PrismQuant: Rate-Distortion-Optimal Vector Quantization for Gaussian-Mixture Sources
Pith reviewed 2026-05-19 15:16 UTC · model grok-4.3
The pith
A single global reverse-waterfilling level governs the rate-distortion function for Gaussian-mixture sources.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The genie-aided conditional rate-distortion function of a Gaussian-mixture source is governed by a single global reverse-waterfilling level shared across all components and all eigenmodes. The paper constructs PrismQuant that transmits the component label losslessly at cost H(C)/n per dimension and then applies the component-matched Karhunen-Loeve transform followed by scalar quantization at levels set by the common water-filling threshold, achieving the conditional rate plus the label cost with a vanishing asymptotic gap.
What carries the argument
The single global reverse-waterfilling level shared across every mixture component and every eigenmode within those components.
Load-bearing premise
The source must be exactly a finite Gaussian mixture and the active component must be known perfectly so its label can be transmitted at exactly its entropy cost.
What would settle it
For a known two-component Gaussian mixture, compute the minimal rate required to achieve a target distortion and check whether it equals the shared reverse-waterfilling conditional rate plus the per-dimension component entropy.
Figures



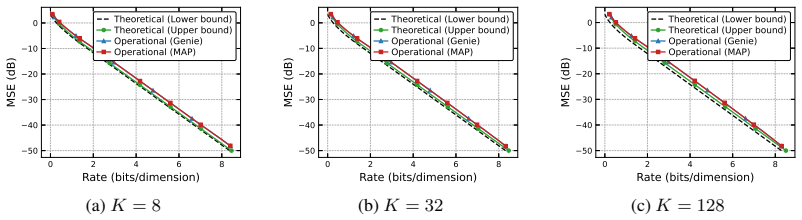




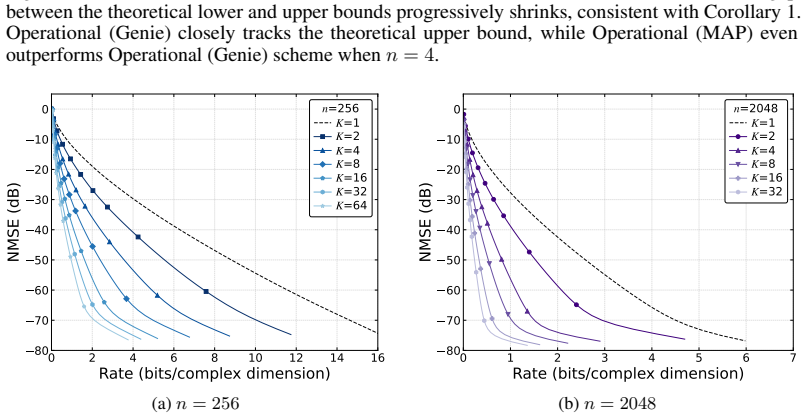
read the original abstract
For a Gaussian source under mean-squared error (MSE), classical transform coding is rate--distortion (RD) optimal: the Karhunen--Loeve transform (KLT) diagonalizes the covariance, reverse waterfilling allocates the bits, and scalar quantization closes the loop. This elegant story breaks down for multimodal sources, where no single covariance can capture heterogeneous local geometries, and the RD function loses its closed form. We revisit this problem through Gaussian-mixture sources and develop a constructive RD theory for them. Our key finding is that the mixture structure incurs only a component label cost. Conditioned on the active mixture component, each branch is Gaussian; the challenge is allocating bits across heterogeneous branches. We prove that the genie-aided conditional RD function is governed by a single global reverse-waterfilling level shared across all components and eigenmodes. Building on this result, we introduce PrismQuant, which transmits the component label losslessly and encodes the residual using the component-matched KLT, followed by scalar quantization, achieving a rate of H(C)/n bits per source dimension of the converse, with a vanishing asymptotic gap. We further develop a practical implementation based on EM-driven Gaussian-mixture learning, component-adaptive KLTs, and entropy-constrained scalar quantization (ECSQ). Experiments on synthetic Gaussian mixtures show that PrismQuant closely approaches the theoretical RD bound, while experiments on real-world channel-state-information (CSI) data demonstrate competitive or superior performance compared with transformer-based learned codecs at more than one order of magnitude smaller model size.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a constructive rate-distortion theory for finite Gaussian-mixture sources under MSE. It proves that the genie-aided conditional RD function is governed by a single global reverse-waterfilling level shared across all mixture components and their eigenmodes. PrismQuant is introduced to transmit the component label losslessly at rate H(C)/n per dimension and then apply the component-matched KLT followed by scalar quantization, achieving a rate within H(C)/n of the converse with a vanishing asymptotic gap. A practical implementation learns the GMM via EM, uses component-adaptive KLTs, and employs entropy-constrained scalar quantization; experiments on synthetic GMMs approach the theoretical bound while CSI data experiments show competitive performance against transformer codecs at far smaller model size.
