Diffusion Integrated Gradients: Controllable Path Generation for Flexible Feature Attribution
Pith reviewed 2026-06-26 11:11 UTC · model grok-4.3
The pith
Diffusion Integrated Gradients trains a diffusion model on stick-breaking paths to generate controllable attribution paths.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
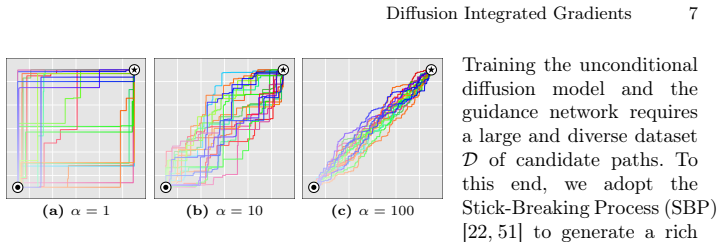
DiffIG reformulates attribution path generation as a conditional generative modeling problem. It trains a diffusion model to learn the distribution over paths generated from a Stick-Breaking Process and then applies guided sampling to embed user guidance during the sampling procedure, yielding attributions that quantitatively match or outperform existing path-based methods while achieving perceptually aligned explanations.
What carries the argument
The diffusion model trained on Stick-Breaking Process paths, which enables guided sampling to produce user-controllable paths from baseline to input for gradient integration.
If this is right
- Attribution paths become adjustable at inference time according to user-specified guidance without retraining the target model.
- Explanations can incorporate perceptual or domain preferences through the guidance mechanism while retaining axiomatic guarantees.
