PS-PPO: Prefix-Sampling PPO for Critic-Free RLHF
Pith reviewed 2026-06-30 07:34 UTC · model grok-4.3
The pith
PS-PPO samples per-trajectory cutoffs and updates only the prefix with importance-weighted gradients that stay unbiased for the full RLHF objective.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PS-PPO introduces a prompt-conditioned cutoff distribution and samples a cutoff timestep for each trajectory. During the update pass, PS-PPO backpropagates only through the sampled prefix of each trajectory and applies an importance-weighting correction so that the resulting truncated gradient estimator remains unbiased with respect to the full-trajectory objective.
What carries the argument
The prompt-conditioned cutoff distribution together with its importance-weighted prefix gradient estimator.
If this is right
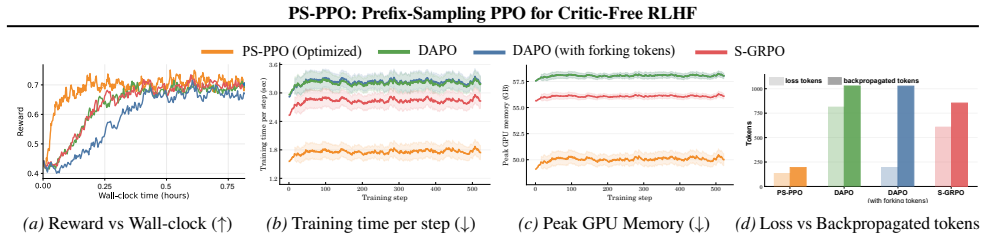
- Training compute and peak GPU memory drop substantially compared with full-trajectory critic-free baselines.
- Accuracy stays comparable on mathematical reasoning and RLHF benchmarks.
- Policy updates no longer require backpropagation through every token of every rollout.
- Temporal redundancy in trajectories can be exploited without changing the underlying RLHF objective.
Where Pith is reading between the lines
- The same prefix-sampling idea could apply to other long-horizon RL problems where early decisions strongly determine later rewards.
- Cutoff distributions might be learned jointly with the policy to further reduce wasted computation on uninformative prefixes.
- The unbiasedness property could be combined with other variance-reduction techniques already used in critic-free methods.
Load-bearing premise
A prompt-conditioned cutoff distribution exists that makes the importance-weighted prefix gradient exactly unbiased for the full-trajectory objective.
What would settle it
A direct comparison on identical rollouts in which the expected gradient produced by PS-PPO differs from the expected gradient of standard full-trajectory PPO.
Figures
read the original abstract
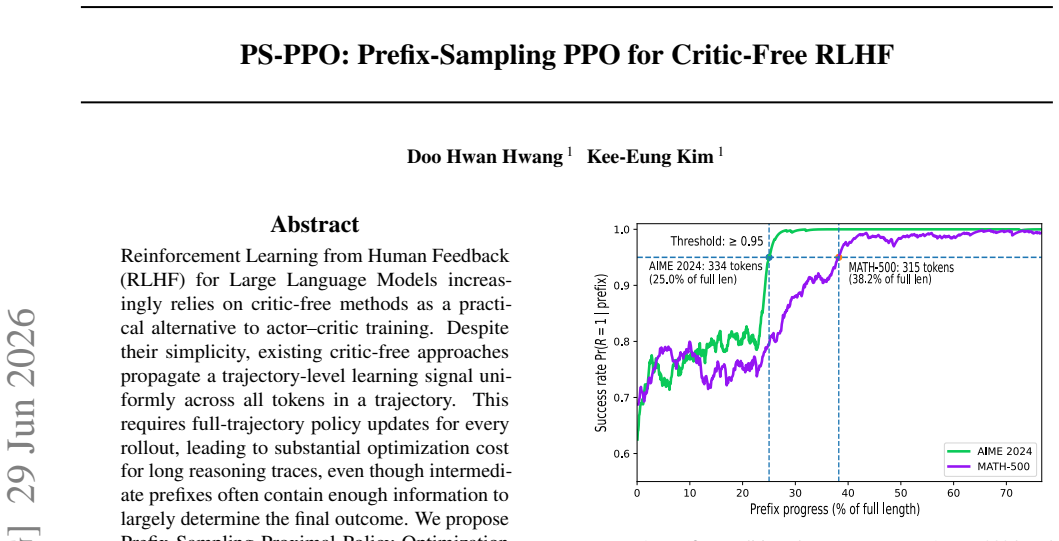
Reinforcement Learning from Human Feedback (RLHF) for Large Language Models increasingly relies on critic-free methods as a practical alternative to actor--critic training. Despite their simplicity, existing critic-free approaches propagate a trajectory-level learning signal uniformly across all tokens in a trajectory. This requires full-trajectory policy updates for every rollout, leading to substantial optimization cost for long reasoning traces, even though intermediate prefixes often contain enough information to largely determine the final outcome. We propose Prefix-Sampling Proximal Policy Optimization (PS-PPO), a compute-efficient critic-free method for RLHF that exploits this temporal redundancy. PS-PPO introduces a prompt-conditioned cutoff distribution and