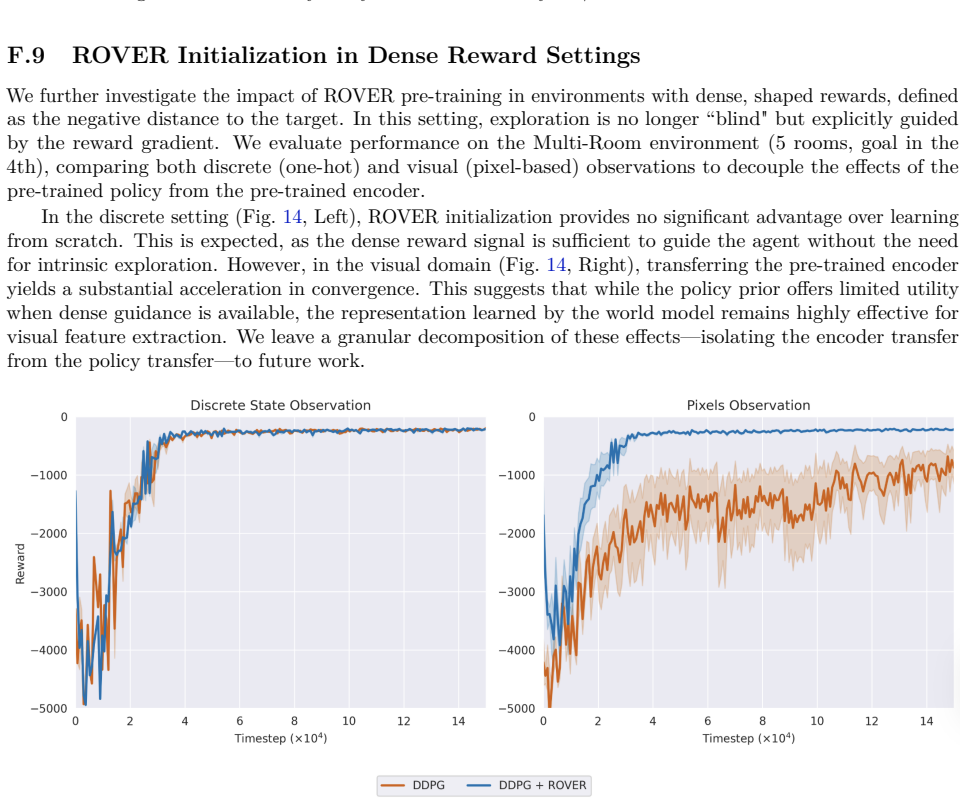
Reward-free Pretraining for Reinforcement Learning via Occupancy Coverage Maximization
Pith reviewed 2026-06-26 14:46 UTC · model grok-4.3
The pith
Pretraining by maximizing occupancy coverage with a resolvent world model yields more uniform exploration and faster adaptation to sparse rewards.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
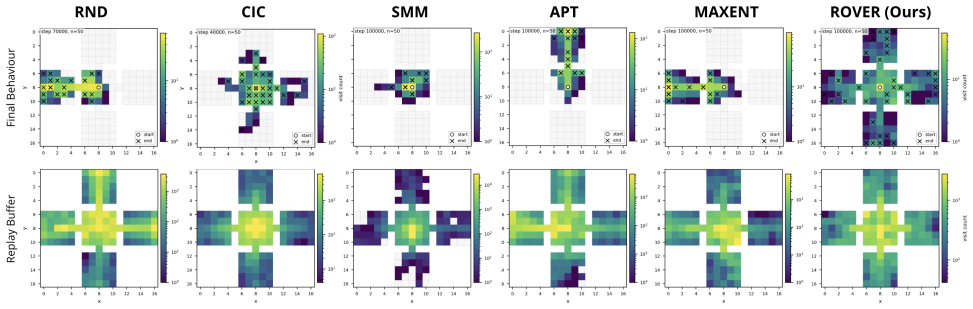
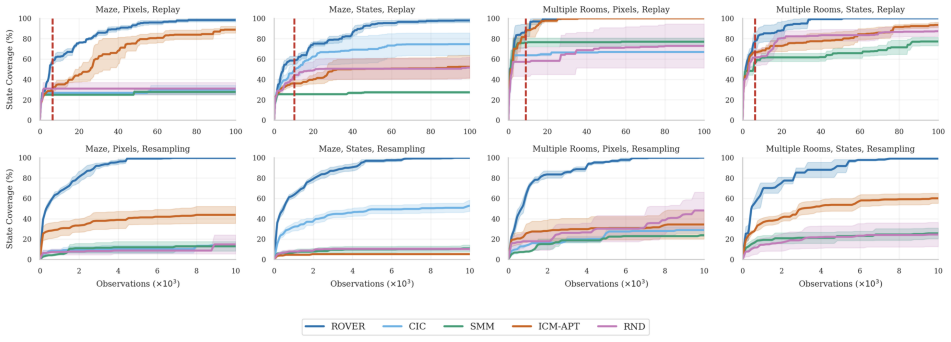
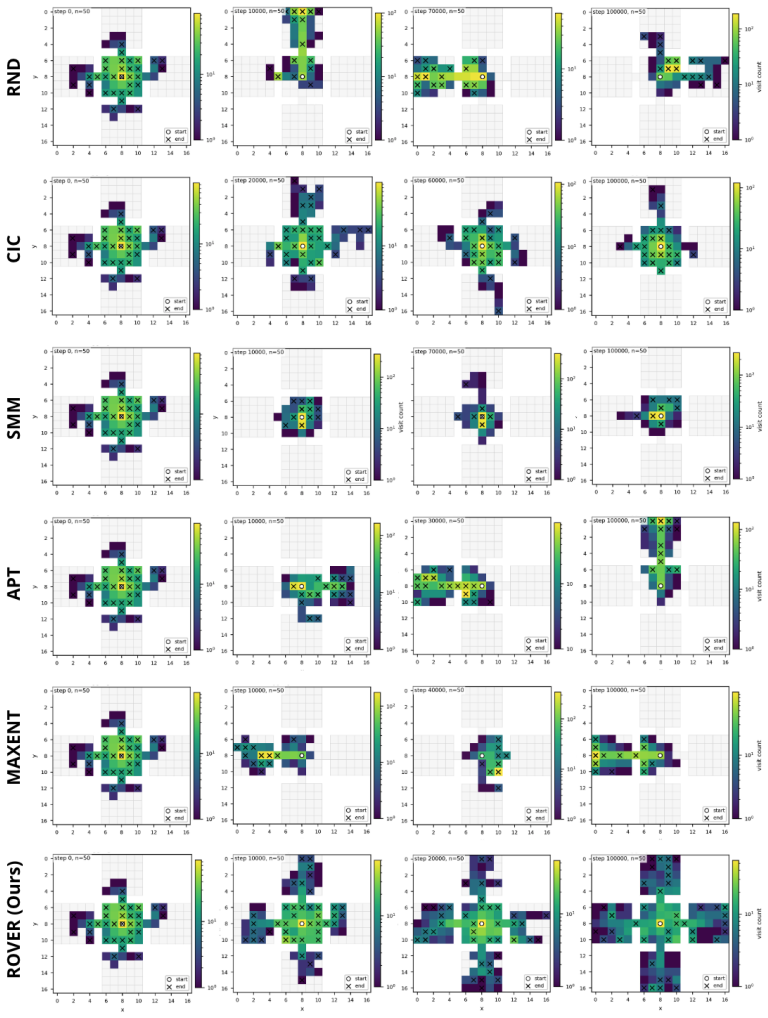
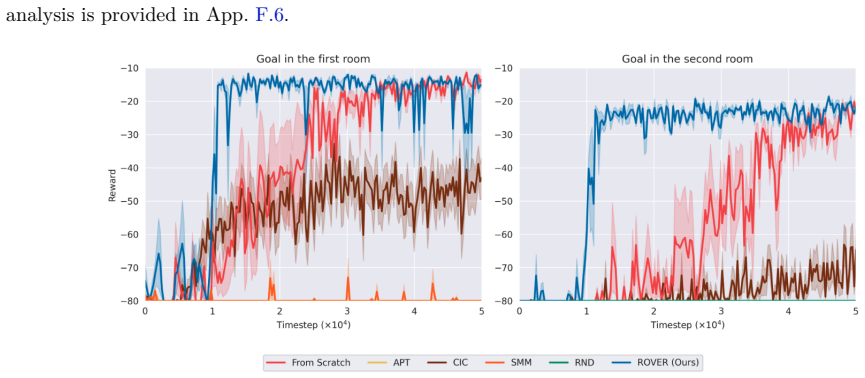
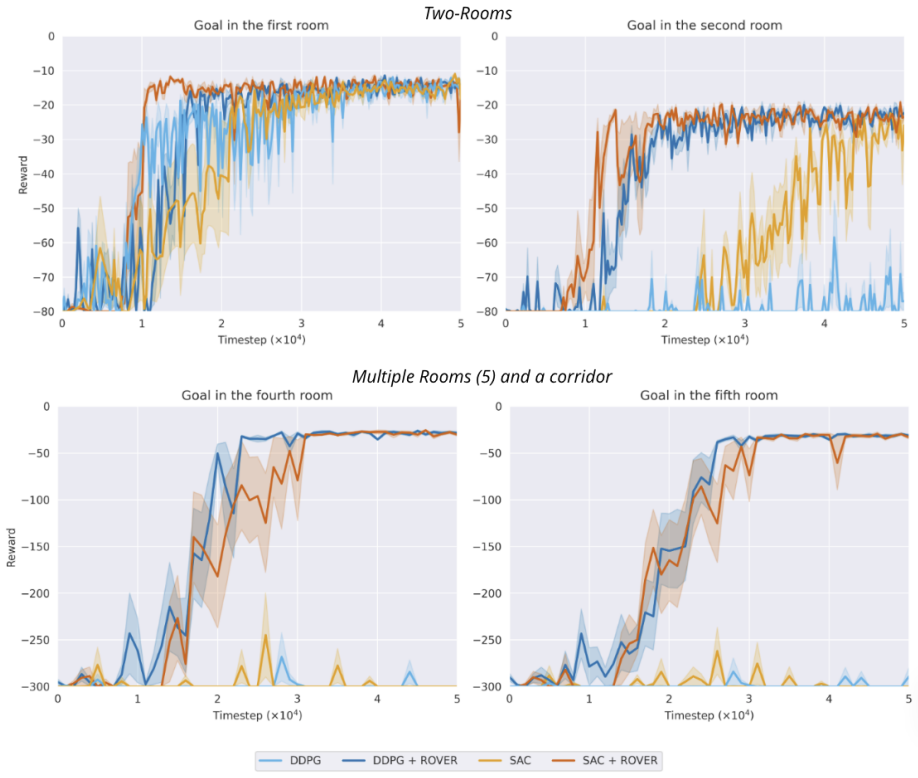
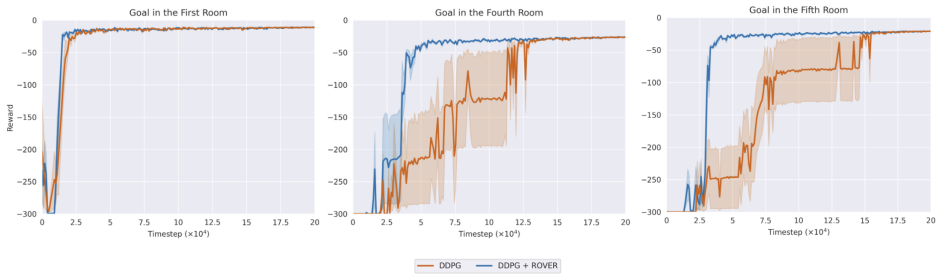
The paper claims that maximizing coverage of the occupancy measure via entropy, estimated through a resolvent world model and balanced by a virtual sink state, produces transferable