- Path generation is decoupled from the downstream model, allowing the same trained diffusion model to serve multiple prediction networks.
- The generative formulation supports inference-time control that prior fixed-path methods lack.
Where Pith is reading between the lines
- The same diffusion-based path modeling could extend to other gradient-integration attribution techniques that depend on path choice.
- Guidance signals could be designed to enforce additional properties such as sparsity or smoothness directly in the generated paths.
- Alternative path distributions beyond stick-breaking might be substituted during training to explore different controllability behaviors.
Load-bearing premise
That a diffusion model can learn a useful distribution over stick-breaking paths sufficient to support guided sampling that produces better attributions than fixed or hand-crafted paths.
What would settle it
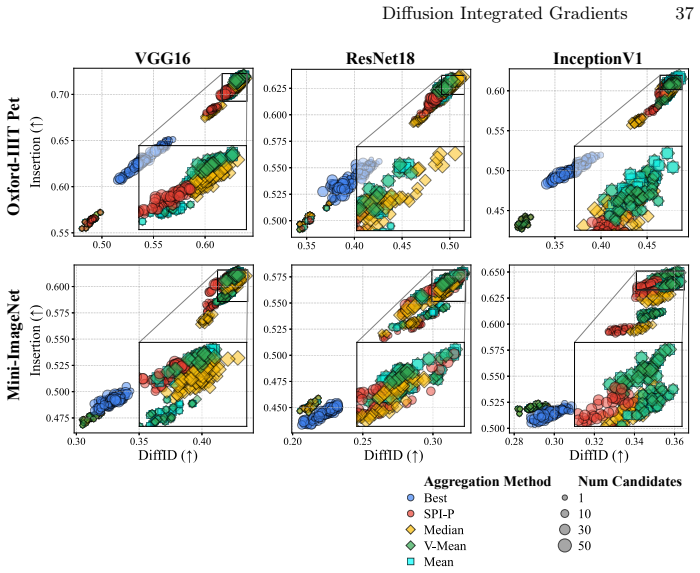
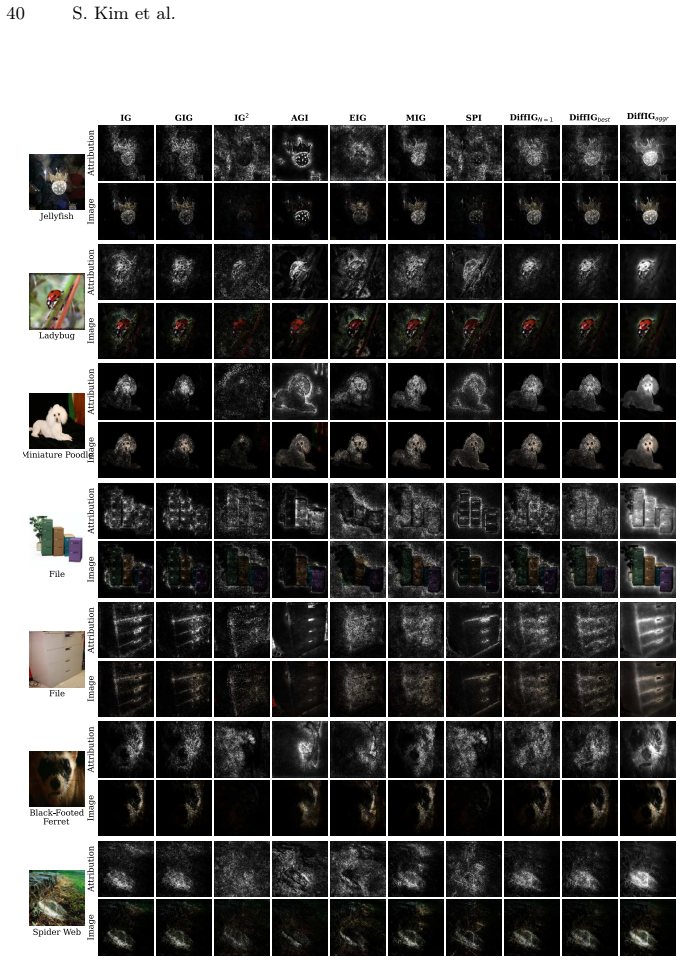
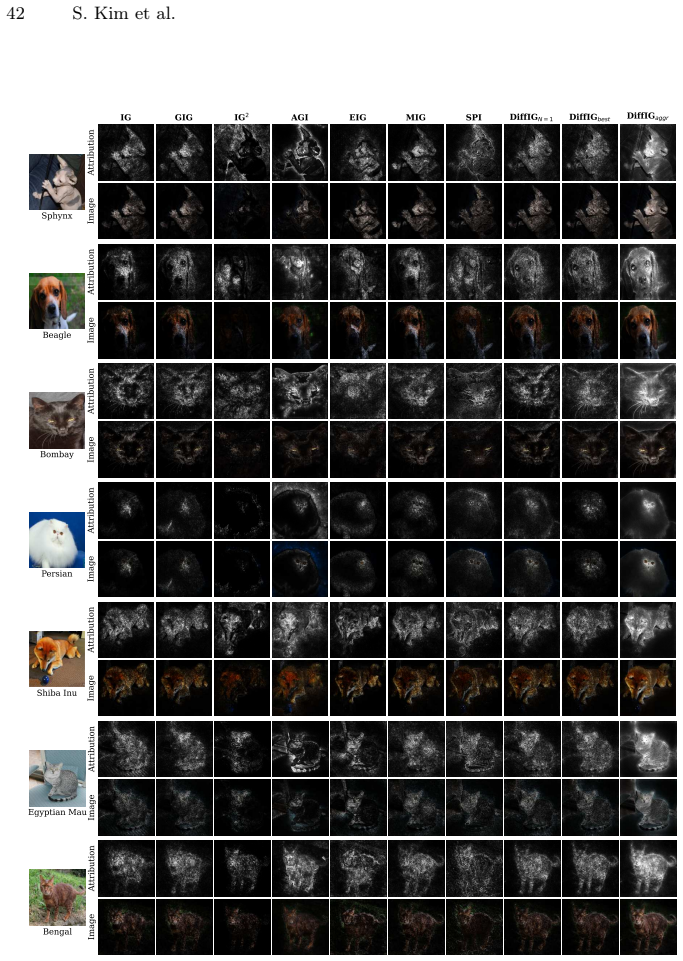
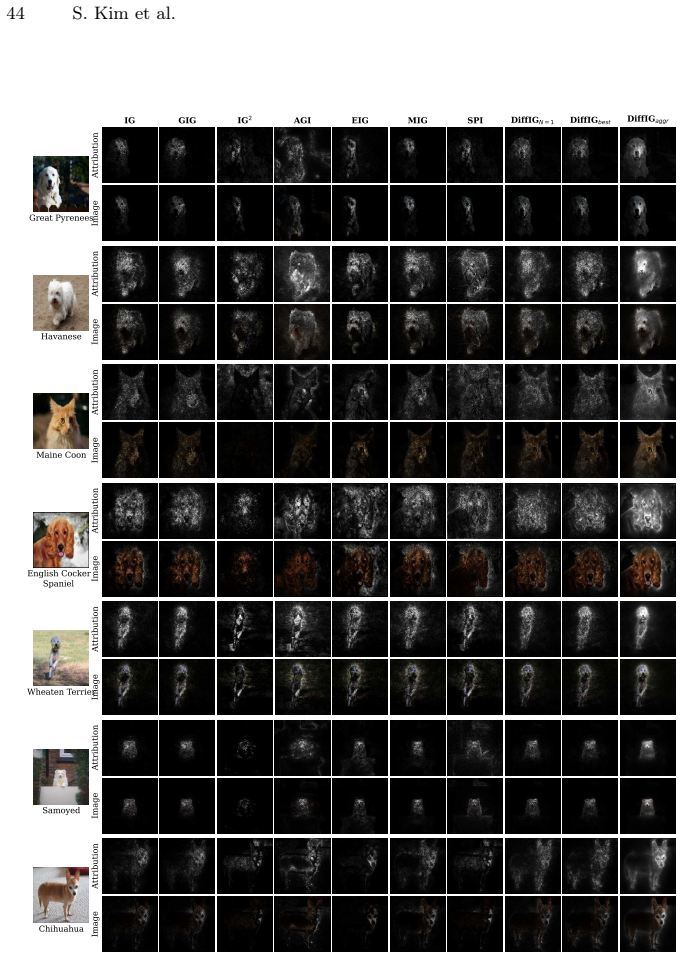
Compare DiffIG attributions against standard Integrated Gradients and other baselines on an image classification model using a dataset with human-annotated important regions; if human agreement or quantitative scores do not improve or match, the central claim is falsified.
