence. Taken together, our results show that coherence illusions arise in Dutch LLMs, with entropy and energy exposing mechanisms that operate across settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Dutch LLMs (6 monolingual + 4 multilingual) exhibit human-like coherence illusions on discourses linked by words such as 'again' and 'too': surprisal at critical words tracks human acceptability judgments and eye-tracking data, with distractors reducing surprisal; attention entropy identifies heads whose ablation produces transfer effects across experiments; and a new energy metric from associative-memory literature quantifies discourse coherence. The results are presented as evidence that coherence illusions arise in Dutch LLMs with mechanisms operating across settings.
Significance. If the central results hold after addressing scope, the work would be significant for bridging psycholinguistics and mechanistic interpretability: it supplies concrete evidence that LLMs replicate a specific human discourse illusion, demonstrates ablation-based transfer as a test for shared mechanisms, and introduces the energy metric as a potentially reusable tool for quantifying coherence. These elements, if rigorously supported, would strengthen claims about cross-linguistic and cross-model applicability of illusion effects.
major comments (3)
- [Methods (model and stimulus selection)] Model and text selection (Methods section): The generalization that coherence illusions 'arise in Dutch LLMs' and that 'entropy and energy expos[e] mechanisms that operate across settings' is load-bearing on the 10 chosen models and the 'again'/'too' items being representative. The manuscript must supply explicit selection criteria, training-corpus diversity metrics, and text-sampling rationale; absent these, the evidence supports the phenomena only for this narrow set rather than Dutch LLMs in general.
- [Results (surprisal analysis)] Surprisal results (Results section): The claim that surprisal 'tracks human acceptability judgments and eye-tracking data' and is reduced by distractors requires reported item counts, statistical tests (e.g., mixed-effects models), effect sizes, and error bars. Without these, it is impossible to assess whether the distractor effect is reliable or item-specific, directly undermining the first main finding.
- [Results (attention entropy and ablation)] Ablation transfer (Results section on attention entropy): The transfer effects across experiments are presented as evidence for a shared mechanism, yet the manuscript must demonstrate that the identified heads are not overfit to the specific lexical triggers or model subset; a control ablation on non-entropy-selected heads or a cross-validation across model families would be needed to secure this inference.
minor comments (2)
- [Abstract] The abstract would be clearer if it briefly stated the number of experimental items, the precise definition of the energy metric, and the statistical approach used for the human-model comparisons.
- [Methods (energy metric)] Notation for the energy metric should be introduced with an explicit equation in the main text rather than only by reference to the associative-memory literature.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important areas for strengthening the generalizability and statistical support of our claims. We respond to each major comment below and commit to revisions where the manuscript currently falls short of the requested standards.
read point-by-point responses
-
Referee: Model and text selection (Methods section): The generalization that coherence illusions 'arise in Dutch LLMs' and that 'entropy and energy expos[e] mechanisms that operate across settings' is load-bearing on the 10 chosen models and the 'again'/'too' items being representative. The manuscript must supply explicit selection criteria, training-corpus diversity metrics, and text-sampling rationale; absent these, the evidence supports the phenomena only for this narrow set rather than Dutch LLMs in general.
Authors: We agree that the Methods section requires explicit documentation to support the stated scope. In the revised manuscript we will add a dedicated subsection on model and stimulus selection. This will report the criteria applied (availability of Dutch monolingual models, parameter-size range, and multilingual comparators), available training-corpus statistics, and the rationale for the 'again'/'too' items drawn from prior psycholinguistic work on coherence illusions. These additions will make the limits of generalization transparent. revision: yes
-
Referee: Surprisal results (Results section): The claim that surprisal 'tracks human acceptability judgments and eye-tracking data' and is reduced by distractors requires reported item counts, statistical tests (e.g., mixed-effects models), effect sizes, and error bars. Without these, it is impossible to assess whether the distractor effect is reliable or item-specific, directly undermining the first main finding.
