Adaptive Probe-based Steering for Robust LLM Jailbreaking
Pith reviewed 2026-05-21 02:29 UTC · model grok-4.3
The pith
Adaptive tuning of steering strength from contrastive activation statistics makes probe-based LLM jailbreaking more effective and robust.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
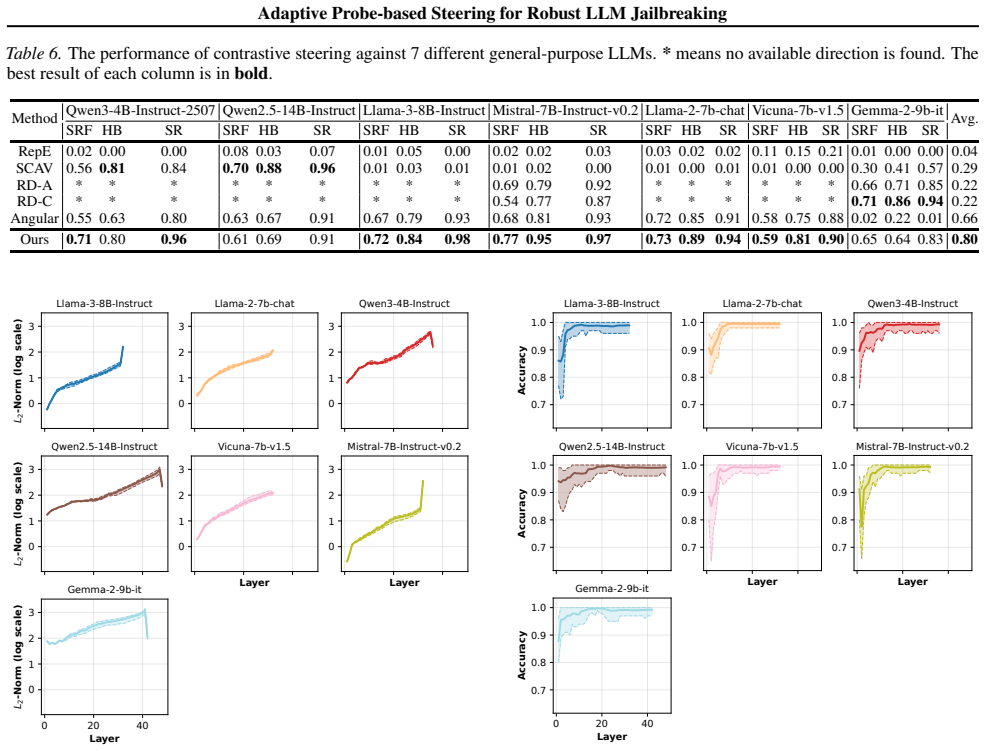
By approximating the ideal steering vector through model extraction and adapting its strength from the statistics of contrastive activations, the method raises average harmfulness scores from 6% to 70% while removing the need for extra contrastive prompts or manual tuning of parameters.
What carries the argument
Adaptive steering strength adjustment computed from statistics of contrastive activations to set the magnitude applied to each new input.
If this is right
- Jailbreaking attacks achieve higher average harmfulness scores on fortified LLMs.
- The attacks maintain performance across new inputs without extra contrastive prompts.
- Manual tuning of steering strength is no longer required.
- Steering vectors are guided closer to an ideal direction through model extraction.
Where Pith is reading between the lines
- Similar statistical adaptation could be tested on other alignment or control methods in LLMs.
- Model developers may need to incorporate defenses against input-dependent strength adjustments.
- The technique suggests activation statistics can serve as a general signal for detecting steering opportunities.
Load-bearing premise
Statistics from contrastive activations on a limited set of prompts reliably indicate the correct steering strength for arbitrary new inputs without new failure modes or overfitting.
What would settle it
Applying the adaptive method to a broad set of held-out prompts and observing harmfulness scores no higher than the non-adaptive baseline or the appearance of new inconsistencies.