exploration policies that achieve more uniform aggregate coverage and stronger initializations for downstream sparse-reward tasks than standard reward-free baselines.
What carries the argument
ROVER, which estimates the occupancy measure with a learned resolvent world model and introduces a virtual sink state to balance known-state coverage against expansion into unseen regions.
If this is right
- Agents reach more uniform aggregate coverage of the state space during pretraining.
- Downstream sparse-reward tasks receive stronger initial policies that adapt faster than those from standard reward-free baselines.
- The method operates without evaluating or accessing the extrinsic reward during the pretraining phase.
- The sink state prevents cyclic expansion-collapse dynamics that can arise in coverage-based learning.
- The resolvent formulation bypasses direct density or entropy estimation difficulties.
Where Pith is reading between the lines
- The same coverage objective might apply to continuous control domains if the resolvent model scales.
- Pretraining of this form could reduce reliance on reward relabeling in meta-learning pipelines.
- The sink-state device might transfer to other exploration objectives to stabilize learning dynamics.
Load-bearing premise
A learned resolvent world model can reliably estimate the occupancy measure for the coverage objective without any reward signal during pretraining.
What would settle it
An experiment in the same tabular or pixel-based navigation tasks where ROVER fails to produce measurably more uniform coverage or faster downstream adaptation than the compared reward-free baselines.