Authors: The referee correctly identifies that the current presentation relies on directional trends without the quantitative statistics needed for rigorous evaluation. We will revise the Results section to report the exact item counts per condition, mixed-effects models testing the distractor effect (with p-values), effect sizes, and error bars on the relevant plots. These additions will allow readers to judge reliability and item-specificity directly. revision: yes
-
Referee: Ablation transfer (Results section on attention entropy): The transfer effects across experiments are presented as evidence for a shared mechanism, yet the manuscript must demonstrate that the identified heads are not overfit to the specific lexical triggers or model subset; a control ablation on non-entropy-selected heads or a cross-validation across model families would be needed to secure this inference.
Authors: We accept that the current ablation results would be strengthened by explicit controls against overfitting. In revision we will add control ablations on heads not selected by the entropy criterion and will report transfer effects broken down by model family. These controls will be included to test the specificity of the identified heads. revision: yes
Circularity Check
No circularity: metrics defined independently of results
full rationale
The paper applies standard surprisal, defines attention entropy at critical positions, and introduces energy from the associative-memory literature as separate metrics. No equations, derivations, or fitted parameters are shown that reduce the target claims about coherence illusions to inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems, and no ansatz or renaming of known results is presented as a derivation. The experimental findings rest on empirical measurements across models and texts rather than definitional equivalence.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aryaman Arora, Dan Jurafsky, and Christopher Potts. 2024. https://doi.org/10.18653/v1/2024.acl-long.785 C ausal G ym: Benchmarking causal interpretability methods on linguistic tasks . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 14638--14663, Bangkok, Thailand. Association for C...
-
[2]
Yonatan Belinkov. 2022. https://doi.org/10.1162/coli_a_00422 Probing classifiers: Promises, shortcomings, and advances . Computational Linguistics, 48(1):207--219
work page internal anchor Pith review doi:10.1162/coli_a_00422 2022
-
[3]
Sid Black, Leo Gao, Phil Wang, Connor Leahy, and Stella Biderman. 2021. https://doi.org/10.5281/zenodo.5297715 GPT-Neo: Large Scale Autoregressive Language Modeling with Mesh-Tensorflow . If you use this software, please cite it using these metadata
-
[4]
Kathryn Bock and Carol A Miller. 1991. https://doi.org/10.1016/0010-0285(91)90003-7 Broken agreement . Cognitive Psychology, 23(1):45--93
-
[5]
Sasha Boguraev, Christopher Potts, and Kyle Mahowald. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.1271 Causal interventions reveal shared structure across E nglish filler -- gap constructions . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 25021--25042, Suzhou, China. Association for Computational L...
-
[6]
Lisa Bylinina, Silvana Abdi, Hylke Brouwer, Martine Elzinga, Shenza Gunput, Sem Huisman, Collin Krooneman, David Poot, Jelmer Top, and Cain Weideman. 2024. https://doi.org/10.57967/hf/3825 Dutch-CoLA (Revision 5a4196c)
-
[7]
John Dang, Shivalika Singh, Daniel D'souza, Arash Ahmadian, Alejandro Salamanca, Madeline Smith, Aidan Peppin, Sungjin Hong, Manoj Govindassamy, Terrence Zhao, Sandra Kublik, Meor Amer, Viraat Aryabumi, Jon Ander Campos, Yi-Chern Tan, Tom Kocmi, Florian Strub, Nathan Grinsztajn, Yannis Flet-Berliac, and 26 others. 2024. https://arxiv.org/abs/2412.04261 Ay...
arXiv 2024
-
[8]
Wietse de Vries and Malvina Nissim. 2021. https://doi.org/10.18653/v1/2021.findings-acl.74 As good as new. how to successfully recycle E nglish GPT -2 to make models for other languages . In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 836--846, Online. Association for Computational Linguistics
-
[9]
Nima Dehmamy, Benjamin Hoover, Bishwajit Saha, Leo Kozachkov, Jean-Jacques Slotine, and Dmitry Krotov. 2026. Nrgpt: An energy-based alternative for gpt. Proceedings of ICLR . arXiv preprint arXiv:2512.16762
Pith/arXiv arXiv 2026
-
[10]
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Nova DasSarma, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, and 6 others. 2021. A mathematical framework for transformer circuits. Transformer C...
