Lost at the End: Primacy Bias in Multimodal Retrieval-Augmented Question Answering
Pith reviewed 2026-06-29 05:20 UTC · model grok-4.3
The pith
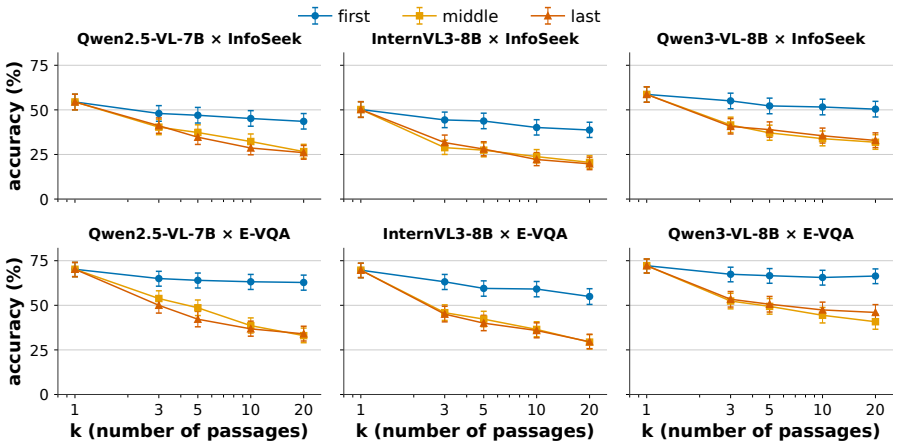
Multimodal KB-VQA readers exhibit a strong primacy bias where the gold passage at the first position outperforms the same passage at the last by 16-26 accuracy points.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
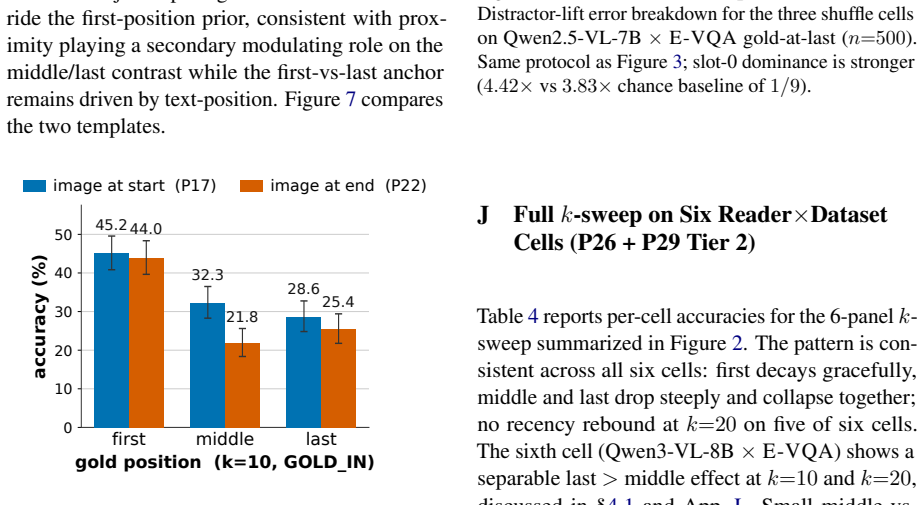
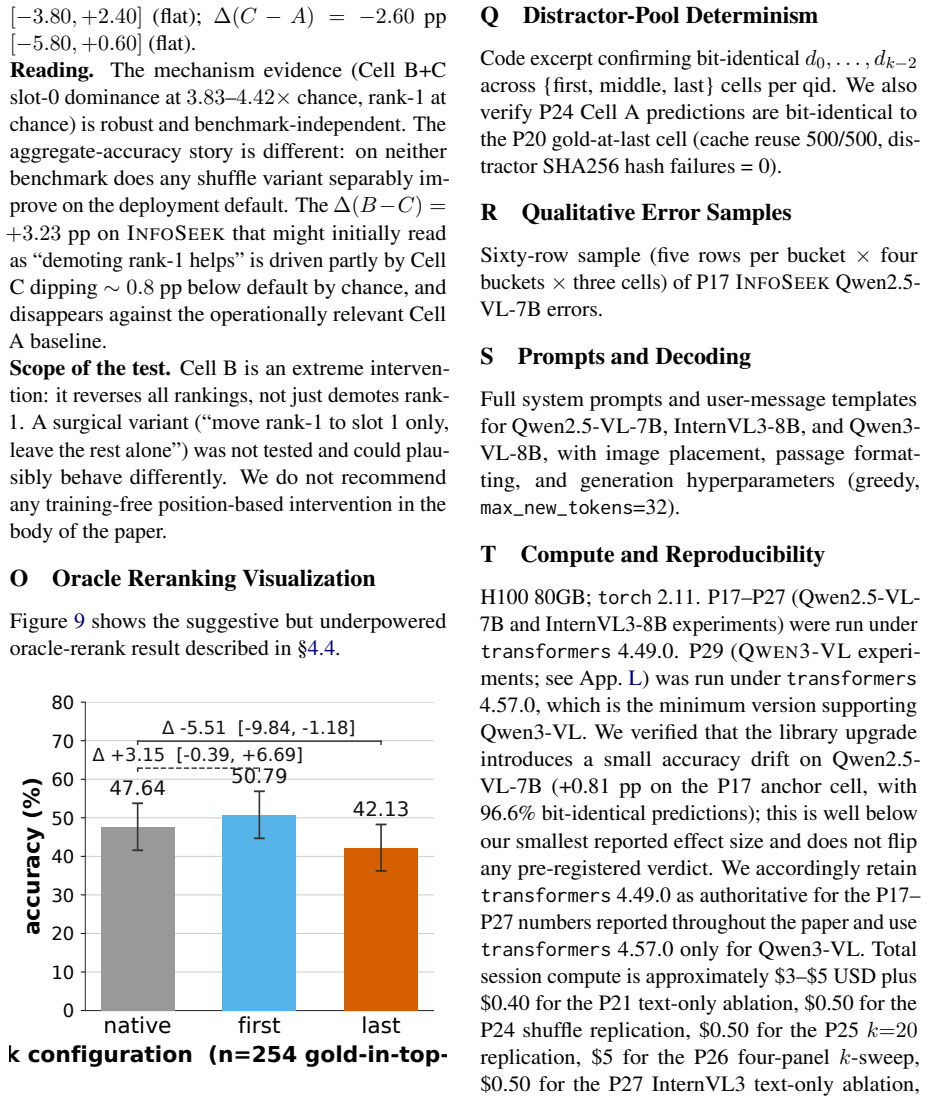
In multimodal KB-VQA the position dependence of retrieved passages is not U-shaped but primacy-driven: across every reader-by-benchmark combination, placing the single gold passage in the first slot yields 16-26 points higher accuracy than placing it in the final slot. The effect is driven by the reader itself rather than by image encoding or distractor content, and standard retrieval fixes do not close it.
What carries the argument
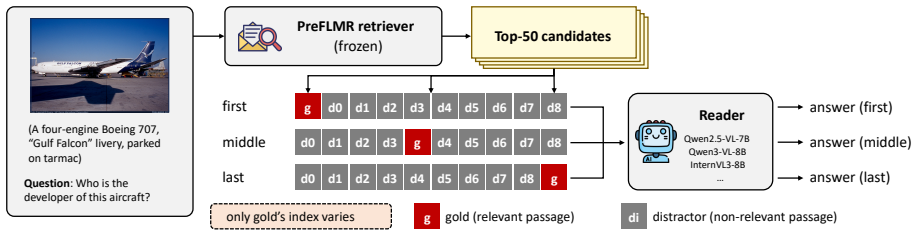
The gold-position protocol, which holds every element fixed except the prompt slot occupied by the single gold passage.
