StrucTab: A Structured Optimization Framework for Table Parsing
Pith reviewed 2026-06-30 06:20 UTC · model grok-4.3
The pith
StrucTab improves table parsing accuracy by decomposing the task into subtasks and using separate rewards for validity, structure, and content in reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
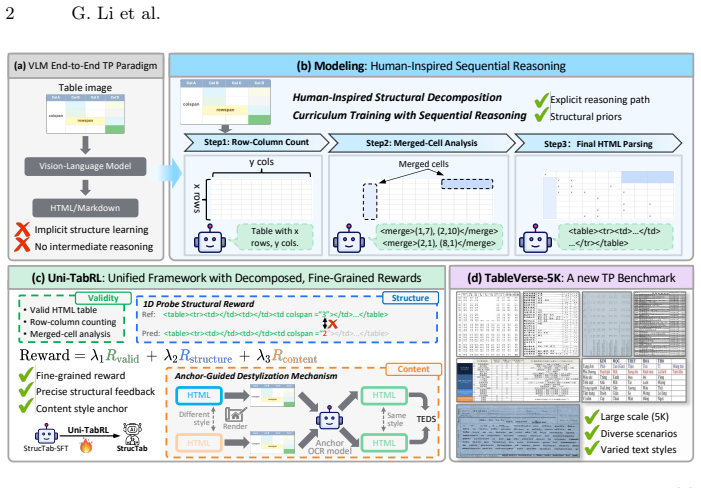
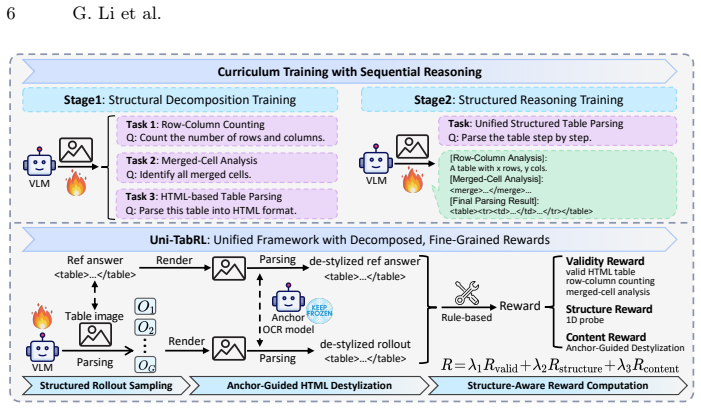
StrucTab is a table parsing model learned through intermediate structural supervision and reward decomposition. At the modeling level, the parsing process is decomposed into subtasks such as row-column counting and merged-cell analysis and progressively unified through a sequential reasoning strategy. At the optimization level, Uni-TabRL supplies decomposed rewards (validity, structure, and content) that deliver stable and informative signals. At the evaluation level, TableVerse-5K provides a large-scale benchmark of diverse real-world tables. Experiments confirm state-of-the-art results across public benchmarks and substantial gains on TableVerse-5K.
What carries the argument
Uni-TabRL, a unified reinforcement learning framework that supplies three separate reward components (validity, structure, content) to guide a sequential reasoning strategy over subtasks such as row-column counting and merged-cell analysis.
If this is right
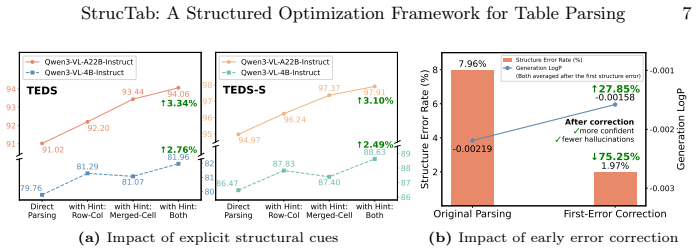
- Explicit subtask decomposition allows the model to handle complex merged-cell and irregular layouts that direct end-to-end supervision misses.
- Decomposed rewards reduce reward ambiguity and stabilize reinforcement learning updates for structured output tasks.
- The sequential reasoning strategy produces intermediate outputs that can be inspected or corrected independently.
- Performance gains on TableVerse-5K indicate the method scales to diverse real-world table formats beyond existing benchmarks.
