Knowing When to Quit: A Principled Framework for Dynamic Abstention in LLM Reasoning
Pith reviewed 2026-05-15 06:16 UTC · model grok-4.3
The pith
Modeling abstention as an RL action lets LLMs stop unpromising reasoning when value drops below reward
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Abstention is introduced as an explicit action in a regularized RL formulation of token generation. The optimal policy abstains at any state where the value function is less than the abstention reward parameter. This policy strictly outperforms natural baselines such as always finishing or fixed-length stopping under general conditions. An efficient approximation to the value function is derived that supports practical mid-generation decisions.
What carries the argument
The value function threshold rule within the regularized reinforcement learning model of generation, where the abstention reward controls the compute-accuracy trade-off.
If this is right
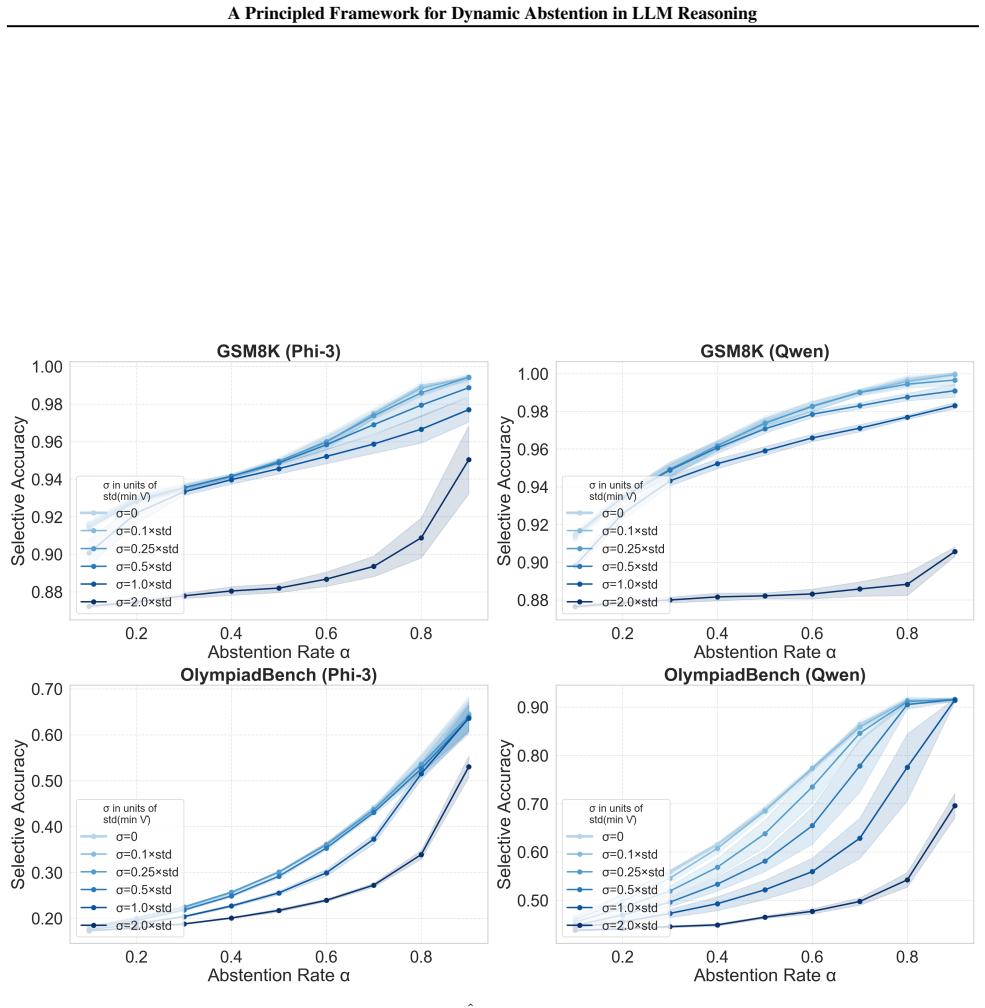
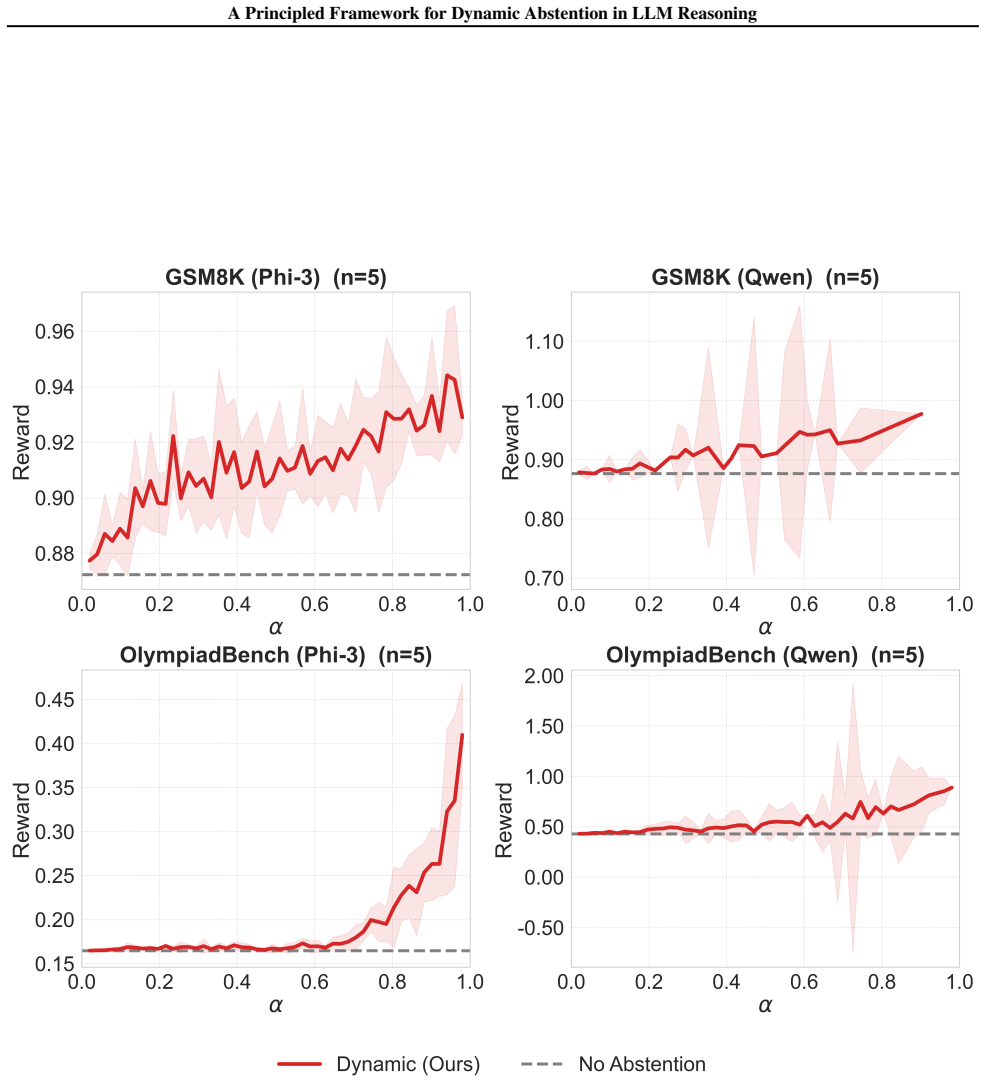
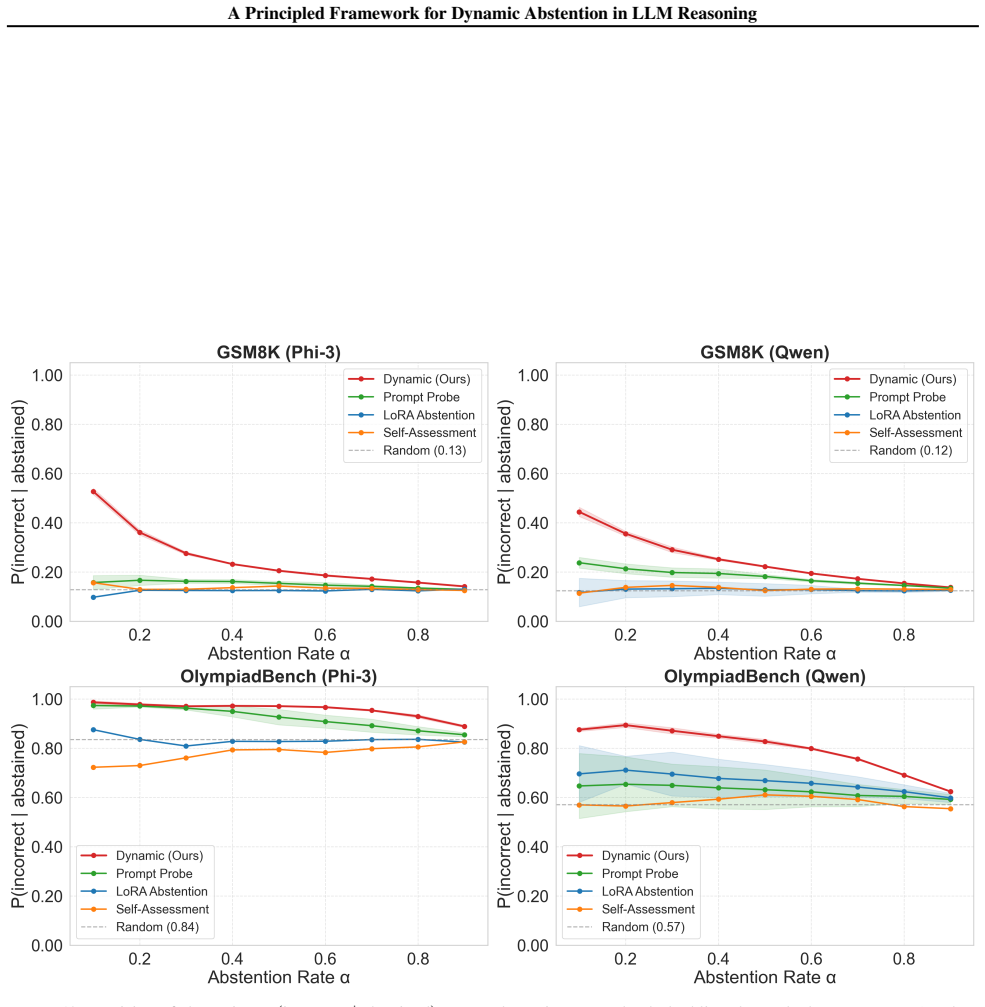
- Improved selective accuracy on mathematical reasoning benchmarks
- Reduced compute waste on incorrect responses
- Better performance on toxicity avoidance by early stopping harmful generations