Figures


read the original abstract
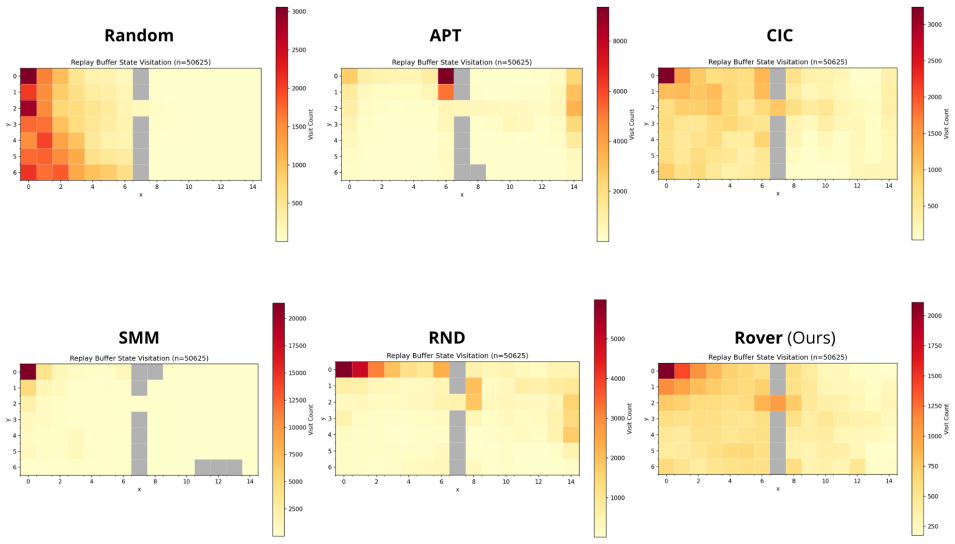
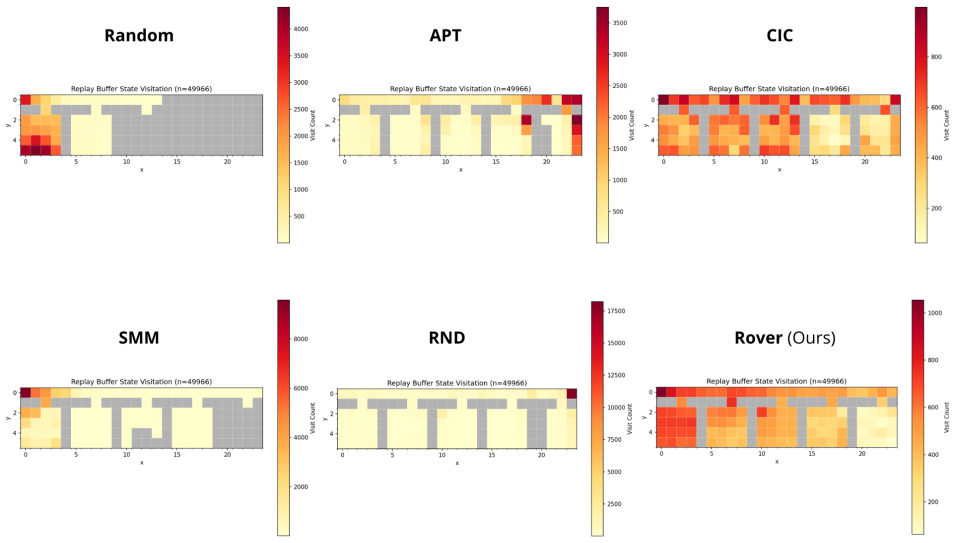
Sparse rewards pose a central challenge in reinforcement learning, since agents receive no informative signal until they reach their goal. Intrinsic-reward methods address this issue by optimizing non-stationary objectives such as novelty, prediction error, or skill diversity, thereby injecting a supervision signal into the problem. While effective, these methods often require that the extrinsic (sparse) reward can be evaluated -- either online or during offline relabeling of the stored transitions. This limitation is particularly vexing for multi-task, meta-, and continual reinforcement learning, where agents' interactions with the environment are usually reward-free. In this work, we present a method to pre-train transferable exploration policies that rapidly adapt to sparse rewards at downstream task time. Our objective maximizes state-space covering for the occupancy measure, and can be framed in terms of entropy maximization. Its algorithmic implementation, ROVER, leverages recent advances on the operatorial formulation of RL to estimate occupancy with a learned resolvent world model, bypassing common hurdles associated with density and entropy estimation. ROVER further introduces a virtual "sink" state for unexplored regions, balancing coverage of known states with expansion into unseen ones and preventing cyclic expansion-collapse behavior during learning. In tabular and pixel-based sparse navigation tasks, ROVER produces more uniform aggregate coverage and stronger initializations for downstream tasks than standard reward-free baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ROVER, a reward-free pretraining algorithm for RL that maximizes coverage of the state-space occupancy measure by framing it as entropy maximization. The method is implemented via a learned resolvent world model that estimates occupancy without rewards, augmented by a virtual sink state to handle unexplored regions and avoid cyclic behavior. The central empirical claim is that, in tabular and pixel-based sparse navigation tasks, ROVER achieves more uniform aggregate coverage and yields stronger initializations for downstream sparse-reward tasks than standard reward-free baselines.