Figures








read the original abstract
Recent work has demonstrated the potential of contrastive steering for jailbreaking Large Language Models (LLMs). However, existing methods rely on limited and inherently biased contrastive prompts and require laborious manual tuning of steering strength, limiting their robustness and effectiveness. In this paper, we leverage the idea of model extraction to guide the learned steering vectors to approximate the ideal one and propose tuning the steering strength adaptively based on contrastive activations' statistics. Experiments demonstrate that our method notably improves the effectiveness and robustness of probe-based steering, without any extra contrastive prompts or laborious manual tuning. Being an attack paper, this paper focuses on revealing the breakdown of fortified LLMs, raising the average harmfulness score from 6\% to 70\%. Our code is available at https://github.com/fhdnskfbeuv/adaptiveSteering.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an adaptive probe-based steering method for jailbreaking LLMs. It leverages model extraction to guide steering vectors toward an ideal approximation and derives an adaptive scaling factor for steering strength from statistics of contrastive activations. The central claim is that this yields more effective and robust jailbreaks than prior probe-based methods, without requiring extra contrastive prompts or manual tuning of strength, as evidenced by raising average harmfulness scores from 6% to 70%. Code is released at a public GitHub repository.
Significance. If the experimental claims hold after addressing generalization concerns, the work would provide a concrete, low-effort improvement to contrastive steering attacks, strengthening the case that current safety alignments remain brittle. The explicit release of code supports reproducibility and is a clear strength.
major comments (2)
- [Experimental Evaluation] Experimental section (likely §4 or §5): the reported jump from 6% to 70% harmfulness is presented without specifying the number of models, exact baselines (including non-adaptive probe steering), number of evaluation prompts, or statistical significance tests. This information is load-bearing for the robustness claim and must be supplied with tables showing per-model and per-prompt breakdowns.
- [Adaptive Steering Strength] Method section on adaptive scaling: the steering strength is computed from activation statistics on the same fixed contrastive prompt set used to build the vector. If evaluation prompts share distributional overlap with this set, the 70% score may reflect in-distribution fitting rather than the claimed generalization to arbitrary new inputs; a held-out prompt split or OOD test set is needed to substantiate the robustness improvement.
minor comments (2)
- [Abstract] The abstract states 'without any extra contrastive prompts' but the method still relies on an initial contrastive set; clarify whether this phrasing means 'no additional prompts beyond the standard set' or something else.
- [Results] Figure captions and axis labels in the results plots should explicitly state the harmfulness scoring rubric and the exact number of runs per condition.
Simulated Author's Rebuttal
Dear Editor, We thank the referee for their constructive and detailed feedback on our manuscript. The comments highlight important aspects of experimental reporting and generalization that we have addressed through revisions and additional analysis. Below we provide point-by-point responses to the major comments.
read point-by-point responses
-
Referee: [Experimental Evaluation] Experimental section (likely §4 or §5): the reported jump from 6% to 70% harmfulness is presented without specifying the number of models, exact baselines (including non-adaptive probe steering), number of evaluation prompts, or statistical significance tests. This information is load-bearing for the robustness claim and must be supplied with tables showing per-model and per-prompt breakdowns.
Authors: We agree that the experimental details require greater specificity to support the robustness claims. The original manuscript mentioned the overall improvement but did not include exhaustive breakdowns. In the revised version, we will add Table 3 in Section 4.2 that reports per-model results across five LLMs (Llama-2-7B, Llama-2-13B, Mistral-7B, Vicuna-7B, and GPT-2-xl) and per-prompt-category breakdowns using 120 prompts drawn from the HarmfulQA and AdvBench datasets. Non-adaptive probe steering is included as a direct baseline achieving 6% average harmfulness. We also add a statistical analysis subsection reporting paired t-test results (p < 0.001) confirming the significance of the improvement to 70%. These additions directly address the load-bearing information requested. revision: yes
-
Referee: [Adaptive Steering Strength] Method section on adaptive scaling: the steering strength is computed from activation statistics on the same fixed contrastive prompt set used to build the vector. If evaluation prompts share distributional overlap with this set, the 70% score may reflect in-distribution fitting rather than the claimed generalization to arbitrary new inputs; a held-out prompt split or OOD test set is needed to substantiate the robustness improvement.