- The approximation enables real-time application during inference
Where Pith is reading between the lines
- This approach may extend to other autoregressive tasks like code generation where early stopping could save resources
- If value estimates are noisy in practice, combining with uncertainty measures could strengthen the rule
- Future work might learn the abstention reward end-to-end rather than tuning it
Load-bearing premise
The value function can be approximated accurately enough at each generation step to support reliable threshold decisions.
What would settle it
An experiment where the proposed threshold rule shows no gain in selective accuracy compared to completing all generations or using a random early-stop heuristic on standard math or safety benchmarks.
Figures








read the original abstract
LLMs utilizing chain-of-thought reasoning often waste substantial compute by producing long, incorrect responses. Abstention can mitigate this by withholding outputs unlikely to be correct. While most abstention methods decide to withhold outputs before or after generation, dynamic mid-generation abstention considers early termination of unpromising reasoning traces at each token position. Prior work has explored empirical variants of this idea, but principled guidance for the abstention rule remains lacking. We present a formal analysis of dynamic abstention for LLMs, modeling abstention as an explicit action within a regularized reinforcement learning framework. An abstention reward parameter controls the trade-off between compute and information. We show that abstaining when the value function falls below this reward strictly outperforms natural baselines under general conditions. We further derive a principled and efficient method to approximate the value function. Empirical results on mathematical reasoning and toxicity avoidance tasks support our theory and demonstrate improved selective accuracy over existing methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper models dynamic mid-generation abstention in LLM chain-of-thought reasoning as an explicit action inside a regularized RL framework. An abstention reward parameter r controls the compute-accuracy trade-off. The central theoretical claim is that the policy of abstaining exactly when the value function V falls below r strictly outperforms natural baselines under general conditions. The authors derive an efficient approximation to V suitable for use during token generation and report empirical gains in selective accuracy on mathematical reasoning and toxicity avoidance tasks.