Significance. If the resolvent-based occupancy estimates are shown to be faithful, the work would provide a principled route to reward-free pretraining that sidesteps direct density estimation, leveraging operatorial RL advances. The virtual sink state is a concrete design choice that addresses a known failure mode in coverage objectives. However, the absence of any verification that the learned model recovers usable occupancy measures (especially in pixel regimes) limits the strength of the contribution at present.
major comments (2)
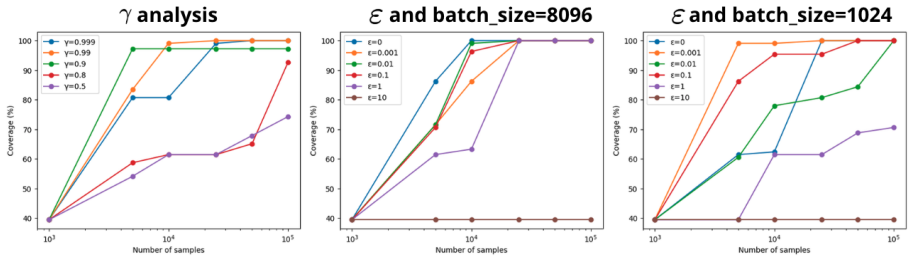
- [Abstract and algorithmic implementation] Abstract and algorithmic implementation section: the central claim that ROVER optimizes the intended occupancy coverage measure rests on the learned resolvent world model producing accurate estimates from reward-free data alone. No ground-truth comparison (possible in tabular settings) or ablation measuring estimation error versus true occupancy is reported, so it remains possible that the objective actually optimized deviates systematically from the coverage measure asserted in the abstract.
- [Abstract] Abstract: the claim of stronger performance on navigation tasks is load-bearing for the paper's contribution, yet the abstract (and by extension the reported results) provides no quantitative metrics, error bars, or ablation studies on components such as the resolvent estimation or sink state. This prevents assessment of whether the reported uniformity and downstream gains are robust or statistically meaningful.
Simulated Author's Rebuttal
We appreciate the referee's insightful comments on our manuscript. We provide point-by-point responses to the major comments and outline the revisions we will make.
read point-by-point responses
-
Referee: [Abstract and algorithmic implementation] Abstract and algorithmic implementation section: the central claim that ROVER optimizes the intended occupancy coverage measure rests on the learned resolvent world model producing accurate estimates from reward-free data alone. No ground-truth comparison (possible in tabular settings) or ablation measuring estimation error versus true occupancy is reported, so it remains possible that the objective actually optimized deviates systematically from the coverage measure asserted in the abstract.
Authors: We agree with this assessment. Verifying the fidelity of the resolvent-based occupancy estimates is crucial. We will add ground-truth comparisons in tabular settings and ablations measuring estimation error against true occupancy in the revised manuscript to ensure the optimized objective matches the intended coverage measure. revision: yes
-
Referee: [Abstract] Abstract: the claim of stronger performance on navigation tasks is load-bearing for the paper's contribution, yet the abstract (and by extension the reported results) provides no quantitative metrics, error bars, or ablation studies on components such as the resolvent estimation or sink state. This prevents assessment of whether the reported uniformity and downstream gains are robust or statistically meaningful.
Authors: The main text of the paper includes quantitative results with error bars from multiple seeds and some ablations. However, we acknowledge that the abstract would benefit from including key metrics. We will revise the abstract to report specific quantitative improvements in coverage and downstream performance. We will also expand ablations on the resolvent estimation and sink state in the main text if not already sufficient. revision: partial
Circularity Check
No circularity in derivation chain
full rationale
The paper defines its pretraining objective directly as entropy maximization over the occupancy measure for state-space coverage and implements it via a learned resolvent world model that draws on operatorial RL advances. No equations or steps are shown that reduce the claimed downstream uniformity or initialization gains to a fitted quantity by construction, nor does any self-citation chain serve as the sole justification for a uniqueness claim or ansatz. The central derivation remains independent of its own outputs and is presented as self-contained against the reported tabular and pixel navigation benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Occupancy measure can be estimated via learned resolvent of the transition operator without reward signal
invented entities (1)
-
virtual sink state
no independent evidence
Reference graph