If this is right
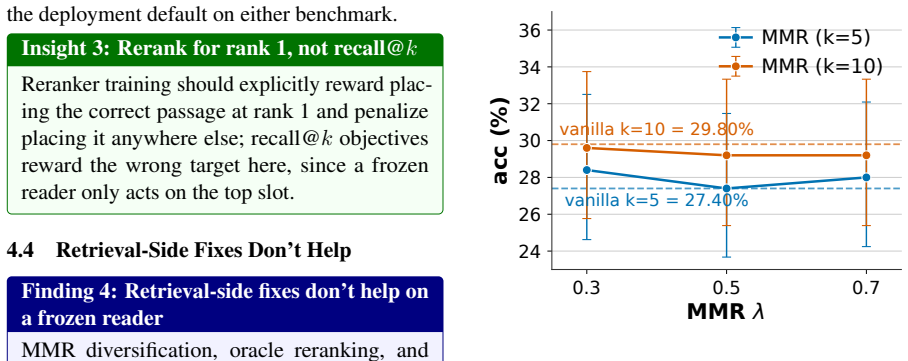
- Recall@k ceases to be a reliable proxy for end-to-end KB-VQA performance once position bias is present.
- Any deployed multimodal system that concatenates multiple retrieved passages will under-use passages that land near the end of the context.
- Reader-side architectural or fine-tuning changes are required to mitigate the bias, because retrieval reordering alone does not help.
- The same protocol can be reused as a diagnostic instrument to measure whether future reader interventions reduce the first-versus-last gap.
Where Pith is reading between the lines
- Systems that dynamically reorder passages based on reader attention patterns could be tested with this protocol to see whether they restore more uniform position use.
- The amplification from text to multimodal may point to competition between visual tokens and late text tokens for the reader's limited attention budget.
- If the bias is strongest at the very first slot, instruction-tuning data that always places key facts first could be a cheap source of the observed behavior.
Load-bearing premise
Varying only the gold passage's slot inside the prompt is enough to isolate reader-side position effects without leftover confounds from image features or question phrasing.
What would settle it
Running the same gold-position sweeps on the same readers and benchmarks and observing no consistent 16-plus-point gap between first and last placement.
Figures


read the original abstract
Knowledge-based visual question answering (KB-VQA) lets vision-language systems answer questions that exceed their parametric knowledge by conditioning a reader on passages retrieved from a Wikipedia-scale knowledge base. In pure-text long-context LLMs, retrieved-context use follows the U-shaped "lost-in-the-middle" effect of Liu et al. (2024): information at the start and end of context is used, the middle is lost. Whether this transfers to deployed multimodal KB-VQA is open. To close this gap, we design the first controlled probe of reader-side position dependence in multimodal KB-VQA: a gold-position protocol in which only the gold passage's prompt slot varies within question. We run it on three open-source 7B/8B VLM readers and two KB-VQA benchmarks at k up to 20. The shape flips from U to primacy: gold-at-first beats gold-at-last by 16 to 26 points on every reader-by-benchmark cell, an effect we call "Lost at the End". Three targeted ablations narrow the cause: a text-only control shows the multimodal setting amplifies an already-present text-mode primacy 2.2 to 4.5 times, and image-position and distractor-shuffle ablations together pin the locus to prompt slot 0 of the instruction-tuned reader. On a frozen reader, three retrieval-side fixes (MMR, oracle reranking, rank-based reordering) all leave the gap intact (no separable improvement). Our findings indicate that recall@k is the wrong metric for deployed KB-VQA and that closing the gap requires reader-side intervention; we release our protocol as a controlled instrument for evaluating such interventions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a gold-position protocol for probing reader-side position dependence in multimodal KB-VQA, where only the slot of the gold passage varies while holding other elements fixed. Across three 7B/8B VLMs and two benchmarks at k≤20, it reports a primacy bias ('Lost at the End') in which gold-at-first outperforms gold-at-last by 16–26 points on every reader-by-benchmark cell, flipping the U-shape observed in text-only long-context models. Targeted ablations (text-only control, image-position, distractor-shuffle) attribute the effect to amplification of text-mode primacy in the multimodal setting and localization at prompt slot 0; retrieval-side interventions (MMR, oracle reranking, rank reordering) leave the gap intact on a frozen reader. The protocol is released for evaluating reader-side fixes.