Significance. If the central result holds, the work cleanly extends classical transform coding to multimodal sources by isolating the mixture overhead to the label entropy term and supplying an explicit, low-complexity construction that approaches the information-theoretic limit. The practical codec's small footprint and strong CSI results indicate immediate relevance to quantization and compression in wireless and sensing applications.
major comments (3)
- [§3] §3 (Global reverse-waterfilling derivation): the proof equalizes the Lagrange multiplier across eigenmodes of every component under the assumption that a genie reveals the active component C before quantization; the manuscript must clarify whether and how this equalization survives when the encoder must infer C from X, since any positive misclassification probability applies the wrong covariance and quantizer.
- [§4] §4 (PrismQuant construction and gap analysis): the claim of a vanishing asymptotic gap to the converse rests on lossless transmission of the true component label; when mixture components overlap, the encoder's inference of C is imperfect and the resulting excess distortion from mismatched KLT/ECSQ may not vanish, requiring either a bound on the misclassification contribution or an explicit statement that the gap analysis assumes perfect identification.
- [Experimental section] Experimental section (synthetic GMM results): the reported approach to the theoretical bound is promising, yet the absence of error bars, number of Monte-Carlo trials, or variance across random seeds leaves open whether the observed gap is statistically consistent with vanishing or merely small for the tested dimensions.
minor comments (2)
- [Notation] Notation for the per-dimension label cost H(C)/n should be introduced once and used consistently; the abstract and main text occasionally switch between “bits per source dimension” and “per dimension” without explicit definition of n.
- [Figures] Figure captions for the CSI experiments should state the exact model sizes of the transformer baselines and the number of parameters in PrismQuant for direct comparison.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review of our manuscript. The comments highlight important points regarding the distinction between genie-aided and practical settings, as well as the need for more rigorous statistical reporting in experiments. We address each major comment below and outline the revisions we intend to make in the next version of the paper.
read point-by-point responses
-
Referee: [§3] §3 (Global reverse-waterfilling derivation): the proof equalizes the Lagrange multiplier across eigenmodes of every component under the assumption that a genie reveals the active component C before quantization; the manuscript must clarify whether and how this equalization survives when the encoder must infer C from X, since any positive misclassification probability applies the wrong covariance and quantizer.
Authors: The analysis in §3 derives the conditional rate-distortion function under the genie-aided assumption that the active component C is known. The equalization of the Lagrange multiplier across all eigenmodes and components follows from this conditional setting. We will revise the manuscript to explicitly clarify this assumption and explain that PrismQuant uses an estimate of C, with the theoretical bound holding in the genie-aided case. The practical performance is evaluated separately in the experiments. revision: yes
-
Referee: [§4] §4 (PrismQuant construction and gap analysis): the claim of a vanishing asymptotic gap to the converse rests on lossless transmission of the true component label; when mixture components overlap, the encoder's inference of C is imperfect and the resulting excess distortion from mismatched KLT/ECSQ may not vanish, requiring either a bound on the misclassification contribution or an explicit statement that the gap analysis assumes perfect identification.