Works this paper leans on
-
[1]
MIT press Cambridge, 1998
Richard S Sutton, Andrew G Barto, et al.Reinforcement learning: An introduction. MIT press Cambridge, 1998
1998
-
[2]
Denis Yarats, David Brandfonbrener, Hao Liu, Michael Laskin, Pieter Abbeel, Alessandro Lazaric, and Lerrel Pinto. Don’t change the algorithm, change the data: Exploratory data for offline reinforcement learning, 2022. URLhttps://arxiv.org/abs/2201.13425
-
[3]
Learning one representation to optimize all rewards.Advances in Neural Information Processing Systems, 34:13–23, 2021
Ahmed Touati and Yann Ollivier. Learning one representation to optimize all rewards.Advances in Neural Information Processing Systems, 34:13–23, 2021
2021
-
[4]
Siddhant Agarwal, Harshit Sikchi, Peter Stone, and Amy Zhang. Proto successor measure: Representing the space of all possible solutions of reinforcement learning, 2024. URLhttps://arxiv.org/abs/2411.19418
-
[5]
Andrea Tirinzoni, Ahmed Touati, Jesse Farebrother, Mateusz Guzek, Anssi Kanervisto, Yingchen Xu, Alessandro Lazaric, and Matteo Pirotta. Zero-shot whole-body humanoid control via behavioral foundation models.arXiv preprint arXiv:2504.11054, 2025
-
[6]
Successor features for transfer in reinforcement learning.Advances in neural information processing systems, 30, 2017
André Barreto, Will Dabney, Rémi Munos, Jonathan J Hunt, Tom Schaul, Hado P Van Hasselt, and David Silver. Successor features for transfer in reinforcement learning.Advances in neural information processing systems, 30, 2017
2017
-
[7]
TD-MPC2: Scalable, Robust World Models for Continuous Control
Nicklas Hansen, Hao Su, and Xiaolong Wang. Td-mpc2: Scalable, robust world models for continuous control.arXiv preprint arXiv:2310.16828, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Mastering Diverse Domains through World Models
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse domains through world models.arXiv preprint arXiv:2301.04104, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Urlb: Unsupervised reinforcement learning benchmark.arXiv preprint arXiv:2110.15191, 2021
Michael Laskin, Denis Yarats, Hao Liu, Kimin Lee, Albert Zhan, Kevin Lu, Catherine Cang, Lerrel Pinto, and Pieter Abbeel. Urlb: Unsupervised reinforcement learning benchmark.arXiv preprint arXiv:2110.15191, 2021
-
[10]
Provably efficient maximum entropy exploration
Elad Hazan, Sham Kakade, Karan Singh, and Abby Van Soest. Provably efficient maximum entropy exploration. InInternational conference on machine learning, pages 2681–2691. PMLR, 2019. 10
2019
-
[11]
A policy gradient method for task-agnostic exploration
Mirco Mutti, Lorenzo Pratissoli, and Marcello Restelli. A policy gradient method for task-agnostic exploration. In4th Lifelong Machine Learning Workshop at ICML 2020, 2020
2020
-
[12]
Reinforcement learning with prototypical representations
Denis Yarats, Rob Fergus, Alessandro Lazaric, and Lerrel Pinto. Reinforcement learning with prototypical representations. InInternational Conference on Machine Learning, pages 11920–11931. PMLR, 2021
2021
-
[13]
Efficient exploration via state marginal matching.arXiv preprint arXiv:1906.05274, 2019
Lisa Lee, Benjamin Eysenbach, Emilio Parisotto, Eric Xing, Sergey Levine, and Ruslan Salakhutdinov. Efficient exploration via state marginal matching.arXiv preprint arXiv:1906.05274, 2019
-
[14]
Behavior from the void: Unsupervised active pre-training, 2021
Hao Liu and Pieter Abbeel. Behavior from the void: Unsupervised active pre-training, 2021. URL https://arxiv.org/abs/2103.04551
-
[15]
Curiosity-driven exploration by self-supervised prediction
Deepak Pathak, Pulkit Agrawal, Alexei A Efros, and Trevor Darrell. Curiosity-driven exploration by self-supervised prediction. InInternational conference on machine learning, pages 2778–2787. PMLR, 2017
2017
-
[16]
Exploration by Random Network Distillation
Yuri Burda, Harrison Edwards, Amos Storkey, and Oleg Klimov. Exploration by random network distillation.arXiv preprint arXiv:1810.12894, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[17]
Self-supervised exploration via disagreement
Deepak Pathak, Dhiraj Gandhi, and Abhinav Gupta. Self-supervised exploration via disagreement. In International conference on machine learning, pages 5062–5071. PMLR, 2019
2019
-
[18]
Wilson, and Emmanuel Rachelson
Paul-Antoine Le Tolguenec, Yann Besse, Florent Teichteil-Konigsbuch, Dennis G. Wilson, and Emmanuel Rachelson. Exploration by learning diverse skills through successor state measures, 2024. URLhttps: //arxiv.org/abs/2406.10127