2021
-
[11]
Allyson Ettinger, Ahmed Elgohary, and Philip Resnik. 2016. https://doi.org/10.18653/v1/W16-2524 Probing for semantic evidence of composition by means of simple classification tasks . In Proceedings of the 1st Workshop on Evaluating Vector-Space Representations for NLP , pages 134--139, Berlin, Germany. Association for Computational Linguistics
-
[12]
Mario Giulianelli, Jack Harding, Florian Mohnert, Dieuwke Hupkes, and Willem Zuidema. 2018. https://doi.org/10.18653/v1/W18-5426 Under the hood: Using diagnostic classifiers to investigate and improve how language models track agreement information . In Proceedings of the 2018 EMNLP Workshop B lackbox NLP : Analyzing and Interpreting Neural Networks for N...
-
[13]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, and 542 others. 2024. https://arxiv.org/abs/2407.21783 The llama 3...
Pith/arXiv arXiv 2024
-
[14]
John Hale. 2001. https://doi.org/10.3115/1073336.1073357 A probabilistic earley parser as a psycholinguistic model . In Proceedings of the Second Meeting of the North American Chapter of the Association for Computational Linguistics on Language Technologies, NAACL '01, page 1–8, USA. Association for Computational Linguistics
-
[15]
John J Hopfield. 1982. Neural networks and physical systems with emergent collective computational abilities. Proceedings of the national academy of sciences, 79(8):2554--2558
1982
-
[16]
John J Hopfield. 1984. Neurons with graded response have collective computational properties like those of two-state neurons. Proceedings of the national academy of sciences, 81(10):3088--3092
1984
-
[17]
Yibo Jiang, Goutham Rajendran, Pradeep Kumar Ravikumar, and Bryon Aragam. 2024. https://openreview.net/forum?id=WJ04ZX8txM Do LLM s dream of elephants (when told not to)? latent concept association and associative memory in transformers . In The Thirty-eighth Annual Conference on Neural Information Processing Systems
2024
-
[18]
Jaap Jumelet, Leonie Weissweiler, Joakim Nivre, and Arianna Bisazza. 2026. https://doi.org/10.1162/tacl.a.600 M ulti BL i MP 1.0: A massively multilingual benchmark of linguistic minimal pairs . Transactions of the Association for Computational Linguistics, 14:193--216
-
[19]
Li Kloostra, Rick Nouwen, and Jakub Dotlačil. 2026. Coherence illusions and failed binding in discourse processing: interferences in the presupposition resolution of again. Under Review. Journal of XXX, XXX:XXX
2026
-
[20]
Hopfield
Dmitry Krotov and John J. Hopfield. 2016. https://proceedings.neurips.cc/paper/2016/file/eaae339c4d89fc102edd9dbdb6a28915-Paper.pdf Dense associative memory for pattern recognition . In Advances in Neural Information Processing Systems, volume 29. Curran Associates, Inc
2016
-
[21]
Tatsuki Kuribayashi, Yohei Oseki, and Timothy Baldwin. 2024. https://doi.org/10.18653/v1/2024.findings-naacl.129 Psychometric predictive power of large language models . In Findings of the Association for Computational Linguistics: NAACL 2024, pages 1983--2005, Mexico City, Mexico. Association for Computational Linguistics
-
[22]
Tatsuki Kuribayashi, Yohei Oseki, Souhaib Ben Taieb, Kentaro Inui, and Timothy Baldwin. 2025. https://doi.org/10.1162/TACL.a.58 Large language models are human-like internally . Transactions of the Association for Computational Linguistics, 13:1743--1766
-
[23]
Roger Levy. 2008. https://doi.org/10.1016/j.cognition.2007.05.006 Expectation-based syntactic comprehension . Cognition, 106(3):1126--1177
-
[24]
Richard L. Lewis and Shravan Vasishth. 2005. https://doi.org/10.1207/s15516709cog0000\_25 An activation-based model of sentence processing as skilled memory retrieval . Cognitive Science, 29(3):375--419
-
[25]
Tal Linzen, Emmanuel Dupoux, and Yoav Goldberg. 2016. https://doi.org/10.1162/tacl_a_00115 Assessing the ability of LSTM s to learn syntax-sensitive dependencies . Transactions of the Association for Computational Linguistics, 4:521--535
-
[26]
Guerreiro, Ricardo Rei, Amin Farajian, Mateusz Klimaszewski, Duarte M
Pedro Henrique Martins, João Alves, Patrick Fernandes, Nuno M. Guerreiro, Ricardo Rei, Amin Farajian, Mateusz Klimaszewski, Duarte M. Alves, José Pombal, Nicolas Boizard, Manuel Faysse, Pierre Colombo, François Yvon, Barry Haddow, José G. C. de Souza, Alexandra Birch, and André F. T. Martins. 2025 a . https://arxiv.org/abs/2506.04079 Eurollm-9b: Technical...