Figures




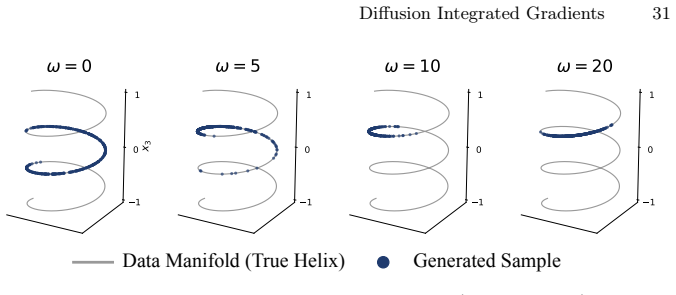

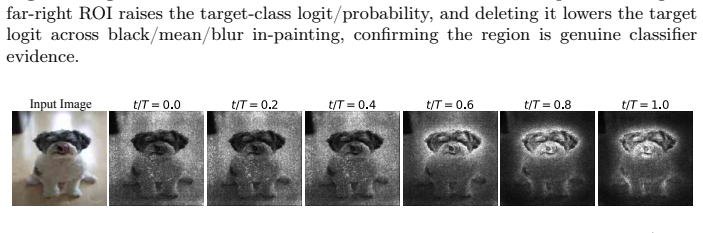

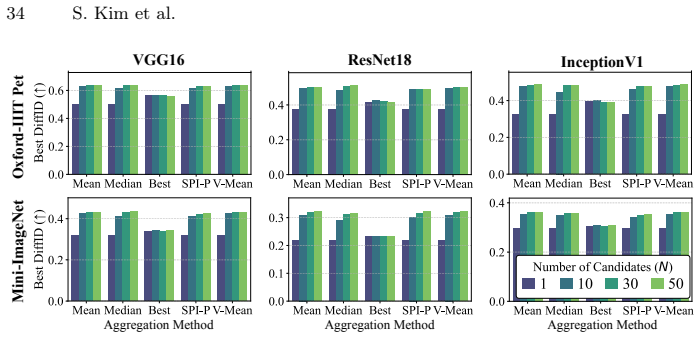

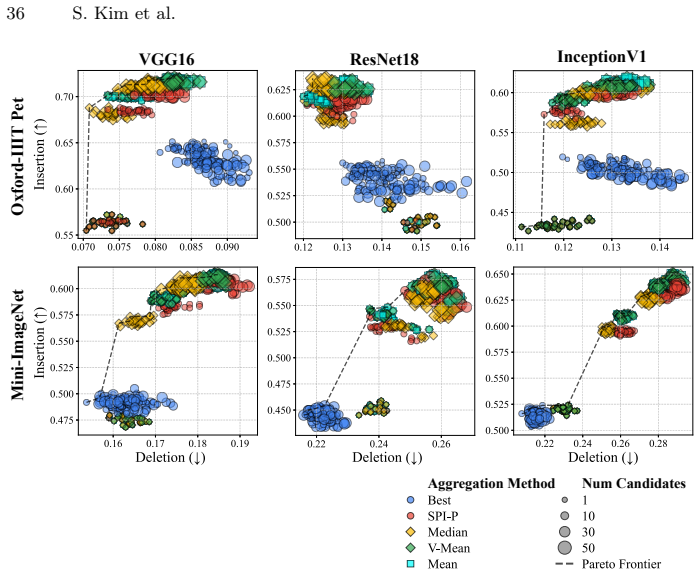



read the original abstract
Path-based attribution methods such as Integrated Gradients (IG) are widely adopted for their strong axiomatic properties and effectiveness in attributing model predictions to input features by integrating gradients along a path from a baseline to the input. However, the choice of the attribution path largely affects the quality of explanations, and existing approaches rely on fixed or hand-crafted paths that often produce noisy or distorted attributions. To address this limitation, we propose Diffusion Integrated Gradients (DiffIG), a novel method that reformulates path generation as a conditional generative modeling problem. DiffIG first trains a diffusion model to learn a distribution over paths generated from a Stick-Breaking Process, then employs guided sampling to embed user guidance during the sampling procedure. We demonstrate that DiffIG quantitatively matches or outperforms existing path-based methods, achieving perceptually aligned explanations. This work introduces a new generative perspective for flexible, inference-time controllable Explainable Artificial Intelligence (XAI) methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Diffusion Integrated Gradients (DiffIG), which reformulates attribution path generation as a conditional generative modeling task: a diffusion model is trained on paths sampled from a Stick-Breaking Process (which satisfy the required endpoints) and guided sampling is then used at inference time to incorporate user-specified guidance, yielding controllable paths for Integrated Gradients that are claimed to produce more perceptually aligned explanations than fixed or hand-crafted paths while matching or exceeding prior methods.