Authors: We agree that the vanishing gap analysis in §4 is predicated on the lossless transmission of the true component label, which corresponds to the H(C)/n rate overhead in the theoretical construction. When components overlap significantly, perfect inference is not always possible, and mismatched quantization can introduce additional distortion. We will add an explicit statement in the revised manuscript clarifying that the gap analysis assumes perfect component identification (as in the genie-aided bound), and note that for the practical implementation, the performance approaches the bound when the mixture components are sufficiently separated or when the classification accuracy is high. A full bound on the misclassification term is left for future work as it would require additional assumptions on the component separation. revision: partial
-
Referee: Experimental section (synthetic GMM results): the reported approach to the theoretical bound is promising, yet the absence of error bars, number of Monte-Carlo trials, or variance across random seeds leaves open whether the observed gap is statistically consistent with vanishing or merely small for the tested dimensions.
Authors: We appreciate this observation. To address it, we will rerun the synthetic GMM experiments with multiple Monte-Carlo trials (specifically, 20 independent trials with different random seeds for initialization and data generation) and include error bars representing the standard deviation in the revised manuscript. This will confirm that the gaps are small and consistent with the expected vanishing behavior as dimension increases. revision: yes
Circularity Check
No significant circularity; derivation uses standard conditional Gaussian RD theory
full rationale
The paper's central result derives the single global reverse-waterfilling level for the genie-aided conditional RD function directly from classical Gaussian rate-distortion theory applied separately to each mixture component after conditioning on the active label. The PrismQuant construction then explicitly transmits the component label losslessly at cost H(C)/n and applies the matched KLT plus scalar quantization to the residual; this is a constructive scheme whose rate expression follows from the preceding independent derivation rather than redefining or fitting the target quantity to itself. No step reduces the claimed vanishing asymptotic gap to a fitted parameter, self-citation chain, or ansatz smuggled from prior work by the same authors. The practical EM-based implementation is presented separately from the theoretical converse and does not alter the first-principles status of the RD proof.
Axiom & Free-Parameter Ledger
free parameters (1)
- number of mixture components
axioms (2)
- domain assumption The source distribution is exactly a finite Gaussian mixture model
- standard math Standard reverse waterfilling and KLT are RD-optimal for each conditional Gaussian component
Reference graph
Works this paper leans on
-
[1]
Claude E. Shannon. Coding theorems for a discrete source with a fidelity criterion.IRE National Convention Record, 7(4):142–163, 1959
work page 1959
-
[2]
Prentice-Hall, Englewood Cliffs, NJ, 1971
Toby Berger.Rate distortion theory: A mathematical basis for data compression. Prentice-Hall, Englewood Cliffs, NJ, 1971
work page 1971
-
[3]
Thomas M. Cover and Joy A. Thomas.Elements of information theory. Wiley–Interscience, New York, NY , 2nd edition, 2006
work page 2006
-
[4]
Vivek K. Goyal. Theoretical foundations of transform coding.IEEE Signal Procesing Magazine, 18(5): 9–21, 2001
work page 2001
-
[5]
Bishop.Pattern recognition and machine learning
Christopher M. Bishop.Pattern recognition and machine learning. Springer, New York, NY , 2006
work page 2006
-
[6]
