READ More than What You See: Reinforcement Learning for Accurate and Coherent Audio Description Generations
Pith reviewed 2026-06-26 09:07 UTC · model grok-4.3
The pith
Reinforcement learning with multiple rewards including narrative coherence produces more accurate audio descriptions than prompting or standard training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
READ formulates audio description generation as sequence-level reinforcement learning optimization using reference-matching, length, format, and coherence rewards under context-aware supervision, and it substantially outperforms prior methods across diverse evaluation metrics on MAD-Eval, CMD-AD, and TV-AD.
What carries the argument
The coherence reward under context-aware supervision, which promotes narratively coherent descriptions as part of the sequence-level RL optimization.
If this is right
- RL can replace next-token prediction or prompting for training-based AD systems.
- Combining reference, length, format, and coherence rewards yields gains across multiple metrics.
- The framework applies across MAD-Eval, CMD-AD, and TV-AD datasets.
- RL constitutes a promising paradigm for accurate and coherent AD generation.
Where Pith is reading between the lines
- The reward structure could extend to other video-to-text tasks where narrative consistency matters.
- Context-aware supervision might help reduce generic outputs in related multimodal generation settings.
- Public release of codes, models, and benchmark results enables direct replication and extension on new media.
- The approach could be tested on live or streaming content to check real-time coherence.
Load-bearing premise
The coherence reward under context-aware supervision produces narratively coherent descriptions that generalize beyond the training distribution rather than merely fitting the reward model.
What would settle it
A human evaluation study on new unseen videos where READ descriptions receive equal or lower coherence and narrative flow ratings than strong baselines would falsify the central performance claim.
Figures
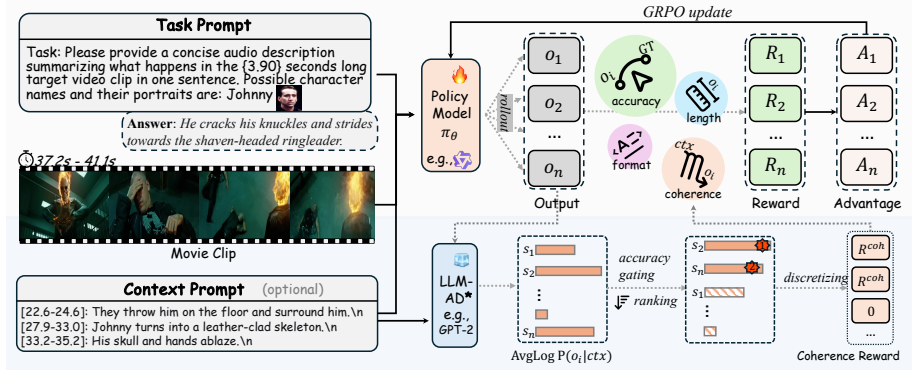


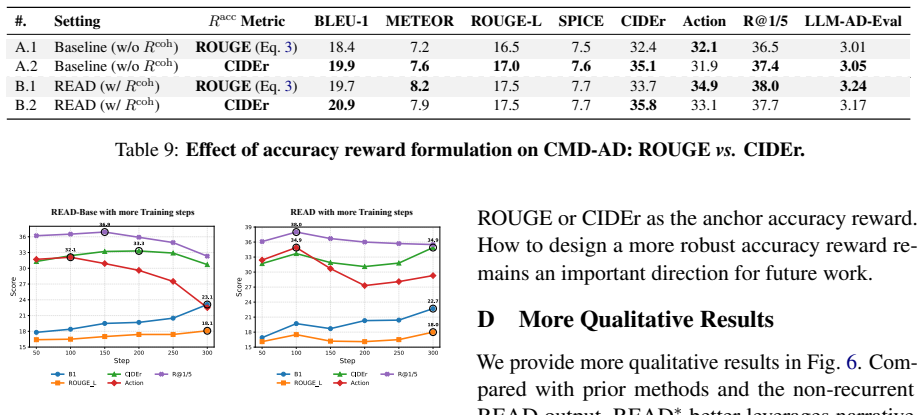

read the original abstract
Audio Description aims to generate concise narrations of essential visual content in audio-visual media for blind and low-vision audiences. Existing methods either rely on prompting off-the-shelf multimodal models, which often mismatch AD style, or partially optimize training-based systems with next-token prediction, which under-explores model capacity and biases generation toward generic expressions. We present READ, the first reinforcement-learning (RL) framework for training-based AD generation. READ formulates AD as sequence-level optimization with reference-matching, length, and format rewards, and further introduces a dedicated coherence reward under context-aware supervision to promote narratively coherent descriptions. Experiments on MAD-Eval, CMD-AD, and TV-AD show that READ substantially outperforms prior methods across diverse evaluation metrics. Our results highlight RL as a promising paradigm for accurate and coherent AD generation. Our codes, models, and benchmark results will be publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents READ, the first reinforcement-learning framework for training-based audio description (AD) generation. It formulates the task as sequence-level optimization using reference-matching, length, and format rewards, plus a dedicated coherence reward under context-aware supervision, and reports substantial outperformance over prior methods on the MAD-Eval, CMD-AD, and TV-AD benchmarks across diverse metrics.
