Envisioning Beyond the Few: Disentangled Semantics and Primitives for Few-Shot Atypical Layout-to-Image Generation
Pith reviewed 2026-06-28 22:55 UTC · model grok-4.3
The pith
Disentangling semantics from primitives resolves representation fragmentation in few-shot atypical layout-to-image generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
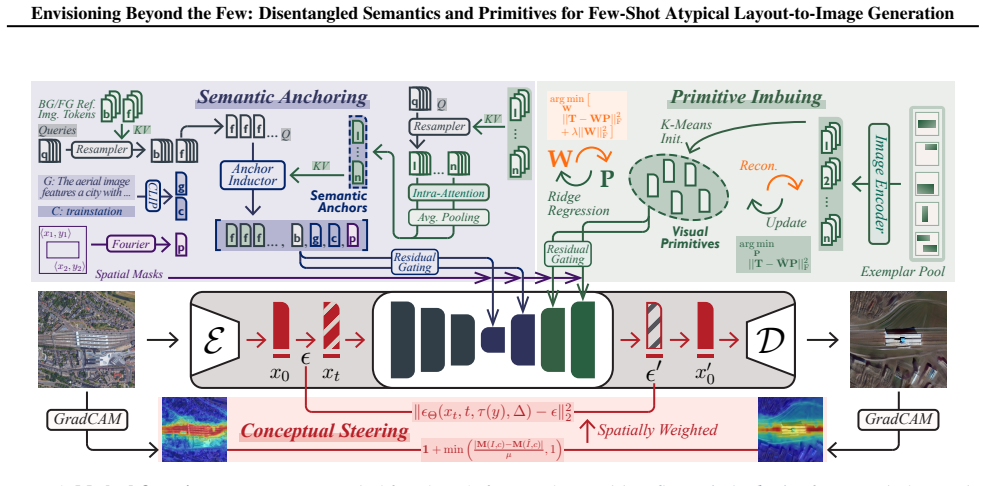
Representation fragmentation arises from a granularity mismatch that entangles semantic identity with visual details, and a representation-driven framework that disentangles semantics from primitives via Semantic Anchoring, Primitive Imbuing, and Conceptual Steering overcomes this mismatch to enable robust few-shot adaptation with improved fidelity and alignment.
What carries the argument
The representation-driven framework consisting of Semantic Anchoring (aggregates categorical semantics into stable identity anchors), Primitive Imbuing (models recomposable primitives for local detail), and Conceptual Steering (regulates optimization via saliency-aware objective to preserve foreground consistency).
If this is right
- Consistent gains in visual fidelity over prior L2I methods in the 5-shot regime.
- Improved object alignment and foreground consistency across multiple atypical domains.
- Robust adaptation achieved without requiring domain-specific tuning beyond the described components.
Where Pith is reading between the lines
- The same separation of identity anchors from local primitives could be tested in other conditional image synthesis tasks that suffer from data scarcity.
- If the granularity mismatch is indeed central, similar disentanglement might reduce failure modes in related structured generation problems such as scene graph to image.
- The saliency-aware steering objective might generalize to other optimization settings where foreground preservation matters under limited supervision.
Load-bearing premise
The granularity mismatch between semantic identity and visual details is the primary cause of failure in few-shot atypical layout-to-image generation, and the three proposed components resolve it without introducing new inconsistencies.
What would settle it
Running the proposed framework on the same 5-shot atypical L2I benchmarks and measuring no gain in visual fidelity or spatial alignment, or the appearance of new distortions, would falsify the central claim.
Figures







read the original abstract
The layout-to-image (L2I) task enables fine-grained control over image generation via object categories and spatial layouts. However, existing L2I methods yield fragmented and distorted generations under few-shot atypical settings. We term this failure as representation fragmentation, arising from a granularity mismatch that entangles semantic identity with visual details. To address this issue, we propose a representation-driven framework that disentangles semantics from primitives for robust few-shot adaptation. Specifically, Semantic Anchoring aggregates categorical semantics into anchors for stable identity, while Primitive Imbuing models recomposable primitives for robust local detail modeling. Conceptual Steering further regulates optimization with a saliency-aware objective to preserve foreground semantic consistency. Extensive experiments demonstrate consistent improvements in the 5-shot regime over state-of-the-art L2I methods in both visual fidelity and alignment across diverse atypical domains. The source code is publicly available at https://github.com/iCVTEAM/DSP.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that existing layout-to-image (L2I) methods suffer from representation fragmentation in few-shot atypical settings due to a granularity mismatch that entangles semantic identity with visual details. It proposes a representation-driven framework with three components—Semantic Anchoring (aggregates categorical semantics into anchors), Primitive Imbuing (models recomposable primitives), and Conceptual Steering (saliency-aware objective for foreground consistency)—to disentangle semantics from primitives. The work reports consistent improvements over state-of-the-art L2I methods in the 5-shot regime for visual fidelity and alignment across diverse atypical domains, with publicly available code.
Significance. If the experimental claims hold with proper validation, the disentangled approach could meaningfully advance few-shot L2I by targeting a specific failure mode in atypical domains. Public code release supports reproducibility and is a positive factor.
major comments (2)
- [Abstract] Abstract: the claim of 'consistent improvements' and 'extensive experiments' is unsupported by any quantitative metrics, baseline comparisons, dataset details, or ablation results in the provided text, preventing assessment of whether gains are load-bearing or due to post-hoc choices.