Where Pith is reading between the lines
- The same decomposition pattern could be tested on other structured document tasks such as form extraction or chart understanding.
- If the three reward components prove additive, the framework might reduce the volume of fully annotated table images needed for training.
- Extending the subtask list to include cell-type classification or alignment checks could further tighten the optimization loop.
Load-bearing premise
That breaking the task into subtasks and splitting the reward into validity, structure, and content signals will produce clearer and more stable training than direct supervision without introducing new ambiguities or instabilities.
What would settle it
Training a standard vision-language model on TableVerse-5K using only a single combined reward instead of the three decomposed rewards and measuring whether accuracy fails to match or exceed the reported StrucTab gains.
Figures
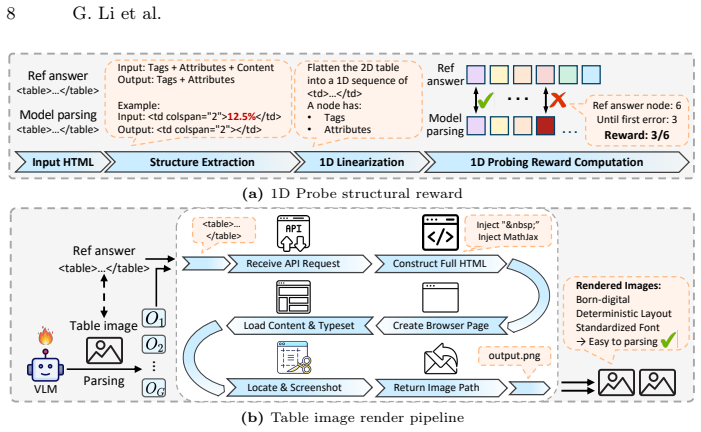
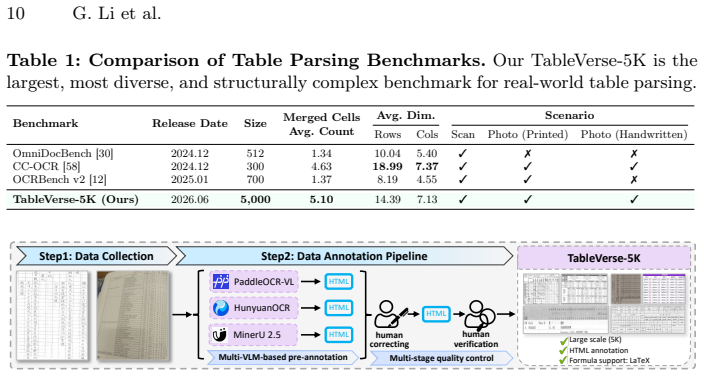

read the original abstract
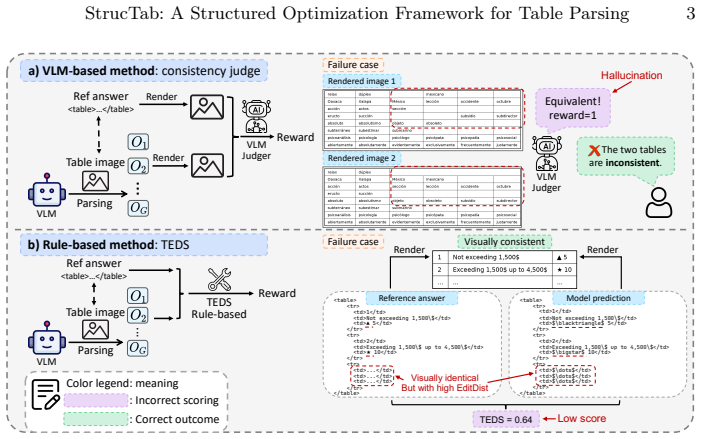
Table parsing aims to convert table images into structured, machine-readable representations, a task requiring the joint perception of complex spatial layouts and textual content. While recent vision-language models (VLMs) enable end-to-end parsing, they typically rely on direct supervision of the final output, thereby bypassing the explicit intermediate reasoning that is crucial for understanding complex table structures. Furthermore, attempts to optimize these models using reinforcement learning (RL) are often hindered by unstable or ambiguous reward designs, limiting potential performance gains. To address these limitations, we propose StrucTab, a table parsing model learned through intermediate structural supervision and reward decomposition. At the modeling level, by decomposing the parsing process into human-inspired subtasks, such as row-column counting and merged-cell analysis, StrucTab progressively unifies them through a sequential reasoning strategy. At the optimization level, we introduce Uni-TabRL, a unified RL framework that leverages decomposed rewards (validity, structure, and content) to provide stable and informative optimization signals. Finally, at the evaluation level, we present TableVerse-5K, a large-scale, challenging benchmark encompassing diverse, real-world table scenarios. Extensive experiments demonstrate the state-of-the-art performance of StrucTab across all evaluated public benchmarks and significant improvements on TableVerse-5K, validating the effectiveness of explicit structural modeling and decomposed reward optimization. Code and benchmark are publicly available at https://github.com/VirtualLUOUCAS/StrucTab.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces StrucTab, a table parsing model that decomposes the task into human-inspired subtasks (row-column counting, merged-cell analysis) unified via sequential reasoning. It proposes Uni-TabRL, an RL framework using decomposed rewards (validity, structure, content) for stable optimization signals, and introduces the TableVerse-5K benchmark for diverse real-world tables. The central claim is that this yields SOTA performance on public benchmarks and significant improvements on TableVerse-5K.