Significance. If the empirical results hold after verification of the reward formulations and generalization, the work would establish RL as a promising direction for AD generation, addressing style mismatch in prompting-based methods and the limitations of next-token prediction. The planned public release of codes, models, and benchmark results is a clear strength that would support reproducibility.
major comments (2)
- [Abstract] Abstract: The central claim that the coherence reward under context-aware supervision produces narratively coherent ADs that generalize rests on an unverified assumption; the reward is derived from the same supervision distribution used for training, yet no explicit check (e.g., correlation with independent human coherence judgments on held-out contexts or ablation isolating the coherence term) is described to rule out reward-model fitting.
- [Experiments] Experiments (MAD-Eval, CMD-AD, TV-AD results): The reported gains are presented without reference to ablation tables or training curves that would isolate the contribution of the coherence reward versus the reference-matching/length/format terms; without these, it is impossible to confirm that the coherence component drives the claimed narrative improvements rather than proxy fitting.
minor comments (1)
- [Abstract] The abstract states that codes and models will be publicly available; the final version should include a concrete link or repository identifier.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive feedback. We address each major comment below and will revise the manuscript to incorporate additional analyses that strengthen the validation of the coherence reward.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the coherence reward under context-aware supervision produces narratively coherent ADs that generalize rests on an unverified assumption; the reward is derived from the same supervision distribution used for training, yet no explicit check (e.g., correlation with independent human coherence judgments on held-out contexts or ablation isolating the coherence term) is described to rule out reward-model fitting.
Authors: We appreciate the referee's concern regarding the verification of the coherence reward. Although the overall framework shows strong performance on held-out test sets, we recognize the value of explicit checks to rule out fitting to the supervision distribution. In the revision, we will add an ablation isolating the coherence term's contribution and perform a correlation analysis between the reward scores and independent human coherence judgments on held-out contexts. revision: yes
-
Referee: [Experiments] Experiments (MAD-Eval, CMD-AD, TV-AD results): The reported gains are presented without reference to ablation tables or training curves that would isolate the contribution of the coherence reward versus the reference-matching/length/format terms; without these, it is impossible to confirm that the coherence component drives the claimed narrative improvements rather than proxy fitting.
Authors: We agree that the manuscript would benefit from explicit ablations to isolate the effects of each reward component. The revised version will include ablation tables comparing the full READ model against variants without the coherence reward, as well as training curves that track the individual reward terms during RL optimization. This will provide clearer evidence that the coherence reward contributes to the observed improvements in narrative coherence. revision: yes
Circularity Check
No significant circularity; RL framework and rewards are independently defined
full rationale
The paper defines READ as an RL framework using explicitly stated rewards (reference-matching, length, format, and coherence under context-aware supervision) and evaluates empirically on external benchmarks MAD-Eval, CMD-AD, TV-AD. No equations, self-citations, or derivations are shown that reduce claims to inputs by construction, fitted parameters renamed as predictions, or self-referential uniqueness theorems. The central results rest on standard RL optimization and held-out evaluation rather than tautological reductions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
Proceedings of the 33rd Annual ACM Symposium on User Interface Software and Technology , pages=
Rescribe: Authoring and automatically editing audio descriptions , author=. Proceedings of the 33rd Annual ACM Symposium on User Interface Software and Technology , pages=
-
[9]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
What You See is What You Ask: Evaluating Audio Descriptions , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[10]
Proceedings of the IEEE international conference on computer vision , pages=
Dense-captioning events in videos , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[11]
arXiv preprint arXiv:2510.25440 , year=
More than a Moment: Towards Coherent Sequences of Audio Descriptions , author=. arXiv preprint arXiv:2510.25440 , year=
-
[12]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Shot-by-Shot: Film-Grammar-Aware Training-Free Audio Description Generation , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[13]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
DistinctAD: Distinctive audio description generation in contexts , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[14]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Autoad iii: The prequel-back to the pixels , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[15]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Autoad ii: The sequel-who, when, and what in movie audio description , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[16]
Proceedings of the Asian Conference on Computer Vision , pages=
Autoad-zero: A training-free framework for zero-shot audio description , author=. Proceedings of the Asian Conference on Computer Vision , pages=
-
[17]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Autoad: Movie description in context , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[18]
2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) , pages=
Now you see me: Context-aware automatic audio description , author=. 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) , pages=. 2025 , organization=
2025
-
[19]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Contextual ad narration with interleaved multimodal sequence , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[20]
European Conference on Computer Vision , pages=
Learning video context as interleaved multimodal sequences , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[21]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Mm-narrator: Narrating long-form videos with multimodal in-context learning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[22]