-
[19]
Cic: Contrastive intrinsic control for unsupervised skill discovery, 2022
Michael Laskin, Hao Liu, Xue Bin Peng, Denis Yarats, Aravind Rajeswaran, and Pieter Abbeel. Cic: Contrastive intrinsic control for unsupervised skill discovery, 2022. URLhttps://arxiv.org/abs/2202. 00161
2022
-
[20]
Kernel mean embedding of distributions: A review and beyond.Foundations and Trends®in Machine Learning, 10 (1-2):1–141, 2017
Krikamol Muandet, Kenji Fukumizu, Bharath Sriperumbudur, and Bernhard Schölkopf. Kernel mean embedding of distributions: A review and beyond.Foundations and Trends®in Machine Learning, 10 (1-2):1–141, 2017
2017
-
[21]
The maximum entropy of a metric space.The Quarterly Journal of Mathematics, 72(4):1271–1309, 2021
Tom Leinster and Emily Roff. The maximum entropy of a metric space.The Quarterly Journal of Mathematics, 72(4):1271–1309, 2021
2021
-
[22]
Operator world models for reinforcement learning.Advances in Neural Information Processing Systems, 37:111432–111463, 2024
Pietro Novelli, Marco Pratticò, Massimiliano Pontil, and Carlo Ciliberto. Operator world models for reinforcement learning.Advances in Neural Information Processing Systems, 37:111432–111463, 2024
2024
-
[23]
Learning Koopman invariant subspaces for dynamic mode decomposition.Advances in Neural Information Processing Systems, 30, 2017
Naoya Takeishi, Yoshinobu Kawahara, and Takehisa Yairi. Learning Koopman invariant subspaces for dynamic mode decomposition.Advances in Neural Information Processing Systems, 30, 2017
2017
-
[24]
Deep learning for universal linear embeddings of nonlinear dynamics.Nature Communications, 9(1):4950, 2018
Bethany Lusch, J Nathan Kutz, and Steven L Brunton. Deep learning for universal linear embeddings of nonlinear dynamics.Nature Communications, 9(1):4950, 2018
2018
-
[25]
Linearly recurrent autoencoder networks for learning dynamics
Samuel E Otto and Clarence W Rowley. Linearly recurrent autoencoder networks for learning dynamics. SIAM Journal on Applied Dynamical Systems, 18(1):558–593, 2019
2019
-
[26]
Learning dynamical systems via Koopman operator regression in reproducing kernel Hilbert spaces
Vladimir Kostic, Pietro Novelli, Andreas Maurer, Carlo Ciliberto, Lorenzo Rosasco, and Massimiliano Pontil. Learning dynamical systems via Koopman operator regression in reproducing kernel Hilbert spaces. Advances in Neural Information Processing Systems, 35:4017–4031, 2022
2022
-
[27]
Sharp spectral rates for Koopman operator learning.Advances in Neural Information Processing Systems, 36:32328–32339, 2023
Vladimir Kostic, Karim Lounici, Pietro Novelli, and Massimiliano Pontil. Sharp spectral rates for Koopman operator learning.Advances in Neural Information Processing Systems, 36:32328–32339, 2023
2023
-
[28]
Finite-data error bounds for Koopman-based prediction and control.Journal of Nonlinear Science, 33(1):14, 2023
Feliks Nüske, Sebastian Peitz, Friedrich Philipp, Manuel Schaller, and Karl Worthmann. Finite-data error bounds for Koopman-based prediction and control.Journal of Nonlinear Science, 33(1):14, 2023. 11
2023
-
[29]
Minchan Jeong, Jongha Jon Ryu, Se-Young Yun, and Gregory W. Wornell. Efficient parametric SVD of koopman operator for stochastic dynamical systems. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URLhttps://openreview.net/forum?id=kL2pnzClyD
2025
-
[30]
Giacomo Turri, Luigi Bonati, Kai Zhu, Massimiliano Pontil, and Pietro Novelli. Self-supervised evolution operator learning for high-dimensional dynamical systems.arXiv preprint arXiv:2505.18671, 2025
-
[31]
Koopman-Assisted Reinforcement Learning
Preston Rozwood, Edward Mehrez, Ludger Paehler, Wen Sun, and Steven L Brunton. Koopman-assisted reinforcement learning.arXiv preprint arXiv:2403.02290, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Representation Learning with Contrastive Predictive Coding
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[33]
Curl: Contrastive unsupervised representations for reinforcement learning
Michael Laskin, Aravind Srinivas, and Pieter Abbeel. Curl: Contrastive unsupervised representations for reinforcement learning. InInternational conference on machine learning, pages 5639–5650. PMLR, 2020
2020
-
[34]
Taco: Temporal latent action-driven contrastive loss for visual reinforcement learning.Advances in Neural Information Processing Systems, 36:48203–48225, 2023
