Spec-AUF: Accept-Until-Fail Training under Train-Inference Misalignment for Masked Block Drafters
Pith reviewed 2026-07-03 14:13 UTC · model grok-4.3
The pith
Accept-Until-Fail training limits cross-entropy support to the first predicted failure in masked block drafters, raising average emitted length from 2.40 to 2.61 tokens.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
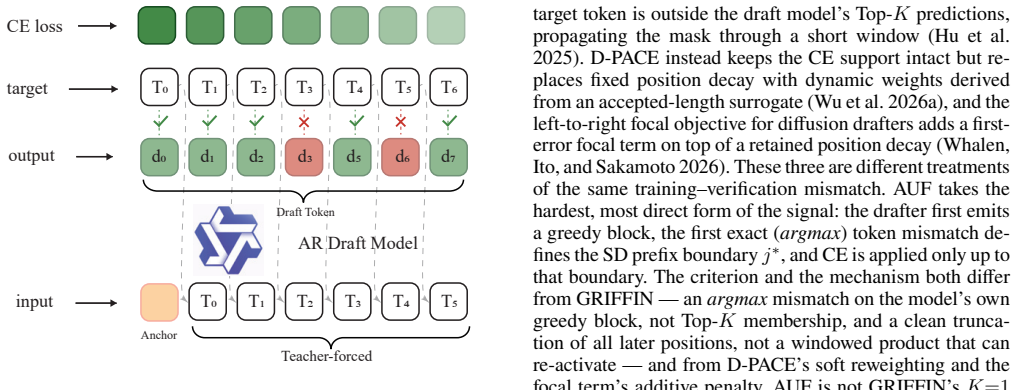
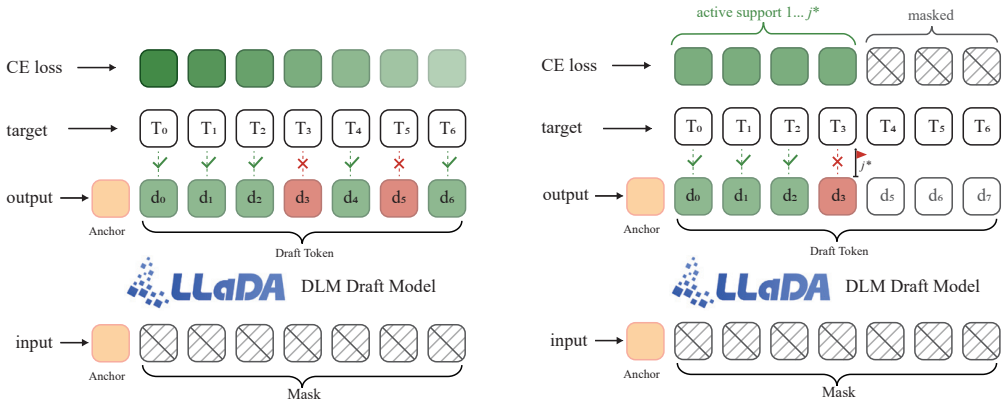
AUF approximates teacher-forced prefix-sensitive supervision on the loss side by restricting cross-entropy support to the drafter's first predicted failure point, thereby aligning training with the inference contract that discards every token after the first rejection.
What carries the argument
The Accept-Until-Fail (AUF) truncation of cross-entropy support at the first predicted failure, which concentrates supervision on the accepted prefix without any input-side conditioning or extra objectives.
If this is right
- AUF raises DFlash drafter average emitted length τ from 2.40 to 2.61 across six benchmarks, with improvement on every benchmark.
- The same AUF change transfers to Domino's two-branch head and lifts its τ from 2.56 to 2.68.
