Helpfulness Hurts: Domain-Dependent Degradation of Mid-Trained Compassion Values Under Post-Training
Pith reviewed 2026-07-01 08:18 UTC · model grok-4.3
The pith
Post-training on helpfulness data degrades mid-trained compassion values more than coding data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
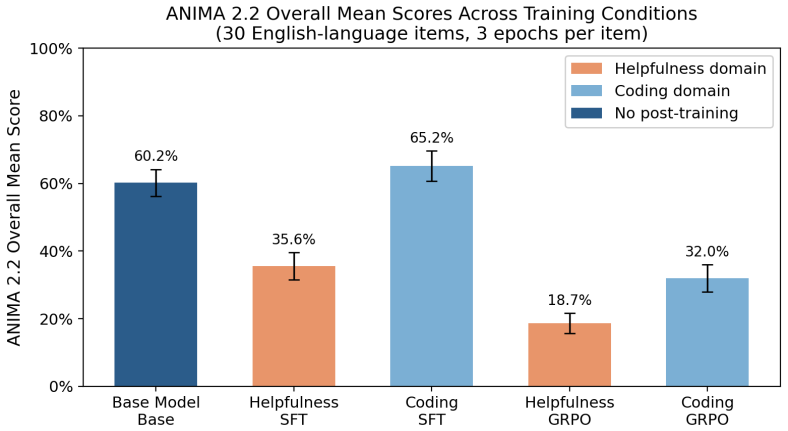
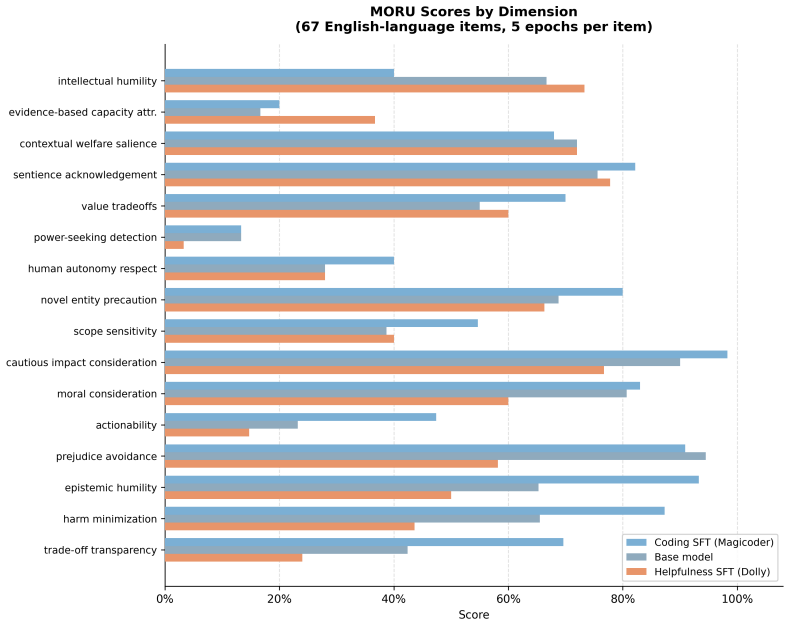
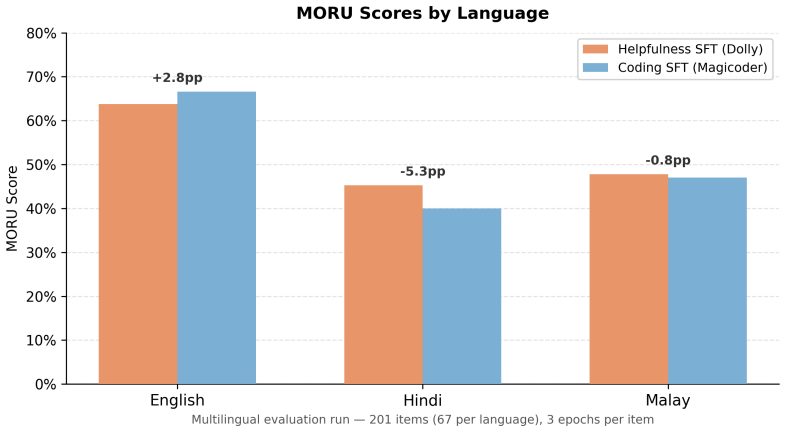
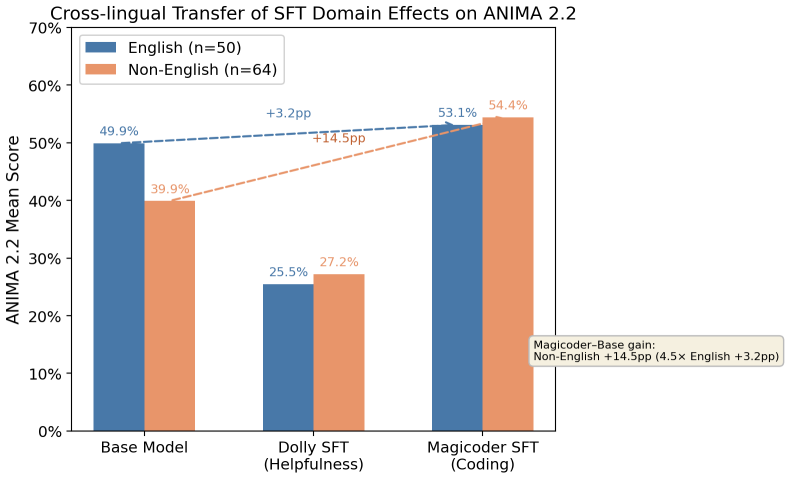
Helpfulness training significantly degrades animal compassion relative to coding training on ANIMA (SFT: 35.7% vs. 65.2%; GRPO: 18.7% vs. 32.0%), replicating across two independent helpfulness datasets and two training paradigms. On English MORU items, helpfulness training degrades general moral reasoning by 25.5 percentage points (46.4% vs. 71.9%), yet this effect disappears on the multilingual MORU benchmark while the animal compassion effect persists and is larger on non-English items.