- [Method (framework description)] The central assumption that granularity mismatch is the primary cause of failure and that the three modules resolve it without new inconsistencies lacks concrete verification; the high-level description does not include equations or pseudocode showing how the components interact or are optimized jointly.
minor comments (1)
- Clarify notation for anchors and primitives to avoid ambiguity across sections.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our submission. We address each of the major comments below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'consistent improvements' and 'extensive experiments' is unsupported by any quantitative metrics, baseline comparisons, dataset details, or ablation results in the provided text, preventing assessment of whether gains are load-bearing or due to post-hoc choices.
Authors: The abstract serves as a high-level summary and conventionally omits detailed metrics to maintain brevity. The full manuscript includes an extensive experimental section with quantitative metrics (FID, LPIPS), baseline comparisons, dataset details for atypical domains, and ablation studies. These substantiate the claims of consistent improvements. We will partially revise the abstract to mention the primary evaluation metrics for better context. revision: partial
-
Referee: [Method (framework description)] The central assumption that granularity mismatch is the primary cause of failure and that the three modules resolve it without new inconsistencies lacks concrete verification; the high-level description does not include equations or pseudocode showing how the components interact or are optimized jointly.
Authors: The abstract provides an overview of the framework. The complete manuscript details the equations for each module (Semantic Anchoring, Primitive Imbuing, Conceptual Steering) and the joint optimization. Ablation experiments verify that the modules address the granularity mismatch effectively. We will add pseudocode to the method section to illustrate component interactions and optimization. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's abstract and described framework introduce a representation-driven approach with three named components (Semantic Anchoring, Primitive Imbuing, Conceptual Steering) to address granularity mismatch in few-shot L2I. No equations, fitted parameters, derivations, or self-citations are present in the supplied text that reduce any claimed prediction or result to the inputs by construction. The central claims rest on the novelty of the disentanglement proposal and experimental improvements, which remain independent of the listed circularity patterns. This is the common case of a self-contained proposal without load-bearing reductions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
doi: 10.48550/ARXIV .2302.08908. Esser, P., Kulal, S., Blattmann, A., Entezari, R., M ¨uller, J., Saini, H., Levi, Y ., Lorenz, D., Sauer, A., Boesel, F., Podell, D., Dockhorn, T., English, Z., and Rombach, R. Scaling rectified flow transformers for high-resolution image synthesis. In Salakhutdinov, R., Kolter, Z., Heller, K. A., Weller, A., Oliver, N., S...
work page internal anchor Pith review doi:10.48550/arxiv 2024
-
[2]
doi: 10.1007/978-3-031-73209-6 \ 15
Springer, 2024. doi: 10.1007/978-3-031-73209-6 \ 15. Kingma, D. P. and Welling, M. Auto-encoding variational bayes. In Bengio, Y . and LeCun, Y . (eds.),2nd Interna- tional Conference on Learning Representations, ICLR 2014, Banff, AB, Canada, April 14-16, 2014, Conference Track Proceedings, 2014. Labs, B. F. Flux. https://github.com/ black-forest-labs/flu...
-
[3]
doi: 10.1109/CVPR52729.2023.02156. Liao, W., Hu, K., Yang, M. Y ., and Rosenhahn, B. Text to image generation with semantic-spatial aware GAN. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022, pp. 18166–18175. IEEE, 2022. doi: 10. 1109/CVPR52688.2022.01765. Lin, T., Maire, M., Belongie, S...
-
[4]
doi: 10.1109/CVPR52729.2023.01469. Liu, N., Li, S., Du, Y ., Torralba, A., and Tenenbaum, J. B. Compositional visual generation with compos- able diffusion models. In Avidan, S., Brostow, G. J., Ciss´e, M., Farinella, G. M., and Hassner, T. (eds.), Computer Vision - ECCV 2022 - 17th European Con- ference, Tel Aviv, Israel, October 23-27, 2022, Pro- ceedin...
-
[5]
Ramesh, A., Pavlov, M., Goh, G., Gray, S., V oss, C., Rad- ford, A., Chen, M., and Sutskever, I
PMLR, 2021. Ramesh, A., Pavlov, M., Goh, G., Gray, S., V oss, C., Rad- ford, A., Chen, M., and Sutskever, I. Zero-shot text-to- image generation. In Meila, M. and Zhang, T. (eds.), Proceedings of the 38th International Conference on Ma- chine Learning, ICML 2021, 18-24 July 2021, Virtual Event, volume 139 ofProceedings of Machine Learning Research, pp. 88...
-
[6]
In: 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
doi: 10.1109/CVPR46437.2021.00089. Zhang, H., Hong, D., Wang, Y ., Shao, J., Wu, X., Wu, Z., and Jiang, Y . Creatilayout: Siamese multimodal diffusion transformer for creative layout-to-image generation. In IEEE/CVF International Conference on Computer Vision, ICCV 2025, Honolulu, HI, USA, October 19-25, 2025, pp. 18487–18497. IEEE, 2025a. doi: 10.1109/IC...
-
[7]
doi: 10.1109/CVPR52729.2023.02154. Zhou, D., Li, Y ., Ma, F., Zhang, X., and Yang, Y . MIGC: multi-instance generation controller for text-to-image synthesis. InIEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, pp. 6818–6828. IEEE, 2024. doi: 10.1109/CVPR52733.2024.00651. Zhou, D., Li, Y ., Ma...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.