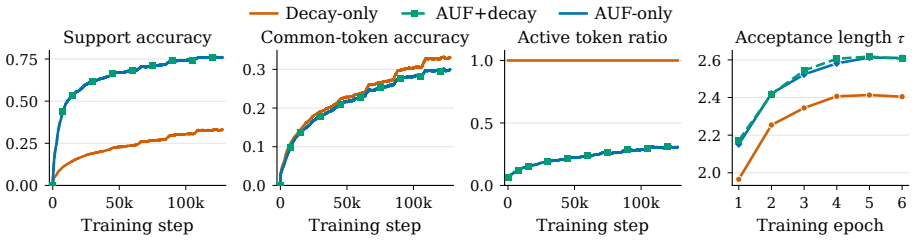
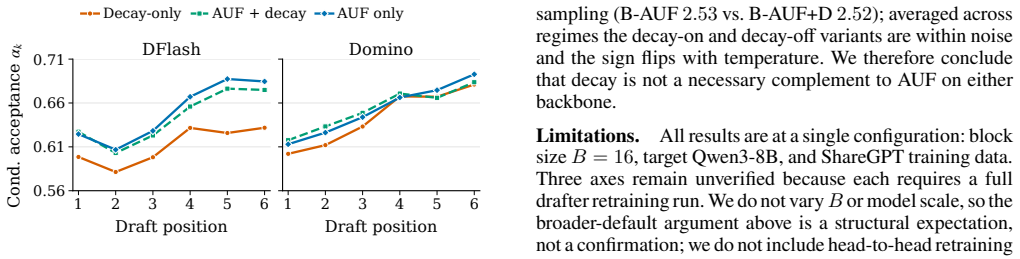
- Once AUF truncates the support, the standard exponential position-decay weighting becomes empirically inert on DFlash.
- A decay-only baseline achieves higher token accuracy on the shared block mask yet produces worse decoding performance than AUF.
Where Pith is reading between the lines
- The finding that accuracy and decoding quality can move in opposite directions suggests future drafter objectives may need to optimize acceptance length directly rather than token-level accuracy.
- Because AUF requires no verifier rollouts or auxiliary heads, it could be combined with existing acceptance-aware reweighting methods to test additive effects.
- The inertness of position-decay weighting after AUF truncation raises the question of whether other position-dependent regularizers would also lose influence under prefix-truncated losses.
Load-bearing premise
That restricting cross-entropy support only through the first predicted failure sufficiently approximates the prefix-sensitive supervision that teacher-forced learning would provide.
What would settle it
A replication experiment on the same six benchmarks and fixed drafter backbones that shows no increase, or a decrease, in average emitted length τ after applying AUF.
Figures

read the original abstract
Speculative decoding accelerates autoregressive generation by drafting a block of tokens that the target model verifies left-to-right, committing only the longest accepted prefix. Block (DLM-style) drafters predict the whole block in parallel, which is fast but trained with a full-block cross-entropy that supervises every position against the gold continuation -- even though inference discards every token after the first rejection. Recent acceptance-aware objectives patch this by reweighting the full-block loss; we instead use teacher-forced learning as a motivation for how supervision should concentrate on the accepted prefix. A mask-only block drafter has no input-side channel for gold-prefix conditioning, so AUF approximates that prefix-sensitive supervision on the loss side by keeping the cross-entropy support only through the drafter's first predicted failure. AUF is a single, detached change to the CE support -- no auxiliary objective, no verifier rollouts, and no change to the inference pipeline or the exactness contract. Within fixed drafter backbones and serving settings on Qwen3-8B, AUF raises the DFlash drafter's average emitted length $\tau$, averaged over six benchmarks, from 2.40 to 2.61, with a gain on every benchmark, and transfers to Domino's two-branch head (2.56 to 2.68). Two findings sharpen the picture: the decay-only baseline reaches higher token accuracy on the shared block mask yet decodes worse, and on DFlash, once AUF truncates the support, the standard exponential position-decay weighting becomes empirically inert.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Accept-Until-Fail (AUF) training for masked block drafters in speculative decoding to mitigate train-inference misalignment. Instead of full-block cross-entropy, AUF restricts loss support to the prefix up to the drafter's first predicted failure, approximating teacher-forced prefix-sensitive supervision without auxiliary objectives, verifier rollouts, or inference changes. On Qwen3-8B with fixed DFlash and Domino drafters, AUF increases average emitted length τ from 2.40 to 2.61 (gains on all six benchmarks) and from 2.56 to 2.68 respectively. Secondary findings note that a decay-only baseline achieves higher token accuracy yet worse decoding, and that AUF renders standard exponential position-decay weighting inert.