samples a cutoff timestep for each trajectory. During the update pass, PS-PPO backpropagates only through the sampled prefix of each trajectory and applies an importance-weighting correction so that the resulting truncated gradient estimator remains unbiased with respect to the full-trajectory objective. Experiments on mathematical reasoning and RLHF benchmarks show that PS-PPO achieves large reductions in training compute and peak GPU memory, while maintaining accuracy comparable to strong critic-free baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Prefix-Sampling PPO (PS-PPO) for critic-free RLHF. It introduces a prompt-conditioned cutoff distribution from which a cutoff timestep is sampled per trajectory; policy updates are performed only on the sampled prefix, with an importance-weighting correction applied so that the resulting truncated gradient estimator remains unbiased for the full-trajectory objective. Experiments on mathematical reasoning and RLHF benchmarks report substantial reductions in training compute and peak GPU memory while maintaining accuracy comparable to strong critic-free baselines.
Significance. If the unbiasedness property holds, the method would provide a practical route to lower optimization cost and memory footprint in critic-free RLHF for long reasoning traces by exploiting temporal redundancy, without requiring a learned critic.
major comments (2)
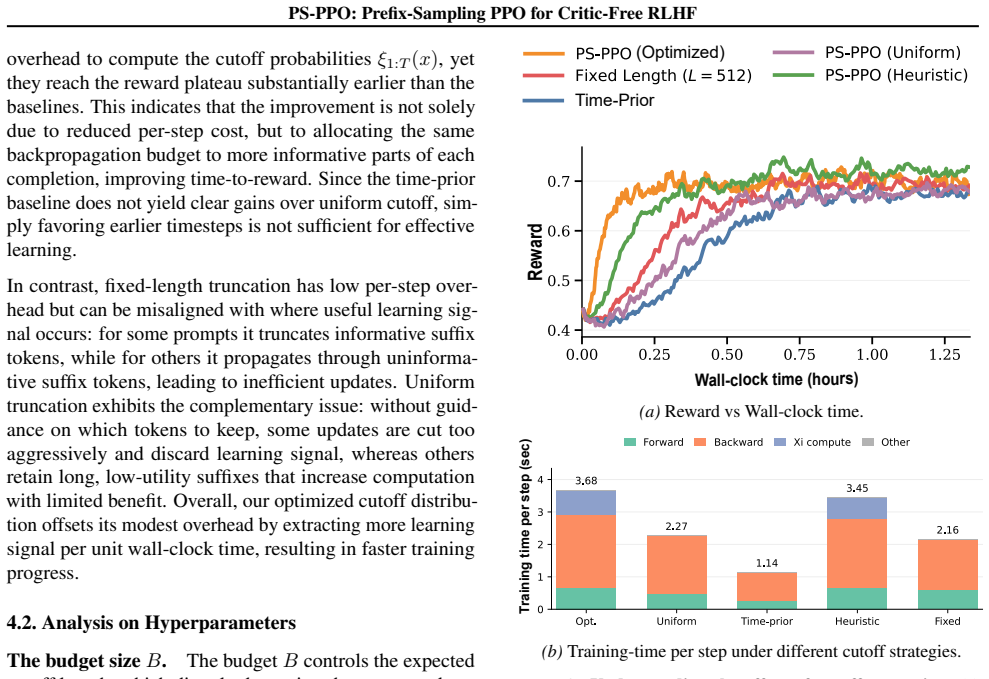
- [Abstract, §3] Abstract and §3 (Method): The central claim that the importance-weighted prefix gradient is exactly unbiased for the full-trajectory objective is load-bearing, yet the manuscript supplies neither the explicit expansion of the expectation nor a proof that E[ w(cut, prompt) · prefix_gradient ] recovers the full-trajectory gradient under the chosen p(cut | prompt). Any mismatch between the Radon-Nikodym derivative induced by the cutoff sampling and the original trajectory measure would render the estimator biased.
- [§4] §4 (Experiments): The reported comparability of accuracy is presented without error bars, statistical significance tests, or ablation on the cutoff distribution itself; this weakens the claim that compute savings are achieved with no degradation, especially given that the unbiasedness property has not been derived.
minor comments (2)
- [§3] Notation for the cutoff distribution p(cut | prompt) and the importance weight should be introduced with a clear definition of the probability space before the gradient estimator is stated.