Significance. If the primacy effect is shown to be isolated from template or encoding confounds, the result would be significant for KB-VQA deployment: it implies recall@k is an incomplete metric and that reader-side interventions are required. The controlled gold-position design and the three ablations that narrow the locus constitute a clear empirical contribution; releasing the protocol adds reproducibility value. The directional consistency across cells is a strength, but the lack of error bars or tests noted in the review limits assessment of effect reliability.
major comments (3)
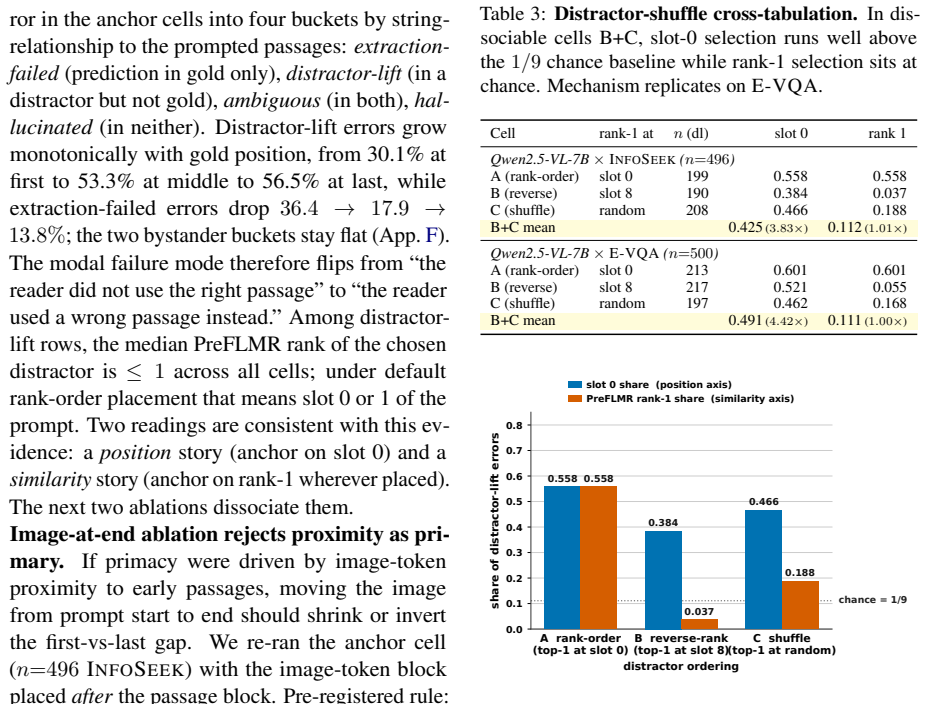
- [Methods] Methods (gold-position protocol description): the protocol is claimed to vary only the gold passage's prompt slot while keeping prompt formatting, image encoding order, and distractor content fixed, yet the text does not explicitly state that a single fixed template with k slots is instantiated for every position. This is load-bearing for the central 16–26 point claim, because any position-dependent template artifact (e.g., special first-slot handling or image-token ordering) could contribute to the measured gap.
- [Results] Results (performance tables or figures reporting the 16–26 point gaps): no error bars, standard deviations across runs, or statistical significance tests are mentioned, despite the abstract claiming 'consistent directional results.' This undermines confidence that the reported effect sizes exceed noise, especially given the low soundness rating on exclusion criteria and post-hoc choices.