Significance. If the empirical results hold under rigorous controls, AUF represents a minimal, detached training modification that improves speculative decoding efficiency while preserving the exactness contract and requiring no serving changes. The transfer across two distinct drafter architectures (DFlash and Domino's two-branch head) and the observation that position-decay becomes inert once support is truncated provide useful mechanistic insight. The approach avoids the complexity of reweighting or auxiliary losses common in acceptance-aware objectives.
major comments (2)
- [Abstract] Abstract: The central claim of consistent τ gains (2.40→2.61 and 2.56→2.68) rests on point estimates from single training runs with no reported standard deviations, seed counts, or statistical significance tests. Because τ aggregates prompt-dependent acceptance lengths whose variance is typically high, a 0.21 difference could arise from training stochasticity or prompt sampling rather than the loss-support change; this directly undermines the reproducibility of the 'gain on every benchmark' assertion.
- [Abstract] Abstract (and experimental results): The assumption that restricting CE support to the first predicted failure sufficiently approximates teacher-forced prefix-sensitive supervision is load-bearing for the method's motivation, yet the manuscript provides no ablation isolating this truncation from other factors (e.g., no comparison against full-block CE with identical random seeds or explicit verification that the approximation holds across varying acceptance rates).
minor comments (2)
- [Abstract] The six benchmarks are referenced but not enumerated in the abstract; naming them (and providing per-benchmark τ values with variance) would strengthen the reproducibility claim.
- Notation for τ (average emitted length) is introduced without an explicit equation; adding a short definition would clarify its computation from accepted prefixes.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on statistical robustness and the isolation of the core modeling assumption. We address each point below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of consistent τ gains (2.40→2.61 and 2.56→2.68) rests on point estimates from single training runs with no reported standard deviations, seed counts, or statistical significance tests. Because τ aggregates prompt-dependent acceptance lengths whose variance is typically high, a 0.21 difference could arise from training stochasticity or prompt sampling rather than the loss-support change; this directly undermines the reproducibility of the 'gain on every benchmark' assertion.
Authors: We agree that single-run point estimates without reported variance or multiple seeds weaken the strength of the reproducibility claim. While the observed gains appear on every benchmark and transfer across two distinct drafter architectures, this does not substitute for statistical controls. In the revised manuscript we will rerun the key experiments with multiple random seeds, report means and standard deviations for average emitted length τ, and include a brief discussion of variability. revision: yes
-
Referee: [Abstract] Abstract (and experimental results): The assumption that restricting CE support to the first predicted failure sufficiently approximates teacher-forced prefix-sensitive supervision is load-bearing for the method's motivation, yet the manuscript provides no ablation isolating this truncation from other factors (e.g., no comparison against full-block CE with identical random seeds or explicit verification that the approximation holds across varying acceptance rates).
Authors: The primary experimental contrast in the paper is between standard full-block cross-entropy and AUF under otherwise identical drafter architectures, data, and hyperparameters; this comparison directly tests the effect of truncating loss support. We also report that position-decay weighting becomes inert once support is restricted, which supplies indirect mechanistic evidence for the truncation. Nevertheless, we acknowledge that the runs were not explicitly matched on random seeds and that acceptance-rate sweeps were not performed. We will add a clarifying paragraph on these points and, resources permitting, include matched-seed controls in the revision. revision: partial
Circularity Check
No significant circularity; empirical gains are independent of inputs.
full rationale
The paper proposes AUF as a direct, single modification to the cross-entropy support (truncating after the first predicted failure) motivated by teacher-forced prefix supervision. The central claim is an empirical observation that this change raises average emitted length τ from 2.40 to 2.61 (and 2.56 to 2.68 on a second backbone) across six benchmarks. No equations, self-citations, or fitted parameters are shown that would reduce the reported τ values to the training inputs by construction. The results are measured on held-out benchmarks under fixed serving settings, with no auxiliary objectives or verifier rollouts involved. This is a standard empirical method paper whose performance numbers do not collapse into the loss definition itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Cross-entropy loss remains the base objective for drafter training
Reference graph
Works this paper leans on
-
[1]
International Conference on Machine Learning , year =
Fast Inference from Transformers via Speculative Decoding , author =. International Conference on Machine Learning , year =
-
[2]
Accelerating Large Language Model Decoding with Speculative Sampling
Accelerating Large Language Model Decoding with Speculative Sampling , author =. arXiv preprint arXiv:2302.01318 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Hu, Shijing and Li, Jingyang and Xie, Xingyu and Lu, Zhihui and Toh, Kim-Chuan and Zhou, Pan , journal =
-
[4]
How (not) to Train your Generative Model: Scheduled Sampling, Likelihood, Adversary?