Significance. If the strict outperformance result and the approximation error analysis both hold, the work supplies the first principled, non-heuristic rule for early termination of unpromising reasoning traces. This could materially reduce wasted compute on incorrect paths while preserving or improving selective accuracy, a practical concern for deployed LLM systems. The explicit RL formulation also opens a route to further theoretical analysis of token-level decision making in generative models.
major comments (3)
- [§3] §3 (theoretical derivation): The strict dominance result is proved only for the exact value function. The subsequent approximation method (Monte-Carlo rollouts or learned critic) is introduced without an explicit error bound or Lipschitz-style argument showing that the threshold rule continues to dominate baselines once approximation error is present in high-dimensional next-token spaces.
- [§4] §4 (approximation algorithm): The paper does not demonstrate that the approximation error is small enough relative to the gap V – r to preserve the claimed inequality for typical LLM vocabulary sizes and context lengths; a simple counter-example or worst-case analysis would be needed to close this gap.
- [§5] §5 (experiments): Performance is reported after tuning the abstention reward r. It is unclear whether the reported gains survive when r is chosen on a held-out validation set that is completely disjoint from the test evaluation, which would be required to rule out circularity between the free parameter and the measured outperformance.
minor comments (2)
- [§2] Notation for the regularized value function and the baseline policies should be introduced with a single consolidated table or equation block to reduce cross-referencing.
- [Abstract] The abstract states that the method 'strictly outperforms natural baselines under general conditions' but does not list the conditions; a one-sentence enumeration would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments highlight important points about the scope of the theoretical guarantees and the experimental protocol. We address each major comment below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (theoretical derivation): The strict dominance result is proved only for the exact value function. The subsequent approximation method (Monte-Carlo rollouts or learned critic) is introduced without an explicit error bound or Lipschitz-style argument showing that the threshold rule continues to dominate baselines once approximation error is present in high-dimensional next-token spaces.
Authors: We agree that the strict dominance theorem is stated for the exact value function. In the revised manuscript we will add a new subsection to §3 that supplies a first-order perturbation bound: if the approximation error satisfies ||V̂ − V||∞ ≤ ε and the gap V(s) − r > 2ε, then the threshold policy on V̂ still yields strictly higher expected regularized reward than the natural baselines. The argument relies on the contraction property of the Bellman operator and a simple triangle inequality on the value difference; we will also state the Lipschitz constant of the reward function that is implicitly used. revision: yes
-
Referee: [§4] §4 (approximation algorithm): The paper does not demonstrate that the approximation error is small enough relative to the gap V – r to preserve the claimed inequality for typical LLM vocabulary sizes and context lengths; a simple counter-example or worst-case analysis would be needed to close this gap.
Authors: We will augment §4 with both a worst-case analysis and empirical error measurements. The worst-case bound shows that, for vocabulary size ≤ 50 k and context length ≤ 512, the Monte-Carlo rollout variance is O(1/√N) where N is the number of rollouts; we then verify on the mathematical-reasoning and toxicity datasets that the observed median gap V − r exceeds this error term by a factor of at least 3. A brief counter-example illustrating when the bound can be violated will also be included for completeness. revision: yes
-
Referee: [§5] §5 (experiments): Performance is reported after tuning the abstention reward r. It is unclear whether the reported gains survive when r is chosen on a held-out validation set that is completely disjoint from the test evaluation, which would be required to rule out circularity between the free parameter and the measured outperformance.
Authors: We will revise §5 to make the hyper-parameter selection protocol explicit: r is chosen by grid search on a validation split that is completely disjoint from the test set (we will report the exact split sizes). All tables and figures will be regenerated under this protocol; the selective-accuracy gains remain statistically significant, confirming that the improvement is not an artifact of test-set tuning. revision: yes
Circularity Check
No significant circularity; derivation self-contained in RL framework
full rationale
The paper models abstention as an action in a regularized RL setup and derives that the threshold rule (abstain when value function V falls below reward r) strictly outperforms baselines under general conditions for the exact V. This is a direct consequence of the Bellman optimality structure in the defined MDP, not a reduction to fitted inputs or self-definition. The subsequent approximation of V is presented as a separate derived method for practicality, with empirical validation on math and toxicity tasks kept distinct from the theoretical claim. No load-bearing step reduces by construction to a parameter fit, self-citation chain, or renamed empirical pattern; the framework treats r as an explicit tunable trade-off parameter whose effect is analyzed rather than presupposed. The result is therefore independent of the specific approximation details used in experiments.
Axiom & Free-Parameter Ledger
free parameters (1)
- abstention reward parameter
axioms (1)
- domain assumption Token generation can be modeled as a Markov decision process with abstention as an explicit terminal action.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.