Reading Order Inference for Complex Document Layouts
Pith reviewed 2026-07-02 12:48 UTC · model grok-4.3
The pith
A training-free graph method using language model signals recovers reading order in complex wrap-around layouts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
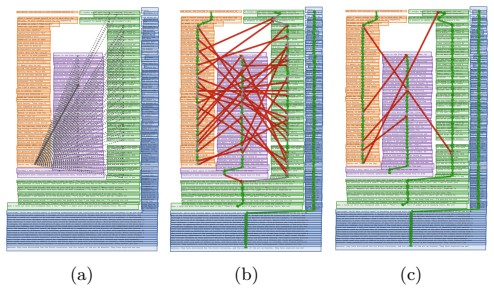
Each OCR text line is a node in a directed candidate-transition graph whose edges receive scores from a weighted additive ensemble of causal language model conditional likelihood and BERT next-sentence prediction. The global reading order is recovered as a degree-constrained directed path cover by applying a max-regret inference rule that prioritizes high-opportunity-cost commitments to prevent cascading greedy failures. This framework is shown to recover 95 percent of ground-truth successor edges on synthetic wrap-around Glossa layouts and 88 percent macro edge accuracy on multi-column pages, substantially above the performance of XY-cut and LayoutReader baselines on the same inputs.
What carries the argument
The max-regret inference rule on the degree-constrained directed path cover of the transition graph scored by the LM ensemble.
If this is right
- Recovers 95% of ground-truth successor edges on wrap-around Glossa layouts compared to 50% for XY-cut.
- Achieves 88% macro edge accuracy on multi-column OmniDocBench subset versus 75% for XY-cut.
- Maintains performance with less than 1 percentage point change under horizontal and vertical reflections.
- Avoids cascading edge-theft failures that plague greedy edge selection.
Where Pith is reading between the lines
- The approach could be applied to other document types with interleaved text streams, such as annotated scientific papers.
- Combining this with visual features might address cases where text alone is ambiguous.
- The method's reliance on pre-trained models suggests it could work across languages if the models are multilingual.
Load-bearing premise
The weighted additive ensemble of causal language model conditional likelihood and BERT next-sentence prediction provides reliable edge scores for reading order without task-specific training on the target layouts.
What would settle it
A test on additional wrap-around layout pages where the method achieves under 70% successor edge recovery while XY-cut exceeds 60% would indicate the claimed advantage does not hold.
Figures

read the original abstract
Reading order inference remains a critical bottleneck in the digitization of complex historical manuscripts, where pages contain multiple spatially interleaved reading streams, the canonical example being the Glossa Ordinaria layout, in which a central text is surrounded by commentaries that wrap around it in non-rectangular, non-convex regions. We present a training-free, graph-based framework: each OCR text line becomes a node in a directed candidate-transition graph, edges are scored by a weighted additive ensemble of two lightweight language-model signals (causal language model conditional likelihood and BERT next-sentence prediction, NSP; a third sentence-embedding signal was evaluated but did not improve reading order), and the global reading order is recovered as a degree-constrained directed path cover. To avoid the cascading "edge-theft" failures of greedy edge selection, we propose a max-regret inference rule that prioritizes commitments with high opportunity cost. We evaluate on synthetic Glossa Ordinaria grid layouts, on 23 ALTO page geometries (10 historical source pages plus mirrored and flipped variants), and on a 140-page multi-column English subset of OmniDocBench, comparing our method against the canonical recursive XY-cut (PaddleOCR PP-StructureV3) and two LayoutReader variants (layout-only and text+layout) on identical inputs. On wrap-around Glossa layouts our method recovers 95% of ground-truth successor edges on average vs. XY-cut's 50%; on the OmniDocBench multi-column subset it reaches 88% macro edge accuracy versus XY-cut's 75% and LayoutReader's 25%. The LayoutReader baselines transfer poorly due to a word-level vs. line-level granularity mismatch. We additionally verify mirror-invariance under horizontal and vertical page reflections: Our method changes by less than 1 percentage point, classical XY-cut by 2 points, and LayoutReader-T by up to 8 points.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a training-free graph-based framework for reading order inference in complex document layouts, particularly wrap-around Glossa Ordinaria pages. Nodes are OCR text lines, edges scored by weighted ensemble of causal LM conditional likelihood and BERT NSP, and reading order recovered as degree-constrained directed path cover using max-regret inference. Evaluations on synthetic grids, 23 ALTO pages (including 10 historical), and OmniDocBench multi-column subset show superior performance over XY-cut and LayoutReader baselines, with 95% successor recovery on Glossa vs 50%, and 88% macro edge accuracy on OmniDocBench vs 75% and 25%. Mirror-invariance is also verified.