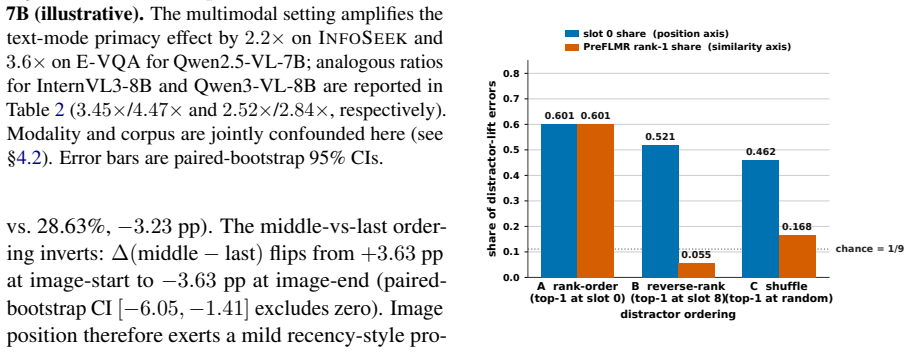
- [Ablations] Ablations (text-only control and image-position ablation): while these narrow the cause to the multimodal reader, the text-only control is reported to amplify the text-mode primacy by 2.2–4.5×, but without quantitative details on how the multimodal prompt template was matched to the text-only version, residual differences in tokenization or instruction formatting cannot be ruled out as partial contributors.
minor comments (2)
- Figure captions or tables should include the exact number of questions per benchmark and the precise k values used for each reported cell to allow direct replication.
- [Abstract] The abstract states 'three open-source 7B/8B VLM readers' but does not name the models; this should be added for clarity even if named later in the text.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our gold-position protocol and strengthen the empirical claims. We address each major comment below.
read point-by-point responses
-
Referee: [Methods] Methods (gold-position protocol description): the protocol is claimed to vary only the gold passage's prompt slot while keeping prompt formatting, image encoding order, and distractor content fixed, yet the text does not explicitly state that a single fixed template with k slots is instantiated for every position. This is load-bearing for the central 16–26 point claim, because any position-dependent template artifact (e.g., special first-slot handling or image-token ordering) could contribute to the measured gap.
Authors: We agree that the current Methods description would benefit from an explicit statement confirming use of a single fixed template. In the revised manuscript we will add the following sentence: 'Across all positions p we instantiate one fixed k-slot template; only the slot index receiving the gold passage changes while distractor content, formatting tokens, and image encoding order remain identical.' This directly rules out template artifacts as a source of the reported gap. revision: yes
-
Referee: [Results] Results (performance tables or figures reporting the 16–26 point gaps): no error bars, standard deviations across runs, or statistical significance tests are mentioned, despite the abstract claiming 'consistent directional results.' This undermines confidence that the reported effect sizes exceed noise, especially given the low soundness rating on exclusion criteria and post-hoc choices.
Authors: We accept that the absence of variability measures weakens the presentation. In revision we will add standard deviations computed over three random seeds for retrieval ordering (where stochastic) and include paired significance tests (McNemar) between gold-first and gold-last conditions in all tables and figures. These additions will be reported for every reader-by-benchmark cell. revision: yes
-
Referee: [Ablations] Ablations (text-only control and image-position ablation): while these narrow the cause to the multimodal reader, the text-only control is reported to amplify the text-mode primacy by 2.2–4.5×, but without quantitative details on how the multimodal prompt template was matched to the text-only version, residual differences in tokenization or instruction formatting cannot be ruled out as partial contributors.
Authors: We will expand the ablation subsection with the requested quantitative details: we will report the exact token counts for the multimodal versus text-only templates (differing only by image tokens), list all instruction tokens that were retained or removed, and note any tokenizer-specific special tokens. These numbers will be added to the text-only control paragraph so readers can evaluate residual formatting differences. revision: yes
Circularity Check
No circularity: purely empirical measurements with no derivations or fitted predictions
full rationale
The paper reports direct experimental results from a gold-position protocol and targeted ablations on VLM readers. No equations, parameters fitted to subsets then re-predicted, self-citations used as load-bearing uniqueness theorems, or ansatzes appear in the provided text. The central claim (16-26 point primacy gap) is a measured difference under controlled variation of gold slot only; it does not reduce to any input quantity by construction. This is the normal case of an empirical study whose validity rests on experimental controls rather than algebraic identity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The gold-position protocol isolates reader-side position dependence without residual confounds from image encoding, distractor content, or benchmark-specific question phrasing.