How (not) to Train Your Generative Model: Scheduled Sampling, Likelihood, Adversary? , author =. arXiv preprint arXiv:1511.05101 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Li, Yuhui and Wei, Fangyun and Zhang, Chao and Zhang, Hongyang , journal =
-
[6]
Domino: Decoupling Causal Modeling from Autoregressive Drafting in Speculative Decoding
Domino: Decoupling Causal Modeling from Autoregressive Drafting in Speculative Decoding , author =. arXiv preprint arXiv:2605.29707 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Chen, Jian and Liang, Yesheng and Liu, Zhijian , journal =
-
[8]
Wu, Tianyu and Yao, Yu and Qi, Zhenting and Zheng, Han and Wang, Zhuohan and Ma, Haoran and Liao, Lawrence and Lakkaraju, Himabindu and Li, Ju and Du, Yilun , journal =
-
[9]
and Hartvigsen, Thomas and Fioretto, Ferdinando , journal =
Sandler, Jameson and Christopher, Jacob K. and Hartvigsen, Thomas and Fioretto, Ferdinando , journal =
-
[10]
Teaching Diffusion to Speculate Left-to-Right
Teaching Diffusion to Speculate Left-to-Right , author =. arXiv preprint arXiv:2606.11552 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Advances in Neural Information Processing Systems , year =
Simple and Effective Masked Diffusion Language Models , author =. Advances in Neural Information Processing Systems , year =
-
[12]
International Conference on Learning Representations , year =
Block Diffusion: Interpolating Between Autoregressive and Diffusion Language Models , author =. International Conference on Learning Representations , year =
-
[13]
From Next-Token to Next-Block: A Principled Adaptation Path for Diffusion
Tian, Yuchuan and Liang, Yuchen and Zhang, Shuo and Shu, Yingte and Yang, Guangwen and He, Wei and Fang, Sibo and Guo, Tianyu and Han, Kai and Xu, Chao and Chen, Hanting and Chen, Xinghao and Wang, Yunhe , journal =. From Next-Token to Next-Block: A Principled Adaptation Path for Diffusion
-
[14]
Wu, Zirui and Zheng, Lin and Ye, Jiacheng and Gong, Shansan and Zhao, Xueliang and Feng, Yansong and Bi, Wei and Kong, Lingpeng , journal =
-
[15]
arXiv preprint arXiv:2509.06949 , year=
Revolutionizing Reinforcement Learning Framework for Diffusion Large Language Models , author =. arXiv preprint arXiv:2509.06949 , year =
-
[16]
An, Zihao and Liu, Taichi and Liu, Ziqiong and Li, Dong and Liu, Ruofeng and Barsoum, Emad , journal =
-
[17]
Samarin, Alexander and Krutikov, Sergei and Shevtsov, Anton and Skvortsov, Sergei and Fisin, Filipp and Golubev, Alexander , journal =
-
[18]
Zhang, Liyuan and Zhang, Jiarui and Yao, Jinwei and Yan, Ran and Yang, Yuchen and Zhang, Jiahao and Yang, Tongkai and Wu, Yi and Yuan, Binhang , journal =
-
[19]
Variational Speculative Decoding: Rethinking Draft Training from Token Likelihood to Sequence Acceptance , author =. arXiv preprint arXiv:2602.05774 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Hu, Lanxiang and Feng, Zhaoxiang and Wu, Yulun and Yuan, Haoran and Zhao, Yujie and Qian, Yu-Yang and Wang, Bojun and Zhao, Peng and Jiang, Daxin and Zhu, Yibo and Rosing, Tajana and Zhang, Hao , journal =
-
[21]
Halfway Speculative Decoding: Direct Acceptance Rate Optimization with Joint Drafter-Target Training , author =
-
[22]
Zhang, Yizhou and Chen, Siming and Ye, Hao and Feng, Erhu , booktitle =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.