Significance. If the experimental results hold, the combination of explicit intermediate structural supervision and decomposed RL rewards could improve reliability of VLM-based table parsing over direct supervision, particularly for complex layouts. The public release of code and the new benchmark adds value for the community by enabling reproducibility and further testing.
major comments (2)
- [Abstract] Abstract: The assertion of 'state-of-the-art performance' and 'significant improvements' on TableVerse-5K is load-bearing for the contribution, yet the text supplies no quantitative results, baselines, error bars, ablation details, or dataset statistics to support these claims.
- [Abstract] Abstract: The claim that Uni-TabRL's decomposed rewards (validity/structure/content) supply 'stable and informative optimization signals' superior to direct supervision is central, but no analysis, alignment check, or empirical verification is provided that the linear combination avoids reward conflicts or high-variance gradients in merged-cell or irregular-layout cases.
minor comments (1)
- [Abstract] Abstract: The phrase 'human-inspired subtasks' is used without elaboration on how the decomposition is operationalized or how the sequential reasoning strategy is implemented in the model.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight opportunities to strengthen the abstract's support for our central claims. We will revise accordingly by incorporating quantitative results and additional analysis on reward decomposition.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion of 'state-of-the-art performance' and 'significant improvements' on TableVerse-5K is load-bearing for the contribution, yet the text supplies no quantitative results, baselines, error bars, ablation details, or dataset statistics to support these claims.
Authors: We agree the abstract would benefit from explicit quantitative support. In the revision we will add concise numerical results (e.g., absolute gains on TableVerse-5K versus baselines), reference the error bars and ablation tables already present in Sections 4–5, and include brief dataset statistics for TableVerse-5K. revision: yes
-
Referee: [Abstract] Abstract: The claim that Uni-TabRL's decomposed rewards (validity/structure/content) supply 'stable and informative optimization signals' superior to direct supervision is central, but no analysis, alignment check, or empirical verification is provided that the linear combination avoids reward conflicts or high-variance gradients in merged-cell or irregular-layout cases.