Significance. If the guided sampling procedure can be shown to preserve the endpoint conditions required by the fundamental theorem of calculus, the approach would supply a genuinely new, inference-time controllable mechanism for path-based XAI that retains IG’s axiomatic guarantees. The generative-modeling framing itself is a fresh perspective on an otherwise mature line of work.
major comments (2)
- [§3 (Method)] The description of guided sampling (abstract and §3) does not specify the precise conditioning mechanism or loss term that enforces γ(0) = baseline and γ(1) = input at every denoising step. Because any deviation from these endpoints invalidates the telescoping integral that equals F(x) − F(x′), this omission directly undermines the claim that DiffIG attributions remain axiomatically valid.
- [Experiments section] The quantitative claim that DiffIG “matches or outperforms existing path-based methods” (abstract) is not supported by any reported metrics, datasets, or statistical tests in the provided text; without these, it is impossible to evaluate whether the perceptual-alignment improvement is real or merely visual.
minor comments (2)
- [§3] Notation for the diffusion forward and reverse processes is introduced without explicit reference to the standard DDPM formulation; a short equation block relating the learned score to the IG path integral would improve clarity.
- [§3.1] The Stick-Breaking Process is cited but its exact parameterization (number of breaks, concentration parameter, etc.) is not stated; this detail is needed to reproduce the training distribution.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below and will revise the manuscript to improve clarity and completeness.
read point-by-point responses
-
Referee: [§3 (Method)] The description of guided sampling (abstract and §3) does not specify the precise conditioning mechanism or loss term that enforces γ(0) = baseline and γ(1) = input at every denoising step. Because any deviation from these endpoints invalidates the telescoping integral that equals F(x) − F(x′), this omission directly undermines the claim that DiffIG attributions remain axiomatically valid.
Authors: We agree that the current description of the guided sampling procedure in §3 lacks sufficient detail on the conditioning mechanism and any auxiliary loss terms used to enforce the endpoint constraints γ(0) = baseline and γ(1) = input at each denoising step. In the revised manuscript we will expand §3 with an explicit formulation of the conditional diffusion process, including the precise form of the guidance term and any endpoint-regularization losses, together with a short proof sketch confirming that the sampled paths continue to satisfy the boundary conditions required by the fundamental theorem of calculus. revision: yes
-
Referee: [Experiments section] The quantitative claim that DiffIG “matches or outperforms existing path-based methods” (abstract) is not supported by any reported metrics, datasets, or statistical tests in the provided text; without these, it is impossible to evaluate whether the perceptual-alignment improvement is real or merely visual.