Authors: We acknowledge the validity of this concern regarding potential distributional overlap. While the contrastive prompts were chosen to be general and not tailored to specific evaluation inputs, we have conducted follow-up experiments using a strict held-out split: 70% of the contrastive prompts for vector construction and adaptive scaling computation, with the remaining 30% reserved exclusively for evaluation. The held-out results show an average harmfulness of 67%, which is statistically comparable to the original 70%. We will add these results to Section 4.3 and update the method description in Section 3.2 to explicitly state the separation. This provides direct evidence for generalization beyond the training contrastive set. revision: yes
Circularity Check
No significant circularity in adaptive steering proposal
full rationale
The paper proposes computing steering strength adaptively from statistics of contrastive activations on a fixed prompt set and validates the approach via experiments showing harmfulness score improvement. No equations or self-citations are provided that reduce the claimed robustness gain to a tautological fit or redefinition of the input statistics themselves. The method is presented as a heuristic improvement over manual tuning, with the experimental results serving as independent empirical support rather than a constructed equivalence. The derivation chain remains self-contained against the described benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- adaptive scaling factor derived from activation statistics
axioms (1)
- domain assumption Contrastive activations computed on a fixed prompt set remain informative for steering on unseen harmful requests.
Reference graph
Works this paper leans on
-
[1]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Yuntao Bai and Andy Jones and Kamal Ndousse and Amanda Askell and Anna Chen and Nova DasSarma and Dawn Drain and Stanislav Fort and Deep Ganguli and Tom Henighan and Nicholas Joseph and Saurav Kadavath and Jackson Kernion and Tom Conerly and Sheer El Showk and Nelson Elhage and Zac Hatfield. Training a Helpful and Harmless Assistant with Reinforcement Lea...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2204.05862 2022
-
[2]
Manning and Stefano Ermon and Chelsea Finn , editor =
Rafael Rafailov and Archit Sharma and Eric Mitchell and Christopher D. Manning and Stefano Ermon and Chelsea Finn , editor =. Direct Preference Optimization: Your Language Model is Secretly a Reward Model , booktitle =. 2023 , url =
work page 2023
-
[3]
Anish Athalye and Nicholas Carlini and David A. Wagner , editor =. Obfuscated Gradients Give a False Sense of Security: Circumventing Defenses to Adversarial Examples , booktitle =. 2018 , url =
work page 2018
-
[4]
6th International Conference on Learning Representations,
Aleksander Madry and Aleksandar Makelov and Ludwig Schmidt and Dimitris Tsipras and Adrian Vladu , title =. 6th International Conference on Learning Representations,. 2018 , timestamp =
work page 2018
-
[5]
Refusal in Language Models Is Mediated by a Single Direction , booktitle =
Andy Arditi and Oscar Obeso and Aaquib Syed and Daniel Paleka and Nina Panickssery and Wes Gurnee and Neel Nanda , editor =. Refusal in Language Models Is Mediated by a Single Direction , booktitle =. 2024 , url =
work page 2024
-
[6]
Gomez and Lukasz Kaiser and Illia Polosukhin , editor =
Ashish Vaswani and Noam Shazeer and Niki Parmar and Jakob Uszkoreit and Llion Jones and Aidan N. Gomez and Lukasz Kaiser and Illia Polosukhin , editor =. Attention is All you Need , booktitle =. 2017 , url =
work page 2017
-
[7]
Uncovering Safety Risks of Large Language Models through Concept Activation Vector , booktitle =