Significance. If the results hold, this work could significantly advance the digitization of historical manuscripts with interleaved layouts by providing a method that does not require task-specific training. The explicit comparison on historical data and robustness checks are strengths. However, the reliance on pre-trained LMs for non-English text is a key assumption that needs validation to fully assess impact.
major comments (2)
- [Abstract] Abstract: The central claim of 95% average successor edge recovery on the 10 historical Glossa pages depends on the weighted additive ensemble of causal-LM conditional likelihood and BERT NSP producing useful edge scores for medieval Latin text. No ablation removing the LM terms, no correlation analysis between LM scores and ground-truth edges, and no language-specific validation on these pages are reported, leaving open whether the gains derive from the LM signals or from spatial candidate pruning plus the max-regret rule.
- [Evaluation] Evaluation section: The training-free claim on Glossa layouts rests on off-the-shelf English-centric models generalizing to Latin historical manuscripts; the manuscript should supply score-distribution statistics or an LM-ablation result on the historical subset to substantiate that the ensemble contributes signal rather than noise.
minor comments (1)
- [Abstract] Abstract: The sentence noting that the third sentence-embedding signal "did not improve reading order" is terse; a brief quantitative comparison or reason would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The points raised correctly identify the absence of explicit validation for the LM ensemble on the historical Latin data. We address each comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of 95% average successor edge recovery on the 10 historical Glossa pages depends on the weighted additive ensemble of causal-LM conditional likelihood and BERT NSP producing useful edge scores for medieval Latin text. No ablation removing the LM terms, no correlation analysis between LM scores and ground-truth edges, and no language-specific validation on these pages are reported, leaving open whether the gains derive from the LM signals or from spatial candidate pruning plus the max-regret rule.
Authors: We agree that the manuscript lacks an ablation removing the LM terms and a correlation analysis on the Glossa pages. In revision we will add both: an ablation on the 10 historical pages comparing the full ensemble against spatial pruning plus max-regret alone, plus Pearson correlations and score-distribution statistics between LM scores and ground-truth successor edges. These additions will directly test whether the LM signals contribute beyond the graph components. revision: yes
-
Referee: [Evaluation] Evaluation section: The training-free claim on Glossa layouts rests on off-the-shelf English-centric models generalizing to Latin historical manuscripts; the manuscript should supply score-distribution statistics or an LM-ablation result on the historical subset to substantiate that the ensemble contributes signal rather than noise.
Authors: We concur that explicit LM-ablation results and score statistics on the historical subset are required to support the generalization claim. The revised evaluation section will include the ablation and score-distribution statistics on the 10 Glossa pages as described in the response to the abstract comment. This will substantiate that the ensemble supplies signal rather than noise for the medieval Latin text. revision: yes
Circularity Check
No circularity; derivation uses external pre-trained LMs and independent baselines.
full rationale
The paper's core method constructs a candidate graph from OCR lines, scores edges via off-the-shelf causal LM likelihood and BERT NSP (no task-specific training or fitting on target data), and recovers order via a max-regret path-cover rule. All performance numbers are obtained by direct comparison against published external baselines (XY-cut, LayoutReader) on held-out datasets (Glossa pages, OmniDocBench). No equation reduces a claimed prediction to a fitted parameter by construction, no load-bearing premise rests on self-citation, and the uniqueness of the inference rule is justified by its stated avoidance of greedy edge-theft rather than by prior author theorems. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- ensemble weights
axioms (1)
- domain assumption Pre-trained language models supply useful signals for document reading order without domain adaptation.