arXiv 2025
-
[27]
Guerreiro, Ricardo Rei, Duarte M
Pedro Henrique Martins, Patrick Fernandes, João Alves, Nuno M. Guerreiro, Ricardo Rei, Duarte M. Alves, José Pombal, Amin Farajian, Manuel Faysse, Mateusz Klimaszewski, Pierre Colombo, Barry Haddow, José G.C. de Souza , Alexandra Birch, and André F.T. Martins. 2025 b . https://doi.org/10.1016/j.procs.2025.02.260 Eurollm: Multilingual language models for e...
-
[28]
Hosein Mohebbi, Willem Zuidema, Grzegorz Chrupa a, and Afra Alishahi. 2023. https://doi.org/10.18653/v1/2023.eacl-main.245 Quantifying context mixing in transformers . In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, pages 3378--3400, Dubrovnik, Croatia. Association for Computational Linguistics
-
[29]
Jingcheng Niu, Xingdi Yuan, Tong Wang, Hamidreza Saghir, and Amir H. Abdi. 2025. https://doi.org/10.18653/v1/2025.acl-long.791 Llama see, llama do: A mechanistic perspective on contextual entrainment and distraction in LLM s . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 16218--1...
-
[30]
Byung-Doh Oh and William Schuler. 2022. https://doi.org/10.18653/v1/2022.emnlp-main.632 Entropy- and distance-based predictors from GPT -2 attention patterns predict reading times over and above GPT -2 surprisal . In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 9324--9334, Abu Dhabi, United Arab Emirates. A...
-
[31]
Byung-Doh Oh and William Schuler. 2023. https://doi.org/10.1162/tacl_a_00548 Why does surprisal from larger transformer-based language models provide a poorer fit to human reading times? Transactions of the Association for Computational Linguistics, 11:336--350
-
[32]
Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Scott Johnston, Andy Jones, Jackson Kernion, Liane Lovitt, and 7 others. 2022. In-context learning and induction heads. Transformer Circuits T...
2022
-
[33]
Wagers, and Ellen F
Colin Phillips, Matthew W. Wagers, and Ellen F. Lau. 2011. https://api.semanticscholar.org/CorpusID:40053259 5: Grammatical illusions and selective fallibility in real-time language comprehension
2011
-
[34]
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, and 1 others. 2019. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9
2019
-
[35]
a fl, Johannes Lehner, Philipp Seidl, Michael Widrich, Lukas Gruber, Markus Holzleitner, Thomas Adler, David Kreil, Michael K Kopp, G \
Hubert Ramsauer, Bernhard Sch \"a fl, Johannes Lehner, Philipp Seidl, Michael Widrich, Lukas Gruber, Markus Holzleitner, Thomas Adler, David Kreil, Michael K Kopp, G \"u nter Klambauer, Johannes Brandstetter, and Sepp Hochreiter. 2021. https://openreview.net/forum?id=tL89RnzIiCd Hopfield networks is all you need . In International Conference on Learning R...
2021
-
[36]
Soo Hyun Ryu and Richard Lewis. 2021. https://doi.org/10.18653/v1/2021.cmcl-1.6 Accounting for agreement phenomena in sentence comprehension with transformer language models: Effects of similarity-based interference on surprisal and attention . In Proceedings of the Workshop on Cognitive Modeling and Computational Linguistics, pages 61--71, Online. Associ...