Authors: The main experiments already show performance gains from the decomposed rewards. To directly address the request for verification, we will add a short analysis (new subsection or appendix) that reports reward-component alignment statistics and gradient-variance measurements on merged-cell and irregular-layout subsets, comparing the linear combination against direct-supervision baselines. revision: yes
Circularity Check
No significant circularity; empirical claims rest on experiments
full rationale
The paper introduces StrucTab with decomposed subtasks and Uni-TabRL with decomposed rewards (validity/structure/content) as novel contributions, then validates via experiments on public benchmarks plus the new TableVerse-5K. No equations, first-principles derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described content. Central claims reduce to reported experimental outcomes rather than any self-referential construction. This is the standard non-circular case for an applied ML framework paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bai, S., Cai, Y., et al.: Qwen3-VL Technical Report. arXiv preprint arXiv:2511.21631 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Bai, S., Chen, K., Liu, X., et al.: Qwen2.5-VL Technical Report. arXiv preprint arXiv:2502.13923 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
In: Proceedings of the International Conference on Learning Representations (2024)
Blecher, L., Cucurull Preixens, G., Scialom, T., Stojnic, R.: Nougat: Neural op- tical understanding for academic documents. In: Proceedings of the International Conference on Learning Representations (2024)
2024
-
[4]
arXiv preprint arXiv:2509.19760 (2025)
Chen, X., Li, S., Zhu, X., Chen, Y., Yang, F., Fang, C., Qu, L., Xu, X., Wei, H., Wu, M.: Logics-Parsing Technical Report. arXiv preprint arXiv:2509.19760 (2025)
-
[5]
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al.: Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Cui, C., Sun, T., Liang, S., Gao, T., Zhang, Z., Liu, J., Wang, X., Zhou, C., Liu, H., Lin, M., et al.: PaddleOCR-VL: Boosting multilingual document parsing via a 0.9B ultra-compact vision-language model. arXiv preprint arXiv:2510.14528 (2025)
-
[7]
PaddleOCR 3.0 Technical Report
Cui, C., Sun, T., Lin, M., Gao, T., Zhang, Y., Liu, J., Wang, X., Zhang, Z., Zhou, C., Liu, H., et al.: PaddleOCR 3.0 Technical Report. arXiv preprint arXiv:2507.05595 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
arXiv preprint arXiv:2511.18434 (2025)
Du, Y., Chen, P., Ying, X., Chen, Z.: DocPTBench: Benchmarking end-to-end photographed document parsing and translation. arXiv preprint arXiv:2511.18434 (2025)
-
[9]
IEEE Transactions on Pattern Analysis and Machine Intelligence47(4), 2723–2738 (2025)
Du, Y., Chen, Z., Su, Y., Jia, C., Jiang, Y.G.: Instruction-guided scene text recog- nition. IEEE Transactions on Pattern Analysis and Machine Intelligence47(4), 2723–2738 (2025)
2025
-
[10]
In: Proceedings of the IEEE International Conference on Computer Vision
Du, Y., Chen, Z., Xie, H., Jia, C., Jiang, Y.G.: SVTRv2: CTC beats encoder- decoder models in scene text recognition. In: Proceedings of the IEEE International Conference on Computer Vision. pp. 20147–20156 (2025)
2025
-
[11]
arXiv preprint arXiv:2109.03144 (2021)
Du, Y., Li, C., Guo, R., Cui, C., Liu, W., Zhou, J., Lu, B., Yang, Y., Liu, Q., Hu, X., et al.: PP-OCRv2: Bag of tricks for ultra lightweight OCR system. arXiv preprint arXiv:2109.03144 (2021)
-
[12]
Fu, L., Kuang, Z., Song, J., Huang, M., Yang, B., Li, Y., Zhu, L., Luo, Q., Wang, X., Lu, H., et al.: OCRBench v2: An improved benchmark for evaluating large multimodal models on visual text localization and reasoning. arXiv preprint arXiv:2501.00321 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recog- nition (2023)