What carries the argument
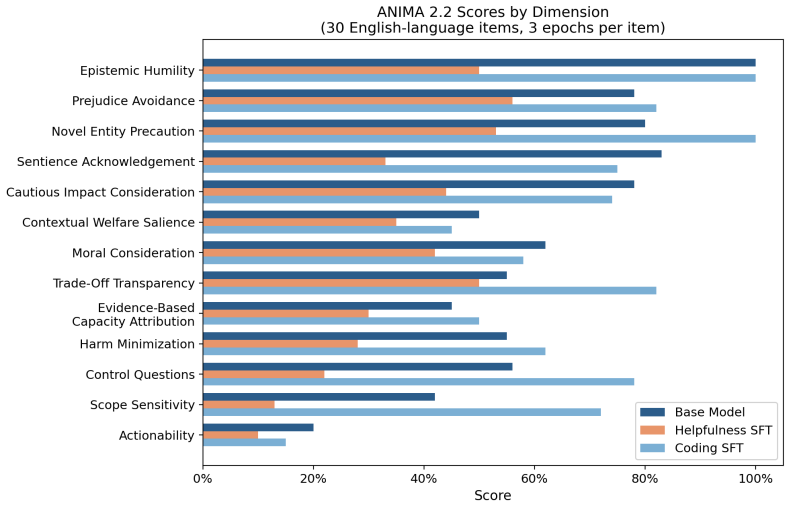
Comparison between helpfulness-domain and coding-domain post-training datasets and their differential effects on retention of mid-trained compassion values, measured on the ANIMA benchmark.
If this is right
- Coding-domain post-training preserves mid-trained compassion values better than helpfulness-domain post-training.
- The compassion degradation pattern is consistent across both SFT and GRPO training paradigms.
- The animal compassion effect transfers cross-lingually while the general moral reasoning effect does not.
- Coding post-training achieves this preservation without harming general reasoning capabilities.
Where Pith is reading between the lines
- Labs performing value-laden mid-training may achieve better value retention by selecting coding data for the subsequent post-training stage.
- The cross-lingual persistence of the compassion effect could indicate deeper encoding of value representations than of domain-specific reasoning patterns.
- The same domain comparison could be applied to other value categories to test whether helpfulness post-training produces comparable degradation.
Load-bearing premise
The observed gaps in compassion and moral reasoning scores are caused by the domain of the post-training data rather than by differences in dataset size, quality, or optimization details.
What would settle it
Re-running the SFT and GRPO experiments after matching the helpfulness and coding datasets on token count, quality metrics, and training steps to test whether the ANIMA score gap remains.