T. L. Marzetta. Noncooperative cellular wireless with unlimited numbers of base station antennas.IEEE Transactions on Wireless Communications, 9(11):3590–3600, 2010
work page 2010
-
[7]
D. J. Love, R. W. Heath, Jr., V . K. N. Lau, D. Gesbert, B. D. Rao, and M. Andrews. An overview of limited feedback in wireless communication systems.IEEE Journal on Selected Areas in Communications, 26(8): 1341–1365, 2008
work page 2008
-
[8]
R. W. Heath, Jr. and A. Lozano.Foundations of MIMO Communication. Cambridge Univ. Press, 2016
work page 2016
-
[9]
Molisch, and Pierre De Doncker
Lingfeng Liu, Claude Oestges, Juho Poutanen, Francois Quitin, Katsuyuki Haneda, Pekka Vainikainen, Fredrik Tufvesson, Andreas F. Molisch, and Pierre De Doncker. The COST 2100 MIMO channel model. IEEE Wireless Communications, 19(6):92–99, 2012
work page 2012
- [10]
-
[11]
B. Park, H. Do, and N. Lee. Transformer-based nonlinear transform coding for multi-rate CSI compression in MIMO-OFDM systems. InProceedings of IEEE International Conference on Communications (ICC), 2025
work page 2025
-
[12]
On the entropy of general mixture distributions, 2026
Namyoon Lee. On the entropy of general mixture distributions, 2026. arXiv:2602.15303
-
[13]
M. Effros and P. A. Chou. Weighted universal transform coding: Universal image compression with the Karhunen–Loève transform. InProceedings of IEEE International Conference on Image Processing (ICIP), 1995
work page 1995
-
[14]
DeepMIMO: A Generic Deep Learning Dataset for Millimeter Wave and Massive MIMO Applications
Ahmed Alkhateeb. DeepMIMO: A generic deep learning dataset for millimeter wave and massive MIMO applications, 2019. arXiv:1902.06435
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[15]
Robert M. Gray. Conditional rate–distortion theory. Technical report, Stanford Electronics Laboratories, Stanford University, 1972
work page 1972
-
[16]
A. D. Wyner and J. Ziv. The rate–distortion function for source coding with side information at the decoder. IEEE Transactions on Information Theory, 22(1):1–10, 1976
work page 1976
-
[17]
C. Heegard and T. Berger. Rate distortion when side information may be absent.IEEE Transactions on Information Theory, 31(6):727–734, 1985
work page 1985
-
[18]
E. A. Riskin and R. M. Gray. A greedy tree growing algorithm for the design of variable rate vector quantizers.IEEE Transactions on Signal Processing, 39(11):2500–2507, 1991
work page 1991
- [19]
- [20]
-
[21]
P. Hedelin and J. Skoglund. Vector quantization based on Gaussian mixture models.IEEE Transactions on Speech and Audio Processing, 8(4):385–401, 2000
work page 2000
-
[22]
J. Han, A. Saxena, and K. Rose. Towards jointly optimal spatial prediction and adaptive transform in video/image coding. InProc. IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP), pages 726–729, Mar. 2010. 11
work page 2010
-
[23]
J. Han, A. Saxena, V . Melkote, and K. Rose. Jointly optimized spatial prediction and block transform for video and image coding.IEEE Trans. Image Process., 21(4):1874–1884, Apr. 2012
work page 2012
-
[24]
A. Saxena and F. C. Fernandes. DCT/DST-based transform coding for intra prediction in image/video coding.IEEE Trans. Image Process., 22(10):3974–3981, Oct. 2013
work page 2013
-
[25]
X. Zhao, J. Chen, M. Karczewicz, A. Said, and V . Seregin. Enhanced multiple transform for video coding. InProc. Data Compression Conf. (DCC), pages 73–82, Mar. 2016
work page 2016
-
[26]
B. Bross, Y .-K. Wang, Y . Ye, S. Liu, J. Chen, G. J. Sullivan, and J.-R. Ohm. Overview of the Versatile Video Coding (VVC) standard and its applications.IEEE Trans. Circuits Syst. Video Technol., 31(10): 3736–3764, Oct. 2021
work page 2021
-
[27]
Variational image compression with a scale hyperprior
Johannes Ballé, David Minnen, Saurabh Singh, Sung Jin Hwang, and Nick Johnston. Variational image compression with a scale hyperprior. InProceedings of International Conference on Learning Representa- tions (ICLR), 2018