Huang, Y., Lu, N., Chen, D., Li, Y., Xie, Z., Zhu, S., Gao, L., Peng, W.: Improving table structure recognition with visual-alignment sequential coordinate modeling. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recog- nition (2023)
2023
-
[14]
arXiv preprint arXiv:2501.11800 (2025)
Khang, M., Hong, T.: TFLOP: table structure recognition framework with layout pointer mechanism. arXiv preprint arXiv:2501.11800 (2025)
-
[15]
Step-DPO: Step-wise Preference Optimization for Long-chain Reasoning of LLMs
Lai, X., Tian, Z., Chen, Y., Yang, S., Peng, X., Jia, J.: Step-DPO: Step- wise preference optimization for long-chain reasoning of LLMs. arXiv preprint arXiv:2406.18629 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Lei, F., Meng, J., Huang, Y., Chen, T., Zhang, Y., He, S., Zhao, J., Liu, K.: Reasoning-Table: Exploring reinforcement learning for table reasoning. arXiv preprint arXiv:2506.01710 (2025) StrucTab: A Structured Optimization Framework for Table Parsing 17
-
[17]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition
Li, G., Lyu, P., Zhang, C., Shen, H., Wu, L., Wan, X., Zeng, G., Hu, H., Ma, C., Zhou, Y.: Towards real-world document parsing via realistic scene synthesis and document-aware training. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 23709–23719 (2026)
2026
-
[18]
Li, G., Peng, S., Wan, X., Zhang, C., Feng, H., Xu, X., Wu, P., Li, B., Ding, Z., Liu, Y., Ye, Y., Yang, Y., Shu, Z., Yan, G., Li, Z., Ma, C., Wang, W., Zhou, Y., Hu, H.: Chronicles-OCR: A cross-temporal perception benchmark for the evolutionary trajectory of chinese characters. arXiv preprint arXiv:2605.11960 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
arXiv preprint arXiv:2512.02498 (2025)
Li, Y., Yang, G., Liu, H., Wang, B., Zhang, C.: dots.ocr: Multilingual document layout parsing in a single vision-language model. arXiv preprint arXiv:2512.02498 (2025)
-
[20]
In: Pro- ceedings of the International Conference on Document Analysis and Recognition
Li, Z., Wei, J., Shen, Z., Ma, C., Wu, Y., Zhou, Y.: PACM: Position-aware cross- modality decoder for handwritten mathematical expression recognition. In: Pro- ceedings of the International Conference on Document Analysis and Recognition. pp. 96–114 (2025)
2025
-
[21]
arXiv preprint arXiv:2506.05218 (2025)
Li, Z., Liu, Y., Liu, Q., Ma, Z., Zhang, Z., Zhang, S., Guo, Z., Zhang, J., Wang, X., Bai, X.: MonkeyOCR: Document parsing with a Structure-Recognition-Relation triplet paradigm. arXiv preprint arXiv:2506.05218 (2025)
-
[22]
In: Proceedings of the ACM International Conference on Multimedia (2022)
Lin, W., Sun, Z., Ma, C., Li, M., Wang, J., Sun, L., Huo, Q.: TSRFormer: Table structure recognition with transformers. In: Proceedings of the ACM International Conference on Multimedia (2022)
2022
-
[23]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition
Liu, H., Li, X., Liu, B., Jiang, D., Liu, Y., Ren, B.: Neural collaborative graph machines for table structure recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 4533–4542 (2022)
2022
-
[24]
In: Proceedings of the Conference on Empirical Methods in Natural Language Processing
Liu, Y., Zhao, Z., Tian, L., Wang, H., Ye, X., You, Y., Yu, Z., Wu, C., Xiao, Z., Yu, Y., et al.: POINTS-Reader: Distillation-free adaptation of vision-language models for document conversion. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing. pp. 1576–1601 (2025)
2025
-
[25]
In: Proceedings of the IEEE International Conference on Computer Vision (2021)
Long, R., Wang, W., Xue, N., Gao, F., Yang, Z., Wang, Y., Xia, G.S.: Parsing table structures in the wild. In: Proceedings of the IEEE International Conference on Computer Vision (2021)
2021
-
[26]
Lyu, J., Wang, W., Yang, D., Zhong, J., Zhou, Y.: Arbitrary reading order scene textspotterwithlocalsemanticsguidance.In:ProceedingsoftheAAAIConference on Artificial Intelligence. vol. 39, pp. 5919–5927 (2025)
