High-Fidelity Two-Step Image Generation via Teacher-Aligned End-to-End Distillation
Pith reviewed 2026-06-27 09:53 UTC · model grok-4.3
The pith
Three distillation choices let a 2-step diffusion model approach the quality of its 8-step teacher.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
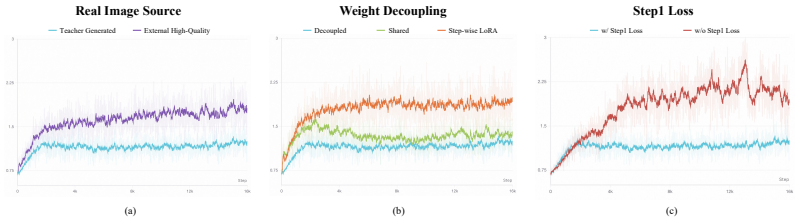
Z-Image Turbo++ is produced by distilling an 8-step teacher into a 2-step student using distribution-aligned adversarial learning that treats teacher-generated images as the real samples, step-decoupled parameterization that assigns separate parameters to each denoising step, and end-to-end training with iterative regularization that routes final-image gradients back to the first step while preserving an explicit loss on the intermediate output; together these choices narrow the quality gap to the teacher in qualitative and quantitative evaluations.
What carries the argument
Distribution-aligned adversarial learning that uses teacher-generated images rather than external real images as the adversarial target, paired with step-decoupled parameterization and end-to-end training that propagates final quality gradients to the first step.
If this is right
- The quality gap between 2-step and 8-step generation narrows substantially in both visual and metric terms.
- The quality-efficiency trade-off in few-step diffusion generation improves when distillation is tailored to the two-step regime.
- Independent parameters per step better accommodate the distinct roles of the first and second denoising operations.
- End-to-end gradient flow from the final image back to the first step produces more useful intermediate outputs without sacrificing the explicit step-1 loss.
Where Pith is reading between the lines
- The same teacher-alignment idea could be tested on other base diffusion models or on tasks such as text-to-image synthesis.
- If the per-step parameterization scales, it might allow further reduction to one-step generation while retaining comparable fidelity.
- The method suggests that matching the student distribution to the teacher's intermediate outputs rather than to real data can be a general principle for aggressive step reduction.
Load-bearing premise
Teacher-generated images form a more attainable and informative target for the GAN component than external real images when only two steps are available.
What would settle it
Side-by-side evaluation showing that the 2-step outputs remain visibly or measurably inferior to the 8-step teacher outputs after all three design choices are applied would falsify the narrowing of the quality gap.
Figures




read the original abstract
Few-step diffusion distillation has become increasingly mature for 4-8-step generation, yet pushing further to 2 steps remains challenging. In this work, we introduce Z-Image Turbo++, a high-quality 2-step image generation model distilled from the 8-step Z-Image Turbo teacher. Our method addresses the central bottlenecks of increased task difficulty and limited model capacity in 2-step generation through three simple but effective design choices tailored to this regime. First, we propose Distribution-Aligned Adversarial Learning, which uses teacher-generated images rather than external real images as real samples for GAN training, providing a more attainable and informative adversarial target. Second, we adopt Step-Decoupled Parameterization, assigning independent model parameters to the two denoising steps to better match their distinct capacity demands. Third, we perform End-to-End Training with Iterative Regularization, allowing the first step to receive gradients from final image quality while preserving a meaningful intermediate generation through an explicit step-1 loss. Together, these designs substantially narrow the quality gap between 2-step and 8-step generation in both qualitative and quantitative evaluations, highlighting the potential of carefully tailored distillation strategies for improving the quality-efficiency trade-off in few-step generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Z-Image Turbo++, a 2-step diffusion model distilled from an 8-step Z-Image Turbo teacher. It proposes three design choices to address increased task difficulty and limited capacity: Distribution-Aligned Adversarial Learning (using teacher-generated images rather than external real images as GAN targets), Step-Decoupled Parameterization (independent parameters for each of the two denoising steps), and End-to-End Training with Iterative Regularization (propagating final-image gradients to the first step while retaining an explicit step-1 loss). The central claim is that these choices substantially narrow the quality gap to the 8-step teacher in both qualitative and quantitative evaluations.
Significance. If the empirical improvements hold under standard evaluation protocols, the work would advance few-step diffusion distillation by showing that teacher-aligned targets, decoupled parameterization, and end-to-end regularization can materially close the 2-step versus multi-step gap without increasing model capacity, offering a practical route to higher-efficiency generative models.
minor comments (2)
- [Abstract] Abstract: the claim of 'substantially narrow[ing] the quality gap' is stated without any numerical metrics (e.g., FID, CLIP score, or human preference deltas) or baseline comparisons; adding one or two key quantitative results would make the summary self-contained.
- The three design choices are presented as 'simple but effective,' yet the manuscript does not report an ablation that isolates the contribution of each choice relative to a common baseline; a compact ablation table would strengthen the attribution of gains.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of Z-Image Turbo++ and the recommendation for minor revision. The work focuses on narrowing the 2-step vs. 8-step quality gap through three targeted distillation techniques without increasing model capacity.