work page 2018
-
[28]
Learned image compression with dis- cretized gaussian mixture likelihoods and attention modules
Zhengxue Cheng, Heming Sun, Masaru Takeuchi, and Jiro Katto. Learned image compression with dis- cretized gaussian mixture likelihoods and attention modules. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020
work page 2020
-
[29]
Eric Lei, Hamed Hassani, and Shirin Saeedi Bidokhti. Neural estimation of the rate-distortion function with applications to operational source coding.IEEE Journal on Selected Areas in Information Theory, 3 (4):674–686, 2022
work page 2022
-
[30]
TurboQuant: Online Vector Quantization with Near-optimal Distortion Rate
Amir Zandieh, Majid Daliri, Majid Hadian, and Vahab Mirrokni. TurboQuant: Online vector quantization with near-optimal distortion rate, 2025. arXiv:2504.19874
work page internal anchor Pith review arXiv 2025
-
[31]
A. P. Dempster, N. M. Laird, and D. B. Rubin. Maximum likelihood from incomplete data via the EM algorithm.Journal on Royal Statistical Society: Series B (Methodological), 39(1):1–22, 1977
work page 1977
-
[32]
Chao-Kai Wen, Shi Jin, Kai-Kit Wong, Jung-Chieh Chen, and Pangan Ting. Channel estimation for massive MIMO using Gaussian-mixture bayesian learning.IEEE Transactions on Wireless Communications, 14(3): 1356–1368, 2015
work page 2015
-
[33]
Yi Song, Tianyu Yang, Mahdi Barzegar Khalilsarai, and Giuseppe Caire. Downlink CSIT under compressed feedback: Joint versus separate source-channel coding.IEEE Transactions on Wireless Communications, 24(10):8429–8444, 2025
work page 2025
-
[34]
Nguyen, Marcel Worring, and Arnold W
Hieu T. Nguyen, Marcel Worring, and Arnold W. M. Smeulders. A study of Gaussian mixture models of color and texture features for image classification and segmentation.Pattern Recognition, 38(11): 2005–2018, 2005
work page 2005
-
[35]
From learning models of natural image patches to whole image restoration
Daniel Zoran and Yair Weiss. From learning models of natural image patches to whole image restoration. InProceedings of IEEE International Conference on Computer Vision (ICCV), 2011
work page 2011
-
[36]
Fabian Falck, Haoting Zhang, Matthew Willetts, George Nicholson, Christopher Yau, and Chris C Holmes. Multi-facet clustering variational autoencoders.Advances in Neural Information Processing Systems, 34: 8676–8690, 2021
work page 2021
-
[37]
Subspace gaussian mixture models for speech recognition
Daniel Povey, Lukas Burget, Mohit Agarwal, Pinar Akyazi, Fan Kai, Arnab Ghoshal, Ondrej Glembek, Nagendra Goel, Martin Karafiat, Ariya Rastrow, et al. Subspace gaussian mixture models for speech recognition. InProceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2010
work page 2010
-
[38]
Gray.Vector quantization and signal compression
Allen Gersho and Robert M. Gray.Vector quantization and signal compression. Springer, Boston, MA, 1992
work page 1992
-
[39]
Zhenyu Liu, Mason del Rosario, and Zhi Ding. A Markovian model-driven deep learning framework for massive MIMO CSI feedback.IEEE Transactions on Wireless Communications, 21(2):1214–1228, 2022. 12 A Proof of Theorem 1 (single global water level) The conditional benchmark (4) is a separable convex program over {Dc} subject to a single linear constraint. For...
work page 2022
-
[40]
documents its current form in VVC. The library is a small set offixed trigonometric transforms (DCT-II together with DST-VII and DCT-VIII variants), the branch is chosen by an encoder-side rate–distortion search and signaled with a few context-coded bits, and the bit allocation is governed by a per-block quantization parameter from the standard. AMT thus ...
work page 2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.