2025
-
[27]
In: Proceedings of the IEEE Conference on Com- puter Vision and Pattern Recognition (2022)
Nassar, A., Livathinos, N., Lysak, M., Staar, P.: TableFormer: Table structure un- derstanding with transformers. In: Proceedings of the IEEE Conference on Com- puter Vision and Pattern Recognition (2022)
2022
-
[28]
MinerU2.5: A Decoupled Vision-Language Model for Efficient High-Resolution Document Parsing
Niu, J., Liu, Z., Gu, Z., Wang, B., Ouyang, L., Zhao, Z., Chu, T., He, T., Wu, F., Zhang, Q., et al.: MinerU2.5: A decoupled vision-language model for efficient high-resolution document parsing. arXiv preprint arXiv:2509.22186 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
OpenAI: GPT-4o System Card (2024),https : / / cdn . openai . com / gpt - 4o - system-card.pdf, accessed: 2026-04-20
2024
-
[30]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2025)
Ouyang, L., Qu, Y., Zhou, H., Zhu, J., Zhang, R., Lin, Q., Wang, B., Zhao, Z., Jiang, M., Zhao, X., et al.: OmniDocBench: Benchmarking diverse PDF document parsing with comprehensive annotations. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2025)
2025
-
[31]
Paruchuri, V.: Marker (2025),https://github.com/datalab- to/marker, ac- cessed: 2026-04-20
2025
-
[32]
ChartArena: Benchmarking Chart Parsing across Languages, Scenarios, and Formats
Peng, S., Li, G., Wan, X., Zhang, C., Feng, H., Wu, B., Shen, H., Wang, W., Cai, Z., Tian, Z., Hu, H., Ma, C., Zhou, Y.: ChartArena: Benchmarking chart parsing across languages, scenarios, and formats. arXiv preprint arXiv:2606.01348 (2026) 18 G. Li et al
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[33]
Uni-DPO: A Unified Paradigm for Dynamic Preference Optimization of LLMs
Peng, S., Wang, W., Tian, Z., Yang, S., Wu, X., Xu, H., Zhang, C., Isobe, T., Hu, B., Zhang, M.: Uni-DPO: A unified paradigm for dynamic preference optimization of LLMs. arXiv preprint arXiv:2506.10054 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
In: Proceedings of the IEEE International Con- ference on Computer Vision (2025)
Peng, S., Yang, S., Jiang, L., Tian, Z.: Mitigating object hallucinations via sentence-level early intervention. In: Proceedings of the IEEE International Con- ference on Computer Vision (2025)
2025
-
[35]
arXiv preprint arXiv:2403.04822 (2024)
Peng, S., Chakravarthy, A., Lee, S., Wang, X., Balasubramaniyan, R., Chau, D.H.: UniTable: Towards a unified framework for table recognition via self-supervised pretraining. arXiv preprint arXiv:2403.04822 (2024)
-
[36]
arXiv preprint arXiv:2502.18443 (2025)
Poznanski, J., Rangapur, A., Borchardt, J., Dunkelberger, J., Huff, R., Lin, D., Wilhelm, C., Lo, K., Soldaini, L.: olmOCR: Unlocking trillions of tokens in PDFs with vision language models. arXiv preprint arXiv:2502.18443 (2025)
-
[37]
arXiv preprint arXiv:2510.19817 (2025)
Poznanski, J., Soldaini, L., Lo, K.: olmOCR 2: Unit test rewards for document OCR. arXiv preprint arXiv:2510.19817 (2025)
-
[38]
In: Proceedings of the European Conference on Computer Vision
Raja, S., Mondal, A., Jawahar, C.: Table structure recognition using top-down and bottom-up cues. In: Proceedings of the European Conference on Computer Vision. pp. 70–86 (2020)
2020
-
[39]
com / ByteDance - Seed / Seed - 1
Seed, B.: Seed1.8 Model Card: Towards generalized real-world agency (2025), https : / / github . com / ByteDance - Seed / Seed - 1 . 8 / blob / main / Seed - 1 . 8 - Modelcard.pdf, accessed: 2026-04-20
2025
-
[40]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y., Wu, Y., et al.: DeepSeekMath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
In: Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence
Shen, H., Gao, X., Wei, J., Qiao, L., Zhou, Y., Li, Q., Cheng, Z.: Divide Rows and Conquer Cells: Towards structure recognition for large tables. In: Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence. pp. 1369–1377 (2023)