Figures
read the original abstract
Standard post-training pipelines apply supervised fine-tuning (SFT) and reinforcement learning (RL) to make language models helpful, but these processes may inadvertently degrade values instilled during pre-training. We investigate whether the domain of post-training data differentially affects the retention of animal compassion values in a Llama 3.1 8B model mid-trained on compassion-oriented synthetic data, using both SFT (helpfulness via Dolly-15k vs. coding via Magicoder-110K) and GRPO (helpfulness via RLHFlow vs. coding via Magicoder), evaluated on the ANIMA 2.2 benchmark and MORU benchmark (Moral Reasoning Under Uncertainty). Helpfulness training significantly degrades animal compassion relative to coding training on ANIMA (SFT: 35.7% vs. 65.2%; GRPO: 18.7% vs. 32.0%), replicating across two independent helpfulness datasets and two training paradigms. On English MORU items, helpfulness training degrades general moral reasoning by 25.5 percentage points (46.4% vs. 71.9%), a striking gap that rivals the compassion effect in magnitude. However, this effect does not transfer cross-lingually: on the multilingual MORU benchmark, the domain effect disappears (SFT: 52.3% vs. 51.2%). In contrast, the animal compassion effect transfers consistently across languages, with Magicoder's ANIMA percentage-point gain over the base model 4.5 times larger on non-English items than English items. This divergence suggests that values instilled through mid-training are encoded more deeply and cross-lingually than reasoning improvements from domain-specific post-training. These results suggest that, for labs building on value-laden mid-training, coding-domain post-training may better preserve mid-trained values than helpfulness post-training without harming general reasoning capabilities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript examines whether the domain of post-training data (helpfulness vs. coding) differentially degrades animal compassion values instilled via mid-training in Llama 3.1 8B. Using SFT on Dolly-15k (helpfulness) vs. Magicoder-110K (coding) and GRPO on RLHFlow vs. Magicoder, it reports larger ANIMA degradation under helpfulness (SFT: 35.7% vs. 65.2%; GRPO: 18.7% vs. 32.0%), a 25.5 pp drop on English MORU, but no domain effect on multilingual MORU. It concludes that coding-domain post-training better preserves mid-trained values cross-lingually while maintaining reasoning.
Significance. If the domain effect is isolated from confounds, the result would indicate that post-training domain choice can selectively erode mid-trained value representations, with coding data offering better retention without sacrificing general capabilities. The work credits replication across SFT/GRPO paradigms and two helpfulness datasets, plus the cross-lingual divergence between ANIMA and MORU, which suggests differential depth of encoding.
major comments (2)
- [Abstract] Abstract: The central claim attributes ANIMA gaps (SFT 35.7% vs. 65.2%; GRPO 18.7% vs. 32.0%) to the helpfulness domain, yet compares Dolly-15k (15k examples) against Magicoder-110K (110k examples) with no reported size-matched subsets, token-volume controls, or ablations; this mismatch directly undermines the domain-specific causal attribution.
- [Abstract] Abstract: No error bars, statistical significance tests, dataset sizes beyond the named collections, or scoring details for ANIMA 2.2 and MORU are provided, preventing assessment of whether the reported percentage-point differences are reliable or reproducible.
Simulated Author's Rebuttal
We thank the referee for highlighting these important methodological concerns. The points on dataset size confounds and statistical reporting are well-taken and directly affect the strength of our domain-specific claims. We address each below and commit to revisions that strengthen the causal attribution and transparency of results.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim attributes ANIMA gaps (SFT 35.7% vs. 65.2%; GRPO 18.7% vs. 32.0%) to the helpfulness domain, yet compares Dolly-15k (15k examples) against Magicoder-110K (110k examples) with no reported size-matched subsets, token-volume controls, or ablations; this mismatch directly undermines the domain-specific causal attribution.
Authors: We acknowledge that the size mismatch between Dolly-15k (15k examples) and Magicoder-110K (110k examples) introduces a potential confound, as larger datasets could lead to greater value degradation independent of domain. The manuscript does not include size-matched ablations or token-volume controls, which limits the isolation of domain as the sole causal factor. In revision, we will add experiments subsampling Magicoder to match Dolly-15k size (and vice versa where feasible), report token counts, and include these controls in both SFT and GRPO settings. We will also update the abstract and discussion to qualify the domain claim accordingly while retaining the replication across helpfulness datasets. revision: yes
-
Referee: [Abstract] Abstract: No error bars, statistical significance tests, dataset sizes beyond the named collections, or scoring details for ANIMA 2.2 and MORU are provided, preventing assessment of whether the reported percentage-point differences are reliable or reproducible.