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, and 8 others. 2025. https://arxiv.org/abs/2502.13923 Qwen2.5-vl technical report . arXiv preprint arXiv:2502.13923
Pith/arXiv arXiv 2025
-
[2]
Davide Caffagni, Federico Cocchi, Nicholas Moratelli, Sara Sarto, Marcella Cornia, Lorenzo Baraldi, and Rita Cucchiara. 2024. Wiki-LLaVA : Hierarchical retrieval-augmented generation for multimodal LLMs . In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pages 1818--1826
2024
-
[3]
Jaime Carbonell and Jade Goldstein. 1998. https://doi.org/10.1145/290941.291025 The use of MMR , diversity-based reranking for reordering documents and producing summaries . In Proceedings of the 21st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 335--336
-
[4]
Shijie Chen, Bernal Jim \'e nez Guti \'e rrez, and Yu Su. 2025. https://arxiv.org/abs/2410.02642 Attention in large language models yields efficient zero-shot re-rankers . In The Thirteenth International Conference on Learning Representations (ICLR)
arXiv 2025
-
[5]
Yang Chen, Hexiang Hu, Yi Luan, Haitian Sun, Soravit Changpinyo, Alan Ritter, and Ming-Wei Chang. 2023. Can pre-trained vision and language models answer visual information-seeking questions? In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 14948--14968
2023
-
[6]
Federico Cocchi, Nicholas Moratelli, Marcella Cornia, Lorenzo Baraldi, and Rita Cucchiara. 2025. Augmenting multimodal LLMs with self-reflective tokens for knowledge-based visual question answering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9199--9209
2025
-
[7]
Florin Cuconasu, Simone Filice, Guy Horowitz, Yoelle Maarek, and Fabrizio Silvestri. 2025. Do RAG systems really suffer from positional bias? In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 28022--28036, Suzhou, China
2025
-
[8]
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, and Steven Hoi. 2023. https://arxiv.org/abs/2305.06500 InstructBLIP : Towards general-purpose vision-language models with instruction tuning . In Advances in Neural Information Processing Systems (NeurIPS)
Pith/arXiv arXiv 2023
-
[9]
Le, Abhishek Kumar, James Glass, Alexander Ratner, Chen-Yu Lee, Ranjay Krishna, and Tomas Pfister
Cheng-Yu Hsieh, Yung-Sung Chuang, Chun-Liang Li, Zifeng Wang, Long T. Le, Abhishek Kumar, James Glass, Alexander Ratner, Chen-Yu Lee, Ranjay Krishna, and Tomas Pfister. 2024. Found in the middle: Calibrating positional attention bias improves long context utilization. In Findings of the Association for Computational Linguistics (ACL), pages 14982--14995
2024
-
[10]
Chan-Wei Hu, Yueqi Wang, Shuo Xing, Chia-Ju Chen, Suofei Feng, Ryan Rossi, and Zhengzhong Tu. 2025. https://arxiv.org/abs/2505.24073 mRAG : Elucidating the design space of multi-modal retrieval-augmented generation . arXiv preprint arXiv:2505.24073
arXiv 2025
-
[11]
Jan Hutter, David Rau, Maarten Marx, and Jaap Kamps. 2025. Lost but not only in the middle: Positional bias in retrieval augmented generation. In Advances in Information Retrieval (ECIR), volume 15572 of LNCS, pages 247--261. Springer
2025
-
[12]
Omar Khattab and Matei Zaharia. 2020. https://doi.org/10.1145/3397271.3401075 ColBERT : Efficient and effective passage search via contextualized late interaction over BERT . In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 39--48
-
[13]
Weizhe Lin, Jingbiao Mei, Jinghong Chen, and Bill Byrne. 2024. PreFLMR : Scaling up fine-grained late-interaction multi-modal retrievers. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), pages 5294--5316
2024
-
[14]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. https://arxiv.org/abs/2304.08485 Visual instruction tuning . In Advances in Neural Information Processing Systems (NeurIPS)