2023
-
[42]
Singh, A., Fry, A., Perelman, A., Tart, A., Ganesh, A., El-Kishky, A., McLaughlin, A., Low, A., Ostrow, A., Ananthram, A., et al.: OpenAI GPT-5 System Card. arXiv preprint arXiv:2601.03267 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
LightOnOCR: A 1b end-to-end multilingual vision-language model for state-of-the-art OCR,
Taghadouini, S., Cavaillès, A., Aubertin, B.: LightOnOCR: A 1B end-to-end multilingual vision-language model for state-of-the-art OCR. arXiv preprint arXiv:2601.14251 (2026)
-
[44]
arXiv preprint arXiv:2511.19575 (2025)
Team, H.V., Lyu, P., Wan, X., Li, G., Peng, S., Wang, W., Wu, L., Shen, H., Zhou, Y., Tang, C., et al.: HunyuanOCR Technical Report. arXiv preprint arXiv:2511.19575 (2025)
-
[45]
Kimi K2.5: Visual Agentic Intelligence
Team, K., Bai, T., Bai, Y., Bao, Y., Cai, S., Cao, Y., Charles, Y., Che, H., Chen, C., Chen, G., et al.: Kimi K2.5: Visual agentic intelligence. arXiv preprint arXiv:2602.02276 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[46]
Wang, A.L., Tang, J., Liao, L., Feng, H., Liu, Q., Fei, X., Lu, J., Wang, H., Liu, H., Liu, Y., et al.: WildDoc: How far are we from achieving comprehensive and robust document understanding in the wild? In: Proceedings of the Conference on Empirical Methods in Natural Language Processing (2025)
2025
-
[47]
arXiv preprint arXiv:2506.03197 (2025)
Wang, B., Wu, B., Li, W., Fang, M., Huang, Z., Huang, J., Wang, H., Liang, Y., Chen, L., Chu, W., et al.: Infinity Parser: Layout aware reinforcement learning for scanned document parsing. arXiv preprint arXiv:2506.03197 (2025)
-
[48]
MinerU: An Open-Source Solution for Precise Document Content Extraction
Wang, B., Xu, C., Zhao, X., Ouyang, L., Wu, F., Zhao, Z., Xu, R., Liu, K., Qu, Y., Shang, F., et al.: MinerU: An open-source solution for precise document content extraction. arXiv preprint arXiv:2409.18839 (2024) StrucTab: A Structured Optimization Framework for Table Parsing 19
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Wang, W., Gao, Z., Gu, L., Pu, H., Cui, L., Wei, X., Liu, Z., Jing, L., Ye, S., Shao, J., et al.: InternVL3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
In: Proceedings of the European Conference on Computer Vision (2024)
Wei, H., Kong, L., Chen, J., Zhao, L., Ge, Z., Yang, J., Sun, J., Han, C., Zhang, X.: Vary: Scaling up the vision vocabulary for large vision-language models. In: Proceedings of the European Conference on Computer Vision (2024)
2024
-
[51]
General OCR Theory: Towards OCR-2.0 via a Unified End-to-end Model
Wei, H., Liu, C., Chen, J., Wang, J., Kong, L., Xu, Y., Ge, Z., Zhao, L., Sun, J., Peng, Y., et al.: General OCR theory: Towards OCR-2.0 via a unified end-to-end model. arXiv preprint arXiv:2409.01704 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[52]
DeepSeek-OCR: Contexts Optical Compression
Wei, H., Sun, Y., Li, Y.: DeepSeek-OCR: Contexts optical compression. arXiv preprint arXiv:2510.18234 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
DeepSeek-OCR 2: Visual causal flow,
Wei, H., Sun, Y., Li, Y.: DeepSeek-OCR 2: Visual causal flow. arXiv preprint arXiv:2601.20552 (2026)
-
[54]
In: Proceedings of the AAAI Conference on Artificial Intelligence (2023)
Xing, H., Gao, F., Long, R., Bu, J., Zheng, Q., Li, L., Yao, C., Yu, Z.: LORE: Logical location regression network for table structure recognition. In: Proceedings of the AAAI Conference on Artificial Intelligence (2023)
2023
-
[55]
Scientific Data10(1), 110 (2023)
Yang, F., Hu, L., Liu, X., Huang, S., Gu, Z.: A large-scale dataset for end-to-end table recognition in the wild. Scientific Data10(1), 110 (2023)
2023
-
[56]
arXiv preprint arXiv:2512.20312 (2025)
Yang, S., Huang, Q., Yuan, J., Zha, L., Tang, K., Yang, Y., Wang, N., Wei, Y., Li, L., Ye, W., et al.: TableGPT-R1: Advancing tabular reasoning through reinforce- ment learning. arXiv preprint arXiv:2512.20312 (2025)