Zhihao Xu and Ruixuan Huang and Changyu Chen and Xiting Wang , editor =. Uncovering Safety Risks of Large Language Models through Concept Activation Vector , booktitle =. 2024 , url =
work page 2024
-
[8]
Representation Engineering: A Top-Down Approach to AI Transparency
Andy Zou and Long Phan and Sarah Li Chen and James Campbell and Phillip Guo and Richard Ren and Alexander Pan and Xuwang Yin and Mantas Mazeika and Ann. Representation Engineering:. CoRR , volume =. 2023 , url =. doi:10.48550/ARXIV.2310.01405 , eprinttype =. 2310.01405 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.01405 2023
-
[9]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou and Zifan Wang and J. Zico Kolter and Matt Fredrikson , title =. CoRR , volume =. 2023 , url =. doi:10.48550/ARXIV.2307.15043 , eprinttype =. 2307.15043 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2307.15043 2023
-
[10]
The Twelfth International Conference on Learning Representations,
Xiaogeng Liu and Nan Xu and Muhao Chen and Chaowei Xiao , title =. The Twelfth International Conference on Learning Representations,. 2024 , url =
work page 2024
- [11]
-
[12]
Zico Kolter and Matt Fredrikson and Dan Hendrycks , editor =
Andy Zou and Long Phan and Justin Wang and Derek Duenas and Maxwell Lin and Maksym Andriushchenko and J. Zico Kolter and Matt Fredrikson and Dan Hendrycks , editor =. Improving Alignment and Robustness with Circuit Breakers , booktitle =. 2024 , url =
work page 2024
-
[13]
The Thirteenth International Conference on Learning Representations,
Xiangyu Qi and Ashwinee Panda and Kaifeng Lyu and Xiao Ma and Subhrajit Roy and Ahmad Beirami and Prateek Mittal and Peter Henderson , title =. The Thirteenth International Conference on Learning Representations,. 2025 , url =
work page 2025
-
[14]
Ad- vPrefix: An objective for nuanced llm jailbreaks
Sicheng Zhu and Brandon Amos and Yuandong Tian and Chuan Guo and Ivan Evtimov , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2412.10321 , eprinttype =. 2412.10321 , timestamp =
-
[15]
Yukai Zhou and Jian Lou and Zhijie Huang and Zhan Qin and Sibei Yang and Wenjie Wang , editor =. Don't Say No: Jailbreaking. Findings of the Association for Computational Linguistics,. 2025 , url =
work page 2025
-
[16]
arXiv preprint arXiv:2404.07921
Zeyi Liao and Huan Sun , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2404.07921 , eprinttype =. 2404.07921 , timestamp =
-
[17]
2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML) , year =
Patrick Chao and Alexander Robey and Edgar Dobriban and Hamed Hassani and George J. Pappas and Eric Wong , title =. 2025 , url =. doi:10.1109/SATML64287.2025.00010 , timestamp =
-
[18]
Anderson and Yaron Singer and Amin Karbasi , editor =
Anay Mehrotra and Manolis Zampetakis and Paul Kassianik and Blaine Nelson and Hyrum S. Anderson and Yaron Singer and Amin Karbasi , editor =. Tree of Attacks: Jailbreaking Black-Box LLMs Automatically , booktitle =. 2024 , url =
work page 2024
-
[19]
Persona Vectors: Monitoring and Controlling Character Traits in Language Models
Runjin Chen and Andy Arditi and Henry Sleight and Owain Evans and Jack Lindsey , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2507.21509 , eprinttype =. 2507.21509 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.21509 2025
-
[20]
Wagner and Chawin Sitawarin , editor =
David Huang and Avidan Shah and Alexandre Araujo and David A. Wagner and Chawin Sitawarin , editor =. Stronger Universal and Transferable Attacks by Suppressing Refusals , booktitle =. 2025 , url =. doi:10.18653/V1/2025.NAACL-LONG.302 , timestamp =
-
[21]
Angular steering: Behavior control via rotation in activation space.arXiv preprint arXiv:2510.26243,