- [Abstract] The abstract states 'large reductions in training compute' but does not quantify them (e.g., FLOPs or wall-clock time per update); a table or figure with these metrics would improve clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important areas for clarification and strengthening. We address each major comment below and will incorporate the requested additions in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (Method): The central claim that the importance-weighted prefix gradient is exactly unbiased for the full-trajectory objective is load-bearing, yet the manuscript supplies neither the explicit expansion of the expectation nor a proof that E[ w(cut, prompt) · prefix_gradient ] recovers the full-trajectory gradient under the chosen p(cut | prompt). Any mismatch between the Radon-Nikodym derivative induced by the cutoff sampling and the original trajectory measure would render the estimator biased.
Authors: We agree that an explicit derivation is necessary to substantiate the unbiasedness claim. In the revised manuscript we will add a dedicated subsection in §3 that expands the expectation E[w(cut, prompt) · prefix_gradient] and provides a step-by-step proof that the importance-weighted estimator recovers the full-trajectory gradient. The proof will explicitly derive the Radon-Nikodym derivative induced by the prompt-conditioned cutoff distribution and verify that it matches the original trajectory measure, thereby confirming unbiasedness. revision: yes
-
Referee: [§4] §4 (Experiments): The reported comparability of accuracy is presented without error bars, statistical significance tests, or ablation on the cutoff distribution itself; this weakens the claim that compute savings are achieved with no degradation, especially given that the unbiasedness property has not been derived.
Authors: We acknowledge that the current experimental presentation would be strengthened by additional statistical rigor. In the revision we will report error bars from multiple independent runs, include paired statistical significance tests (e.g., Wilcoxon or t-tests) for accuracy comparisons, and add an ablation study varying the cutoff distribution parameters. These changes will be placed in §4 and the associated figures/tables. revision: yes
Circularity Check
No significant circularity; unbiasedness claim rests on standard importance sampling
full rationale
The paper proposes PS-PPO by defining a prompt-conditioned cutoff distribution, sampling prefixes, and applying an importance-weighting correction to restore unbiasedness for the full-trajectory objective. No equations are shown that reduce the claimed unbiased estimator to a fitted parameter or self-defined quantity by construction. No self-citations, ansatz smuggling, or renaming of known results appear in the provided text. The central claim is a novel algorithmic proposal whose correctness depends on an external mathematical property (importance sampling) rather than on any internal reduction to the paper's own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A prompt-conditioned cutoff distribution exists such that importance-weighted prefix gradients are unbiased estimators of the full-trajectory objective.