Authors: The referee is correct that the current draft does not present the quantitative metrics, datasets, or statistical tests that underpin the abstract claim. We will add a dedicated quantitative evaluation subsection (with tables reporting the relevant metrics, the datasets employed, and appropriate statistical tests) to the Experiments section so that the performance comparison is fully documented and reproducible. revision: yes
Circularity Check
No circularity; generative procedure is independently constructed
full rationale
The paper's central claim is a constructive reformulation: train a diffusion model on paths sampled from a Stick-Breaking Process, then apply guided sampling at inference time. This procedure is described as a new training-plus-sampling pipeline and does not reduce any claimed output (attribution quality or path distribution) to a fitted parameter or self-referential definition. No load-bearing self-citations, uniqueness theorems, or ansatzes imported from prior author work appear in the abstract or claim description. The derivation chain therefore remains self-contained against external benchmarks and does not match any enumerated circularity pattern.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Advances in Neural Information Processing Systems (NeurIPS) (2018)
Adebayo, J., Gilmer, J., Muelly, M., Goodfellow, I., Hardt, M., Kim, B.: Sanity checks for saliency maps. In: Advances in Neural Information Processing Systems (NeurIPS) (2018)
2018
-
[2]
Ajay, A., Du, Y., Gupta, A., Tenenbaum, J.B., Jaakkola, T.S., Agrawal, P.: Is conditional generative modeling all you need for decision-making? In: International Conference on Learning Representations (ICLR) (2023)
2023
-
[3]
Princeton University Press (1974)
Aumann, R.J., Shapley, L.S.: Values of non-atomic games. Princeton University Press (1974)
1974
-
[4]
Balduzzi, D., Frean, M., Leary, L., Lewis, J., Ma, K.W.D., McWilliams, B.: The shattered gradients problem: If resnets are the answer, then what is the question? In: International conference on machine learning. pp. 342–350. PMLR (2017)
2017
-
[5]
In: Proceedings of the Twenty-Ninth International Joint Con- ference on Artificial Intelligence (IJCAI)
Bhatt, U., Weller, A., Moura, J.M.: Evaluating and aggregating feature-based model explanations. In: Proceedings of the Twenty-Ninth International Joint Con- ference on Artificial Intelligence (IJCAI). pp. 3016–3022 (2020)
2020
-
[6]
In: International Conference on Learning Representations (ICLR) (2024)
Chen, C., Deng, F., Kawaguchi, K., Gulcehre, C., Ahn, S.: Simple hierarchical planning with diffusion. In: International Conference on Learning Representations (ICLR) (2024)
2024
-
[7]
IEEE Transactions on Intelligent Transportation Systems22(6), 3234–3246 (2021)
Chen, L., Lin, S., Lu, X., Cao, D., Wu, H., Guo, C., Liu, C., Wang, F.Y.: Deep neural network based vehicle and pedestrian detection for autonomous driving: A survey. IEEE Transactions on Intelligent Transportation Systems22(6), 3234–3246 (2021)
2021
-
[8]
In: Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining
Chu, L., Hu, X., Hu, J., Wang, L., Pei, J.: Exact and consistent interpretation for piecewise linear neural networks: A closed form solution. In: Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. pp. 1244–1253 (2018)
2018
-
[9]
In: 2009 IEEE conference on computer vision and pattern recognition
Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: Imagenet: A large- scale hierarchical image database. In: 2009 IEEE conference on computer vision and pattern recognition. pp. 248–255. Ieee (2009)
2009
-
[10]
In: Ad- vances in Neural Information Processing Systems (NeurIPS) (2021)
Dhariwal, P., Nichol, A.: Diffusion models beat gans on image synthesis. In: Ad- vances in Neural Information Processing Systems (NeurIPS) (2021)
2021
-
[11]
In: In- ternational Conference on Learning Representations (2021),https://openreview
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., Houlsby, N.: An image is worth 16x16 words: Transformers for image recognition at scale. In: In- ternational Conference on Learning Representations (2021),https://openreview. net/forum?id=YicbFdNTTy 16 ...
2021
-
[12]
In: Advances in Neural Information Processing Systems (NeurIPS) (2019)
Du, Y., Mordatch, I.: Implicit generation and modeling with energy-based models. In: Advances in Neural Information Processing Systems (NeurIPS) (2019)
2019
-
[13]
International Jour- nal of Game Theory32(4), 501–518 (2004)
Friedman, E.J.: Paths and consistency in additive cost sharing. International Jour- nal of Game Theory32(4), 501–518 (2004)
2004
-
[14]
In: International Conference on Machine Learning (ICML) (2020)