Circularity Check
No significant circularity; empirical claims rest on external evaluations
full rationale
The paper describes an empirical distillation method with three design choices (Distribution-Aligned Adversarial Learning using teacher images, Step-Decoupled Parameterization, and End-to-End Training with Iterative Regularization). The central claim is that these choices narrow the 2-step vs. 8-step quality gap, evaluated qualitatively and quantitatively. No equations, derivations, or first-principles results are presented that reduce to inputs by construction. No fitted parameters are renamed as predictions, no self-citation load-bearing arguments, and no ansatz or uniqueness theorems imported from prior work. The argument structure is self-contained against external benchmarks (teacher outputs and quality metrics), with no reduction of the reported improvement to a tautology or self-defined quantity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard diffusion forward/reverse process and adversarial training objectives remain valid when applied to teacher-generated targets.
Reference graph
Works this paper leans on
-
[1]
Oneig-bench: Omni-dimensional nuanced evaluation for image generation, 2025
Jingjing Chang, Yixiao Fang, Peng Xing, Shuhan Wu, Wei Cheng, Rui Wang, Xianfang Zeng, Gang Yu, and Hai-Bao Chen. Oneig-bench: Omni-dimensional nuanced evaluation for image generation. arXiv preprint arXiv:2506.07977, 2025
-
[2]
Structural pruning for diffusion models, 2023
Gongfan Fang, Xinyin Ma, and Xinchao Wang. Structural pruning for diffusion models, 2023. URLhttps://arxiv.org/abs/2305.10924
-
[3]
Zigang Geng, Yibing Wang, Yeyao Ma, Chen Li, Yongming Rao, Shuyang Gu, Zhao Zhong, Qinglin Lu, Han Hu, Xiaosong Zhang, et al. X-omni: Reinforcement learning makes discrete autoregressive image generative models great again. arXiv preprint arXiv:2507.22058, 2025
-
[4]
Geneval: An object-focused frame- work for evaluating text-to-image alignment
Dhruba Ghosh, Hannaneh Hajishirzi, and Ludwig Schmidt. Geneval: An object-focused frame- work for evaluating text-to-image alignment. Advances in Neural Information Processing Systems, 36:52132–52152, 2023
2023
-
[5]
Ptqd: Accurate post-training quantization for diffusion models
Yefei He, Luping Liu, Jing Liu, Weijia Wu, Hong Zhou, and Bohan Zhuang. Ptqd: Accurate post-training quantization for diffusion models. Advances in Neural Information Processing Systems, 36:13237–13249, 2023
2023
-
[6]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[7]
Lora: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models. Iclr, 1(2):3, 2022
2022
-
[8]
ELLA: Equip Diffusion Models with LLM for Enhanced Semantic Alignment
Xiwei Hu, Rui Wang, Yixiao Fang, Bin Fu, Pei Cheng, and Gang Yu. Ella: Equip diffusion models with llm for enhanced semantic alignment. arXiv preprint arXiv:2403.05135, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Dengyang Jiang, Dongyang Liu, Zanyi Wang, Qilong Wu, Liuzhuozheng Li, Hengzhuang Li, Xin Jin, David Liu, Changsheng Lu, Zhen Li, Bo Zhang, Mengmeng Wang, Steven Hoi, Peng Gao, and Harry Yang. Distribution matching distillation meets reinforcement learning, 2026. URL https://arxiv.org/abs/2511.13649
-
[10]
FLUX.2: Frontier Visual Intelligence
Black Forest Labs. FLUX.2: Frontier Visual Intelligence. https://bfl.ai/blog/flux-2, 2025
2025
-
[11]
SDXL-Lightning: Progressive Adversarial Diffusion Distillation
Shanchuan Lin, Anran Wang, and Xiao Yang. Sdxl-lightning: Progressive adversarial diffusion distillation. arXiv preprint arXiv:2402.13929, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling. arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[13]
Decoupled DMD: CFG augmentation as the spear, distribution matching as the shield
Dongyang Liu, Peng Gao, David Liu, Ruoyi Du, Zhen Li, Qilong Wu, Xin Jin, Sihan Cao, Shifeng Zhang, Steven HOI, and Hongsheng Li. Decoupled DMD: CFG augmentation as the spear, distribution matching as the shield. In The Fourteenth International Conference on Learning Representations, 2026. URLhttps://openreview.net/forum?id=jBztvOiCKE
2026
-
[14]
Timestep embedding tells: It’s time to cache for video diffusion model
Feng Liu, Shiwei Zhang, Xiaofeng Wang, Yujie Wei, Haonan Qiu, Yuzhong Zhao, Yingya Zhang, Qixiang Ye, and Fang Wan. Timestep embedding tells: It’s time to cache for video diffusion model. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 7353–7363, 2025
2025
-
[15]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. arXiv preprint arXiv:2209.03003, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[16]
Instaflow: One step is enough for high-quality diffusion-based text-to-image generation
Xingchao Liu, Xiwen Zhang, Jianzhu Ma, Jian Peng, et al. Instaflow: One step is enough for high-quality diffusion-based text-to-image generation. In The Twelfth International Conference on Learning Representations, 2023
2023
-
[17]
Simplifying, Stabilizing and Scaling Continuous-Time Consistency Models