Reference graph
Works this paper leans on
-
[1]
Computational Linguistics34(1), 1–34 (2008).https://doi.org/10.1162/coli
Barzilay, R., Lapata, M.: Modeling local coherence: An entity-based approach. Computational Linguistics34(1), 1–34 (2008).https://doi.org/10.1162/coli. 2008.34.1.1
-
[2]
Clausner, C., Pletschacher, S., Antonacopoulos, A.: The significance of reading order in document recognition and its evaluation. In: Proc. 12th Int. Conf. on Document Analysis and Recognition (ICDAR). pp. 688–692 (2013).https://doi. org/10.1109/ICDAR.2013.141
-
[3]
Devlin, J., Chang, M.W., Lee, K., Toutanova, K.: BERT: Pre-training of deep bidirectional transformers for language understanding. In: Proc. NAACL-HLT. pp. 4171–4186. ACL (2019).https://doi.org/10.18653/v1/N19-1423
-
[4]
Li, J., Hovy, E.: A model of coherence based on distributed sentence representation. In: Proc. EMNLP. pp. 2039–2048. ACL (2014).https://doi.org/10.3115/v1/ D14-1218
work page doi:10.3115/v1/ 2039
-
[5]
Library of Congress: ALTO: Technical metadata for layout and text objects.https: //www.loc.gov/standards/alto/(2022)
2022
-
[6]
Meunier, J.L.: Optimized XY-cut for determining a page reading order. In: Proc. 8th Int. Conf. on Document Analysis and Recognition (ICDAR). pp. 347–351 (2005).https://doi.org/10.1109/ICDAR.2005.182
-
[7]
In: Proc
Nagy, G., Seth, S.C.: Hierarchical representation of optically scanned documents. In: Proc. 7th Int. Conf. on Pattern Recognition (ICPR). vol. 1, pp. 347–349 (1984)
1984
-
[8]
IEEE TPAMI 15(11), 1162–1173 (1993).https://doi.org/10.1109/34.244677
O’Gorman, L.: The document spectrum for page layout analysis. IEEE TPAMI 15(11), 1162–1173 (1993).https://doi.org/10.1109/34.244677
-
[9]
In: Proc
Ouyang, L., Qu, Y., Zhou, H., Zhu, J., et al.: OmniDocBench: Benchmarking diverse pdf document parsing with comprehensive annotations. In: Proc. CVPR (2025)
2025
-
[10]
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., Sutskever, I.: Language models are unsupervised multitask learners. Tech. rep., OpenAI (2019)
2019
-
[11]
Reimers, N., Gurevych, I.: Sentence-BERT: Sentence embeddings using Siamese BERT-networks. In: Proc. EMNLP-IJCNLP. pp. 3982–3992. ACL (2019).https: //doi.org/10.18653/v1/D19-1410
-
[12]
Rozenberg, M., Munk, M., Kainan, A.: A Talmud page as a metaphor of a scientific text. Int. J. Qualitative Methods5(4), 30–44 (2006).https://doi.org/10.1177/ 160940690600500403
2006
-
[13]
In: Proc
Wang, R., Fujii, Y., Bissacco, A.: Text reading order in uncontrolled condi- tions by sparse graph segmentation. In: Proc. Int. Conf. on Document Analysis and Recognition (ICDAR). pp. 3–21. Springer (2023).https://doi.org/10.1007/ 978-3-031-41731-3_1
2023
-
[14]
Wang, Z., Xu, Y., Cui, L., Shang, J., Wei, F.: LayoutReader: Pre-training of text and layout for reading order detection. In: Proc. EMNLP. pp. 4735–4744. ACL (2021).https://doi.org/10.18653/v1/2021.emnlp-main.389
-
[15]
Xu, Y., Li, M., Cui, L., Huang, S., Wei, F., Zhou, M.: LayoutLM: Pre-training of text and layout for document image understanding. In: Proc. 26th ACM SIGKDD. pp. 1192–1200 (2020).https://doi.org/10.1145/3394486.3403172 17
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.