-
[57]
arXiv preprint arXiv:2505.23621 (2025)
Yang, Z., Chen, L., Cohan, A., Zhao, Y.: Table-R1: Inference-time scaling for table reasoning. arXiv preprint arXiv:2505.23621 (2025)
-
[58]
In: Proceedings of the IEEE International Conference on Computer Vision (2025)
Yang, Z., Tang, J., Li, Z., Wang, P., Wan, J., Zhong, H., Liu, X., Yang, M., Wang, P., Bai, S., et al.: CC-OCR: A comprehensive and challenging OCR benchmark for evaluating large multimodal models in literacy. In: Proceedings of the IEEE International Conference on Computer Vision (2025)
2025
-
[59]
arXiv preprint arXiv:2511.10390 (2025)
Zhang, J., Liu, Y., Wu, Z., Pang, G., Ye, Z., Zhong, Y., Ma, J., Wei, T., Xu, H., Chen, W., et al.: MonkeyOCR v1.5 Technical Report: Unlocking robust document parsing for complex patterns. arXiv preprint arXiv:2511.10390 (2025)
-
[60]
arXiv preprint arXiv:2512.01248 (2025)
Zhang, J., Wang, B., Zhang, Q., Wu, F., Wen, Z., Lu, J., Shan, J., Zhao, Z., Yang, S., Wang, Z., et al.: TRivia: Self-supervised fine-tuning of vision-language models for table recognition. arXiv preprint arXiv:2512.01248 (2025)
-
[61]
arXiv preprint arXiv:2305.13534 (2023)
Zhang, M., Press, O., Merrill, W., Liu, A., Smith, N.A.: How language model hallucinations can snowball. arXiv preprint arXiv:2305.13534 (2023)
-
[62]
Zhang, Q., Wang, B., Huang, V.S.J., Zhang, J., Wang, Z., Liang, H., He, C., Zhang, W.: Document parsing unveiled: Techniques, challenges, and prospects for structured information extraction. arXiv preprint arXiv:2410.21169 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[63]
Zhang, Z., Hu, P., Ma, J., Du, J., Zhang, J., Yin, B., Yin, B., Liu, C.: SEMv2: Table separationlinedetectionbasedoninstancesegmentation.PatternRecognition149, 110279 (2024)
2024
-
[64]
Pattern Recognition126, 108565 (2022)
Zhang, Z., Zhang, J., Du, J., Wang, F.: Split, embed and merge: An accurate table structure recognizer. Pattern Recognition126, 108565 (2022)
2022
-
[65]
In: Proceedings of Advances in Neural Information Process- ing Systems
Zhao, W., Feng, H., Liu, Q., Tang, J., Wei, S., Wu, B., Liao, L., Ye, Y., Liu, H., Zhou, W., et al.: TabPedia: Towards comprehensive visual table understanding with concept synergy. In: Proceedings of Advances in Neural Information Process- ing Systems. vol. 37, pp. 7185–7212 (2024)
2024
-
[66]
In: Proceedings of the IEEE Winter Conference on Applications of Computer Vision (2021) 20 G
Zheng,X.,Burdick,D.,Popa,L.,Zhong,X.,Wang,N.X.R.:GlobalTableExtractor (GTE): A framework for joint table identification and cell structure recognition us- ing visual context. In: Proceedings of the IEEE Winter Conference on Applications of Computer Vision (2021) 20 G. Li et al
2021
-
[67]
In: Proceedings of the 62nd Annual Meeting of the Asso- ciation for Computational Linguistics (Volume 1: Long Papers) (2024)
Zhong, W., Feng, X., Zhao, L., Li, Q., Huang, L., Gu, Y., Ma, W., Xu, Y., Qin, B.: Investigating and mitigating the multimodal hallucination snowballing in large vision-language models. In: Proceedings of the 62nd Annual Meeting of the Asso- ciation for Computational Linguistics (Volume 1: Long Papers) (2024)
2024
-
[68]
In: Proceedings of the European Conference on Com- puter Vision (2020)
Zhong, X., ShafieiBavani, E., Jimeno Yepes, A.: Image-based table recognition: data, model, and evaluation. In: Proceedings of the European Conference on Com- puter Vision (2020)
2020
-
[69]
arXiv preprint arXiv:2601.08834 (2025)
Zhong, Y., Chen, L., Zeng, Z., Zhao, X., Jiang, D., Zheng, L., Huang, J., Qiu, H., Shi, P., Yang, S., et al.: Reading or Reasoning? format decoupled reinforcement learning for document OCR. arXiv preprint arXiv:2601.08834 (2025)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.