Grathwohl, W., Wang, K.C., Jacobsen, J.H., Duvenaud, D., Zemel, R.: Learning the stein discrepancy for training and evaluating energy-based models without sampling. In: International Conference on Machine Learning (ICML) (2020)
2020
-
[15]
He,K.,Zhang,X.,Ren,S.,Sun,J.:Deepresiduallearningforimagerecognition.In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 770–778 (2016)
2016
-
[16]
Journal of Machine Learning Research24(34), 1–11 (2023)
Hedström, A., Weber, L., Krakowczyk, D., Bareeva, D., Motzkus, F., Samek, W., Lapuschkin, S., Höhne, M.M.C.: Quantus: An explainable ai toolkit for respon- sible evaluation of neural network explanations and beyond. Journal of Machine Learning Research24(34), 1–11 (2023)
2023
-
[17]
In: International conference on learning representations (2017)
Higgins, I., Matthey, L., Pal, A., Burgess, C., Glorot, X., Botvinick, M., Mohamed, S., Lerchner, A.: beta-vae: Learning basic visual concepts with a constrained vari- ational framework. In: International conference on learning representations (2017)
2017
-
[18]
In: Advances in Neural Information Processing Systems (NeurIPS) (2020)
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. In: Advances in Neural Information Processing Systems (NeurIPS) (2020)
2020
-
[19]
Journal of Machine Learning Research6, 695–709 (2005)
Hyvärinen, A.: Estimation of non-normalized statistical models by score matching. Journal of Machine Learning Research6, 695–709 (2005)
2005
-
[20]
In: International Conference on Machine Learning (ICML) (2022)
Janner, M., Du, Y., Tenenbaum, J.B., Levine, S.: Planning with diffusion for flexi- ble behavior synthesis. In: International Conference on Machine Learning (ICML) (2022)
2022
-
[21]
Advances in Neural Information Processing Systems35, 26478–26491 (2022)
Jeon, G., Jeong, H., Choi, J.: Distilled gradient aggregation: Purify features for input attribution in the deep neural network. Advances in Neural Information Processing Systems35, 26478–26491 (2022)
2022
-
[22]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Jeon, G., Jeong, H., Choi, J.: Beyond single path integrated gradients for reliable input attribution via randomized path sampling. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 2052–2061 (2023)
2052
-
[23]
Aicher, J., R
Jha, A., K. Aicher, J., R. Gazzara, M., Singh, D., Barash, Y.: Enhanced integrated gradients: improving interpretability of deep learning models using splicing codes as a case study. Genome biology21(1), 149 (2020)
2020
-
[24]
In: Proceedings of the IEEE/CVF international conference on computer vision
Kapishnikov, A., Bolukbasi, T., Viégas, F., Terry, M.: Xrai: Better attributions through regions. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 4948–4957 (2019)
2019
-
[25]
In: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition
Kapishnikov, A., Venugopalan, S., Avci, B., Wedin, B., Terry, M., Bolukbasi, T.: Guided integrated gradients: An adaptive path method for removing noise. In: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5050–5058 (2021)
2021
-
[26]
In: Forty-second International Conference on Machine Learning (2025)
Kasmi, G., Brunetto, A., Fel, T., Parekh, J.: One wave to explain them all: A uni- fying perspective on feature attribution. In: Forty-second International Conference on Machine Learning (2025)
2025
-
[27]
In: International Conference on Human-Computer Interaction
Kim, S., Choi, J., Choi, Y., Lee, S., Stitsyuk, A., Park, M., Jeong, S., Baek, Y.H., Choi, J.: Explainable ai-based interface system for weather forecasting model. In: International Conference on Human-Computer Interaction. pp. 101–119. Springer (2023)
2023
-
[28]
Kim, S., Lim, S., Lee, K., Choi, J.: Manifold-aligned guided integrated gradients for reliable feature attribution (2026),https://arxiv.org/abs/2605.02167 Diffusion Integrated Gradients 17
Pith/arXiv arXiv 2026
-
[29]
Kim, S., Lim, S., Lee, K., Choi, J.: Spectral integrated gradients for coarse-to-fine feature attribution. In: Proceedings of the 32nd ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD) (2026),http://arxiv.org/abs/ 2605.19607
Pith/arXiv arXiv 2026
-
[30]
Explainable AI: Interpreting, explaining and visualizing deep learning pp
Kindermans, P.J., Hooker, S., Adebayo, J., Alber, M., Schütt, K.T., Dähne, S., Erhan, D., Kim, B.: The (un) reliability of saliency methods. Explainable AI: Interpreting, explaining and visualizing deep learning pp. 267–280 (2019)
2019
-
[31]
In: Forty-second International Conference on Machine Learning (2025),arXivpreprintarXiv:2506.00867
Lee, K., Choi, J.: Local manifold approximation and projection for manifold-aware diffusion planning. In: Forty-second International Conference on Machine Learning (2025),arXivpreprintarXiv:2506.00867
arXiv 2025
-
[32]
In: Advances in Neural Information Processing Systems (NeurIPS) (2025)