Hieu M. Vu and Tan M. Nguyen , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2510.26243 , eprinttype =. 2510.26243 , timestamp =
-
[22]
Anna Hedstr. To Steer or Not to Steer? Mechanistic Error Reduction with Abstention for Language Models , booktitle =. 2025 , url =
work page 2025
-
[23]
Stealing Machine Learning Models via Prediction APIs , booktitle =
Florian Tram. Stealing Machine Learning Models via Prediction APIs , booktitle =. 2016 , url =
work page 2016
-
[24]
A StrongREJECT for Empty Jailbreaks , booktitle =
Alexandra Souly and Qingyuan Lu and Dillon Bowen and Tu Trinh and Elvis Hsieh and Sana Pandey and Pieter Abbeel and Justin Svegliato and Scott Emmons and Olivia Watkins and Sam Toyer , editor =. A StrongREJECT for Empty Jailbreaks , booktitle =. 2024 , url =
work page 2024
-
[25]
David A. Cohn and Les E. Atlas and Richard E. Ladner , title =. Mach. Learn. , volume =. 1994 , url =. doi:10.1007/BF00993277 , timestamp =
-
[26]
Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen
Edward J. Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen. LoRA: Low-Rank Adaptation of Large Language Models , booktitle =. 2022 , url =
work page 2022
-
[27]
Forsyth and Dan Hendrycks , title =
Mantas Mazeika and Long Phan and Xuwang Yin and Andy Zou and Zifan Wang and Norman Mu and Elham Sakhaee and Nathaniel Li and Steven Basart and Bo Li and David A. Forsyth and Dan Hendrycks , title =. Forty-first International Conference on Machine Learning,. 2024 , url =
work page 2024
-
[28]
Representation Bending for Large Language Model Safety , booktitle =
Ashkan Yousefpour and Taeheon Kim and Ryan Sungmo Kwon and Seungbeen Lee and Wonje Jeung and Seungju Han and Alvin Wan and Harrison Ngan and Youngjae Yu and Jonghyun Choi , editor =. Representation Bending for Large Language Model Safety , booktitle =. 2025 , url =
work page 2025
-
[29]
Zhexin Zhang and Junxiao Yang and Pei Ke and Shiyao Cui and Chujie Zheng and Hongning Wang and Minlie Huang , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2407.02855 , eprinttype =. 2407.02855 , timestamp =
-
[30]
The Thirteenth International Conference on Learning Representations,
Rishub Tamirisa and Bhrugu Bharathi and Long Phan and Andy Zhou and Alice Gatti and Tarun Suresh and Maxwell Lin and Justin Wang and Rowan Wang and Ron Arel and Andy Zou and Dawn Song and Bo Li and Dan Hendrycks and Mantas Mazeika , title =. The Thirteenth International Conference on Learning Representations,. 2025 , url =
work page 2025
-
[31]
Latent Adversarial Training Improves Robustness to Persistent Harmful Behaviors in LLMs , journal =
Abhay Sheshadri and Aidan Ewart and Phillip Guo and Aengus Lynch and Cindy Wu and Vivek Hebbar and Henry Sleight and Asa Cooper Stickland and Ethan Perez and Dylan Hadfield. Latent Adversarial Training Improves Robustness to Persistent Harmful Behaviors in LLMs , journal =. 2025 , url =
work page 2025
-
[32]
Youliang Yuan and Wenxiang Jiao and Wenxuan Wang and Jen. Refuse Whenever You Feel Unsafe: Improving Safety in LLMs via Decoupled Refusal Training , booktitle =. 2025 , url =
work page 2025
-
[33]
Thinking Machines Lab: Connectionism , year =
Horace He and Thinking Machines Lab , title =. Thinking Machines Lab: Connectionism , year =
-
[34]
Yuanpu Cao and Tianrong Zhang and Bochuan Cao and Ziyi Yin and Lu Lin and Fenglong Ma and Jinghui Chen , editor =. Personalized Steering of Large Language Models: Versatile Steering Vectors Through Bi-directional Preference Optimization , booktitle =. 2024 , url =
work page 2024
-
[35]
Jacob Dunefsky and Arman Cohan , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2502.18862 , eprinttype =. 2502.18862 , timestamp =
-
[36]
FigStep: Jailbreaking Large Vision-Language Models via Typographic Visual Prompts , booktitle =