Pith/arXiv arXiv 2023
-
[15]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. https://doi.org/10.1162/tacl_a_00638 Lost in the middle: How language models use long contexts . Transactions of the Association for Computational Linguistics, 12:157--173
-
[16]
Yao Lu, Max Bartolo, Alastair Moore, Sebastian Riedel, and Pontus Stenetorp. 2022. Fantastically ordered prompts and where to find them: Overcoming few-shot prompt order sensitivity. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL), pages 8086--8098
2022
-
[17]
Thomas Mensink, Jasper Uijlings, Lluis Castrejon, Arushi Goel, Felipe Cadar, Howard Zhou, Fei Sha, Andr \'e Araujo, and Vittorio Ferrari. 2023. Encyclopedic VQA : Visual questions about detailed properties of fine-grained categories. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 3113--3124
2023
-
[18]
OpenAI . 2023. GPT-4V(ision) system card. https://openai.com/index/gpt-4v-system-card/
2023
-
[19]
Ofir Press, Noah A. Smith, and Mike Lewis. 2022. https://arxiv.org/abs/2108.12409 Train short, test long: Attention with linear biases enables input length extrapolation . In The Tenth International Conference on Learning Representations (ICLR)
Pith/arXiv arXiv 2022
-
[20]
Qwen Team . 2025. https://arxiv.org/abs/2511.21631 Qwen3-vl technical report . arXiv preprint arXiv:2511.21631
Pith/arXiv arXiv 2025
-
[21]
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. 2024. https://doi.org/10.1016/j.neucom.2023.127063 RoFormer : Enhanced transformer with rotary position embedding . Neurocomputing, 568:127063
-
[22]
Zhijie Tan, Xu Chu, Weiping Li, and Tong Mo. 2024. https://arxiv.org/abs/2410.16983 Order matters: Exploring order sensitivity in multimodal large language models . arXiv preprint arXiv:2410.16983
arXiv 2024
-
[23]
Raphael Tang, Crystina Zhang, Xueguang Ma, Jimmy Lin, and Ferhan Ture. 2024. https://aclanthology.org/2024.naacl-long.129/ Found in the middle: Permutation self-consistency improves listwise ranking in large language models . In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Languag...
2024
-
[24]
Xinyu Tian, Shu Zou, Zhaoyuan Yang, and Jing Zhang. 2025. Identifying and mitigating position bias of multi-image vision-language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10599--10609
2025
-
[25]
Kebin Wu and Fatima Albreiki. 2025. https://arxiv.org/abs/2511.11216 Positional bias in multimodal embedding models: Do they favor the beginning, the middle, or the end? arXiv preprint arXiv:2511.11216
arXiv 2025
-
[26]
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. 2024. https://arxiv.org/abs/2309.17453 Efficient streaming language models with attention sinks . In The Twelfth International Conference on Learning Representations (ICLR)
Pith/arXiv arXiv 2024
-
[27]
Yibin Yan and Weidi Xie. 2024. EchoSight : Advancing visual-language models with wiki knowledge. In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 1538--1551, Miami, Florida, USA
2024
-
[28]
Jiayu Yao, Shenghua Liu, Yiwei Wang, Lingrui Mei, Baolong Bi, Yuyao Ge, Zhecheng Li, and Xueqi Cheng. 2025. Who is in the spotlight: The hidden bias undermining multimodal retrieval-augmented generation. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 15183--15193
2025
-
[29]
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, Zhangwei Gao, Erfei Cui, Xuehui Wang, Yue Cao, Yangzhou Liu, Xingguang Wei, Hongjie Zhang, Haomin Wang, Weiye Xu, and 32 others. 2025. https://arxiv.org/abs/2504.10479 InternVL3 : Exploring advanced training and test-time recipes for open-s...
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.