-
[37]
Soo Hyun Ryu and Richard L. Lewis. 2025. https://doi.org/10.1016/j.jml.2025.104670 Memory for prediction: A transformer-based theory of sentence processing . Journal of Memory and Language, 145:104670
-
[38]
Tijn Schmitz, Rick Nouwen, and Jakub Dotlačil. 2025. https://doi.org/10.1016/j.jml.2025.104637 Memory retrieval in discourse: Illusions of coherence during presupposition resolution . Journal of Memory and Language, 143:104637
-
[39]
Cory Shain, Clara Meister, Tiago Pimentel, Ryan Cotterell, and Roger Levy. 2024. https://doi.org/10.1073/pnas.2307876121 Large-scale evidence for logarithmic effects of word predictability on reading time . Proceedings of the National Academy of Sciences, 121(10):e2307876121
-
[40]
C. E. Shannon. 1948. https://doi.org/10.1002/j.1538-7305.1948.tb01338.x A mathematical theory of communication . Bell System Technical Journal, 27(3):379--423
-
[41]
Freda Shi, Xinyun Chen, Kanishka Misra, Nathan Scales, David Dohan, Ed Chi, Nathanael Sch\" a rli, and Denny Zhou. 2023. Large language models can be easily distracted by irrelevant context. In Proceedings of the 40th International Conference on Machine Learning, ICML'23. JMLR.org
2023
-
[42]
Michelle Suijkerbuijk, Zo \"e Prins, Marianne de Heer Kloots, Willem Zuidema, and Stefan L. Frank. 2025. https://doi.org/10.1162/coli_a_00559 BL i MP - NL : A corpus of D utch minimal pairs and acceptability judgments for language model evaluation . Computational Linguistics, 51(4):1267--1301
-
[43]
Eleftheria Tsipidi, Samuel Kiegeland, Francesco Ignazio Re, Tianyang Xu, Mario Giulianelli, Karolina Stanczak, and Ryan Cotterell. 2026. https://arxiv.org/abs/2604.18712 Probing for reading times . Preprint, arXiv:2604.18712
Pith/arXiv arXiv 2026
-
[44]
Julie A Van Dyke and Richard L Lewis. 2003. https://doi.org/10.1016/S0749-596X(03)00081-0 Distinguishing effects of structure and decay on attachment and repair: A cue-based parsing account of recovery from misanalyzed ambiguities . Journal of Memory and Language, 49(3):285--316
-
[45]
Bram Vanroy. 2023. Language resources for Dutch large language modelling. arXiv preprint arXiv:2312.12852
arXiv 2023
-
[46]
Bram Vanroy. 2024. https://arxiv.org/abs/2412.04092 Geitje 7b ultra: A conversational model for dutch . Preprint, arXiv:2412.04092
arXiv 2024
-
[47]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, ukasz Kaiser, and Illia Polosukhin. 2017. https://proceedings.neurips.cc/paper_files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf Attention is all you need . In Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc
2017
-
[48]
Titus von der Malsburg and Sebastian Pad \'o . 2026. Diverging transformer predictions for human sentence processing: A comprehensive analysis of agreement attraction effects. arXiv preprint arXiv:2603.16574
arXiv 2026
-
[49]
Kevin Ro Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, and Jacob Steinhardt. 2023. https://openreview.net/forum?id=NpsVSN6o4ul Interpretability in the wild: a circuit for indirect object identification in GPT -2 small . In The Eleventh International Conference on Learning Representations
2023
-
[50]
Ethan G Wilcox, Tiago Pimentel, Clara Meister, Ryan Cotterell, and Roger P Levy. 2023. Testing the predictions of surprisal theory in 11 languages. Transactions of the Association for Computational Linguistics, 11:1451--1470
2023
-
[51]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, and 41 others. 2025. https://arxiv.org/abs/2505.09388 Qwen3 technical report . Preprint, arXiv:2505.09388
Pith/arXiv arXiv 2025
-
[52]
Ori Yoran, Tomer Wolfson, Ori Ram, and Jonathan Berant. 2024. https://openreview.net/forum?id=ZS4m74kZpH Making retrieval-augmented language models robust to irrelevant context . In The Twelfth International Conference on Learning Representations
2024
-
[53]
Fabio Massimo Zanzotto, Elena Sofia Ruzzetti, Giancarlo A. Xompero, Leonardo Ranaldi, Davide Venditti, Federico Ranaldi, Cristina Giannone, Andrea Favalli, and Raniero Romagnoli. 2025. https://doi.org/10.18653/v1/2025.findings-acl.785 Position paper: M e M o: Towards language models with associative memory mechanisms . In Findings of the Association for C...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.