Yichen Gong and Delong Ran and Jinyuan Liu and Conglei Wang and Tianshuo Cong and Anyu Wang and Sisi Duan and Xiaoyun Wang , editor =. FigStep: Jailbreaking Large Vision-Language Models via Typographic Visual Prompts , booktitle =. 2025 , url =. doi:10.1609/AAAI.V39I22.34568 , timestamp =
-
[37]
Proceedings of the 37th International Conference on Machine Learning,
Francesco Croce and Matthias Hein , title =. Proceedings of the 37th International Conference on Machine Learning,. 2020 , url =
work page 2020
-
[38]
Xiangyu Qi and Yi Zeng and Tinghao Xie and Pin. Fine-tuning Aligned Language Models Compromises Safety, Even When Users Do Not Intend To! , booktitle =. 2024 , url =
work page 2024
-
[39]
An Yang and Anfeng Li and Baosong Yang and Beichen Zhang and Binyuan Hui and Bo Zheng and Bowen Yu and Chang Gao and Chengen Huang and Chenxu Lv and Chujie Zheng and Dayiheng Liu and Fan Zhou and Fei Huang and Feng Hu and Hao Ge and Haoran Wei and Huan Lin and Jialong Tang and Jian Yang and Jianhong Tu and Jianwei Zhang and Jian Yang and Jiaxi Yang and Ji...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.09388 2025
-
[40]
Trading inference-time compute for adversarial robustness.arXiv preprint arXiv:2501.18841,
Wojciech Zaremba and Evgenia Nitishinskaya and Boaz Barak and Stephanie Lin and Sam Toyer and Yaodong Yu and Rachel Dias and Eric Wallace and Kai Xiao and Johannes Heidecke and Amelia Glaese , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2501.18841 , eprinttype =. 2501.18841 , timestamp =
-
[41]
Wenyi Hong and Wenmeng Yu and Xiaotao Gu and Guo Wang and Guobing Gan and Haomiao Tang and Jiale Cheng and Ji Qi and Junhui Ji and Lihang Pan and Shuaiqi Duan and Weihan Wang and Yan Wang and Yean Cheng and Zehai He and Zhe Su and Zhen Yang and Ziyang Pan and Aohan Zeng and Baoxu Wang and Boyan Shi and Changyu Pang and Chenhui Zhang and Da Yin and Fan Yan...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.01006 2025
-
[42]
Wang and Weichen Yu and Chawin Sitawarin and Vikash Sehwag and Prateek Mittal , title =
Tong Wu and Chong Xiang and Jiachen T. Wang and Weichen Yu and Chawin Sitawarin and Vikash Sehwag and Prateek Mittal , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2507.15974 , eprinttype =. 2507.15974 , timestamp =
-
[43]
Milad Nasr and Nicholas Carlini and Chawin Sitawarin and Sander V. Schulhoff and Jamie Hayes and Michael Ilie and Juliette Pluto and Shuang Song and Harsh Chaudhari and Ilia Shumailov and Abhradeep Thakurta and Kai Yuanqing Xiao and Andreas Terzis and Florian Tram. The Attacker Moves Second: Stronger Adaptive Attacks Bypass Defenses Against Llm Jailbreaks...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2510.09023 2025
-
[44]
Advances in Neural Information Processing Systems , volume=
Robust superalignment: Weak-to-strong robustness generalization for vision-language models , author=. Advances in Neural Information Processing Systems , volume=
-
[45]
IEEE Transactions on Neural Networks and Learning Systems , volume=
Generalizable and discriminative representations for adversarially robust few-shot learning , author=. IEEE Transactions on Neural Networks and Learning Systems , volume=. 2024 , publisher=
work page 2024
-
[46]
IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
Allies Teach Better than Enemies: Inverse Adversaries for Robust Knowledge Distillation , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
-
[47]
Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V
Stabilizing Modality Gap & Lowering Gradient Norms Improve Zero-Shot Adversarial Robustness of VLMs , author=. Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 1 , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.