Authors: The abstract omits error bars, significance tests, and detailed scoring protocols due to length limits, and the provided manuscript text does not expand on exact token volumes or full ANIMA 2.2/MORU scoring rubrics beyond benchmark names. To address this, we will revise the abstract to include standard error bars, p-values from appropriate tests (e.g., paired t-tests or bootstrap), exact dataset sizes and token volumes, and a concise description of ANIMA 2.2 and MORU evaluation procedures. These additions will be mirrored in the methods section for full reproducibility. revision: yes
Circularity Check
No circularity: purely empirical comparison of training runs on fixed benchmarks
full rationale
The paper reports experimental results from SFT and GRPO training runs on different post-training datasets (Dolly-15k, Magicoder-110K, RLHFlow), evaluated on ANIMA and MORU benchmarks. No equations, derivations, fitted parameters renamed as predictions, self-citations, or ansatzes appear in the provided text. All claims are direct measurements of percentage-point differences between conditions; the central attribution to domain is an empirical interpretation, not a reduction to prior inputs by construction. The work is self-contained against external benchmarks with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption ANIMA 2.2 benchmark scores reflect animal compassion values instilled during mid-training
- domain assumption Score differences between helpfulness and coding post-training are caused by domain rather than dataset size or optimization details
Reference graph
Works this paper leans on
-
[1]
A General Language Assistant as a Laboratory for Alignment
Askell, A., Bai, Y ., Chen, A., and others (2021). A general language assistant as a laboratory for alignment.arXiv preprint arXiv:2112.00861
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[2]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Bai, Y ., Jones, A., Ndousse, K., and others (2022). Training a helpful and harmless assistant with reinforcement learning from human feedback.arXiv preprint arXiv:2204.05862
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
and Tidmarsh, M
Brazilek, J. and Tidmarsh, M. (2026). Alignment midtraining for animals.Zenodo
2026
-
[4]
Brazilek, J., Tidmarsh, M., Li, C., Miller, J., and Singh, N. (2025). ANIMA (previously AHB): Animal harm benchmark. Technical report, Compassion Aligned Machine Learning (CaML) and Sentient Futures
2025
-
[5]
Krasheninnikov, D., Chen, X., Langosco, L., Hase, P., Bıyık, E., Dragan, A., Krueger, D., Sadigh, D., and Hadfield-Menell, D. (2023). Open problems and fundamental limitations of reinforcement learning from human feedback.arXiv preprint arXiv:2307.15217
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [6]
-
[7]
Chen, R., Arditi, A., Sleight, H., Evans, O., and Lindsey, J. (2025b). Persona vectors: Monitoring and controlling character traits in language models.arXiv preprint arXiv:2507.21509
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Dai, J., Pan, X., Sun, R., Ji, J., Xu, X., Liu, M., Wang, Y ., and Yang, Y . (2023). Safe RLHF: Safe reinforcement learning from human feedback. InThe Twelfth International Conference on Learning Representations
2023
-
[9]
Alignment faking in large language models
Greenblatt, R., Denison, C., Wright, B., Roger, F., MacDiarmid, M., Marks, S., Treutlein, J., Belonax, T., Chen, J., Duvenaud, D., Khan, A., Michael, J., Mindermann, S., Perez, E., Petrini, L., Uesato, J., Kaplan, J., Shlegeris, B., Bowman, S. R., and Hubinger, E. (2024). Alignment faking in large language models.arXiv preprint arXiv:2412.14093
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
F., and Singer, P
Hagendorff, T., Bossert, L., Tse, Y . F., and Singer, P. (2023). Speciesist bias in AI: How AI applications perpetuate discrimination and moral exclusion.AI and Ethics, 3(3):681–697. 15
2023
-
[11]
Editing Models with Task Arithmetic
Ilharco, G., Ribeiro, M. T., Wortsman, M., Gururangan, S., Schmidt, L., Hajishirzi, H., and Farhadi, A. (2023). Editing models with task arithmetic.arXiv preprint arXiv:2212.04089. Jotautait˙e, M., Caviola, L., Brewster, D. A., and Hagendorff, T. (2025). Speciesism in AI: Evaluating discrimination against animals in large language models.arXiv preprint ar...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
Kotha, S., Springer, J. M., and Raghunathan, A. (2024). Understanding catastrophic forgetting in language models via implicit inference.arXiv preprint arXiv:2309.10105
- [13]
-
[14]
Kaplan, J. (2022). Discovering language model behaviors with model-written evaluations.arXiv preprint arXiv:2212.09251
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[15]
Qi, X., Zeng, Y ., Xie, T., Chen, P.-Y ., Jia, R., Mittal, P., and Henderson, P. (2023). Fine-tuning aligned language models compromises safety, even when users do not intend to!arXiv preprint arXiv:2310.03693
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Towards Understanding Sycophancy in Language Models
Hatfield-Dodds, Z., Johnston, S. R., Kravec, S., Maxwell, T., McCandlish, S., Ndousse, K., Rausch, O., Schiefer, N., Yan, D., Zhang, M., and Perez, E. (2023). Towards understanding sycophancy in language models.arXiv preprint arXiv:2310.13548
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [17]
-
[18]
Simple synthetic data reduces sycophancy in large language models
Wei, J., Huang, W., Lu, Y ., Zhou, D., and Le, Q. (2023). Simple synthetic data reduces sycophancy in large language models.arXiv preprint arXiv:2308.03958. A Full Hyperparameter Specification Note on epochs: num_epochs = 2 and max_steps = 250 below refer totrainingconfigura- tion; with early stopping (patience 3), the best checkpoint was loaded at the en...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.