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , note =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
Communication, Simulation, and Intelligent Agents: Implications of Personal Intelligent Machines for Medical Education
Clancey, William J. Communication, Simulation, and Intelligent Agents: Implications of Personal Intelligent Machines for Medical Education. Proceedings of the Eighth International Joint Conference on Artificial Intelligence (IJCAI-83)
-
[9]
Classification Problem Solving
Clancey, William J. Classification Problem Solving. Proceedings of the Fourth National Conference on Artificial Intelligence
-
[10]
, title =
Robinson, Arthur L. , title =. 1980 , doi =
1980
-
[11]
New Ways to Make Microcircuits Smaller---Duplicate Entry
Robinson, Arthur L. New Ways to Make Microcircuits Smaller---Duplicate Entry. Science
-
[12]
International Journal of Man-Machine Studies , volume = 20, number = 1, pages =
Strategic explanations for a diagnostic consultation system , journal =. 1984 , issn =. doi:https://doi.org/10.1016/S0020-7373(84)80003-6 , author =
-
[13]
and Rennels, Glenn R
Hasling, Diane Warner and Clancey, William J. and Rennels, Glenn R. and Test, Thomas. Strategic Explanations in Consultation---Duplicate. The International Journal of Man-Machine Studies
-
[14]
Poligon: A System for Parallel Problem Solving
Rice, James. Poligon: A System for Parallel Problem Solving
-
[15]
Transfer of Rule-Based Expertise through a Tutorial Dialogue
Clancey, William J. Transfer of Rule-Based Expertise through a Tutorial Dialogue
-
[16]
The Engineering of Qualitative Models
Clancey, William J. The Engineering of Qualitative Models
-
[17]
2017 , eprint=
Attention Is All You Need , author=. 2017 , eprint=
2017
-
[18]
Pluto: The 'Other' Red Planet
NASA. Pluto: The 'Other' Red Planet
-
[19]
Understanding
Liu, Zichen and Chen, Changyu and Li, Wenjun and Qi, Penghui and Pang, Tianyu and Du, Chao and Lee, Wee Sun and Lin, Min , eprint=. Understanding
-
[20]
APO: Enhancing Reasoning Ability of MLLMs via Asymmetric Policy Optimization , author=. 2506.21655 , archivePrefix=
-
[21]
Effective Reinforcement Learning for Reasoning in Language Models , author=. 2505.17218 , archivePrefix=
-
[22]
BNPO: Beta Normalization Policy Optimization , author=. 2506.02864 , archivePrefix=
-
[23]
Yang, An and Zhang, Beichen and Hui, Binyuan and Gao, Bofei and Yu, Bowen and Li, Chengpeng and Liu, Dayiheng and Tu, Jianhong and Zhou, Jingren and Lin, Junyang and others , eprint=
-
[24]
Anil, Rohan and Dai, Andrew M and Firat, Orhan and Johnson, Melvin and Lepikhin, Dmitry and Passos, Alexandre and Shakeri, Siamak and Taropa, Emanuel and Bailey, Paige and Chen, Zhifeng and others , eprint=
-
[25]
Shao, Zhihong and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Song, Junxiao and Bi, Xiao and Zhang, Haowei and Zhang, Mingchuan and Li, YK and Wu, Yang and others , eprint=
-
[26]
A Technical Survey of Reinforcement Learning Techniques for Large Language Models , author=. 2507.04136 , archivePrefix=
-
[27]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word problems , author=. 2110.14168 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Training a helpful and harmless assistant with reinforcement learning from human feedback , author=. 2204.05862 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Li, Jia and Beeching, Edward and Tunstall, Lewis and Lipkin, Ben and Soletskyi, Roman and Huang, Shengyi and Rasul, Kashif and Yu, Longhui and Jiang, Albert Q and Shen, Ziju and others , journal=