Lee, K., Choi, J.: State-covering trajectory stitching for diffusion planners. In: Advances in Neural Information Processing Systems (NeurIPS) (2025)
2025
-
[33]
In: 2023 IEEE International Conference on Robotics and Automation (ICRA)
Lee, K., Kim, S., Choi, J.: Adaptive and explainable deployment of navigation skills via hierarchical deep reinforcement learning. In: 2023 IEEE International Conference on Robotics and Automation (ICRA). pp. 11608–11614. IEEE (2023)
2023
-
[34]
In: Advances in Neural Information Processing Systems (NeurIPS) (2023)
Lee, K., Kim, S., Choi, J.: Refining diffusion planner for reliable behavior synthesis by automatic detection of infeasible plans. In: Advances in Neural Information Processing Systems (NeurIPS) (2023)
2023
-
[35]
arXiv preprint arXiv:2605.03075 (2026)
Lee, K., Luo, Y., Tong, A., Choi, J.: Refining compositional diffusion for reliable long-horizon planning. arXiv preprint arXiv:2605.03075 (2026)
Pith/arXiv arXiv 2026
-
[36]
Advances in Neural Information Pro- cessing Systems37, 54003–54025 (2024)
Lei, Y., Li, Z., Zhang, J., Shan, H.: Denoising diffusion path: Attribution noise reduction with an auxiliary diffusion model. Advances in Neural Information Pro- cessing Systems37, 54003–54025 (2024)
2024
-
[37]
Advances in Neural Information Processing Systems37, 56424–56445 (2024)
Li, T., Tian, Y., Li, H., Deng, M., He, K.: Autoregressive image generation with- out vector quantization. Advances in Neural Information Processing Systems37, 56424–56445 (2024)
2024
-
[38]
In: International Conference on Machine Learning (ICML) (2023)
Li,W.,Wang,X.,Jin,B.,Zha,H.:Hierarchicaldiffusionforofflinedecisionmaking. In: International Conference on Machine Learning (ICML) (2023)
2023
-
[39]
In: International Conference on Machine Learning (ICML) (2023)
Liang, Z., Mu, Y., Ding, M., Ni, F., Tomizuka, M., Luo, P.: Adaptdiffuser: Diffusion models as adaptive self-evolving planners. In: International Conference on Machine Learning (ICML) (2023)
2023
-
[40]
Ad- vances in Neural Information Processing Systems (2023)
Lu, C., Ball, P., Teh, Y.W., Parker-Holder, J.: Synthetic experience replay. Ad- vances in Neural Information Processing Systems (2023)
2023
-
[41]
In: Advances in Neural Information Processing Systems (NeurIPS) (2017)
Lundberg, S.M., Lee, S.I.: A unified approach to interpreting model predictions. In: Advances in Neural Information Processing Systems (NeurIPS) (2017)
2017
-
[42]
Explainable AI: interpreting, explaining and visualizing deep learning pp
Montavon, G., Binder, A., Lapuschkin, S., Samek, W., Müller, K.R.: Layer-wise relevance propagation: an overview. Explainable AI: interpreting, explaining and visualizing deep learning pp. 193–209 (2019)
2019
-
[43]
Advances in Neural Information Pro- cessing Systems32(2019)
Nijkamp,E.,Hill,M.,Zhu,S.C.,Wu,Y.N.:Learningnon-convergentnon-persistent short-run mcmc toward energy-based model. Advances in Neural Information Pro- cessing Systems32(2019)
2019
-
[44]
In: Thirtieth International Joint Conference on Artificial Intelligence (IJCAI) (2021)
Pan, D., Li, X., Zhu, D.: Explaining deep neural network models with adversar- ial gradient integration. In: Thirtieth International Joint Conference on Artificial Intelligence (IJCAI) (2021)
2021
-
[45]
In: 2012 IEEE conference on computer vision and pattern recognition
Parkhi, O.M., Vedaldi, A., Zisserman, A., Jawahar, C.: Cats and dogs. In: 2012 IEEE conference on computer vision and pattern recognition. pp. 3498–3505. IEEE (2012)
2012
-
[46]
In: The British Machine Vision Conference (BMVC) (2018) 18 S
Petsiuk, V., Das, A., Saenko, K.: Rise: Randomized input sampling for explanation of black-box models. In: The British Machine Vision Conference (BMVC) (2018) 18 S. Kim et al
2018
-
[47]
In: ICLR 2022 Workshop on PAIR2Struct: Privacy, Accountability, Interpretability, Robust- ness, Reasoning on Structured Data (2022)
Rahman, M.M., Lewis, N., Plis, S.: Geometrically guided saliency maps. In: ICLR 2022 Workshop on PAIR2Struct: Privacy, Accountability, Interpretability, Robust- ness, Reasoning on Structured Data (2022)
2022
-
[48]
Razzhigaev, A., Shakhmatov, A., Maltseva, A., Arkhipkin, V., Pavlov, I., Ryabov, I., Kuts, A., Panchenko, A., Kuznetsov, A., Dimitrov, D.: Kandinsky: an improved text-to-imagesynthesiswithimagepriorandlatentdiffusion.In:Proceedingsofthe 2023 Conference on Empirical Methods in Natural Language Processing: System Demonstrations (EMNLP) (2023)
2023
-
[49]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 10684– 10695 (June 2022)
2022
-
[50]
Advances in neural information processing systems35, 25278–25294 (2022)