Ruijie Zheng, Xiyao Wang, Yanchao Sun, Shuang Ma, Jieyu Zhao, Huazhe Xu, Hal Daumé III, and Furong Huang. Taco: Temporal latent action-driven contrastive loss for visual reinforcement learning.Advances in Neural Information Processing Systems, 36:48203–48225, 2023
2023
-
[35]
Byol-explore: Exploration by bootstrapped prediction.Advances in neural information processing systems, 35:31855–31870, 2022
Zhaohan Guo, Shantanu Thakoor, Miruna Pislar, Bernardo Avila Pires, Florent Altché, Corentin Tallec, Alaa Saade, Daniele Calandriello, Jean-Bastien Grill, Yunhao Tang, Michal Valko, Remi Munos, Mohammad Gheshlaghi Azar, and Bilal Piot. Byol-explore: Exploration by bootstrapped prediction.Advances in neural information processing systems, 35:31855–31870, 2022
2022
-
[36]
Modelling transition dynamics in MDPs with RKHS embeddings
Steffen Grunewalder, Guy Lever, Luca Baldassarre, Massi Pontil, and Arthur Gretton. Modelling transition dynamics in mdps with rkhs embeddings.arXiv preprint arXiv:1206.4655, 2012
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[37]
Adaptive trust region policy optimization: Global convergence and faster rates for regularized mdps
Lior Shani, Yonathan Efroni, and Shie Mannor. Adaptive trust region policy optimization: Global convergence and faster rates for regularized mdps. InProceedings of the AAAI conference on artificial intelligence, volume 34, pages 5668–5675, 2020
2020
-
[38]
Kakade, Jason D
Alekh Agarwal, Sham M. Kakade, Jason D. Lee, and Gaurav Mahajan. On the theory of policy gradient methods: Optimality, approximation, and distribution shift.Journal of Machine Learning Research, 22 (98):1–76, 2021
2021
-
[39]
On the convergence rates of policy gradient methods.Journal of Machine Learning Research, 23 (282):1–36, 2022
Lin Xiao. On the convergence rates of policy gradient methods.Journal of Machine Learning Research, 23 (282):1–36, 2022
2022
-
[40]
Using the nyström method to speed up kernel machines
Christopher Williams and Matthias Seeger. Using the nyström method to speed up kernel machines. Advances in neural information processing systems, 13, 2000
2000
-
[41]
Less is more: Nyström computational regularization.Advances in neural information processing systems, 28, 2015
Alessandro Rudi, Raffaello Camoriano, and Lorenzo Rosasco. Less is more: Nyström computational regularization.Advances in neural information processing systems, 28, 2015
2015
-
[42]
Minigrid & miniworld: Modular & customizable reinforcement learning environments for goal-oriented tasks.Advances in Neural Information Processing Systems, 36:73383–73394, 2023
Maxime Chevalier-Boisvert, Bolun Dai, Mark Towers, Rodrigo Perez-Vicente, Lucas Willems, Salem Lahlou, Suman Pal, Pablo Samuel Castro, and Jordan Terry. Minigrid & miniworld: Modular & customizable reinforcement learning environments for goal-oriented tasks.Advances in Neural Information Processing Systems, 36:73383–73394, 2023
2023
-
[43]
Springer, 1972
NS Landkof.Foundations of modern potential theory, volume 180. Springer, 1972
1972
-
[44]
Minimal riesz energy point configurations for rectifiable d-dimensional manifolds.Advances in Mathematics, 193(1):174–204, 2005
Douglas P Hardin and Edward B Saff. Minimal riesz energy point configurations for rectifiable d-dimensional manifolds.Advances in Mathematics, 193(1):174–204, 2005
2005
-
[45]
Springer, 2006
Charalambos D Aliprantis and Kim C Border.Infinite dimensional analysis: a hitchhiker’s guide. Springer, 2006. 12
2006
-
[46]
Continuous control with deep reinforcement learning
Timothy P Lillicrap, Jonathan J Hunt, Alexander Pritzel, Nicolas Heess, Tom Erez, Yuval Tassa, David Silver, and Daan Wierstra. Continuous control with deep reinforcement learning.arXiv preprint arXiv:1509.02971, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[47]
Soft Actor-Critic Algorithms and Applications
Tuomas Haarnoja, Aurick Zhou, Kristian Hartikainen, George Tucker, Sehoon Ha, Jie Tan, Vikash Kumar, Henry Zhu, Abhishek Gupta, Pieter Abbeel, et al. Soft actor-critic algorithms and applications.arXiv preprint arXiv:1812.05905, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[48]
Aviral Kumar, Aurick Zhou, George Tucker, and Sergey Levine. Conservative q-learning for offline reinforcement learning, 2020. URLhttps://arxiv.org/abs/2006.04779. 13 A Connections to Information Geometry and Potential Theory A.1 Connection to Rényi Entropy and Diversity. Our use of a Reproducing Kernel Hilbert Space (RKHS) naturally equips the state spac...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.