Cheng Lu and Yang Song. Simplifying, stabilizing and scaling continuous-time consistency models. arXiv preprint arXiv:2410.11081, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps. Advances in neural information processing systems, 35:5775–5787, 2022. 11
2022
-
[19]
Diff- instruct: A universal approach for transferring knowledge from pre-trained diffusion models
Weijian Luo, Tianyang Hu, Shifeng Zhang, Jiacheng Sun, Zhenguo Li, and Zhihua Zhang. Diff- instruct: A universal approach for transferring knowledge from pre-trained diffusion models. Advances in Neural Information Processing Systems, 36:76525–76546, 2023
2023
-
[20]
Deepcache: Accelerating diffusion models for free
Xinyin Ma, Gongfan Fang, and Xinchao Wang. Deepcache: Accelerating diffusion models for free. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15762–15772, 2024
2024
-
[21]
Qwen-image-lightning, 2025
ModelTC. Qwen-image-lightning, 2025. URL https://github.com/ModelTC/ LightX2V-Qwen-Image-Lightning
2025
-
[22]
Hyper-sd: Trajectory segmented consistency model for efficient image synthesis
Yuxi Ren, Xin Xia, Yanzuo Lu, Jiacheng Zhang, Jie Wu, Pan Xie, Xing Wang, and Xuefeng Xiao. Hyper-sd: Trajectory segmented consistency model for efficient image synthesis. Advances in Neural Information Processing Systems, 37:117340–117362, 2024
2024
-
[23]
Progressive Distillation for Fast Sampling of Diffusion Models
Tim Salimans and Jonathan Ho. Progressive distillation for fast sampling of diffusion models. arXiv preprint arXiv:2202.00512, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[24]
Multistep distillation of diffusion models via moment matching
Tim Salimans, Thomas Mensink, Jonathan Heek, and Emiel Hoogeboom. Multistep distillation of diffusion models via moment matching. Advances in Neural Information Processing Systems, 37:36046–36070, 2024
2024
-
[25]
Fast high-resolution image synthesis with latent adversarial diffusion distillation
Axel Sauer, Frederic Boesel, Tim Dockhorn, Andreas Blattmann, Patrick Esser, and Robin Rom- bach. Fast high-resolution image synthesis with latent adversarial diffusion distillation. In SIGGRAPH Asia 2024 Conference Papers, pages 1–11, 2024
2024
-
[26]
Adversarial diffusion distillation
Axel Sauer, Dominik Lorenz, Andreas Blattmann, and Robin Rombach. Adversarial diffusion distillation. In European Conference on Computer Vision, pages 87–103. Springer, 2024
2024
-
[27]
Post-training quantization on diffusion models
Yuzhang Shang, Zhihang Yuan, Bin Xie, Bingzhe Wu, and Yan Yan. Post-training quantization on diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1972–1981, 2023
1972
-
[28]
Deep unsuper- vised learning using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsuper- vised learning using nonequilibrium thermodynamics. In International conference on machine learning, pages 2256–2265. pmlr, 2015
2015
-
[29]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. arXiv preprint arXiv:2010.02502, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[30]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. arXiv preprint arXiv:2011.13456, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[31]
Consistency models
Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. Consistency models. 2023
2023
-
[32]
Z-Image: An Efficient Image Generation Foundation Model with Single-Stream Diffusion Transformer
Z-Image Team. Z-image: An efficient image generation foundation model with single-stream diffusion transformer. arXiv preprint arXiv:2511.22699, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Phased consistency models
Fu-Yun Wang, Zhaoyang Huang, Alexander Bergman, Dazhong Shen, Peng Gao, Michael Lin- gelbach, Keqiang Sun, Weikang Bian, Guanglu Song, Yu Liu, et al. Phased consistency models. Advances in neural information processing systems, 37:83951–84009, 2024
2024
-
[34]
Improved distribution matching distillation for fast image synthesis
Tianwei Yin, Michaël Gharbi, Taesung Park, Richard Zhang, Eli Shechtman, Fredo Durand, and Bill Freeman. Improved distribution matching distillation for fast image synthesis. Advances in neural information processing systems, 37:47455–47487, 2024
2024
-
[35]
One-step diffusion with distribution matching distillation
Tianwei Yin, Michaël Gharbi, Richard Zhang, Eli Shechtman, Fredo Durand, William T Freeman, and Taesung Park. One-step diffusion with distribution matching distillation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6613–6623, 2024
2024
-
[36]
Unipc: A unified predictor- corrector framework for fast sampling of diffusion models
Wenliang Zhao, Lujia Bai, Yongming Rao, Jie Zhou, and Jiwen Lu. Unipc: A unified predictor- corrector framework for fast sampling of diffusion models. Advances in Neural Information Processing Systems, 36:49842–49869, 2023. 12 A Pseudo-code for Memory-Efficient Training def naive_generator_training(step0_model, step1_model, step0_stride, step1_stride, cap...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.