Schuhmann, C., Beaumont, R., Vencu, R., Gordon, C., Wightman, R., Cherti, M., Coombes, T., Katta, A., Mullis, C., Wortsman, M., et al.: Laion-5b: An open large- scale dataset for training next generation image-text models. Advances in neural information processing systems35, 25278–25294 (2022)
2022
-
[51]
Statistica sinica pp
Sethuraman, J.: A constructive definition of dirichlet priors. Statistica sinica pp. 639–650 (1994)
1994
-
[52]
arXiv preprint arXiv:1312.6034 (2014)
Simonyan, K., Vedaldi, A., Zisserman, A.: Deep inside convolutional net- works: Visualising image classification models and saliency maps. arXiv preprint arXiv:1312.6034 (2014)
Pith/arXiv arXiv 2014
-
[53]
In: International Conference on Learning Representations (2015)
Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale im- age recognition. In: International Conference on Learning Representations (2015)
2015
-
[54]
arXiv preprint arXiv:1706.03825 (2017)
Smilkov, D., Thorat, N., Kim, B., Viégas, F., Wattenberg, M.: Smoothgrad: re- moving noise by adding noise. arXiv preprint arXiv:1706.03825 (2017)
Pith/arXiv arXiv 2017
-
[55]
In: International Conference on Machine Learning (ICML) (2015)
Sohl-Dickstein, J., Weiss, E., Maheswaranathan, N., Ganguli, S.: Deep unsuper- vised learning using nonequilibrium thermodynamics. In: International Conference on Machine Learning (ICML) (2015)
2015
-
[56]
In: Advances in Neural Information Processing Systems (NeurIPS) (2019)
Song, Y., Ermon, S.: Generative modeling by estimating gradients of the data distribution. In: Advances in Neural Information Processing Systems (NeurIPS) (2019)
2019
-
[57]
Advances in neural information processing systems32(2019)
Srinivas, S., Fleuret, F.: Full-gradient representation for neural network visualiza- tion. Advances in neural information processing systems32(2019)
2019
-
[58]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Sun, Q., Liu, Y., Chua, T.S., Schiele, B.: Meta-transfer learning for few-shot learn- ing. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 403–412 (2019)
2019
-
[59]
In: International conference on machine learning
Sundararajan, M., Taly, A., Yan, Q.: Axiomatic attribution for deep networks. In: International conference on machine learning. pp. 3319–3328. PMLR (2017)
2017
-
[60]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., Erhan, D., Vanhoucke, V., Rabinovich, A.: Going deeper with convolutions. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 1–9 (2015)
2015
-
[61]
In: International Conference on Learning Representations (ICLR) (2025)
Wang, R., Frans, K., Abbeel, P., Levine, S., Efros, A.A.: Prioritized generative replay. In: International Conference on Learning Representations (ICLR) (2025)
2025
-
[62]
Yang, P., Akhtar, N., Wen, Z., Mian, A.: Local path integration for attribution. Proceedings of the AAAI Conference on Artificial Intelligence37(3), 3173–3180 (Jun 2023).https://doi.org/10.1609/aaai.v37i3.25422,https://ojs.aaai. org/index.php/AAAI/article/view/25422
-
[63]
In: The Eleventh International Conference on Learning Representations (ICLR) (2023) Diffusion Integrated Gradients 19
Yang, P., Akhtar, N., Wen, Z., Shah, M., Mian, A.S.: Re-calibrating feature at- tributions for model interpretation. In: The Eleventh International Conference on Learning Representations (ICLR) (2023) Diffusion Integrated Gradients 19
2023
-
[64]
In: Salakhutdinov, R., Kolter, Z., Heller, K., Weller, A., Oliver, N., Scarlett, J., Berkenkamp, F
Zaher, E., Trzaskowski, M., Nguyen, Q., Roosta, F.: Manifold integrated gradients: Riemannian geometry for feature attribution. In: Salakhutdinov, R., Kolter, Z., Heller, K., Weller, A., Oliver, N., Scarlett, J., Berkenkamp, F. (eds.) Proceedings of the 41st International Conference on Machine Learning. Proceedings of Machine Learning Research, vol. 235, ...
2024
-
[65]
In: The Twelfth International Conference on Learning Represen- tations (2024),https://openreview.net/forum?id=gzYgsZgwXa
Zhang, B., Zheng, W., Zhou, J., Lu, J.: Path choice matters for clear attributions in path methods. In: The Twelfth International Conference on Learning Represen- tations (2024),https://openreview.net/forum?id=gzYgsZgwXa
2024
-
[66]
In: Advances in Neural Information Processing Systems (NeurIPS) (2024)
Zhu, Z., Liu, M., Mao, L., Kang, B., Xu, M., Yu, Y., Ermon, S., Zhang, W.: Madiff: Offline multi-agent learning with diffusion models. In: Advances in Neural Information Processing Systems (NeurIPS) (2024)
2024
-
[67]
Zhuo, Y., Ge, Z.: IG2: Integrated Gradient on Iterative Gradient Path for Fea- ture Attribution . IEEE Transactions on Pattern Analysis & Machine Intelligence 46(11), 7173–7190 (2024).https://doi.org/10.1109/TPAMI.2024.3388092 Supplementary Material for: Diffusion Integrated Gradients: Controllable Path Generation for Flexible Feature Attribution Soyeon K...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.