-
[30]
Measuring Mathematical Problem Solving With the
Dan Hendrycks and Collin Burns and Saurav Kadavath and Akul Arora and Steven Basart and Eric Tang and Dawn Song and Jacob Steinhardt , booktitle=. Measuring Mathematical Problem Solving With the. 2021 , publisher=
2021
-
[31]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
DAPO: An open-source llm reinforcement learning system at scale , author=. 2503.14476 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. 1707.06347 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. 2501.12948 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
2018 , eprint=
High-Dimensional Continuous Control Using Generalized Advantage Estimation , author=. 2018 , eprint=
2018
-
[35]
Communications of the ACM , volume=
Temporal difference learning and TD-Gammon , author=. Communications of the ACM , volume=
-
[36]
Advances in Neural Information Processing Systems , year=
Training language models to follow instructions with human feedback , author=. Advances in Neural Information Processing Systems , year=
-
[37]
Advances in neural information processing systems , year=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in neural information processing systems , year=
-
[38]
Back to Basics: Revisiting REINFORCE -Style Optimization for Learning from Human Feedback in LLM s
Ahmadian, Arash and Cremer, Chris and Gall. Back to Basics: Revisiting REINFORCE -Style Optimization for Learning from Human Feedback in LLM s. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics. 2024. doi:10.18653/v1/2024.acl-long.662
-
[39]
Bowman , booktitle=
David Rein and Betty Li Hou and Asa Cooper Stickland and Jackson Petty and Richard Yuanzhe Pang and Julien Dirani and Julian Michael and Samuel R. Bowman , booktitle=. 2024 , url=
2024
-
[40]
Math-Shepherd : Verify and Reinforce LLM s Step-by-step without Human Annotations
Wang, Peiyi and Li, Lei and Shao, Zhihong and Xu, Runxin and Dai, Damai and Li, Yifei and Chen, Deli and Wu, Yu and Sui, Zhifang. Math-Shepherd : Verify and Reinforce LLM s Step-by-step without Human Annotations. Association for Computational Linguistics. 2024
2024
-
[41]
International Conference on Machine Learning. 2024
2024
-
[42]
Advances in Neural Information Processing Systems , year=
Policy gradient methods for reinforcement learning with function approximation , author=. Advances in Neural Information Processing Systems , year=
-
[43]
Advances in Neural Information Processing Systems , year=
Language models are few-shot learners , author=. Advances in Neural Information Processing Systems , year=
-
[44]
OpenAI , year=
Language models are unsupervised multitask learners , author=. OpenAI , year=
-
[45]
Jaech, Aaron and Kalai, Adam and Lerer, Adam and Richardson, Adam and El-Kishky, Ahmed and Low, Aiden and Helyar, Alec and Madry, Aleksander and Beutel, Alex and Carney, Alex and others , journal=
-
[46]
OpenAI , year=
Gpt-4 technical report , author=. OpenAI , year=
-
[47]
Grattafiori, Aaron and Dubey, Abhimanyu and Jauhri, Abhinav and Pandey, Abhinav and Kadian, Abhishek and Al-Dahle, Ahmad and Letman, Aiesha and Mathur, Akhil and Schelten, Alan and Vaughan, Alex and others , eprint=. The
-
[48]
International Conference on Learning Representations , year=
Variance Reduction for Reinforcement Learning in Input-Driven Environments , author=. International Conference on Learning Representations , year=
-
[49]
International Conference on Learning Representations , year=