Proceedings of the 2023 conference on empirical methods in natural language processing: system demonstrations , pages=
Video-llama: An instruction-tuned audio-visual language model for video understanding , author=. Proceedings of the 2023 conference on empirical methods in natural language processing: system demonstrations , pages=
2023
-
[23]
arXiv preprint arXiv:2405.00983 , year=
LLM-AD: Large language model based audio description system , author=. arXiv preprint arXiv:2405.00983 , year=
-
[24]
arXiv preprint arXiv:2504.12157 , year=
Focusedad: Character-centric movie audio description , author=. arXiv preprint arXiv:2504.12157 , year=
-
[25]
OneThinker: All-in-one Reasoning Model for Image and Video
Onethinker: All-in-one reasoning model for image and video , author=. arXiv preprint arXiv:2512.03043 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Qwen3-vl technical report , author=. arXiv preprint arXiv:2511.21631 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Qwen2-vl: Enhancing vision-language model's perception of the world at any resolution , author=. arXiv preprint arXiv:2409.12191 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Gpt-4o system card , author=. arXiv preprint arXiv:2410.21276 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Openai gpt-5 system card , author=. arXiv preprint arXiv:2601.03267 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) , pages=
MMAD: Multi-modal movie audio description , author=. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) , pages=
2024
-
[31]
Proceedings of the Winter Conference on Applications of Computer Vision , pages=
NarrAD: Automatic generation of audio descriptions for movies with rich narrative context , author=. Proceedings of the Winter Conference on Applications of Computer Vision , pages=
-
[32]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[33]
Text summarization branches out , pages=
Rouge: A package for automatic evaluation of summaries , author=. Text summarization branches out , pages=
-
[34]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Cider: Consensus-based image description evaluation , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[35]
European conference on computer vision , pages=
Spice: Semantic propositional image caption evaluation , author=. European conference on computer vision , pages=. 2016 , organization=
2016
-
[36]
BERTScore: Evaluating Text Generation with BERT
Bertscore: Evaluating text generation with bert , author=. arXiv preprint arXiv:1904.09675 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[37]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Mad: A scalable dataset for language grounding in videos from movie audio descriptions , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[38]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models
Vision-r1: Incentivizing reasoning capability in multimodal large language models , author=. arXiv preprint arXiv:2503.06749 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
arXiv e-prints , pages=
Openvlthinker: An early exploration to complex vision-language reasoning via iterative self-improvement , author=. arXiv e-prints , pages=
-
[42]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
Proceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization , pages=
METEOR: An automatic metric for MT evaluation with improved correlation with human judgments , author=. Proceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization , pages=
-
[44]
Proceedings of the 40th annual meeting of the Association for Computational Linguistics , pages=
Bleu: a method for automatic evaluation of machine translation , author=. Proceedings of the 40th annual meeting of the Association for Computational Linguistics , pages=
-
[45]
Proceedings of the Asian Conference on Computer Vision , year=
Condensed movies: Story based retrieval with contextual embeddings , author=. Proceedings of the Asian Conference on Computer Vision , year=
-
[46]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
A dataset for movie description , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[47]
Proceedings of the 2018 conference on empirical methods in natural language processing , pages=
Tvqa: Localized, compositional video question answering , author=. Proceedings of the 2018 conference on empirical methods in natural language processing , pages=
2018
-
[48]
arXiv preprint arXiv:2111.09734 , year=
Clipcap: Clip prefix for image captioning , author=. arXiv preprint arXiv:2111.09734 , year=
-
[49]
Findings of the Association for Computational Linguistics: EMNLP 2022 , pages=
Text-only training for image captioning using noise-injected clip , author=. Findings of the Association for Computational Linguistics: EMNLP 2022 , pages=
2022
-
[50]
arXiv preprint arXiv:2310.19773 , year=
Mm-vid: Advancing video understanding with gpt-4v (ision) , author=. arXiv preprint arXiv:2310.19773 , year=
-
[51]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Llama 2: Open foundation and fine-tuned chat models , author=. arXiv preprint arXiv:2307.09288 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[52]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
OpenAI blog , volume=
Language models are unsupervised multitask learners , author=. OpenAI blog , volume=
-
[54]
Journal of Visual Impairment & Blindness , volume=
Livedescribe: can amateur describers create high-quality audio description? , author=. Journal of Visual Impairment & Blindness , volume=. 2012 , publisher=
2012
-
[55]
Sequence Level Training with Recurrent Neural Networks
Sequence level training with recurrent neural networks , author=. arXiv preprint arXiv:1511.06732 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[56]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Self-critical sequence training for image captioning , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[57]
A Deep Reinforced Model for Abstractive Summarization
A deep reinforced model for abstractive summarization , author=. arXiv preprint arXiv:1705.04304 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[58]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[59]
Information processing & management , volume=
Term-weighting approaches in automatic text retrieval , author=. Information processing & management , volume=. 1988 , publisher=
1988
-
[60]
Proceedings of the Twentieth European Conference on Computer Systems , pages=
Hybridflow: A flexible and efficient rlhf framework , author=. Proceedings of the Twentieth European Conference on Computer Systems , pages=
-
[61]
AudioVault , howpublished =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.