Variance Reduction for Policy Gradient with Action-Dependent Factorized Baselines , author=. International Conference on Learning Representations , year=
-
[50]
International Conference on Machine Learning , year=
The mirage of action-dependent baselines in reinforcement learning , author=. International Conference on Machine Learning , year=
-
[51]
2007 , publisher=
Variance reduction three approaches to control variates , author=. 2007 , publisher=
2007
-
[52]
Operations Research , volume=
Control variate remedies , author=. Operations Research , volume=. 1990 , publisher=
1990
-
[53]
ICLR 2019 Deep Reinforcement Learning meets Structured Prediction Workshop , year=
Buy 4 REINFORCE Samples, Get a Baseline for Free! , author=. ICLR 2019 Deep Reinforcement Learning meets Structured Prediction Workshop , year=
2019
-
[54]
and Hajishirzi, Hannaneh
Lambert, Nathan and Pyatkin, Valentina and Morrison, Jacob and Miranda, LJ and Lin, Bill Yuchen and Chandu, Khyathi and Dziri, Nouha and Kumar, Sachin and Zick, Tom and Choi, Yejin and Smith, Noah A. and Hajishirzi, Hannaneh. R eward B ench: Evaluating Reward Models for Language Modeling. Findings of the Association for Computational Linguistics: NAACL 2025. 2025
2025
-
[55]
Asynchronous Methods for Deep Reinforcement Learning , booktitle =
Volodymyr Mnih and Adri. Asynchronous Methods for Deep Reinforcement Learning , booktitle =. 2016 , url =
2016
-
[56]
International conference on machine learning , publisher=
Addressing function approximation error in actor-critic methods , author=. International conference on machine learning , publisher=. 2018 , organization=
2018
-
[57]
Variance Reduction Techniques for Gradient Estimates in Reinforcement Learning , url =
Greensmith, Evan and Bartlett, Peter and Baxter, Jonathan , booktitle =. Variance Reduction Techniques for Gradient Estimates in Reinforcement Learning , url =. 2001 , publisher=
2001
-
[58]
Proceedings of the Thirty-Third Conference on Uncertainty in Artificial Intelligence , year =
Yang Liu and Prajit Ramachandran and Qiang Liu and Jian Peng , title =. Proceedings of the Thirty-Third Conference on Uncertainty in Artificial Intelligence , year =
-
[59]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , booktitle =
Lianmin Zheng and Wei. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , booktitle =. 2023 , url =
2023
-
[60]
Length-Controlled AlpacaEval:
Yann Dubois and Bal. Length-Controlled AlpacaEval:. CoRR , year =
-
[61]
AGIE val: A Human-Centric Benchmark for Evaluating Foundation Models
Zhong, Wanjun and Cui, Ruixiang and Guo, Yiduo and Liang, Yaobo and Lu, Shuai and Wang, Yanlin and Saied, Amin and Chen, Weizhu and Duan, Nan. AGIE val: A Human-Centric Benchmark for Evaluating Foundation Models. Findings of the Association for Computational Linguistics: NAACL 2024. 2024
2024
-
[62]
Proceedings of the Conference on Robot Learning , pages =
Trajectory-wise Control Variates for Variance Reduction in Policy Gradient Methods , author =. Proceedings of the Conference on Robot Learning , pages =. 2020 , volume =
2020
-
[63]
CoRR , volume =
Liangchen Luo and Yinxiao Liu and Rosanne Liu and Samrat Phatale and Harsh Lara and Yunxuan Li and Lei Shu and Yun Zhu and Lei Meng and Jiao Sun and Abhinav Rastogi , title =. CoRR , volume =. 2024 , url =
2024
-
[64]
The Twelfth International Conference on Learning Representations,
Hunter Lightman and Vineet Kosaraju and Yuri Burda and Harrison Edwards and Bowen Baker and Teddy Lee and Jan Leike and John Schulman and Ilya Sutskever and Karl Cobbe , title =. The Twelfth International Conference on Learning Representations,. 2024 , url =
2024
-
[65]
Solving Quantitative Reasoning Problems with Language Models , year =
Lewkowycz, Aitor and Andreassen, Anders and Dohan, David and Dyer, Ethan and Michalewski, Henryk and Ramasesh, Vinay and Slone, Ambrose and Anil, Cem and Schlag, Imanol and Gutman-Solo, Theo and Wu, Yuhuai and Neyshabur, Behnam and Gur-Ari, Guy and Misra, Vedant , booktitle =. Solving Quantitative Reasoning Problems with Language Models , year =
-
[66]
Forty-first International Conference on Machine Learning , publisher =
Alex James Chan and Hao Sun and Samuel Holt and Mihaela van der Schaar , title =. Forty-first International Conference on Machine Learning , publisher =. 2024 , url =
2024
-
[67]
CoRR , volume =
Yaru Hao and Li Dong and Xun Wu and Shaohan Huang and Zewen Chi and Furu Wei , title =. CoRR , volume =. 2025 , url =
2025
-
[68]
Chang and Wenhao Zhan and Owen Oertell and Gokul Swamy and Kiant
Zhaolin Gao and Jonathan D. Chang and Wenhao Zhan and Owen Oertell and Gokul Swamy and Kiant. Advances in Neural Information Processing Systems , year =
-
[69]
Amirhossein Kazemnejad and Milad Aghajohari and Eva Portelance and Alessandro Sordoni and Siva Reddy and Aaron Courville and Nicolas Le Roux , booktitle=. Vine. 2025 , url=
2025
-
[70]
Forty-first International Conference on Machine Learning , year=
Token-level Direct Preference Optimization , author=. Forty-first International Conference on Machine Learning , year=
-
[71]
American Invitational Mathematics Examination (AIME) , url =
-
[72]
Advances in Neural Information Processing Systems , volume=
Variance reduction techniques for gradient estimates in reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[73]
Backpropagation through the Void: Optimizing control variates for black-box gradient estimation
Backpropagation through the void: Optimizing control variates for black-box gradient estimation , author=. arXiv preprint arXiv:1711.00123 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[74]
Journal of Machine Learning Research , volume=
Monte carlo gradient estimation in machine learning , author=. Journal of Machine Learning Research , volume=
-
[75]
CoRR , volume =
Shenzhi Wang and Le Yu and Chang Gao and Chujie Zheng and Shixuan Liu and Rui Lu and Kai Dang and Xionghui Chen and Jianxin Yang and Zhenru Zhang and Yuqiong Liu and An Yang and Andrew Zhao and Yang Yue and Shiji Song and Bowen Yu and Gao Huang and Junyang Lin , title =. CoRR , volume =. 2025 , url =
2025
-
[76]
Well Begun, Half Done: Reinforcement Learning with Prefix Optimization for
Sun, Yiliu and Zhao, Zicheng and Wei, Yang and Zhang, Yanfang and Gong, Chen , journal=. Well Begun, Half Done: Reinforcement Learning with Prefix Optimization for
-
[77]
CoRR , volume =
Qiying Yu and Zheng Zhang and Ruofei Zhu and Yufeng Yuan and Xiaochen Zuo and Yu Yue and Tiantian Fan and Gaohong Liu and Lingjun Liu and Xin Liu and Haibin Lin and Zhiqi Lin and Bole Ma and Guangming Sheng and Yuxuan Tong and Chi Zhang and Mofan Zhang and Wang Zhang and Hang Zhu and Jinhua Zhu and Jiaze Chen and Jiangjie Chen and Chengyi Wang and Hongli ...
2025
-
[78]
Journal of the American Statistical Association , volume=
A Generalization of Sampling Without Replacement From a Finite Universe , author=. Journal of the American Statistical Association , volume=
-
[79]
Model Assisted Survey Sampling , author=
-
[80]
2024 , note=
Reinforcement Learning from Human Feedback , author=. 2024 , note=
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.